
融合BERT的多层次语义协同模型情感分析研究
2021-07-14 16:21胡任远刘建华卜冠南张冬阳罗逸轩
计算机工程与应用 2021年13期
胡任远,刘建华,卜冠南,张冬阳,罗逸轩
1.福建工程学院 信息科学与工程学院,福州350118
2.福建省大数据挖掘与应用技术重点实验室,福州350118
情感分析(sentiment analysis),是指通过自动分析用户对某种事物的文本内容,提取出用户对该事物的褒贬态度以及意见,属于文本分类问题。传统的机器学习方法可以解决文本分类问题,例如支持向量机、朴素贝叶斯、最大熵、K邻近算法等。传统方法主要通过人工标注一部分文本数据为训练集,并需要文本数据特征进行人工提取,然后训练机器学习的分类模型,最后利用分类模型对没有标注的数据进行预测,输出最终的预测分类结果。基于传统机器学习的文本分类方法已经取得了非常多的成果,但需要依赖复杂人工规则的文本特征工程,而特征工程的策略是否合适会大大影响情感分类的效果。
近些年来,深度学习在自然语言处理领域取得了硕果,被广泛应用于情感分析任务中,成为当前研究热点[1]。其优势为能够采用词嵌入(word embedding)技术,把词映射成一个实值向量空间,提取词向量为特征,减少人工特征工程对情感分析的影响。Kim等[2]将不同卷积核的卷积神经网络对英文文本进行语义特征提取,在句子级分类任务中模型的分类效果出色。李洋等[3]提出将CNN与BiLSTM网络特征融合的文本情感分析模型,利用Word2vec训练词向量,在以往模型的基础上进一步提升情感分析问题的分类准确率。刘全等[4]提出的一种用于基于方面情感分析的深度分层网络模型,其中的区域卷积神经网络需要将事先将用户的评论语言按不同方面的目标词分割为长度固定的不同区域,提取了文本序列中不同的特征。以上研究人员都通过不同的神经网络模型处理情感分析问题,并且取得了较好的分类效果。
Word2vec[5]目前被广泛应用于NLP 领域中词向量的训练。Pennington 等[6]于2014 年提出Glove 模型,该模型提高了词向量在大语料数据集上的训练速度和模型稳定性,从而被广泛应用。通过深度学习对语料库数据的训练,可以预训练出词向量,构成预训练模型。故预训练模型(Pre-trainedmodel)是一种基于大量数据集训练得到的神经网络架构,并且可以在此基础上进行下游任务的实现。预训练模型在很多NLP 任务中的表现大多比传统神经网络更为出色。通过对预训练模型进一步的深入研究,ELMo[7]、Transformer[8]、基于转换器的双向编码表征(BERT)[9]等丰富的预训练模型被相继提出,其中BERT 是目前应用最广泛的预训练模型。Xu等[10]针对BERT模型缺乏对领域知识和任务相关知识的问题,提出了一种后训练的解决方案,但其训练的特征较为单一,未能学习到序列的多层次特征。GAO等[11]在目标词后添加了一层最大池化层和一层全连接神经网络,提出了基于目标的BERT 分类模型,但其忽略了上下文之间的联系而只关注于目标情感词。堪志群等[12]将BERT 与BiLSTM 结合,在微博数据的倾向性分析中取得了出色的效果,串行连接的BiLSTM可以在微调任务(Fine Tune)中特征提取能力仍有提高空间。谢润忠等[13]提出了一种基于BERT 和双通道注意力的模型,在情感分类任务中表现出色,但其用的双通道注意力模型同时需要训练两种BERT 模型,时间成本巨大,并且其左通道结合了BiGRU提取序列的联系忽略的情感极性的表达,右通道添加一层全连接神经网络,同样缺乏对目标任务特征的进一步提取。
以上文献使用的BERT 模型为了处理不同领域的任务,使用了微调的方法让模型在训练时可以不断学习领域知识,并且通过反馈神经网络的来更新原本模型的参数。但是在研究文本序列的情感极性时,均存在以下不足:(1)BERT模型在通过后续任务补全推理和决策的过程中,未能很好的帮助其多方面学习情感分析领域知识,提升模型的分类能力。(2)对于句子级文本情感分类任务模型获取的文本情感极性略显单一,多层次语义的捕获能力不足。
由于在情感分析任务中,截取不同长度的文本内容,其所表达的情感极性可能出现截然不同的情况。针对以上问题,本文提出一种多层次语义协同模型(MCNN)来提取多层次语义的情感倾向特征,该模型能够以分组的形式,将句子切分成不同长度的句块,进而对不同的句块做特征提取,因此可提取到文本序列内不同层次角度的情感极性特征,帮助模型更准确的判断文本序列的情感极性。最后,本文将MCNN 与BERT 融合,形成了一种基于BERT 模型的多层次语义协同模型,能够分析文本序列的情感极性,并且该模型使用BiLSTM,抓取序列的上下文联系,使用MCNN 对文本序列进行不同层次上的情感极性特征提取,避免模型存在上述问题的不足,提高了模型的分类准确性。
1 相关工作
1.1 卷积神经网络
卷积神经网络(CNN)是深度学习的重要网络之一,其由于采用了局部连接,权值共享的方式,相比起传统神经网络采用全连接方式而言,有效的解决了网络参数大,训练时间长等问题。CNN 主要是由输入层、卷积层、池化层和全连接层组成,如图1所示。

图1 卷积神经网络
1.1.1 卷积层
在文本处理中,对句子做分词处理,得到词向量数据,然后将词向量数据输入到CNN的卷积层,使用卷积核对其做卷积操作,得到新的特征矩阵。图1中的X1,X2,…,Xn为句子所对应的词嵌入向量,将词嵌入向量作为卷积层的输入,根据式(1),可以得到序列输出:

其中,X为词嵌入向量组成的矩阵,W为权重矩阵,b为偏置量,f为卷积核激活函数。
1.1.2 最大池化层
在卷积神经网络结构中,池化层一般分为平均池化层和最大池化层,本文使用的为最大池化层。将卷积层的输出序列输入池化层,在提取文本的主要特征同时,也降低了向量维度,减少要训练的权重,并将结果传给下一层神经网络。
1.2 双向长短期记忆网络
1.2.1 传统长短期记忆网络
传统的循环神经网络(RNN)在情感分类任务中,随着文本序列长度的增大,容易出现梯度消失问题。为解决该问题,1997年,Hochreiter等[14]提出长短期记忆网络模型(LSTM),LSTM 是对RNN 的改进,有效地解决RNN 网络在训练过程中梯度消失的问题,利用细胞状态和门机制,使其能够记忆上一步的信息,并融合当前接受的信息向下传输,如图2所示。

图2 长短期记忆网络
LSTM运行机制如式(2)~(7)所示:

其中,i、o、f分别代表着LSTM网络中门机制内的输入门、输出门和遗忘门,c是记忆细胞用来记录细胞状态的更新,在t时刻,网络接收到当前输入xt和上一时刻t-1 遗留的信息向量ht-1作为三个门机制的输入,it、ot、ft分别为输入门、输出门、遗忘门在t时刻所得到的激活向量。σ为非线性激活函数sigmoid(),tanh为非线性激活函数tanh(),图中Wf、Wi、We、Wc和Ut、Ui、Ue、Uc分别为遗忘门、输入门、输出门的记忆细胞所对应的权重矩阵,bt、bi、be、bc是偏置量,由模型训练获得。
1.2.2 双向长短记忆网络
LSTM虽然解决了文本长度依赖的问题,但是无法获取文本的上下文信息,双向长短期记忆网络(BiLSTM)可以同时考虑文本的上下文语境,如图3 所示,其工作原理为:将接收的输入传入两个时序相反的LSTM 网络中,前向LSTM 可以获取输入序列的上文信息,而后向的LSTM 可以获取输入序列的下文信息,然后通过向量拼接的方式得到最终序列的隐藏表示。为了防止过拟合,本文采用Hinton 等[15]提出的Dropout 策略,每次迭代随机删减隐藏层的部分神经元,达到了一定程度上的正则化效果。将x1,x2,…,xn作为输入,通过前向LSTM 和后向LSTM 分别获得了hL和hR,如式(8)和(9)所示:
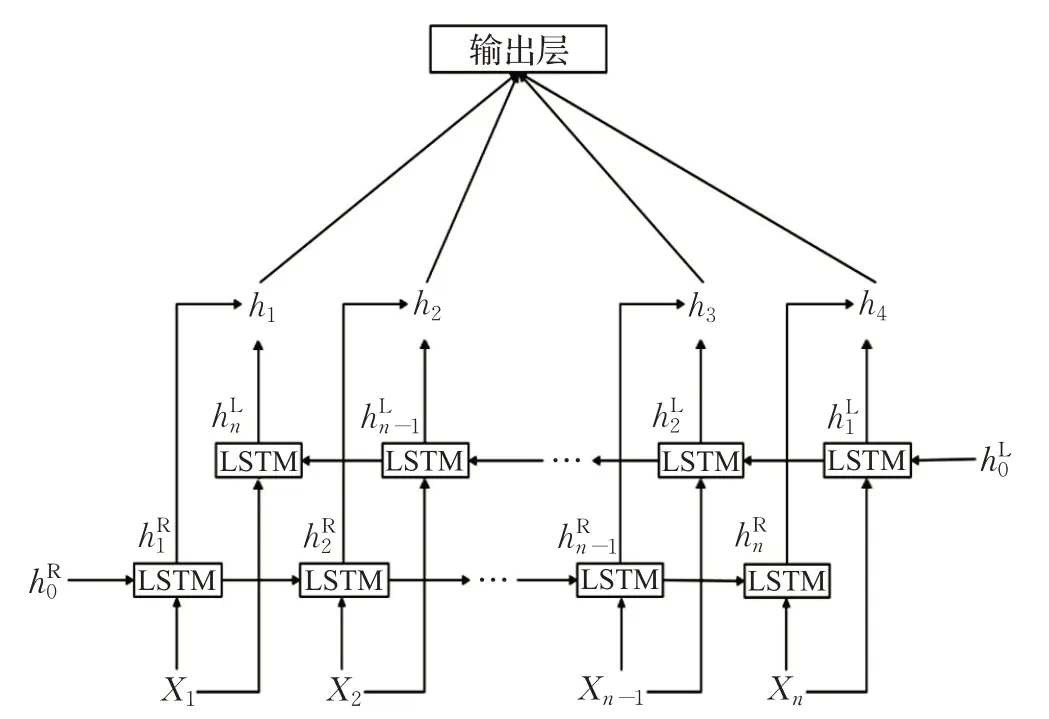
图3 双向长短期记忆网络

最后连接hL和hR获得输出数据hi(i=1,2,…,n)。
1.3 BERT预训练网络
1.3.1 Transformer
Transformer 模型的Encoder 部分包含两个子模块,一个是自注意力机制层,其采用了多头自注意力(Multihead Attention),另一个为全连接的前馈神经网络,并且都对数据进行标准化操作。模型中每个子模块采用了残差连接的方式来改善神经网络退化的问题。Transformer模型以Seq2Seq结构为基础,改变了传统Encoder-Decoder架构需要依赖于RNN的模式,仅使用注意力机制和全连接神经网络搭建而成,将输入数据通过词嵌入(Word Embedding)和位置编码(Position Encoding)处理,可以学习到文本序列的位置关系,再通过多头自注意力机制来学习文本序列中字词相互的关系。Transformer模型结构如图4所示。

图4 Transformer模型
图中虚线箭头为残差连接,是为了解决多层神经网络训练困难的问题,通过将前一层的信息无差的传递到下一层,可以有效的仅关注差异部分。Attention的计算公式如(10)和(11)所示,其中Q、K、V为随机初始化而成后续通过训练不断更新,是注意力层的输入。多头注意力机制为多个自注意力机制的结合,可以使模型通过不同的头学习到不同方面的内容,给予模型更大的容量。可以帮助模型进行缩放,避免softmax的结果非0即1,W0同样为随机初始化的矩阵最后将每个头学习到的注意力矩阵进行拼接。
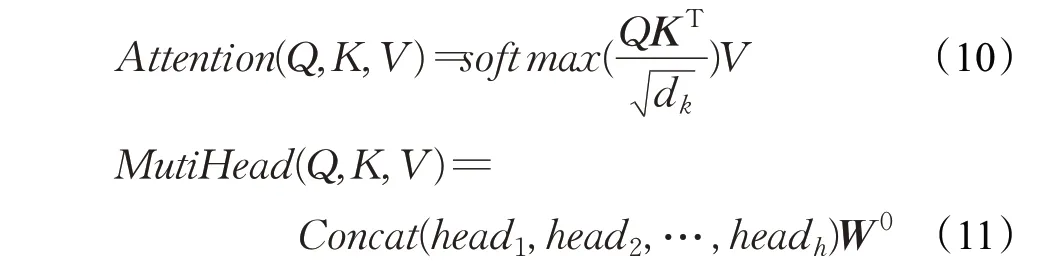
1.3.2 BERT模型
Word2vec 等传统生成词向量工具知识基于浅层神经网络的模型来提供词嵌入作为特征,相比之下BERT模型还可以集成到下游任务中,可以适用特定的任务体系并作出调整。BERT 是以双向Transformer 模型为基础的双向Transformer编码器,主要使用了Encoder模块来计算,如图5 所示。其采用遮蔽语言模型[16](Masked Language Model,MLM)建模,使得其输出的序列可以更全面的学习到不同方向的文本信息,为给后续的微调提供了更好的初始参数。
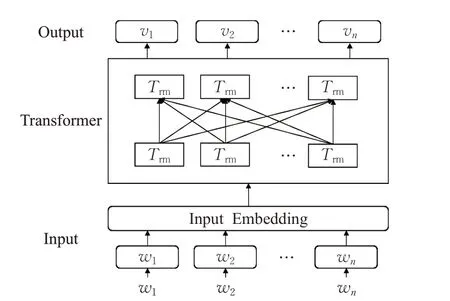
图5 BERT模型结构图
2 基于BERT 的多层次语义协同模型(BERTCMCNN)
本文提出一种基于BERT 的多层次语义协同模型。如图6所示,BERT-CMCNN模型一共有四层:输入层、特征提取层,信息融合层以及输出层。为解决BERT模型缺乏情感分析领域的知识,帮助其补全后续推理和决策环节,本文使用在BERT模型后添加的双通道中含有BiLSTM 来抓取上下文关系以及协同的多层次语义特征提取模型MCNN,该模型可以从不同角度去理解序列所表达的情感特征,而且采用协同结构可以很好地避免神经网络过深而带来的梯度消失以及信息丢失等问题。最后,在信息整合之下本文提出的BERT-CMCNN模型便包含了情感分类领域的序列关系以及不同层次的情感极性特征,更适用于情感分类任务中。

图6 BERT-CMCNN模型结构图
2.1 输入层
首先对中文文本数据进行停用词和特殊且无意义的符号进行去除,其次挑选出情感分析领域最常见的错别字构建字词典,对文本序列进行错别字替换。英文文本数据则进行特殊无意义符号去除的大小写转换。BERT 模型的每输入都需要由词向量(Token Embeddings)、段向量(Segment Embeddings)、位置向量(Position Embeddings)相加而成。其中词向量是由随机初始化而来,该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字词的语义信息相融合。段向量为区分字词所在的上下文。位置向量是由于出现在文本不同位置的字词所携带的语义信息存在差异(比如,“我爱你”和“你爱我”),因此,BERT模型对不同位置的字词分别附加一个不同的向量以作区分,输入格式如图7所示。
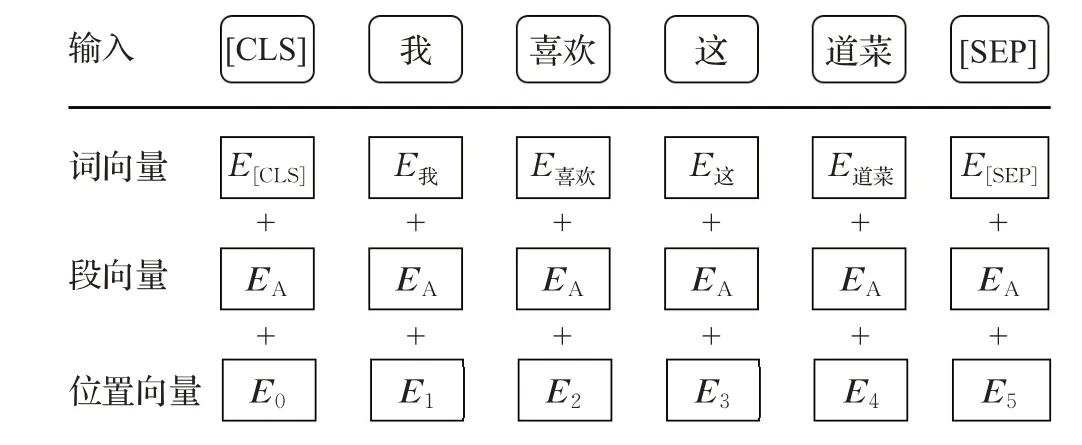
图7 BERT模型的输入
2.2 MCNN模型结构
MCNN结构如图8所示,该结构由多个不同大小卷积核的一维卷积神经网络协同组成了多层次语义学习器。该模型可以学习到以不同卷积核大小为长度的语块中,不同层次的情感特征。
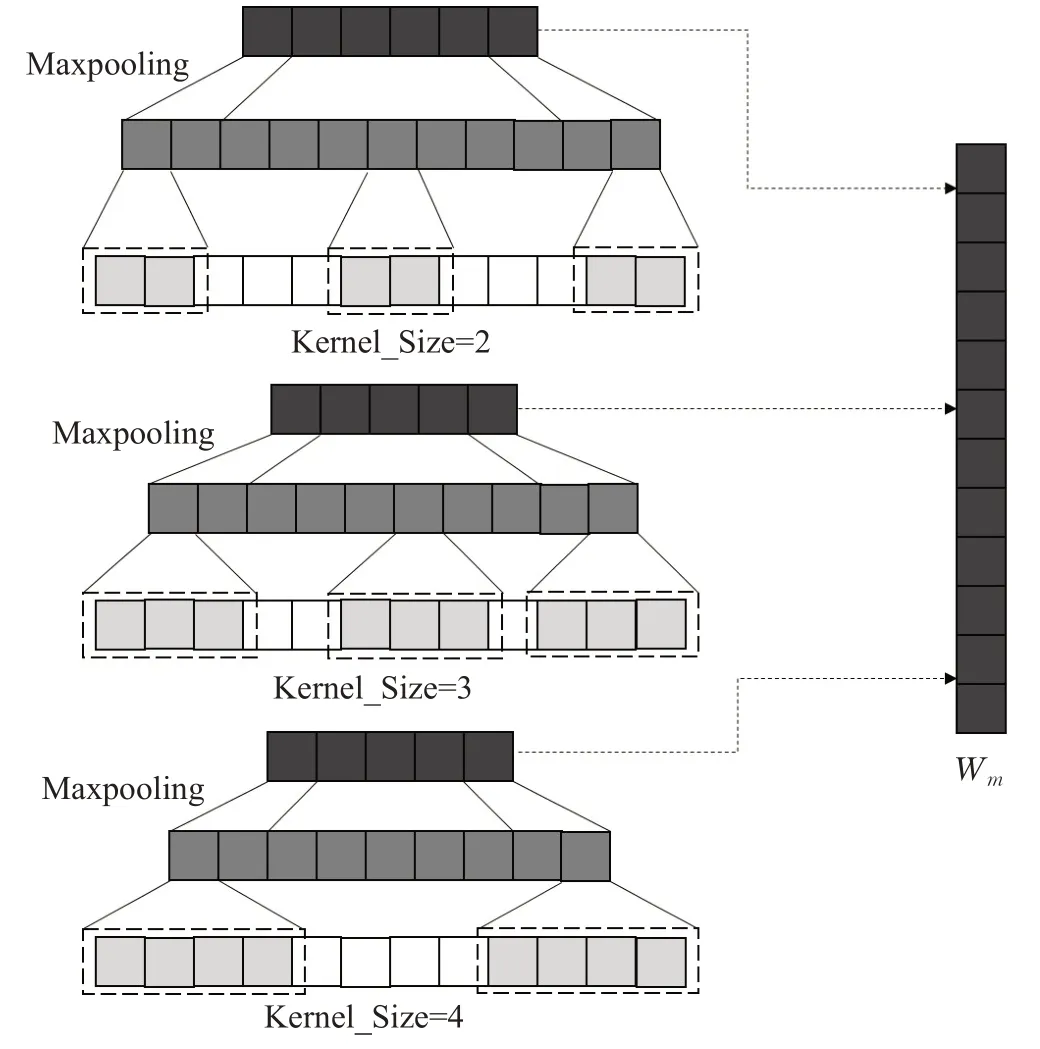
图8 MCNN模型结构图
本文采用的协同结构一定程度上避免了串行结构中容易出现深度神经网络梯度消失的问题,在后续情感分析任务中帮助模型学习到了目标领域的知识,来进行后续的补全推理和决策环节,最后将学习到的不同层次情感特征进行融合。因其能多角度多层次的学习到序列表达的情感极性,故该模型可以适用于不同语料的情感分类任务中。
3 实验方法与结果分析
实验方法主要采用以下三种方式:
(1)将BERT词向量模型与Word2vec、Glove和ELMo三种不同词向量模型做对比实验,验证了BERT词向量模型的优越性。
(2)将CMCNN 的组合方式与BiLSTM-BiLSTM 和MCNN-MCNN等两种不同的组合方式分别做消融实验并进行对比,验证了CMCNN 能够使BERT 模型补充更丰富的领域知识,提高情感分类准确率。
(3)将BERT-CMCNN 模型与其他情感分类的深度学习模型做对比实验,验证本文提出模型的能够提高情感分类的效率。
3.1 实验设置
3.1.1 实验环境
本文实验环境:操作系统为Windows10,CPU 为Intel Core i5-8300H,GPU为GeForce GTX 1060 6 GB,内存大小为DDR4 16 GB,开发环境为TensorFlow 2.2.0-GPU,开发工具使用了JetBrainsPycharm。
3.1.2 实验数据
实验采用的数据集有两种语言(中文和英文),其中每种语言都包含一个二分类数据和一个三分类数据并且训练集和测试集是独立的两个数据集,来确保本文提出方法的有效性。首先对中文文本数据进行停用词和特殊且无意义的符号进行去除,其次挑选出情感分析领域最常见的错别字构建字词典,对文本序列进行错别字替换。英文文本数据则进行特殊无意义符号去除的大小写转换。中文实验数据采用了Data Fountain 的开源数据O2O 商铺食品相关评论数据(本文缩写为据o2o)以及疫情期间网民情绪数据(本文缩写为Cov19),英文实验数据则是SST-2 和Twitter 航空评论数据,如表1 所示,CN代表中文文本数据,EN代表英文文本数据。

表1 实验数据统计
3.1.3 评价标准
本文使用的评价模型的指标为精准率(Precision)、召回率(Recall)和F1 值(F1-score),其中精准率是指正确预测正样本占实际预测为正样本的比例,召回率是指表示正确预测正样本占正样本的比例,文本引入了综合衡量指标F1 值作为模型分类结果的评价标准之一,如式(12)~(14)所示:

其中,TP(TruePositive)是指正类判定为正类个数,FP(False Positive)是指负类判定为正类个数,FN(False Negative)是指正类判定为负类个数。
3.1.4 模型参数设置
由于模型参数的选择对结果会有较大的影响,实验采用控制变量法,BiLSTM 隐层节点分别取64、128 和256,使用Adam优化器优化函数,将卷积层填充模式设为same,BERT模型选用混合语言模型来确保模型初始权重的相同。通过多次对比实验,发现取表2 参数时,BERT-CMCNN分类模型效果最好。

表2 模型参数设置
3.2 词向量模型对比实验
3.2.1 实验方法与内容
本小节采用Word2vec、Glove、ELMo和BERT不同词向量模型,对4个数据集做情感分类对比实验,目的是验证选择BERT模型更合理。实验结果数据如表3所示。
3.2.2 实验结果与分析
从表3 可以看出,Glove-CMCNN 模型结果优于Word2vec-CMCNN,是因为Glove 通过矩阵分解的方法利用词共现信息,在关注上下文的同时还学习到了全局信息,在语义表征能力上有所提升。而ELMo 与BERT都可以动态表示词向量,根据下游任务对语义表征能力进行微调,帮助模型学习领域知识,提高了了多义词的识别效率,同时产生的词向量特征更为丰富,因而模型得分均获得了大幅度的提高。

表3 基于不同词向量模型的对比结果 %
进一步观察表3 可知,相比于Word2vec 模型而言,ELMo 在4 组数据集上的准确率、召回率、F1 分数平均分别提高了4.16、4.84 和4.50 个百分点。不同于ELMo使用LSTM 进行词向量特征提取的方法,BERT 采用更为强大Transformer 编码器进行情感表征,特征提取能力得到进一步提高,相比ELMo模型,BERT模型在4组数据集上F1 分数分别提高了2.54、1.92 和2.22 个百分点,在4 组数据集上使用BERT 作为词向量工具的模型均取得了最高F1 分数。
3.3 模型组合选择的实验与分析
3.3.1 实验方法与内容
实验设置了3 组消融实验,分别改变BERT 模型后神经网络的组合方式来证明本文模型组合方式的合理性。实验结果如表4所示。
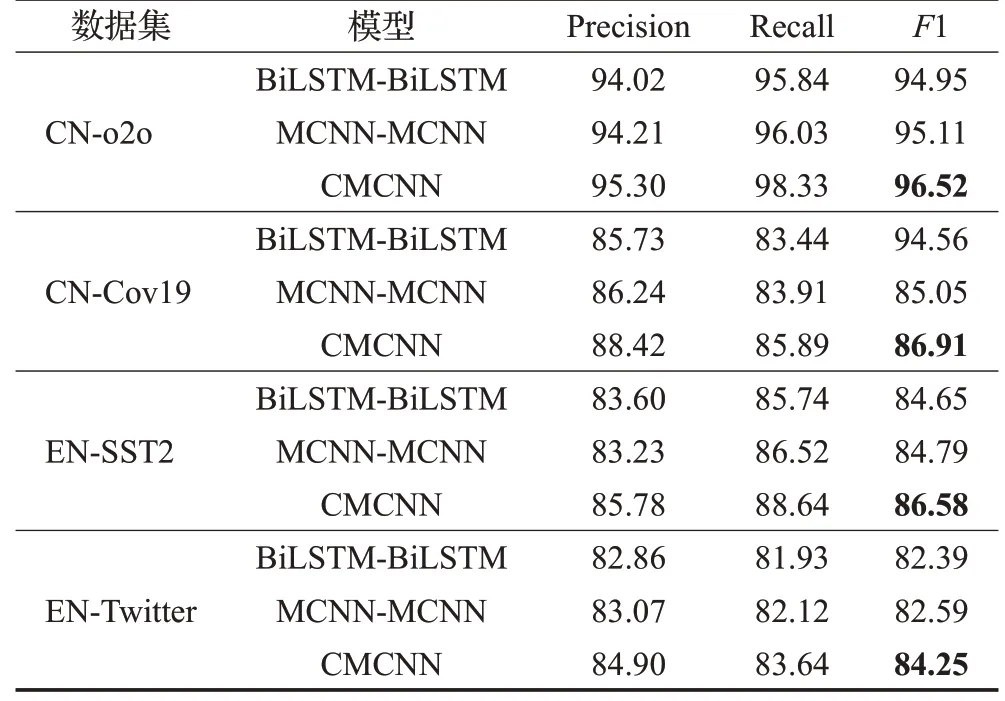
表4 不同组合方式在4种数据集上的消融实验结果 %
3.3.2 实验结果与分析
根据表4 所示实验结果,本文模型使用BiLSTMMCNN(CMCMM)模型组合方式的实验结果会优于MCNN-MCNN 以及BiLSTM-BiLSTM 模型组合方式的实验结果,因为仅使用MCNN 组合的模型虽然可以学习到多层次的语义,但其缺乏提取文本的上下文信息的能力,而仅使用BiLSTM组合的模型在多层次语义特征提取能力上更弱。相比BiLSTM-BiLSTM 模型以及MCNN-MCNN 模型,本文提出的模型在4 组数据集上的准确率、召回率、F1 分数平均分别提高了2.04、2.39、1.93个百分点和1.91、2.01、1.68个百分点。
3.4 分类模型实验与分析
3.4.1 实验方法与内容
为了验证文本提出BERT-CMCNN 模型的有效性,本小节将此模型和3 种典型的神经网络模型,3 种近期提出的基于BERT 深度学习模型,在4 个数据集上进行对比实验,这7组实验模型介绍如下。
(1)CNN:基于文献[17]提出的卷积神经网络模型,使用独立的句子作为网络模型的输入,忽略了文本序列的时序问题,也忽略了句子长距离依赖关系。是基础的卷积网络模型。
(2)BiLSTM:基于文献[18]提出的BiLSTM模型,该模型可以处理时间序列,但输入的文本序列未能进行特征提取工作,边缘信息会干扰模型分类结果,无法有效判别句子的情感极性。
(3)BiLSTM-CNN:基于文献[19]提出的结合BiLSTM和CNN的模型。输入序列先通过BiLSTM处理后再作为CNN的输入进行局部语义特征提取。在情感分析任务中该模型取得了比以往单一模型更好的效果,但未融合循环机制在CNN中,局部语义提取效果仍不显著。
(4)BERT:基于文献[10]提出一种基于迁移学习的预训练模型,采用Transformer 的Encoder 模块来构建,结合多头注意力机制和前馈神经网络去学习输入信息,相比传统的神经网络而言取得了重大的突破。
(5)BERT-CNN:基于文献[20]提出的结合BERT 和CNN 的模型,在BERT 模型后添加一层CNN 来进一步提取输入序列的情感特征,使模型能够很好地处理情感分析的任务。
(6)BERT-BiLSTM:基于文献[13]提出的结合BERT和BiLSTM 的模型,在BERT 模型后使用BiLSTM 进一步获取文本的上下文信息,使得模型在情感分类任务获得了更好的效果。
(7)BERT-CMCNN:文本提出的结合BERT 的多层次语义协同网络模型。在学习序列上下文关系的同时抓取了序列多层次的情感特征,帮助模型在后续训练中学习到目标领域的知识,使得模型更好地适应情感分类任务,并在该任务中表现出色。
3.4.2 实验结果与分析
根据表5 所示的实验结果,基于迁移学习思想的BERT模型分类效果远高于传统神经网络模型的分类效果(表5中,P、R、F分别代表精准率、召回率和F1值)。CNN、BiLSTM和BiLSTM-CNN在4个数据集上的平均F1 分数只有76.91%、78.78%和79.81%,而BERT模型相比传统神经网络,在4 个数据集上的平均F1 分数比基础的CNN、BiLSTM 和BiLSTM-CNN 模型总体提高了8.03、6.16和5.13个百分点。文本提出的BERT-CMCNN模型在4 个数据集上都取得了比其他网络模型更好的分类效果。该模型在4个数据集上的平均F1 分数比传统神经网络中表现最好的BiLSTM-CNN 网络模型在4个数据集上的平均F1 分数提高了8.48 个百分点,在表现最好的Conv19 数据集上模型效果提高了15.08 个百分点。相比使用了BERT模型的网络结构,本文提出的BERT-CMCNN 模型相比传统的BERT 模型在4 个数据集上的平均F1 分数提高了3.63个百分点,在表现最好的Cov19数据集上模型效果提高了4.16个百分点,相比近期提出的BERT-CNN模型和BERT-BiLSTM模型也均有提高,F1 分数平均提高了2.87 个百分点和2.25 个百分点。如图9~12所示,在4组数据集上本文模型的收敛速度均快于其他对比模型,验证了本文提出方法的有效性。

图9 o2o数据集上4种模型分数变化曲线

表5 不同模型在4种数据集上的结果 %
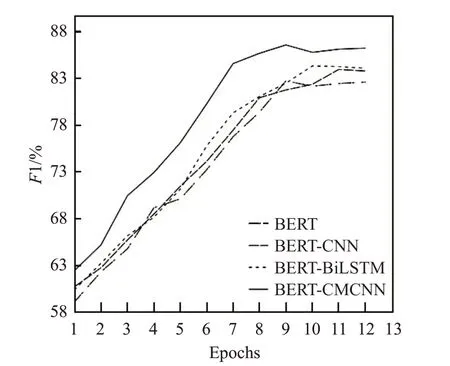
图10 Cov19数据集上4种模型分数变化曲线
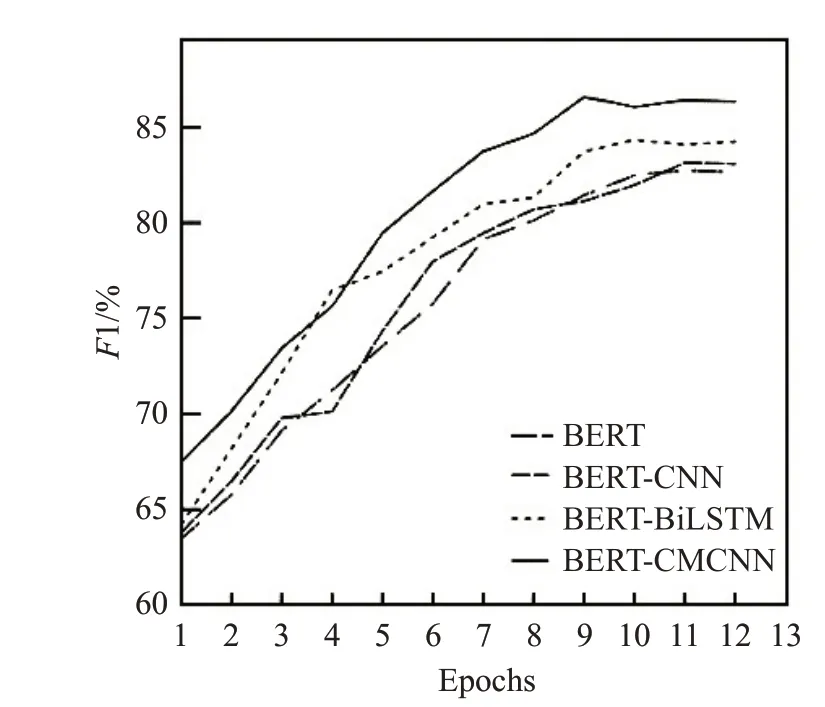
图11 SST2数据集上4种模型分数变化曲线

图12 Twitter数据集上4种模型分数变化曲线
同时本文对MCNN 中的协同通道数进行多次试验,测试模型在4组数据集上训练过程的平均F1 分数,如图13所示。分别使用二通道(K2)、三通道(K3)和四通道(K4)的协同模型进行实验,实验发现通道数过多会影响模型的时间成本但模型分类效果并无明显提高,过少则会影响模型的分类准确性和收敛速度,故本文采用三通道模型来提取多层次情感特征。对于卷积核大小的取值决定了不同层次情感特征的来源,故本文以三通道模型为前提,对卷积核大小组合的取值做了实验分析,发现卷积核在取[2,3,4]时模型分类效果最佳,如图14所示。
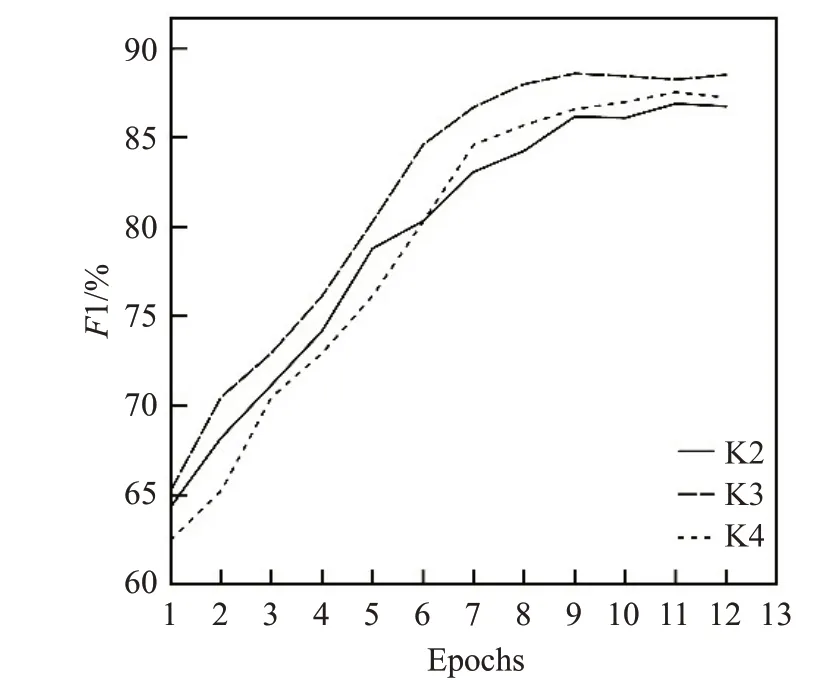
图13 不同通道数模型分数变化曲线

图14 不同卷积核组合模型分数变化曲线
4 结束语
本文针对基于迁移学习思想的BERT 模型在不同目标任务中会缺乏领域知识和目标相关知识,提出了基于BERT多层次语义协同模型,将其应用于情感分析任务中。通过和传统神经网络模型以及近期提出的基于迁移学习思想的模型在情感分类任务实验对比,验证了BERT-CMCNN模型具有更好的分类性能。本文研究模型的实验内容限于二分类和三分类问题,未来需要针对情感极性更细腻的问题,研究本文模型的有效性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
数学物理学报(2017年5期)2017-11-23
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
