
集成分类器的加密YouTube流量精细化分类方法
2021-07-14 05:34邹乐述翟江涛
重庆理工大学学报(自然科学) 2021年6期
邹乐述,翟江涛
(1.江苏科技大学 电子信息学院,江苏 镇江 212003;2.南京信息工程大学 电子与信息工程学院,南京 210044)
据CNNIC(China internet network information center)2019年8月30日发布的第44次《中国互联网络发展状况统计报告》显示,截至2019年上半年,我国互联网普及率已超过6成。截至2019年6月,我国网民规模达8.54亿。人们在享受互联网技术带来便利的同时也产生了一些新的问题,近年来互联网安全[1]事件频发,僵尸网络[2-3]、APT(advanced persistent threat)[4-5]、木马[6-7]等为主要形式的网络攻击事件愈演愈烈。2018年就有勒索病毒GlobeImposter、Facebook用户数据泄露、前程无忧195万条个人求职简历泄露等事件。随着人们的安全意识的增强,对数据保护意识也越来越强烈,为提升网络服务质量,流量加密技术成为保护数据的重要手段,当前加密流量已经成为当前主要的流量之一。流量加密在保护数据的同时也给网络安全带来了新的问题,在保护数据安全的同时也隐藏了恶意流量,因此加密流量分类成为当前研究的热点问题之一。随着加密技术、端口伪装技术、端口随机分配等方法的使用,使得现有的特征失效,很多传统的网络流量分类技术分类效果往往不佳,如普遍使用的DPI(deep packet inspection)、基于端口识别技术等。
目前,在非加密流量分类方面已有众多相关文献给出了诸多较好的方法,国内外学者取得了较多成果,Ruixi等[8]采用一种基于SVM(support vector machine)的方式可实现高精确度流量分类。在2018的互联网报告中,加密流量占比已经超过一半,而且还在急速增长之中,相信不久互联网流量将会基本以加密流量为主。将识别非加密流量的方法和特征直接应用于加密流量将不再适用。现有对加密流量分类相关文献也已取得十分不错的成果[9-11],Grimaudo等[12]提出自学习分类器也取得了不错的效果。Shen等[13]引入了Certificate报文大小增加Markov链的状态多样性,并建立二阶Markov链模型对HTTPS(hyper text transfer protocol over securesocket layer)应用进行分类。Lotfollahi等[14]采用CNN(convolutional neural networks)建立模型对流量进行分类。赵博等[15]提出了一种基于加权累积和检验的时延自适应加密流量盲识别算法,通过实验表明该方法能有效区别加密流量。当前,在不同方向都已取得了一些不错的研究成果,如加密协议的识别[16-18]、加密应用的识别[19-20]等,但上述方法大都存在分类颗粒度较粗的问题,在针对具体某一应用下流量精细化分类问题,国内相关文献较少。很多特征在具体的某一应用下的精细化识别实验效果往往不理想。加密流量之下特征的转变,不仅使得传统常用的特征失效,而且也使加密之后流量的精细化识别难度加大,在某一个应用之下,流量的相似性更大,很难寻找到有效的特征。加密流量之中视频流量所占比例较高,为提升网络服务质量,实现流量更精细化可管可控,本文提出一种基于集成分类器的加密YouTube视频流量精细化标题分类方法。实验表明,本文中所提方法较现有模型对加密应用下流量分类效果提升3%左右。
1 加密YouTube流量精细化分类方法
1.1 流量特征获取
本文的识别目标为加密YouTube视频流量精细化分类,针对传统特征失效问题,采用一种快捷且有效的特征提取方法。
1.1.1 数据集的获取及预处理
本研究所做实验采用的数据集来源是Ran等[21]所公开的数据集,如表1所示。
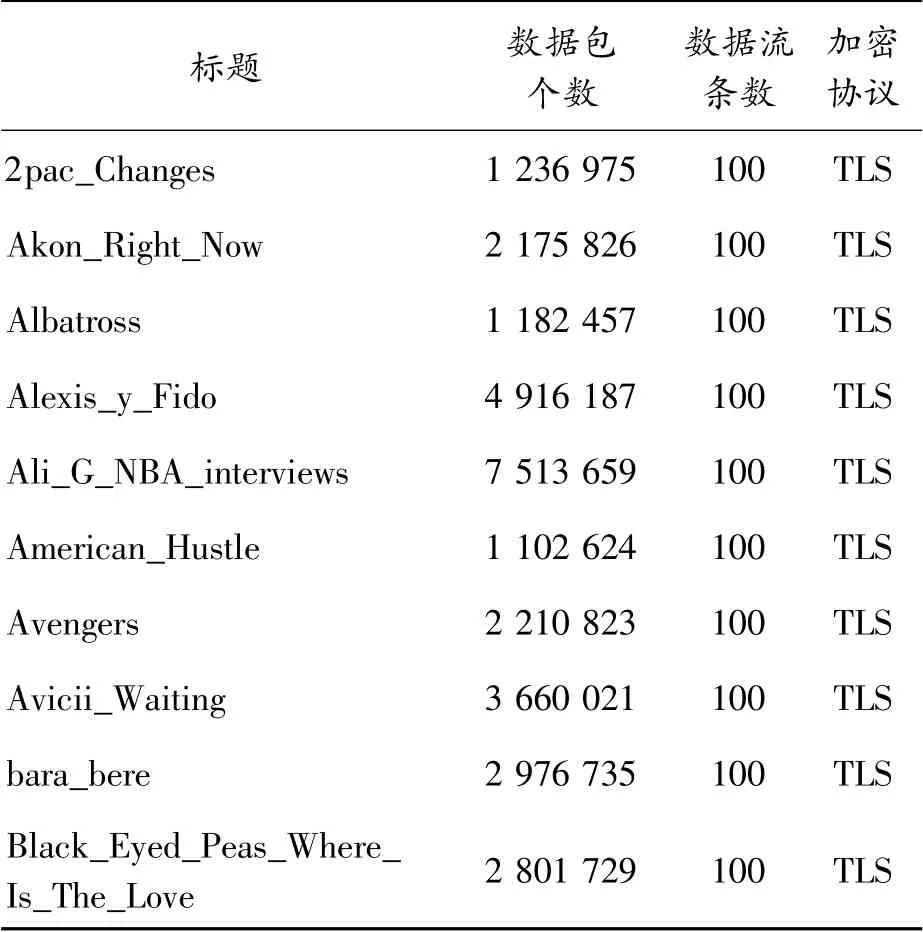
表1 实验数据集
该数据集是一个拥有10 000个YouTube视频流的大数据集,所使用的视频标题是来自不同类别的热门YouTube视频,比如体育、新闻、自然以及视频动作预告片和GoPro视频等。因为Chrome浏览器在市场上是最受欢迎的浏览器,并且其受欢迎程度正在不断增长,所以YouTube视频集采集浏览是通过Chrome浏览器,使用的播放模式是YouTube的默认的自动播放模式(播放器会根据客户端网络状况的估计决定下载哪种质量)。所使用的是Selenium网络自动化工具和ChromeDriver作为爬虫,因此它将模拟完全相同的普通用户视频下载行为方式。为此,在数据集中,其中包含10 000个YouTube流(通过真实世界的互联网连接在一个月内通过不同的真实网络条件下载)。
在获取数据集后,首先根据流量的五元组将流量进行划分(protocol、src IP、dst IP、src port、dst port),决定每个流是否为YouTube流,过滤掉其他存在的干扰流,先可基于客户端消息SNI(Server Name Indication)中的服务名称中的字段完成,如在(SNI)中找“googlevideos.com”的字段则将其留下。同时,去除其音频包,相比于视频包,音频包对识别分类的影响是有限的。本次预处理还可通过wireshark进行IP过滤筛选,wireshark分析数据样本如表2所示,同时将其中的重传包进行过滤(重传一般都是由于网络原因所造成的)。

表2 数据集样本分析
1.1.2 特征提取
通过分析流量的传输,提取传输过程的时间戳及对应时间传输的包长,如表2所示Time、Length。选取Time前T时间内传输的数据包长Length,根据时间T将它平均切分成n份,将每段时间传输数据包长之和作为特征,n段即可得n个特征,如上表取T、n分别为0.1、2,即可得2个特征,特征1为前Time0.05时间Length长度之和为2 918(285 +285+1 414+934),特征2为1 503(1 308+195)。
1.1.3 流量特征对比
当T取20、n为20,如图1所示,随机在某一类中选取10个样本,通过对比同类别之间的特征区别,可以从同类特征表现图中发现样本之间同类特征表现具有极大的相似性。如图2所示,随机选取其中4类中各一个样本,通过对比非同类样本之间的特征表现,可以发现不同类之间总存在某一特征时刻与其他样本之间差别较大。且本方法提取的特征经实验部分验证具有较强的可行性。
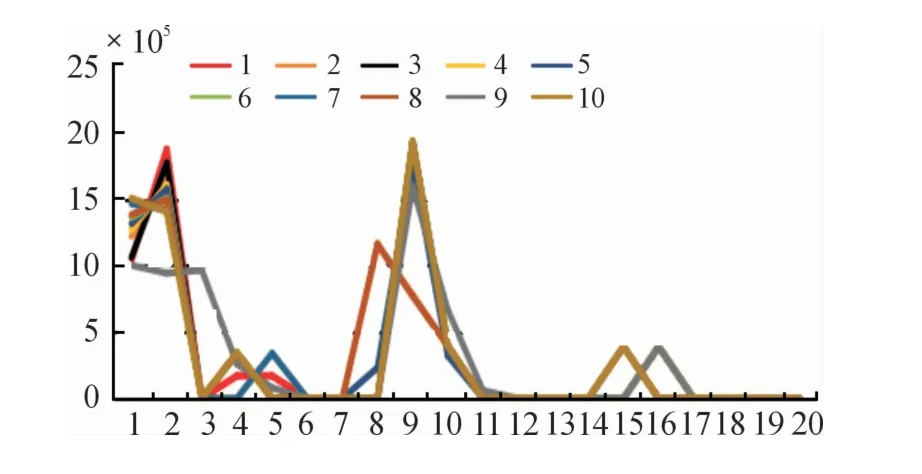
图1 同类特征对比曲线
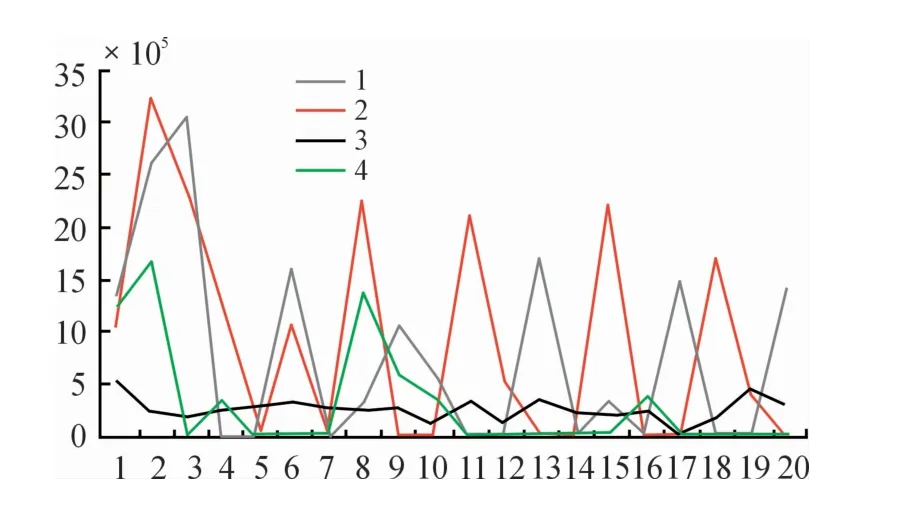
图2 非同类特征对比曲线
经特征提取后分别标上对应的类别标签,如表3所示,随机抽取了7个样本,为方便展示,表中数据集样本为T为20、n为5的数据,同时通过实验发现,T取不同值时,对分类精确度存在一定的影响,将在实验部分对比T和n取不同值时对分类的影响。

表3 数据集特征样本
1.2 集成加密流量精细化识别方法
1.2.1 现有典型分类器
随机森林主要是以bagging算法为基础,也是一种集成学习的算法,由多棵决策树构成,且具有随机性,从总体的特征之中随机选取特征,就可以很好地降低过拟合的现象,使其具有比较好的泛化能力,这是比较常用的算法,但在数据集样本噪声干扰比较大时,随机森林所训练的模型容易陷入过拟合。同时,当存在取值划分特征较多时就很容易对随机森林所训练的模型产生更大的影响,最终对模型的评估产生影响。
KNN(k-nearest neighbor)是一种常见的算法,因为它非常有效,所以经常在实验当中使用。它的原理也非常的简单,主要包括3个要素:K值的选择、距离的度量以及决策的规则。对于K值的选择通常采用交叉验证的方式选取最优K值,常使用的距离的度量方式是欧氏距离,分类决策规则往往是多数表决的方式。现将已有的带标签的数据集分布在空间当中。当需要预测新的数据时,将找到它在空间坐标之中对应的位置,并选取计算距离它最近的K个点,并且找到这K个点对应的类别,最终将预测的数据类别划归为这K个点种类别最多的一类。KNN虽然原理非常简单,但是存在一些缺点,当类别不平衡时对数据量稀少的类别预测准确率极低。所以相对来说仅仅使用某一种算法来分类,虽然能取得的效果还算不错,但是分类评估手段比较单一,如K近邻算法仅采用计算距离的方式来评估所属类别,决策树通过信息增益来进行分类。这种依靠单一度量属性的方法相对集成多种方法的方式来说鲁棒性较差,分类效果也不如集成之后的方法。
1.2.2 本文方法
主要思想是基于特征维度和模型集成2个部分去提升分类效果,①通过改变特征的输入组合以及数量,使得分类器输入不同的特征维度;②通过集成不同模型分类结果进行最终分类。集成分类方法如图3所示。

图3 集成分类方法框图
1.2.3 数据处理及特征选择
由于不同的基分类器对于特征要求不同,本文对于同样的数据特征根据不同的基分类器进行相应的特征处理,针对KNN基分类器对数据进行了归一化数据处理。
特征选择对分类器的结果起着至关重要的作用,对于每一份数据来说都拥有不止一个属性特征,但是部分特征对分类识别比较重要,同时也存在某些特征对分类有反作用影响。同时特征选择可以规避维数灾难,当对分类器性能要求较高时,选取其中比较重要的特征,可提高运行性能,简化分析。比较常见的特征选择方法分为3类,过滤式、包裹式、嵌入式。过滤式方法是先对数据进行处理,而不管后续使用的是什么分类器。包裹式方法是直接将学习器的性能作为特征的评价指标,但是当然它的开销也比过滤式的大。嵌入式方法是直接将特征选择与学习器结为一体,即在学习的过程之中自动进行特征选择,比如决策树等。
采用GBDT(gradient boosting decision tree)嵌入式的特征选择模块,综合考虑选择不同维度特征,从低维到高维,当n取20时,通过GBDT分类器的获取各特征在分类器中的重要程度,选择特征数量为11~20,共10种特征组合。
1.2.4 基分类器、权重选择以及集成决策
为克服单个分类算法度量单一,如KNN仅通过单一的距离度量手段,决策树通过信息增益或信息增益比的方式来度量。本文提出采用集成多分类器的方法,由于本文实验是针对YouTube视频流量具体精细化分类,通过选取其中一些针对YouTube视频流量具体精细化分类效果较好的分类算法,如KNN、随机森林、贝叶斯算法、决策树算法、GBDT(梯度提升树),将其作为基分类器,且从机器学习框架sklearn的model_selection模块中使用GridSearchCV调参算法选择出每个基分类器相对最优参数。选择KNN、随机森林、贝叶斯算法、决策树算法分类模型每种模型10个,4种算法分类模型总共40个模型分类器。将特征选择模块获得的10种特征组合输入各分类器,如分类器KNN1输入特征数11、分类器KNN2输入特征数12…分类器KNN10输入特征数20,随机森林、贝叶斯算法、决策树算法分类模型也类似。由于GBDT分类效果相对更好,将其单独拿出直接输入所有特征,并在之后权值模块将其权值设置为1 100 。
将数据集按0.7、0.1、0.2的比例切分为训练集、验证集、测试集。在权重选择模块上,设置阈值X,将分类效果相对较差的模型剔除不参与最终决策。将阈值X设置为80%,它最终决定有多少基分类器能参与决策,分类能力比较低的基分类器模型将会被剔除不能参与集成决策,否则将影响最终的集成分类效果。同时还为每个分类器在最终决策时设置权重,权值决策分类如图4所示。

图4 集成权值分类决策流程框图
例如基分类器1验证精确度91%分类样本1的所属各类概率(0.1,0.15,0.6,0,0,0,0,0,0.15,0),权值为(91%~80%)×100等于11,基分类器1分类结果为(0.1,0.15,0.6,0,0,0,0,0,0.15,0)×11等于(1.1,1.65,6.6,0,0,0,0,0,1.65,0)。将所有基分类器分类结果相加求和,将该样本分类为其中的最大值的类别。由于在分类实验中分类器GBDT明显效果好于其他分类器,且GBDT分类器只有一个,所以将权值部分的100加大为1 100。为了拉开基分类器之间的权值差距,权值计算部分使用了验证集精确度减去0.8,如直接使用验证精确度×100作为权值则各基分类器对最终决策影响几乎一样。为减少切分的偶然性,采用k折交验证进行权值更新,选择k次验证权值的平均为最终权值。
通过k折交叉验证根据分类精确度调整更新分类权值,分类效果相对较好的基分类器将在最终的分类决策时所占权值高一些。对于分类效果高于阈值,但相比对其他基分类器来说,它的效果较低时,将它的权值设置较低。总之,每个对于基分类器在总决策分类时所占的比重与它分类的准确度是成正相关的。本文设置k折交叉验证在每次验证之后,模型将对每个基分类器分类的验证后的效果进行权值反馈更新。在最终的决策预测时,将每个基分类器对于每个样本分类概率乘权值求和,概率最高则将其分为该类。本方法存在较好的可扩展性,即存在其他分类器模型在所分类的数据集取得较好的效果时,本方法可将它加入其中扩充基分类器。由于每个基分类器都参与决策,而不由某一分类器或者某一类分类器单独决定,最终分类效果一般比较理想。同时,基分类器间相互独立且输入特征互异,可高度并行训练,所以在训练时间上与训练单个分类器基本相同。
2 实验结果及其分析
2.1 本次实验所配环境
实验采用的设备:Windows10,处理器:4核Intel(R)Core(TM)i3-4170 CPU@3.70GHz,RAM:8.00GB,系统类型:64位,基于x64的处理器。同时还有其他的一些第三方软件:Wireshark、Python、pycharm、anaconda、Google浏览器、机器学习sklearn框架等。
2.2 实验结果与分析
2.2.1 评价指标
为了公正的判断本实验方法的有效性,采用准确率(accuracy)、召回率(recall)、精确率(Precision)、F1-score作为评价指标,可以通过混淆矩阵来进行计算准确率。准确率是被分类的样本的正确率,当正确率越高,一般来说就分类器越好,它主要反应分类器将正判别为正、负判别为负的能力。召回率主要是指某一类正确被分为该类的所占的比例。精确率表示正确预测为正的占全部预测为正的比例。F1-score它同时兼顾了分类模型的精确率和召回率。F1-score可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。

式中:TP(true positive)是将正类预测为正类的数目;FP(false positive)是将负类预测为正类的数目;TN(true negative)是将负类预测为负类的数目;FN(false negative)是将正类预测为负类的数目。
2.2.2 时间T取值长度不同之间的对比
实验通过选取n为20,分别选择时间长度T分别为5、10、20进行对比,图5为实验对比图,横轴为实验次数,纵轴为分类准确度,从图中可以看出,当时间T取值越大分类效果越好,且对分类准确度影响较大。同时从实验中可看出,如存在实时检测性能的要求,可将T设置为更小,当然分类精确度也相对较低。
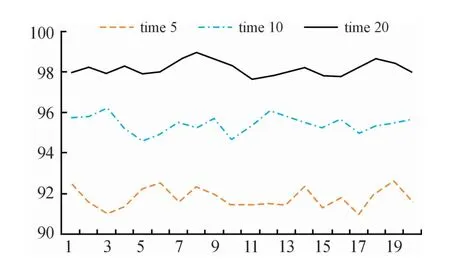
图5 T取不同值时分类效果对比曲线
2.2.3 提取特征数n不同之间的对比
实验在相同的流时间间隔内,通过提取流量特征n为不同数目,相互之间对比,得到适合的特征数目。主要设置特征数n分别为15、20、25。图6为不同特征数量之间的分类效果对比图,可以看出,当取不同的特征数目对分类效果的影响。15、20、25分别对应黄、蓝、灰线,经过20次实验分类效果的平均值分别为97.532 5、98.028 5、97.921,所以通过对比本文最终选取特征数n为20。
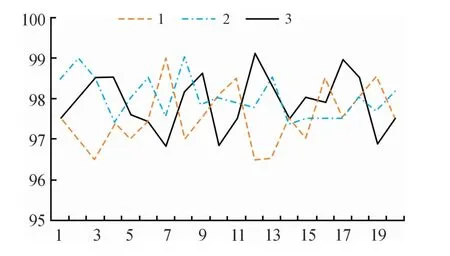
图6 不同特征数分类效果对比曲线
基分类器模型在验证集分类准确度删选阈值X选取实验对比如表4所示。主要参数如表5所示。

表4 不同阈值分类效果对比

表5 主要参数
其余非主要参数主要通过GridSearchCV调参算法自动选出,如KNN算法中的K的取值,给定GridSearchCV算法1~10的范围,步长为1,Grid-SearchCV算法最终通过范围搜索得到使KNN分类器分类效果最好的K值,如图7所示。
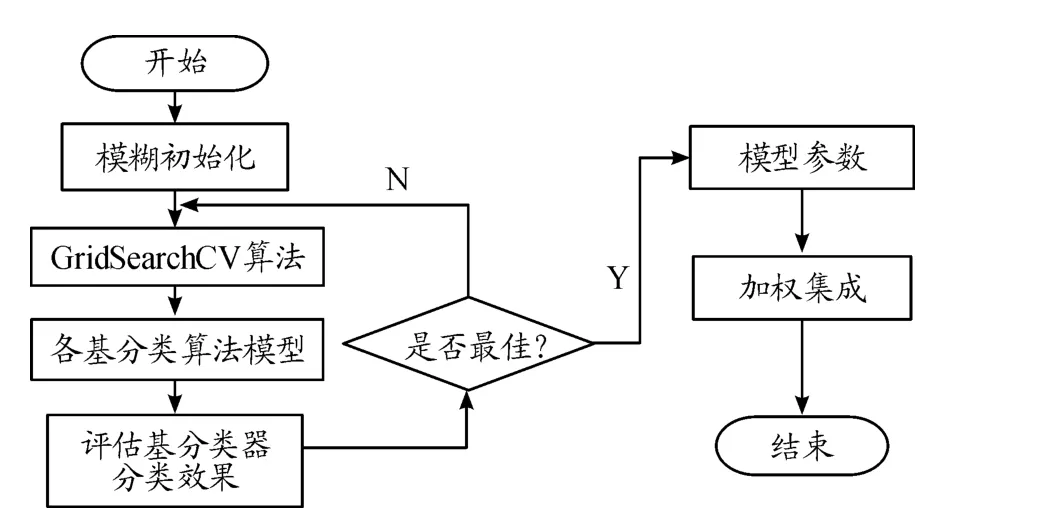
图7 模型流程框图
2.2.4 与其他分类模型对比
当前,由于在某一应用下加密流量再精细化分类的相关研究成果较为有限,据Ran等[21]的研究,本文将与其提出的方法进行对比实验。
从图8中可以看出,经过20次实验对比,本方法的准确率平均为98.01%,最高时可超过99%。而文献[21]中方法的平均准确率为95.26%,平均提升了2.75%。同时本实验还对召回率进行了对比,可通过图9发现本方法的召回率平均为98.092 5%也是优于文献[21]中的95.353 5%,平均提升2.739%。从图10的精确率对比实验中得到本文方法的平均精确率为98.672 5%,文献[21]的平均精确度为95.486 0%,本方法精确率明显高于文献[21],提升了3.186 5%。最后,对2个方法的F1-score进行对比,如图11所示,本文方法的平均F1-score为98.380 5%,文献[21]的平均F1-score为95.417 8%,本方法F1-score上也是高于文献[21],提升了2.962 7%。综合4项指标对比实验可以看出本模型基本优于文献[21]中的方法。
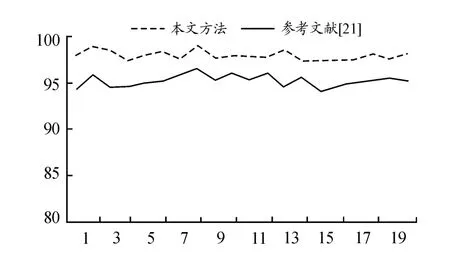
图8 不同模型准确度对比曲线
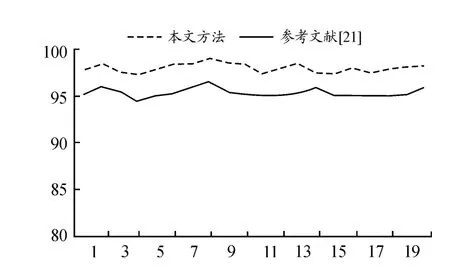
图9 不同模型召回率对比曲线

图10 不同模型精确率对比曲线

图11 不同模型F1比对曲线
3 结论
针对加密的YouTube视频流量进行精细化分类算法研究,主要有2个方面。特征方面:提出一种快捷且有效的特征提取方法,模型方面:通过改变特征维度以及集成不同模型的方式,最终实现在公开数据集上最高识别率可达99%的良好效果。本文特征提取可将时间T设置相对更大,取得相对更好的分类效果。同时,本方法存在的一些不足之处也会在后续的研究中去改进,通过实验发现将文中提取出来的特征用较深层的深度学习模型进行分类识别,也能取得非常好的分类效果。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
太原科技大学学报(2019年3期)2019-08-05
计算机应用(2017年4期)2017-06-27
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
信息安全研究(2016年10期)2016-02-28
