
基于BERT模型的排比句自动识别方法
2021-07-16 08:02朱晓亮谯宇同
计算机应用与软件 2021年7期
朱晓亮 谯宇同
1(华中师范大学教育大数据应用技术国家工程实验室 湖北 武汉 430079) 2(华中师范大学国家数字化学习工程技术研究中心 湖北 武汉 430079)
0 引 言
修辞是通过各种语言手段修饰言论,从而达到尽可能好的表达效果的一种语言活动,常用的修辞手法主要有排比、拟人、比喻三种。其中,排比修辞手法可以让行文更加条理清晰且气势宏大,因此在各类文章中都被大量采用。通过计算机自动抽取文章中的排比句,可以在自动写作推荐领域和作文评分领域得到较好的应用[1-2]。
对于排比句的自动抽取问题,早期的研究者的解决方法是根据排比句的语法特征,提出一系列规则对排比句进行识别。例如:巩捷甫[1]根据排比句的结构和语法特征提出一系列规则对高考作文中的排比句进行自动识别,并在此基础上实现了对高考作文的自动评阅;熊李艳等[2]提出对主题词进行提取,并对标点符号、共现词和工整性进行匹配,对演讲稿中的排比句和工整句进行了自动抽取;梁社会等[3]通过求最长公共子序列及分句结构相似程度的方法对《孟子》和《论语》中的排比句进行了自动识别。然而,由于汉语的句法和章法并不一定具备严格的逻辑性结构[4],采用固定规则而不考虑语意信息对排比句进行自动抽取的效果并不理想。随着深度学习在自然语言处理领域的发展,通过深度学习方法抽取文本的语意特征对排比句进行自动抽取的研究也逐步展开。比如:穆婉青等[5]将分句结构相似度计算方法与卷积神经网络相结合,对文学作品以及高考题中的文学类阅读材料进行了排比句自动抽取实验;Dai等[6]采用循环神经网络中的长短期记忆网络对学生作文中的排比句进行了自动抽取。综合上述研究,基于深度学习的抽取效果较大程度上取决于是否选取了合适的特征抽取器。同时,也需要综合权衡算法复杂度与算法有效性之间的关系。
基于上述分析,本文对用深度学习方法对排比句进行自动抽取展开研究,提出了两种自动识别方法,并将两种方法结合作为预处理手段,在选择出的特征抽取器的基础上设计了排比句自动识别方法并在数据集上验证方法的有效性。
1 相关研究
1.1 特征抽取器
自然语言处理任务的常见输入形式往往是若干数量的句子或者段落,这使得自然语言处理的任务存在如下特征:其输入是一个不定长的一维线性序列;句子中各成分之间的相对位置有重要意义;句子中存在的长距离特征对于理解语义也比较关键。在自然语言处理任务当中,对于语义特征信息的抽取是由特定的特征抽取器完成的,因此从模型角度来说,特征抽取器性能的好坏在很大限度上决定了整个模型的性能优劣。目前比较典型的特征抽取器有CNN、RNN,以及由谷歌在2017年提出的Transformer模型。
1) CNN。卷积神经网络(CNN)是深度学习的代表算法之一,CNN最初在计算机视觉领域的应用较多,在自然语言处理领域的应用则是由Kim[7]提出的。在经典的CNN算法中,输入的字符以Word Embedding的形式进行表达,对于特征的抽取是由包含了若干个卷积核的卷积层[8]来完成的,对于一个指定窗口大小的卷积核,不断地将输入中相应大小的输入转换为特征值,最终形成一个特征向量。在卷积层的每个卷积核都完成这样的一个过程后,形成的不同特征序列,输入到一个池化层中进行降维,进而输入到全连接层中,形成对原始输入的分类[9]。
传统的CNN模型可以简洁地完成某些自然语言处理任务,但也存在着一些缺陷:卷积核的窗口大小是固定的,对于超过窗口大小的长距离特征无法抽取;在池化层进行的池化操作,可能会导致文本的相对位置信息丢失。因此CNN的各种改进方法被提出,如Yu等[10]提出用空洞卷积的方法使得卷积核的计算区域大于卷积核的一维卷积长度。同时随着计算机运算能力不断提高,用池化层来降低运算规模已经不再重要,因此取消池化层,提高CNN的深度,也能提高CNN模型的性能。
2) RNN。循环神经网络(RNN)是自然语言处理领域的经典模型之一,传统RNN的模型结构如图1所示。
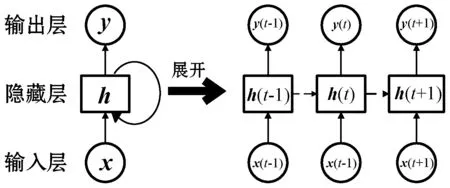
图1 标准RNN模型结构图
在RNN网络的每一层之间都有一个隐藏状态h(t)从前向后传播,每一层的h(t)都由当前层的输入x(t)和由上一层传入的h(t-1)计算得来[11]。传统RNN模型在对隐藏状态反向传播的时候很容易发生梯度爆炸和梯度消失的问题,在RNN模型基础上加以改进而提出的LSTM模型和GRU模型通过控制隐藏状态的传递过程来缓解此问题,取得了很好的效果,成为了主流的RNN模型。但除此之外,RNN仍存在一个较大的问题:每一时刻的隐藏状态h(t)的计算都需要依赖前一时刻的隐藏状态h(t-1)的输入,给RNN进行并行计算造成了困难。
3) Transformer。Transformer是由谷歌在2017年针对机器翻译[12]提出的一种模型,其结构如图2所示。
从宏观上讲,标准的Transformer模型是由编码组件和解码组件两部分组成的,编码组件部分由若干个编码器组成,而解码组件部分由相同数量的解码器组成。每个编码器都有着相同的结构,即由Multi-Head Attention和前馈神经网络两部分组成;每个解码器的结构也相同,即由Masked Multi-Head Attention、Multi-Head Attention和前馈神经网络三部分组成。
为了保存并利用输入的文本序列中各成分的相对和绝对位置关系,Transformer模型在将输入的文本进行Embedding操作过后,还会将文本的位置信息进行编码并加入,这称为Position Embedding,其计算公式如下:
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(1)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(2)
式(1)-式(2)意为将id为pos的位置映射为一个dmodel维的位置向量,该向量的第i个元素对应的数值即为PE(pos,i)。将两个公式的计算结果拼接起来,即得到每个成分的位置编码。
Transformer模型对特征的抽取依赖于自注意力机制。在编码器的Multi-Head Attention层,每个输入的Embedding都会与查询、键和值三个权重矩阵相乘,生成对应的查询向量、键向量和值向量。然后将每个输入的查询向量与其他输入的键向量求点积,得到一个得分。之后将计算出的得分进行处理后,通过Softmax归一化,使得所有的得分都为正且和小于1,得到Softmax分数,该分数代表了每个输入对于编码当前输入的贡献。最后将Softmax分数分别与每个输入的值向量相乘,再对其加权求和,即得到了某个输入的自注意力输出。在Transformer模型中,自注意力机制还被赋予了Multi-Head机制,即定义多组不同的权重矩阵,令每个输入重复多次上述计算过程,每一个计算过程被称为一个自注意力头,以此可以提升Multi-Head Attention层的性能。
在解码器中,除了Multi-Head Attention层之外,还有一层Masked Multi-Head Attention层。因为解码器需要完成将编码转换成单词输出的操作,因此在该生成过程中,对于某一时刻i,只有小于i时刻的输入有效,大于i时刻的就会被屏蔽掉。解码器其余两层的结构与编码器相同,最终会输出一个实数向量。该实数向量会经过线性变换层,转换为一个分数值,投射到一个被称为对数概率的向量中。对数几率向量中的分数再经过一个Softmax层,转换为概率,最终最高的概率被转换成对应的单词,形成最终的输出。
4) 分类器比较。与CNN和RNN模型相比,Transformer模型在对语义特征进行提取的能力上有非常显著的优势,且对于不同自然语言处理任务都有较好的特征抽取能力。同时,Transformer模型在抽取长距离语义特征的能力上与RNN接近,且明显优于CNN,在执行并行计算的性能上与CNN接近,且明显优于RNN。
1.2 排比句的语法特征
李胜梅[13]在对排比句的篇章特点进行研究后认为,排比句最重要的结构特征是在句子中包含三项或者三项以上的结构相同或相近的言语片段。排比句的结构中包含了首项与复现项,其中首项为复现项提供了结构与定势,为读者的阅读过程给予引导;复现项与首项的结构相同,仅在部分成分上加以变化,使读者的注意力能够集中在变化的部分,接受到新的语意信息,举例如下。
例1友谊是“桃花潭水深千尺,不及汪伦送我情”的那份真诚;友谊是“祝你每一天都有一个灿烂的笑容”的那声祝福;友谊是“如果你正心情不好,我可以借个肩膀你靠一靠”的那种安慰;友谊是成功时朋友脸上的微笑和鼓励;友谊是失败时朋友脸上呈现的那份焦急和肯定、支持的眼神!
例2勇气是冬天里炎热的火把,让我重燃斗志,继续向前;勇气是干渴时甘甜的河水,让我心花重绽,干劲万分;勇气是迷茫时明亮的灯塔,给我指明方向,勇往直前。
例3父爱如山,深沉而又博大;父爱如海,深沉而又宽厚;父爱如火,炽热燃烧;父爱如酒,令人回味无穷;父爱如伞,为你遮风挡雨。
显然,排比句具有显著的结构特征,因此可用于实现对排比句的自动抽取。
2 分类器选择
2.1 数据源
实验数据集为从作文中人工抽取出的1 022条排比句及相应数量的非排比句。这些作文来源于研究团队从某小学收集到的考试、日常作文及从网络上收集到的作文。
2.2 实验环境
本次实验的环境如表1所示。

表1 实验环境
2.3 分类器筛选
为了确定哪种特征抽取器的效果最优,本文使用不同的特征抽取器在数据集上进行排比句的自动抽取。本文选取相关研究中介绍的CNN模型、RNN模型及BERT模型作为对比特征抽取器。其中,BERT模型[14]是谷歌于2018年10月提出的语言表示模型,即来自Transformer的双向编码器表示。BERT是一个基于双向Transformer的预训练模型,即其本身是在一个大规模语料库上进行训练生成的双向Transformer模型,可以通用于各种自然语言处理任务。在对具体的任务进行处理时,只需要在预训练模型的基础上增加一个额外的输出层,对模型进行微调而不是进行大量的结构修改。BERT模型在序列级别的分类任务上的表现最好,而排比句的自动识别实际上是一个对输入进行排比/非排比的二分类任务,因此可以用于排比句自动识别。在中文预训练BERT模型中,包含了12个Transformer层,768个隐藏单元,12个自注意力头,总参数量达到了1.1亿。
实验使用标准的CNN模型、改进的RNN模型(GRU模型和LSTM模型)和谷歌的中文预训练BERT模型来进行排比句的自动识别。使用不同分类器对排比句进行自动识别的结果如表2所示。
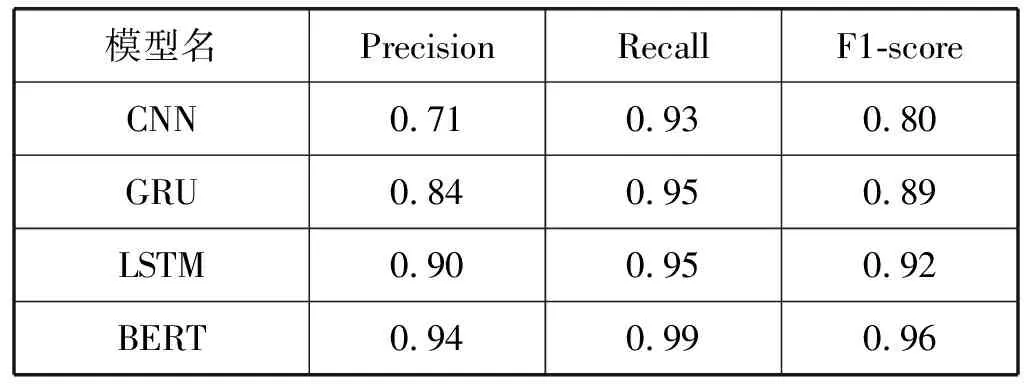
表2 不同分类器的排比句自动识别效果
可见,BERT模型对排比句进行自动识别的效果相比于其他模型有明显提升,因此采用BERT模型来对排比句进行自动识别较传统模型相比获得了较好的结果。同时,运用BERT模型的结果与相关研究者的排比句自动识别结果对比如表3所示,非排比句的识别结果对比如表4所示。可见,采用BERT模型对排比句和非排比句进行自动识别的准确度较以往的方法有较大提升。
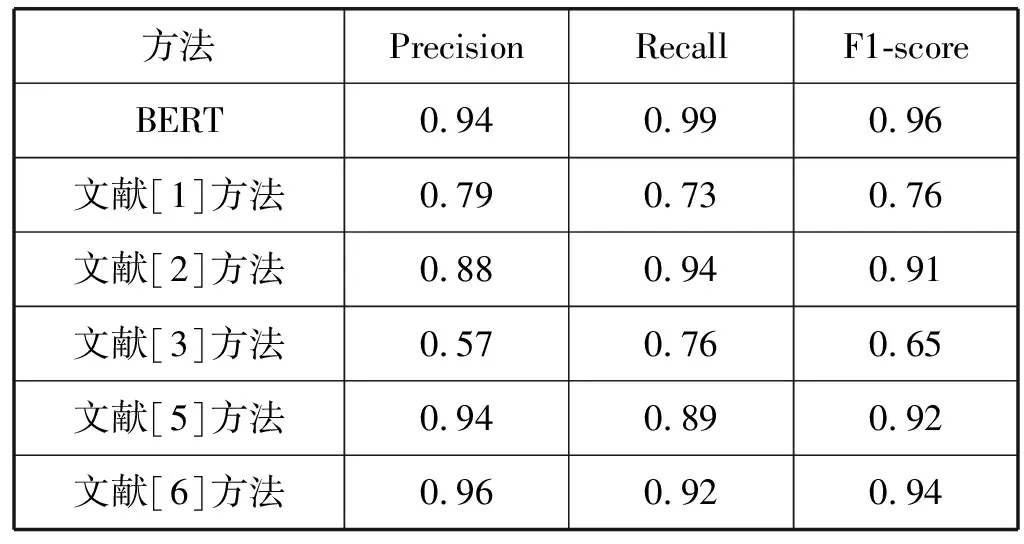
表3 排比句自动识别结果

表4 非排比句自动识别结果
3 改进的排比句自动提取方法
由于BERT模型自身的复杂性,对大量的语料进行自动识别时,其运行速度有待提升,见图3。其中CPU时间的测试环境见表1。

图3 BERT模型处理不同数据集所需的CPU时间
为了降低识别时间,考虑到对于作文这一类别的语料而言,排比句在所有句子中只占有较少的一部分。因此,在对大规模语料进行自动识别之前,如采用一些预处理手段缩小待识别语料的规模,将在不降低识别准确度的前提下提升识别的速度。
3.1 算法设计
根据上述排比句的语法特征,以及对于例句的分析,可以将对排比句的自动抽取分为两种情况:① 句子中的部分分句包含相同的词语,且重复的次数大于2次;② 句子中的分句不包含相同的词语,或相同词语重复出现的次数小于等于2次。
对于情况①,可以认为该句为排比句。对于输入的语句T,将T按照句中的标点符号(逗号或分号)分为若干个分句Si,若两个分句包含相同的词语则记为Si≈Sj,那么整个句子中含有相同词语的分句数D可以用如下递归函数进行计算:
(3)
为判断各个分句间是否包含相同的词语,将分句Si分别通过分词工具进行分词,并将Si的分词结果与Si-1的分词结果逐个进行比对。最终判断分句数D是否大于2,若大于2,则将语句T判别为排比句。本文使用这种方法在包含400个语句的数据集上进行测试,得到的结果如表5所示。

表5 基于重复词汇的方法测试结果 %
可见,本文方法识别排比句的准确率极高,因此可以通过该方法快速地抽取数据集中结构特征明显的排比句。
对于情况②,则无法准确判断该句是否为排比句。对于这种情况,可以对句子进行依存句法分析,判断整句结构各成分之间包含的语义依赖关系。由于在排比修辞当中,各排比项之间往往存在着相互并列的关系,这与依存句法当中的并列(Coordination)关系相对应,因此可以作为判断排比句的另一特征。对于输入的语句T,本文将T通过哈尔滨工业大学的语言技术平台中的依存句法分析工具进行分析,得到T中各成分之间包含的语义依赖关系,对这些依赖关系中存在的并列关系进行计数,若并列关系数小于2,则将该句判别为非排比句。本文在基于重复词汇的方法基础上,使用这种方法在包含400个语句的数据集上进行测试,得到的结果如表6所示。

表6 基于并列关系的方法测试结果 %
可见,本文方法识别排比句的召回率极高,因此基本可以保证识别的结果中不会丢失正确的结果。需要注意的是,依存句法当中的并列关系并不仅仅存在于排比句当中,而是在语言使用当中广泛存在的,因此通过这种方法无法准确判断输入的语句是否为排比句,本文仅通过这种方法对输入语句中的非排比句进行识别。
基于BERT模型,结合以上两种方法,本文设计出如下的排比句自动识别流程:通过基于重复词汇的方法识别输入中的排比句,并将其余语句通过基于并列关系的方法识别其中的非排比句。对于剩下的包含并列关系数大于等于2的语句,本文将其标记为疑似排比句,交由BERT模型进行进一步的判断,将BERT模型的识别结果与前两种方法的结果进行结合,得到最终的输出。方法流程如图4所示。
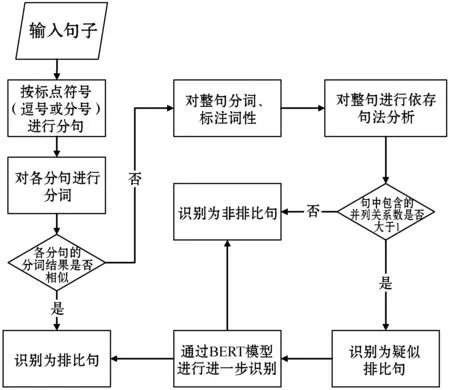
图4 排比句自动提取方法流程
3.2 实验与结果分析
对于包含了400条语句的数据集,在经过本文提出的预处理方法进行缩小规模过后,仅保留103条语句需要BERT模型进一步识别,规模缩小了74%,可见该方法缩小数据规模的效果明显。由上文可知,在本文实验环境下,BERT模型对每一条语句识别的CPU时间需要12 s左右,而基于重复词汇的方法识别出一条排比句最多仅需要低于0.001 s,基于并列关系的方法识别出一条非排比句最多仅需要低于0.9 s,对于这两种方法的结合使用使得整个自动提取的流程速度大幅提升。在不同数据集下,本文方法的识别所需CPU时间如图5所示。
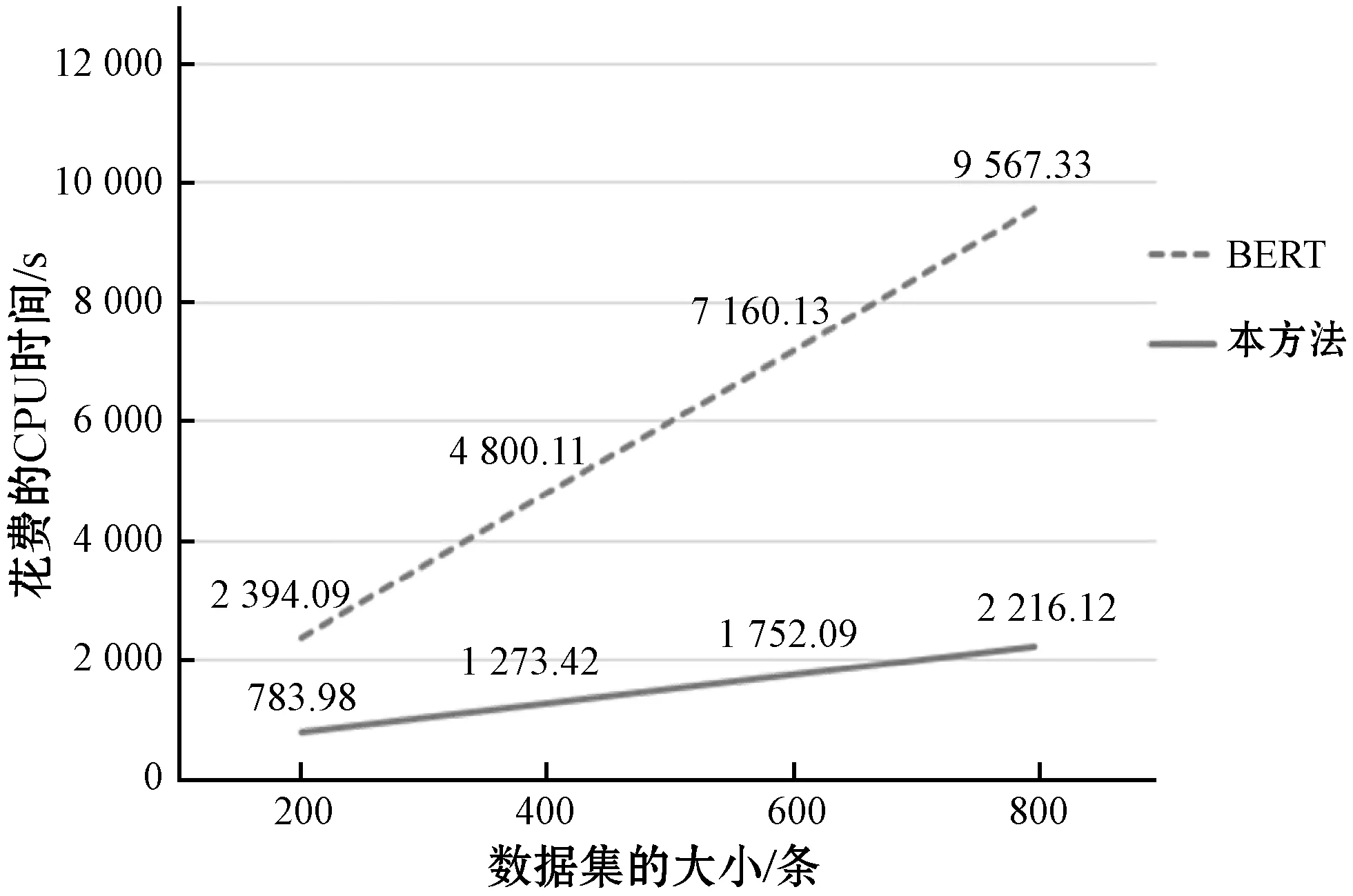
图5 本文方法处理不同数据集所需CPU时间
同时,由于对部分结构特征明显的排比句和句法特征明显的非排比句进行了直接快速地判别,避免了BERT处理过程中可能出现的误判,使得识别的准确率也有所提升,如表7所示。

表7 本文方法测试结果
此外,本文流程也可以在计算能力更强的GPU上运行,使得所需时间进一步降低。
4 结 语
本文针对作文文本中的排比句,提出了使用BERT模型进行识别的方法。同时根据排比句结构相似、成分存在并列关系的特点,提出了一种预处理手段,缩小了输入数据的规模,在大幅提升模型整体运行速度的同时,对准确率也有所提升,验证了本文方法的有效性。但本文仅在作文文本上进行了实验,未在政论、新闻等其他文体上进行实验,数据量较小。后续工作中,将考虑把本文的方法推广到更广泛的语料上开展实验,验证算法的可靠性。
猜你喜欢
农业工程学报(2022年5期)2022-06-22
舰船科学技术(2022年10期)2022-06-17
计算技术与自动化(2022年1期)2022-04-15
小学阅读指南·高年级版(2022年2期)2022-03-10
作文周刊·小学四年级版(2020年24期)2020-07-17
小学教学研究·理论版(2015年10期)2015-12-05
数学教学通讯·初中版(2014年6期)2014-08-11
小学生·多元智能大王(2014年6期)2014-07-09
创新作文(1-2年级)(2014年3期)2014-05-19
小雪花·初中高分作文(2009年8期)2009-11-16
