
高EGCG含量茶树品种光谱识别模型构建*
2021-07-15 01:42翁海勇许金钗陶铸刘江洪郑金贵叶大鹏
中国农机化学报 2021年6期
翁海勇,许金钗,陶铸,刘江洪,郑金贵,叶大鹏
(1. 福建农林大学机电工程学院,福州市,350002; 2. 现代农业装备福建省高校工程研究中心,福州市,350002; 3. 海峡两岸科技产业合作基地(成员单位),福州市,350002)
0 引言
表没食子儿茶素没食子酸酯(Epigallocatechin gallate,EGCG)是茶多酚里面一种重要单体,具有较强的抗氧化活性,能提高免疫力,抑制癌细胞的产生,已在流行病学、细胞培养、动物研究和临床试验中得到证实[1-2]。高EGCG茶在市场上倍受青睐,EGCG的含量已成为衡量茶叶价格的重要因素。然而,茶叶是EGCG唯一的来源,EGCG无法通过人工合成[3]。因此,筛选出高EGCG含量的茶树品种具有重要意义。
目前,茶叶中的EGCG含量检测主要采用高效液相色谱法(High Performance Liquid Chromatography, HPLC)[4-5]。虽然检测精度高但存在操作过程繁琐、检测周期长、破坏性和成本较高等问题,无法满足高EGCG茶树育种过程中大规模测量。近年来,光谱检测技术因具有快速、无损的优点在农产品品质高通量检测中表现出巨大的应用前景。Lee等[6]利用近红外光谱技术对绿茶鲜叶中的咖啡因、ECG和EGCG等9种品质指标进行检测,预测模型精度大于0.9。Huang等[7]利用可见—近红外光谱技术研究了新鲜绿茶中的儿茶素和咖啡因,建立的多元线性回归定量模型得到相关系数均大于0.893。董春旺等[8]通过近红外光谱对红茶发酵过程中品质指标进行检测,建立了支持向量机(SVR)模型,能够较好地反演出红茶中茶红素、茶褐素、儿茶素和酚氨比的含量。赵杰文等[9]应用傅里叶近红外漫反射光谱检测茶叶中儿茶素含量,建立了偏最小二乘法的定量分析模型,相关系数大于0.97。Luypaert等[10]利用近红外光谱技术对绿茶中EGCG和EC两种单体的含量进行定量分析,模型对EGCG和EC的相关系数分别可达0.83和0.44。Li等[11]提取了茶叶的可见近红外光谱反射率,结合区间偏最小二乘法建立了茶多酚预测模型,相关系数为0.916 3。上述对茶多酚或儿茶素单体的研究虽然取得较好的效果,但所选用的样本所含的茶多酚或儿茶素单体浓度较低,模型无法适用于高EGCG茶树品种的筛选。
鉴于上述研究,有必要研究基于光谱技术的高EGCG茶树品种识别模型。因此,本文以高/低EGCG茶树品种的叶片为研究对象,利用近红外高光谱技术探究高/低EGCG含量茶树品种叶片的光谱特性,结合化学计量法建立高EGCG含量茶树叶片的识别模型,研究结果可为高EGCG茶树高通量育种提供技术支持。
1 材料与方法
1.1 试验样本
供本次研究的2个茶树品种分别为高EGCG含量的W1茶树和低EGCG含量的Huangdan,其中W1和Huangdan茶树均由福建农林大学农产品品质研究所培育。茶树种植于福建农林大学农产品品质研究所试验茶园内。茶叶采摘于2020年9月14日。采摘时,摘取嫩梢上一芽四叶,W1和Huangdan的叶片各396片。本次试验共得到792片作为研究对象。如图1所示,高(W1)和低(Huangdan)EGCG含量茶树品种的叶片无法通过肉眼进行有效地区分。

图1 代表性高EGCG茶树品种(W1)和低EGCG茶树品种(Huangdan)叶片
1.2 茶叶近红外光谱反射率采集
本次试验采用NIRez-G1近红外光谱仪获取W1号和Huangdan茶树叶片的近红外光谱反射率。仪器的光谱波长范围为950~1 650 nm,光谱分辨率为10 nm。在茶叶的近红外光谱反射率采集前,先获取暗电流和参考板的光谱数据,用于数据处理前对茶叶原始光谱的校正。首先,采用近红外光谱仪采集标准白板(HIS—CT—250×280)上3个不同位置光谱,求平均值,记为W。随后用黑色不透光的塑料圆盘遮住采样口,采集3次光谱,求平均值,记为B。为了尽可能地获取更多茶叶表面的光谱信息,在试验过程中采集叶片上3个不同的位置,求平均值作为该样本的原始光谱数据。随后采用式(1)对茶叶的光谱进行校正,求得反射率。
Rc=(Dc-B)/(W-B)
(1)
式中:Rc——茶叶的光谱反射率;
Dc——茶叶的原始光谱;
W——标准白板的原始光谱;
B——暗电流的原始光谱。
1.3 茶叶EGCG含量测定
光谱数据采集完后,分别选取W1和Huangdan叶片各45片用于EGCG含量测定。每3片当成1个样本,每个品种分别取15个,共30个。样品前处理过程如下:将茶鲜叶放置于120 ℃烘箱中杀青6 min,随后在90 ℃条件下烘干至恒重。具体方法参考GB/T 8313—2018进行测量。
1.4 识别模型构建
1.4.1 主成分分析
主成分分析(Principal Component Analysis,PCA)是通过正交变换将一组可能存在相关的变量转化为一组线性不相关的变量[12-13]。PCA通过将原始数据降维,消除众多信息共存中相互重叠的信息部分,使得数目较少的新变量成为原变量的线性组合且能最大限度的表征原变量的数据结构特征。将分析主成分得分向量绘制成二维或三维散点图可实现不同类别样本聚类趋势的定性分析。
1.4.2 敏感波段的选择
高光谱的数据维度高,易出现冗余和共线性等问题。为了简化模型以及提高模型运算效率,需要从全波长中筛选出对EGCG敏感的波段。本研究选用RF(Random Frog)算法对EGCG敏感波段进行提取。RF算法通过少数变量进行建模,从而输出每个变量被选取的概率。首先,初始化包含Q个变量的子集V0。其次,计算出包含Q*个变量的候选变量子集V*,然后选择V*作为V1来代替原始变量的子集V0,接着迭代N次直到终止。最后,输出每个变量被选取的概率[14]。变量被选取的概率越大说明其对EGCG越敏感。
1.4.3 识别模型
识别模型的性能直接影响着高EGCG含量茶树叶片的识别效果。本文分别对比线性判别分析(Linear Discriminant Analysis,LDA)和最小二乘支持向量机(Least Support Vector Machine,LS-SVM)两种机器学习方法对高EGCG含量茶树叶片的识别效果。
LDA是将高维空间的样本映射到低维空间,以期实现提取有效的分类信息并对数据降维,以此同时确保映射到低维空间的样本具有最小的类内距离以及最大的类间距离,具备最优的可分离性[15]。LS-SVM是在传统SVM的基础上,采取最小二乘线性系统作为损失函数,通过求解线性方程式来取代标准SVM的凸二次规划求解,从而加快模型运算效率[16]。本文选取径向基(Radial Basis Function,RBF)作为LS-SVM的核函数。采用网格搜索算法和交叉验证(Cross Validation,CV)相结合实现模型的两个主要参数γ和sig2(σ2)的寻优。在分类过程中,把W1茶树叶片和Huangdan茶树叶片的标签分别赋值为“1”和“2”。采用KS(Kennard-Stone)算法将茶叶样品按照2∶1的比例分成建模集和预测集[17]。
1.4.4 模型筛选效果的评估指标
识别模型的性能利用识别正确率Accuracy、漏判率、误判率和Kappa系数4个参数进行评估[18]。模型将高EGCG茶树品种(W1)判别成低EGCG茶树品种(Huangdan)称为漏判率,反之则称为误判。Accuracy的计算公式为
Accuracy=(n1/n2)×100%
(2)
式中:n1——预测正确的预测集样本数;
n2——预测集样本总数。
在混淆矩阵的基础上计算Kappa系数,如式(3)所示。
Kappa=(po-pe)/(1-pe)
(3)
式中:po——每类被正确分类样本数量之和与该样本总数量的比值。
每一类的真实样本个数分别为a1,a2,…,ac,而预测结果中的每一类的样本个数分别为b1,b2,…,bc,总样本个数为n,则pe为
pe=(a1×b1+a2×b2+…+ac×bc)/(n×n)
(4)
当Kappa=0.0~0.2,表示预测与真实的一致性极低;当Kappa=0.21~0.40,表示预测与真实的一致性一般;当Kappa=0.41~0.60,表示预测与真实的一致性中等;当Kappa=0.61~0.80表示预测与真实的一致性较好;当Kappa=0.81~1.0,表示预测与真实的一致性几乎一致[19]。
本文涉及到的光谱数据处理在MATLAB R2014a、Unscrambler10.1和EXCEL2010中完成。
2 结果与分析
2.1 茶叶EGCG浓度统计分析
W1和Huangdan叶片中的EGCG含量如图2所示。W1茶树叶片中的EGCG含量(13.68±1.99)%明显高于Huangdan(4.86±1.17)%,相差2.81倍。单因素方差分析结果表明两者达到显著性差异(P=2.75×10-6<0.05)。将EGCG含量大于10%的茶树品种称为高EGCG含量茶树品种[20]。因此,本研究选用的茶树W1和Huangdan可分别视为高/低EGCG含量茶树品种,这为下文建立高EGCG含量茶叶品种识别模型提供参考。
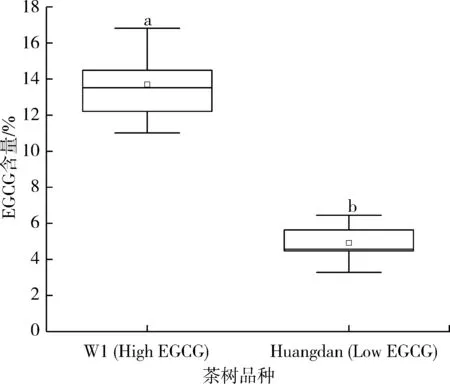
图2 W1茶树和Huangdan叶片中的EGCG含量
2.2 平均光谱曲线
高EGCG含量茶树(W1)和低EGCG含量茶树(Huangdan)叶片的平均光谱反射率如图3所示。
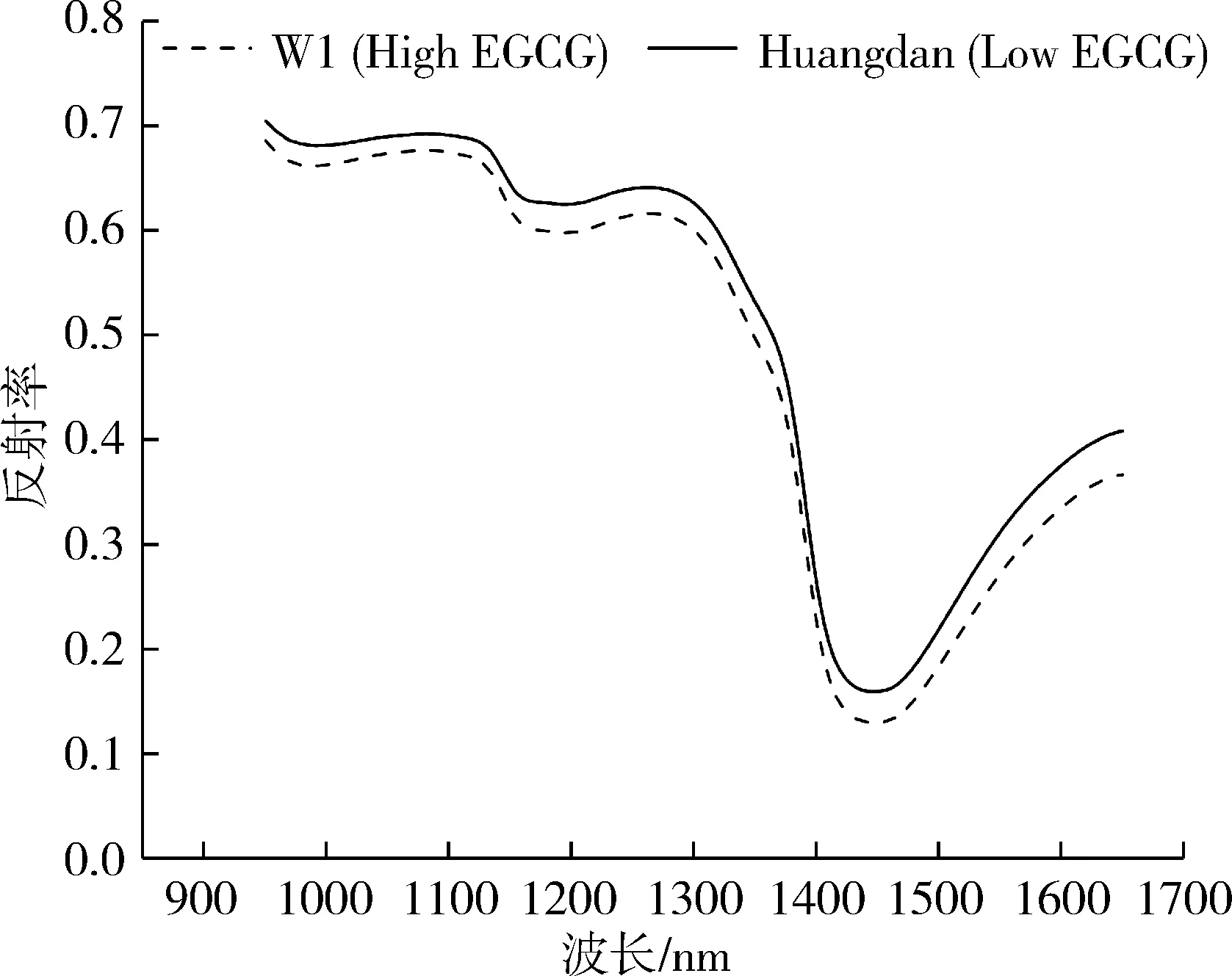
图3 高EGCG含量茶树(W1)和低EGCG含量的茶树(Huangdan)叶片的平均光谱曲线
由图3可知,两种茶树叶片的光谱曲线趋势大致相似,具有相似的吸收峰,说明其所含的主要成分相似。进一步分析可知,W1叶片的近红外光谱反射率低于Huangdan叶片,这可能与W1和Huangdan叶片中某些成分的含量存在差异有关。1 100~1 650 nm的反射率反映了样品中有机物含氢基团(C—H、O—H、N—H)的弯曲振动或倍频伸缩振动信息。在1 100~1 420 nm 范围内光谱反射率与CH3或CH2的C—H键伸缩振动的一级倍频及组合频有关,在1 400~1 550 nm 的吸收峰主要由O—H键、C—H键以及N—H键伸缩或弯曲振动引起;在1 600~1 650 nm范围内的光谱反射率发生变化主要是与C—H键的一级倍频振动伸缩振动有关[21]。儿茶素单体的分子结构中含有许多碳氢基团,因此,在1 100~1 650 nm范围内可能含有与儿茶素单体相关的化学信息[22]。W1茶树和Huangdan叶片的光谱反射率在这些光谱范围内存在差异。因此,有望依据光谱特性建立高EGCG含量茶树品种识别模型。
2.3 主成分分析
图4(a)显示了前7个主成分对原始变量的解释程度。前四个主成分累计贡献率达99.92%,能够解释原始数据绝大部分信息。其中,PC1、PC2、PC3和PC4的贡献率分别为95.4%、4.2%、0.19%和0.057%。由于PC1和PC2的贡献率已经大于99%,因此将有必要进一步分析PC1和PC2的得分。
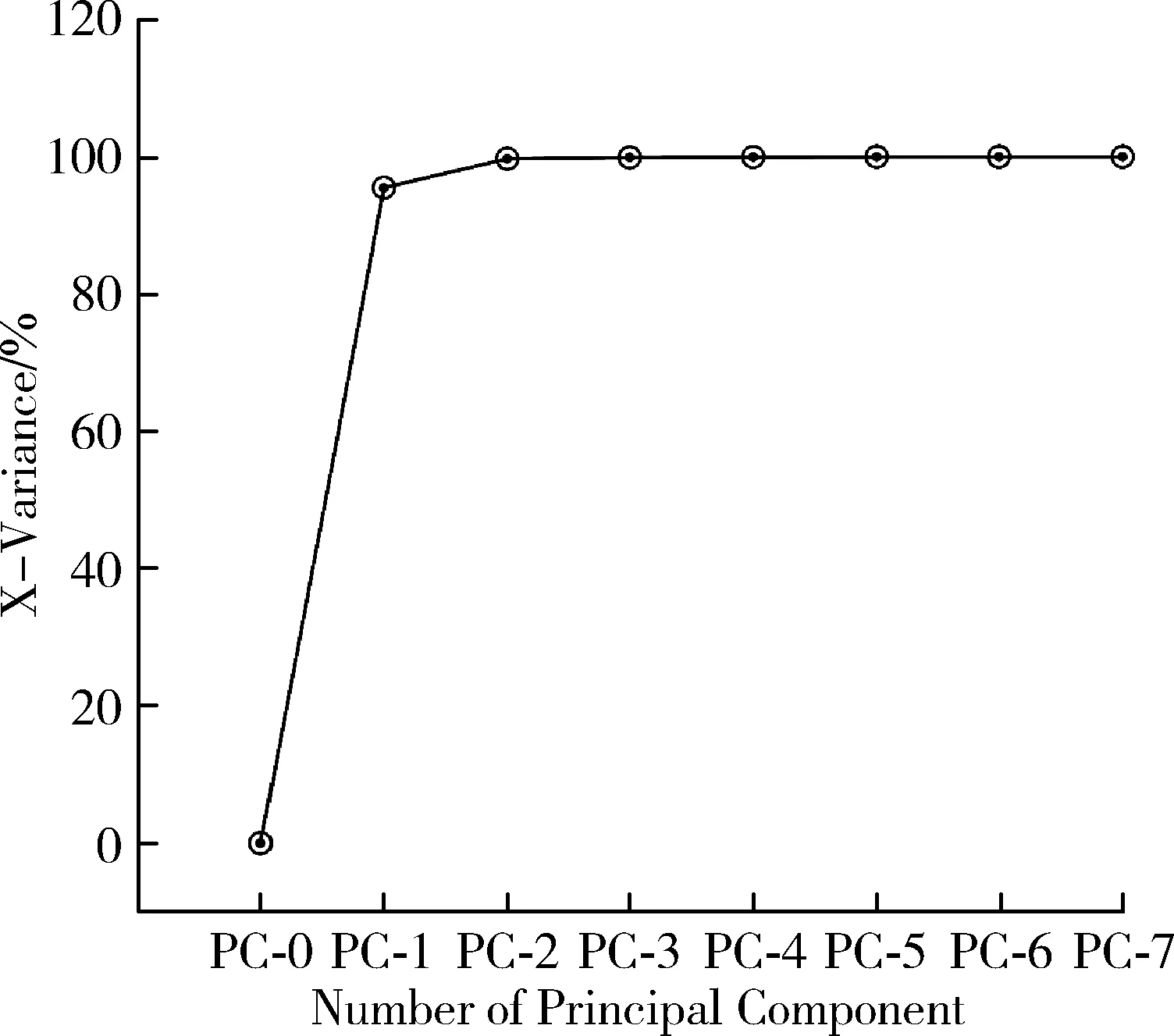
(a) 前7个主成分累积方程贡献率
由图4(b)可知,高EGCG茶树叶片和低EGCG茶树叶片在PC1和PC2得分分布图上具有聚成两类的趋势,但是仍然也存在重叠的地方。因此,需要对光谱数据进行进一步分析和处理以期获得更好的区分结果。
2.4 敏感波段的筛选
简化数据维度,提高模型运算速度,优化筛选模型有助于在茶树育种过程中更加有效地筛选出高EGCG含量茶树品种。因此,有必要从原始的228个变量中提取出EGCG含量敏感波段。基于RF算法求解出的各个波段对EGCG的敏感性如图5(a)所示。由图5(a)可知,对EGCG敏感性较高的波段主要集中在1 100~1 650 nm范围内,这与图3分析的结论相一致。合理的敏感波段数量有利于减少数据维度以及简化筛选模型,因此有必要按照最终识别模型的识别效果来设置最优的选取概率的阈值,从而获取相应的敏感波段作为识别模型的输入变量。
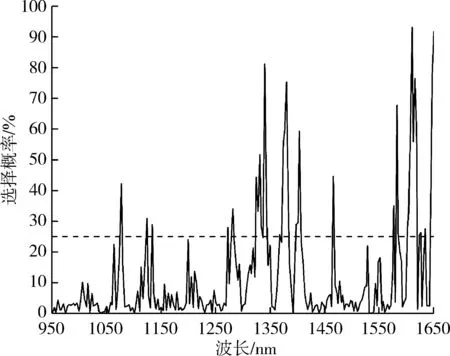
(a) 不同波段的选择概率
本文采用阈值为25%,取前35个概率较大的敏感波段进行分析,分别为(1 610,1 650,1 341,1 647,1 615,1 380,1 582,1 607,1 618,1 377,1 403,1 612,1 374,1 331,1 645,1 465,1 325,1 078,1 383,1 577,1 282,1 604,1 328,1 344,1 124,1 401,1 398,1 134,1 334,1 273,1 602,1 634,1 627,1 585和1 368 nm),分布情况如图5(b)所示。
2.5 高EGCG含量茶树品种模型的识别效果分析
不同输入变量下LS-SVM和LDA模型对高/低EGCG茶树品种的识别效果如图6所示。从图6可以看出,当输入变量的数量小于等于3时,LS-SVM和LDA的识别效果均不理想。随着输入变量的数量增多,两个模型的识别准确率逐步上升,这说明增加敏感波段的数量有助于提升高EGCG茶树品种的识别效果。总体来看,LS-SVM模型的识别准确率均优于LDA模型。当敏感波段数量为20个时,LS-SVM模型的总体准确率为93.94%大于LDA模型(90.90%)。但是当敏感波段数量大于20个时,随着输入变量的逐渐增多,LS-SVM 和LDA模型的总体识别准确率保持相对平稳,说明增加的敏感波段并没有显著增加对样本的描述性信息。综上所述,在相同的输入变量,LS-SVM算法更适合用来构建高EGCG茶树品种的识别模型。
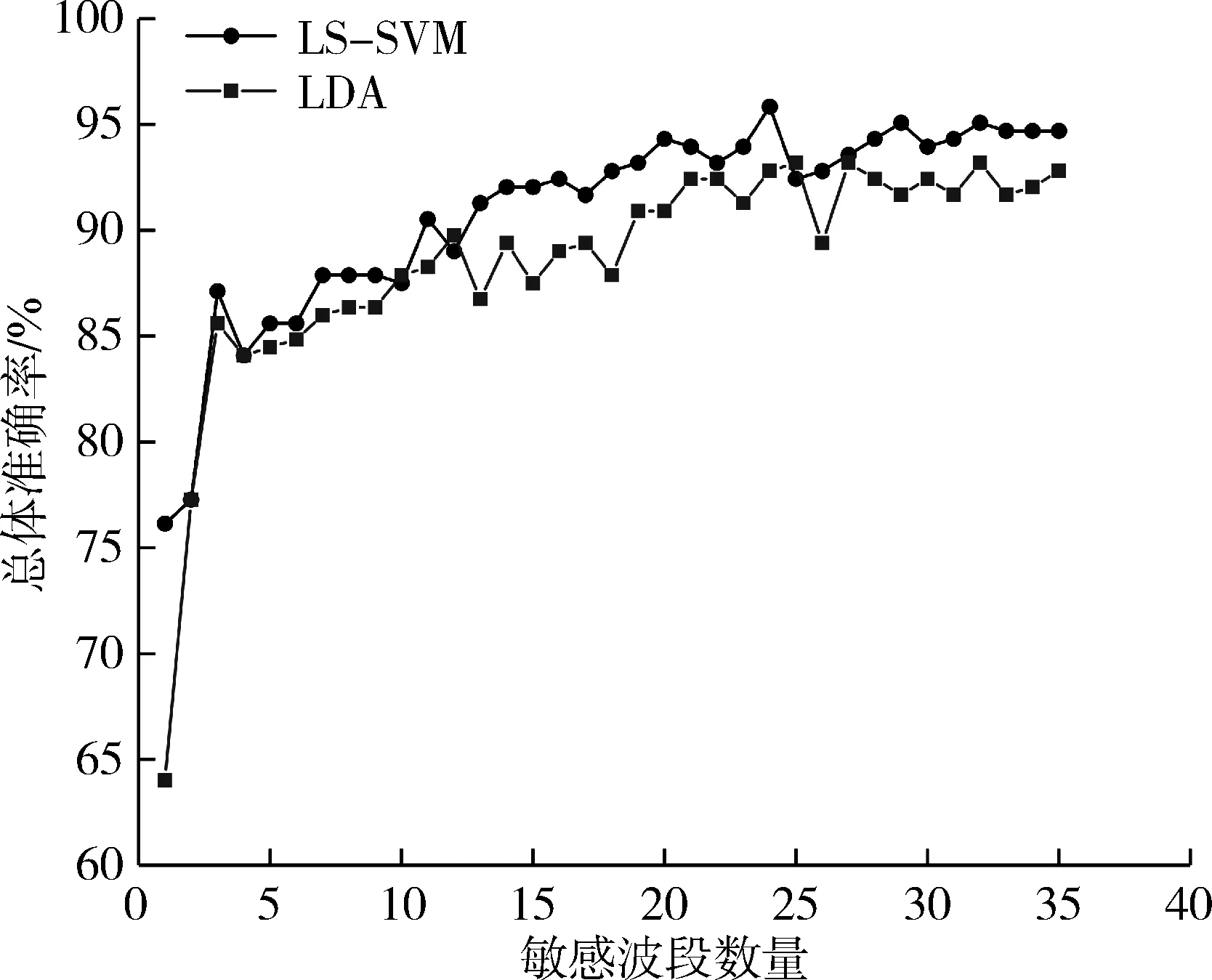
图6 不同数量的敏感波段对LS-SVM和LDA模型识别效果影响
仅根据总体准确率来评估LS-SVM和LDA模型的识别性能还不够,需要进一步分析两个模型的混淆矩阵及Kappa系数。当敏感波段为20个时,LS-SVM和LDA对高/低EGCG茶树品种的识别结果如表1所示。从表1可以看出,LS-SVM筛选模型建模集和预测集的总体准确率分别为94.32%和93.94%。其预测集的漏判率、误判率、Kappa系数分别为8.63%、3.20%和0.89。其中,12个高EGCG茶树品种的叶片被漏判成低EGCG茶树叶片。LS-SVM模型的Kappa系数均大于0.81表明利用机器学习方法识别出高EGCG茶树品种与实际高EGCG茶树品种几乎完全一致。相比之下,LDA识别模型建模集和预测集总体准确率分别为86.17%和90.90%,出现了过拟合的现象。LDA模型预测集的漏判率为7.26%,误判率为10.71%,Kappa系数为0.83。9个高EGCG茶树品种的叶片被漏判成低EGCG茶树品种叶片。上述结果表明,在茶树育种过程中,RF算法结合 LS-SVM 构建的模型具有快速实现高EGCG茶树品种初筛的能力。
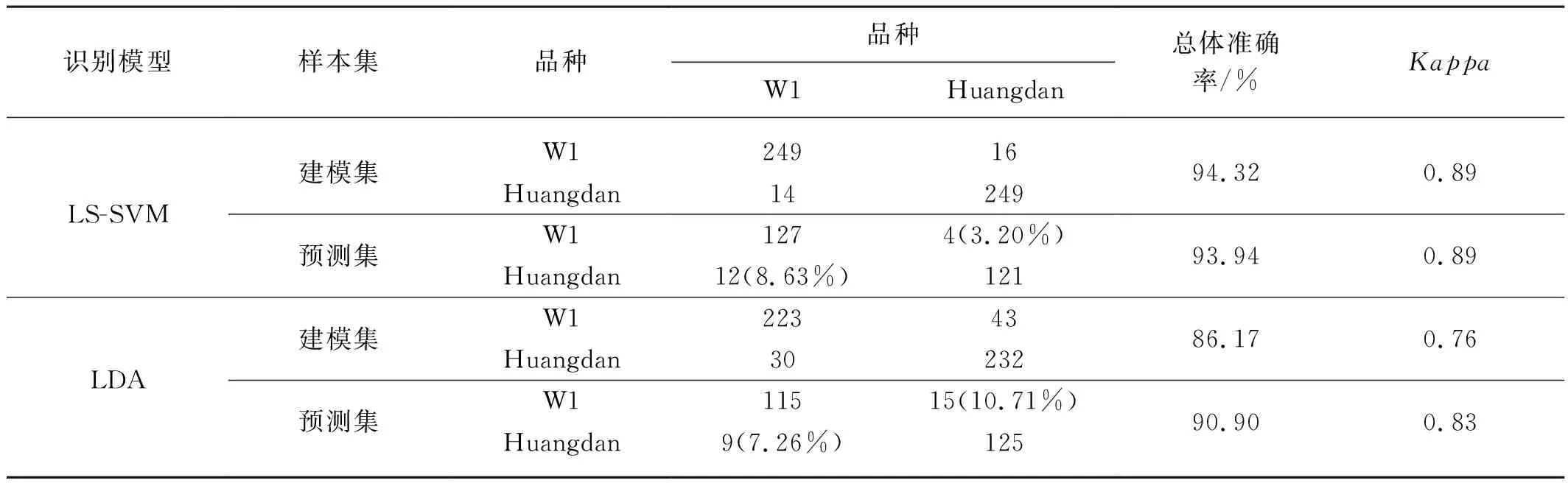
表1 LS-SVM和LDA模型对高/低EGCG茶树叶片的识别结果Tab. 1 Discriminant results of high/low EGCG tea varieties with LS-SVM and LDA models
3 结论
1) 本文采用高效液相色谱法(HPLC)测定W1和Huangdan叶片中的EGCG含量,得出W1茶树叶片中的EGCG含量(13.68±1.99)%明显高于Huangdan(4.86±1.17)%,相差2.81倍。单因素方差分析结果表明两者达到显著性差异,这为建立高EGCG含量茶叶品种识别模型提供参考。
2) 对比分析了高/低EGCG茶树叶片的光谱反射率,主成分分析后样本的第一主成分(PC1)和第二主成分(PC2)的累计方差贡献率为99.6%,对应的得分对高/低EGCG含量茶树叶片具有较好的聚类作用,但是仍然也存在重叠的地方。
3) 利用Random Frog算法选取的前20个敏感波段结合LS-SVM建立的识别模型能够有效实现高EGCG含量茶树叶片的识别,LS-SVM模型的建模集总体准确率为94.32%,Kappa系数为0.89,预测集总体准确率为93.94%,Kappa系数为0.89。表明利用机器学习方法识别出高EGCG茶树品种与实际高EGCG茶树品种几乎完全一致。
4) 采用近红外高光谱技术结合化学计量学分析方法具有快速识别高EGCG茶树品种能力,研究结果为筛选出高EGCG含量茶树品种提供新方法和技术指导。
猜你喜欢
印制电路信息(2022年11期)2022-11-30
海洋通报(2022年4期)2022-10-10
光谱学与光谱分析(2022年4期)2022-04-06
乡村地理(2018年2期)2018-09-19
电子器件(2017年2期)2017-04-25
高师理科学刊(2016年8期)2016-06-15
湖南农业(2016年3期)2016-06-05
音乐天地(音乐创作版)(2016年11期)2016-02-05
西藏科技(2015年4期)2015-09-26
河北北方学院学报(自然科学版)(2014年2期)2014-05-30
