
基于特征相对贡献度对加权Mel倒谱的改进
2021-07-14 01:13:12王家盛郭其威马建敏
声学技术 2021年3期
王家盛,郭其威,吴 松,马建敏
(1. 复旦大学航空航天系,上海200433;2. 上海宇航系统工程研究所,上海201109)
0 引 言
声纹识别技术是生物识别技术的一种,借助人体生物特征或者行为特征对身份进行识别。与其他生物识别技术相比,说话人识别具有简便经济,隐藏性高以及获取成本廉价等优势,可广泛应用于公共安全、金融服务、智能硬件等应用场景。
在声纹识别中,影响识别率最大的就是特征参数的提取与选择。目前主流的说话人特征主要是提取以梅尔倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)为代表的基于人耳听觉感知特性的特征参数,类似的特征还有伽马通频率倒谱系数(Gammatone Frequency Cepstral Coefficients, GFCC)、耳蜗滤波器特征参数(Cochlear Filter Cepstral Coefficients, CFCC)等。其中,在大量的实验中已证实MFCC具有优异的识别率表现,故对MFCC特征参数的优化与改进一直都是说话人识别研究中的重点。目前以优化特征的方式去改善声纹识别性能的研究,主要可分为三个方向,即针对特征提取过程的改进、特征融合以及差异化特征分量。
在MFCC的提取过程中,实际上存在许多的简单设定,并不能很好地模拟人耳听觉效应。如传统的傅里叶变换仅能提供2π/N等分的固定频率分辨率,单个三角带通滤波器呈中心对称分布等。张怡然等通过引入多窗谱估计代替传统的加汉明窗求频谱的操作,减少了频谱估计的方差值,能使特征更好地反映出声道的结构[1]。章熙春等将弯折傅里叶变换(Wrapped Discrete Fourier transform, WDFT)应用到MFCC特征中以提高低频段的频率分辨率[2],邓蕾等采用弯折滤波器组(Warped Filter Banks,WFBS)基于人耳基底膜感知频率群在低频处密集、高频处宽松的分布特性,更好地模拟出人耳的听觉机理[3]。Chakroborty等提出了翻转梅尔倒谱滤波器组,目的是补偿抑制高频后的说话人信息缺失[4]。曹孝玉则进一步在翻转梅尔倒谱率滤波器的基础上提出混合型滤波器[5]。
为了弥补MFCC特征自身的局限,加入其他特征参数以提升系统识别正确率与应用场景,即特征融合。最典型的就是在静态 MFCC的基础上加入动态差分特征,补偿说话人动态行为特征。唐宗渤将 MFCC与离散小波变换结合得到离散小波加权系数(Discrete Wavelet Transform Weighted Coefficient, DWTWC)特征[6]。吕霄云等将短时能量信息与 MFCC特征作为混合参数应用于异常声音的识别[7]。沈凌洁等加入了韵律特征,在声调识别场景有不错的表现[8]。柯晶晶等将差分动态特征和加权后的Mel倒谱进行特征融合,提升了说话人系统的识别率[9]。茅正冲等利用Teager能量算子导出信号的瞬时相位信息,将其与耳蜗倒谱系数进行融合[10]。周萍等将MFCC与鲁棒性更强的GFCC参数相互融合,提高了特征的识别性能和抗噪性[11]。
常规的特征提取或者进行简单的特征堆叠势必会导致大量的信息冗余现象,大量实验已经证明,并不是特征的维数越高越好,各个维度的识别性能也存在不同的差异。故需要将识别性能强或者包含说话人身份信息的特征维度加强,让低识别性的特征权重减少或消失。魏丹芳等将一阶和二阶动态系数加权合并成一个向量,能够提高复杂场景环境下的分类正确率[12]。鲜晓东等基于Fisher比值对三类 MFCC特征参数进行筛选并组成一种混合特征参数,提高语音中高频信息的识别精细度[13]。魏君颖等也采用了此方法结合翻转梅尔倒谱系数选出区分度大的特征分量,提升了特征在噪声环境下的鲁棒性[14]。
本文基于强化特征差异的方法,借助 GMMUBM基线系统,对各维度MFCC分量的表征能力进行了分析,利用增减分量法定量计算出各维度对识别率的贡献度,基于此对MFCC特征进行了二次提取,改进了特征分量的权重系数,提高了说话人识别的准确率。
1 MFCC特征提取与改进
声道特性通常被认为是声纹识别中包含说话人信息量最多的部分,由短时功率谱的包络表征,即共振峰。如何准确地表达这个包络成为声纹特征构造的关键。
1940年Stevens和Volkmann对人耳主观感知频域的非线性进行了研究,给出了Mel标度与实际频率f的定量近似关系[15]:
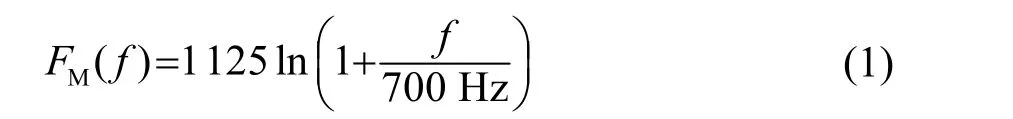
Mel频率倒谱系数(MFCC)作为人耳听觉感知特性的代表参数,能够更好地仿真人耳主观感知频域与实际接收的声音频率的非线性关系。
1.1 MFCC特征提取
MFCC特征的提取大致可以分为以下两个部分。首先,需要对采样后的离散数字信息进行预处理。预处理主要包含去除寂静帧、预加重、分帧和加窗等步骤。
预加重的目的在于弥补发声系统所抑制的高频分量损失,消除口鼻辐射端的影响,强化语音信号与声道间的联系,表达式为

其次,将预处理后的信息经过FFT变换可以得到信号的能量谱,将其作为基本特征传入Mel三角滤波器组中,将每个子带中的对数能量再进行一次离散余弦变换,可以得到一组系数。目前通常的方式是舍弃第1维参数,保留2~13维作为MFCC静态特征。若仅用静态 MFCC特征去训练模型会损失掉动态帧的信息,一般会在后面加入一阶差分动态特征和二阶差分动态特征。
通过上述的MFCC提取过程可知,存在以下两个步骤会导致特征的重复冗余:(1) 分帧步骤中为了保证短时范围内提取的特征平滑变化,需使相邻帧中有一部分重叠;(2) 为了弥补静态MFCC特征的表征局限,引入语音特征向量的动态变换特性,动态特征一定程度上能提升识别率,但其计算过程中重复调用了前后帧的信息,且过多的动态特征引入反而不利于模型的识别。
1.2 权重系数的改进
为了使提取后的特征最大程度地包含说话人个性信息,可以对原始 MFCC特征序列进一步处理,即进行二次特征提取,提取后的特征更具区分性。提高特征参数区分性的方法有两种:特征筛选和特征加权。
特征筛选,是指从原始特征参数中选取出表征能力强的部分分量进行模型训练与识别。常用Fisher比值(简称F比)来判断特征分量的区分能力,F比计算公式为

图 1为 TIMIT数据集下 30位说话人的静态MFCC各维Fisher比分布情况。
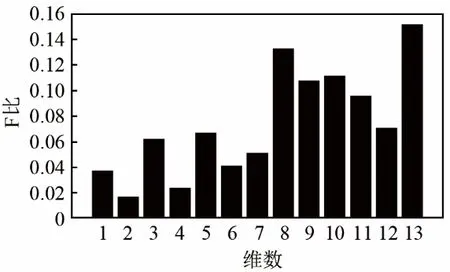
图1 MFCC 参数各维 Fisher 比Fig.1 Fisher ratios of various dimensions of MFCC
由图1可知,MFCC第13维的F比最高。但根据经验,高维特征分量值太小易受到噪声影响,区分性好的特征并非一定能训练出识别性能高的说话人识别模型,故特征与模型之间还存在一个匹配问题。虽然F比计算简便,但它假设特征分量之间是相互独立的,没有考虑到参数之间的相关性。
特征加权,是通过对特征参数内部设置不同的加权系数,放大或者缩小指定特征分量在识别时的作用。常采用升半正弦函数对 MFCC参数进行加权,公式[16]为
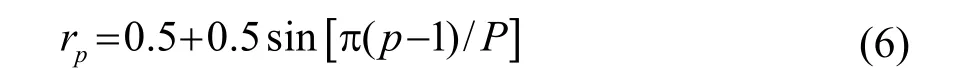
其中: p =1,2, … ,P,P是特征参数的维数。rp代表第p维分量上的权重系数。升半正弦函数的数学特征呈现两端低中间高,代表对易受噪声干扰的低阶特征分量以及数值相对较小的高阶分量进行衰减,对鲁棒性较好的中部分量则维持不变。但升半正弦函数仅粗糙地设置了权重系数,没有定量刻画出每个分量在识别时的重要度。
基于此,本文对升半正弦公式进行优化。首先通过实验得出各维特征分量对识别率的相对贡献度。再据此,定量计算出各个特征分量上的权重系数。具体步骤如下:
(1) 采用增减分量法[17]定量计算不同特征分量对识别率的贡献度,平均贡献度计算公式为
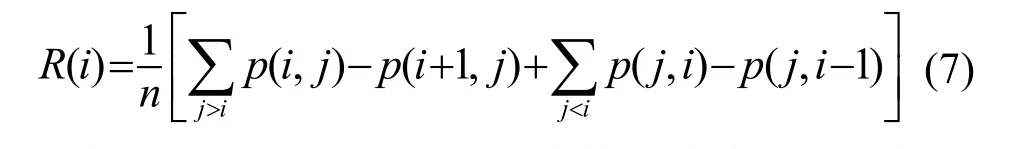
式中:p( i, j)是从i阶到j阶特征系数的识别率;n是倒谱阶数。
本文随机选取TIMIT数据集中100人的10句话作为实验数据集,从语音中提取13维MFCC倒谱参数作为静态特征,再分别作一阶、二阶差分得到各13维的动态特征,构成39维特征向量。依次计算 MFCC各特征分量的顺序组合在说话人识别系统中的识别率情况,结果如图2所示。
图2中每一条曲线的绘制方式如下,从下侧标签中选择第i维特征Ci作为MFCC组合特征中的起始特征分量,依次计算Ci~Ci+1,Ci~Ci+2,… ,直至Ci~C39组合下的识别率,并将结果依次连接形成曲线。考虑到单独一维特征在模型中的识别率太低,结果已经失去参考意义,加入会影响到贡献度的计算,故实验中所有测试特征向量的长度最低为2维。
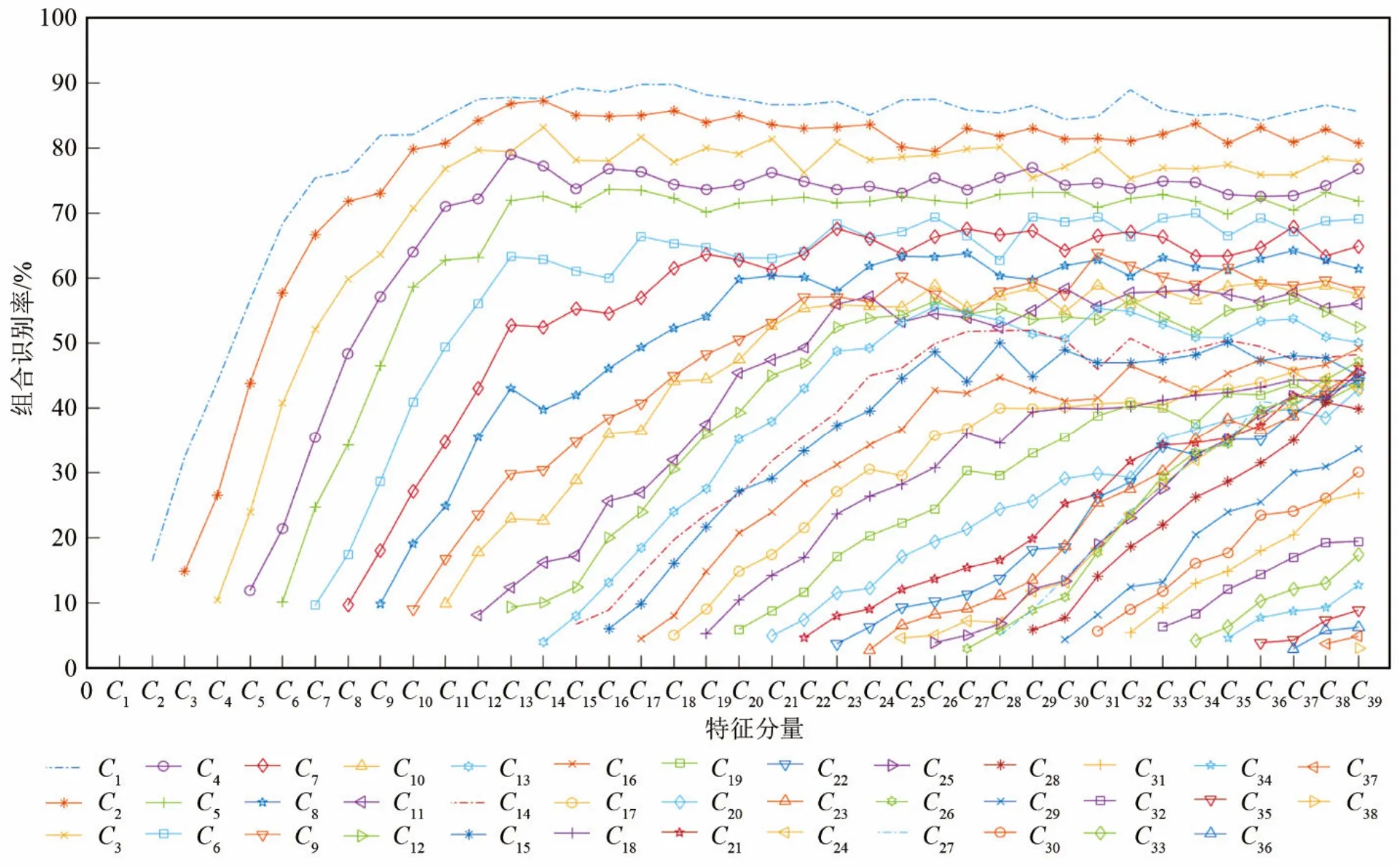
图2 MFCC不同起始特征分量的特征组合识别率Fig.2 Recognition rates of different combinations of MFCC with different initial features
根据式(7)计算出 MFCC各维分量的平均贡献度,得到贡献率柱状图如图3所示。
从图3中可以发现,第一,静态特征对最终识别率的贡献度明显大于动态特征对最终识别率的贡献度,贡献度越高,一定程度上反映的就是特征中包含说话人信息量也越多,此结果表明最有用的说话人的信息是包含在第 1~13维静态特征之中的。第二,从图3(a)中可以看出特征分量贡献度的分布规律并不完全呈现出一种半正弦趋势,反映的是一种类波浪分布,其中第 3~7维带来更高的识别率。第三,动态特征是在静态特征的基础上差分得到的,从实际的测试结果看,贡献度变化也符合前者的波浪走势。
(2) 仿照升半正弦系数的构造方式,对 MFCC的第1~13维特征分量计算权重系数,如图3(a)所示,第 11维特征分量的识别率贡献度最低,设置其权重系数为 0.5,用于保证倒谱分量不至于完全衰减;贡献度最高的第5维分量权重则设置为1,其余权重系数根据min-max标准化方法将数值放缩至[0.5, 1]区间内。
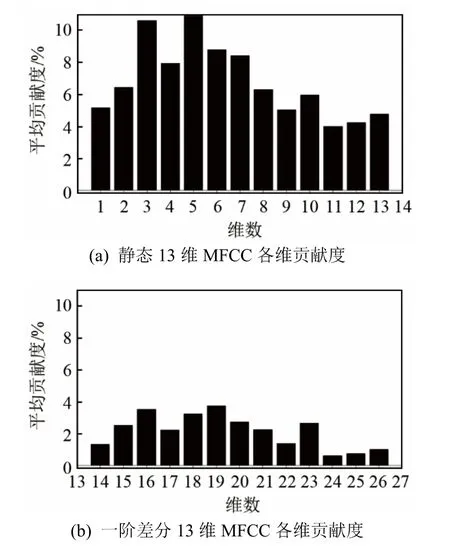
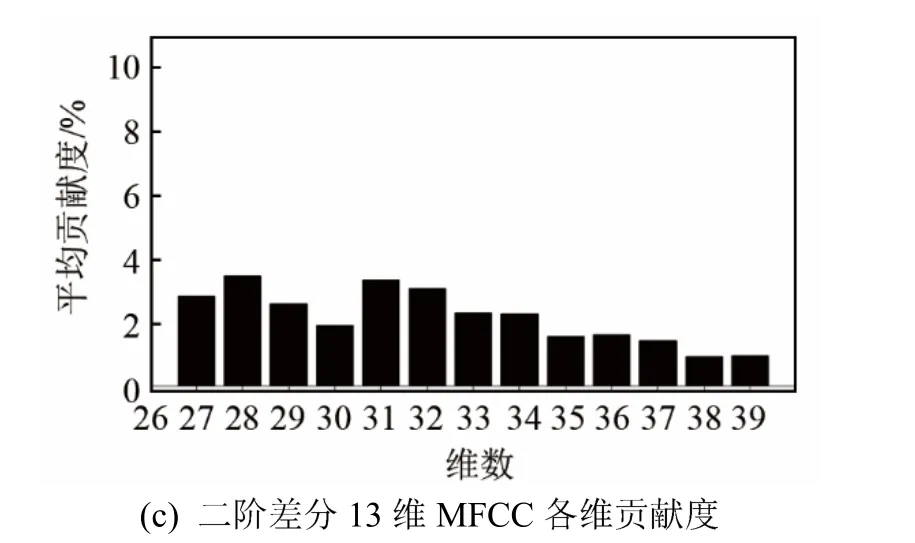
图3 MFCC静态及其差分特征对识别率的贡献度Fig.3 Contribution of MFCC feature and its differential features to recognition
为了泛化实验结果,同时也考虑到各分量本质上反映的是谱包络的变化信息,权重需平滑过渡才能更好地体现分量间的相互依赖关系。使用Matlab软件自带的曲线拟合工具箱对放缩后的权重系数进行傅里叶拟合,并将拟合曲线对应特征序号上的离散值作为改进后的权重系数,权重系数为
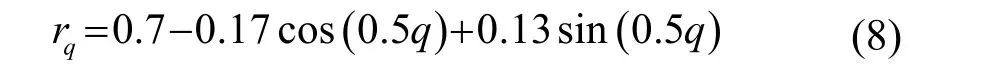
式中: q =1,2,… ,Q。rq代表第 q维分量上经过放缩和拟合处理后的权重系数。本文将此系数称为贡献度拟合权重系数。
图4比较了升半弦权重系数和贡献度拟合权重系数的分布特性。由图4可以看出贡献度拟合权重系数呈类波浪分布,相对于升半弦权重系数,能更准确地反映出各特征分量的识别能力表现。
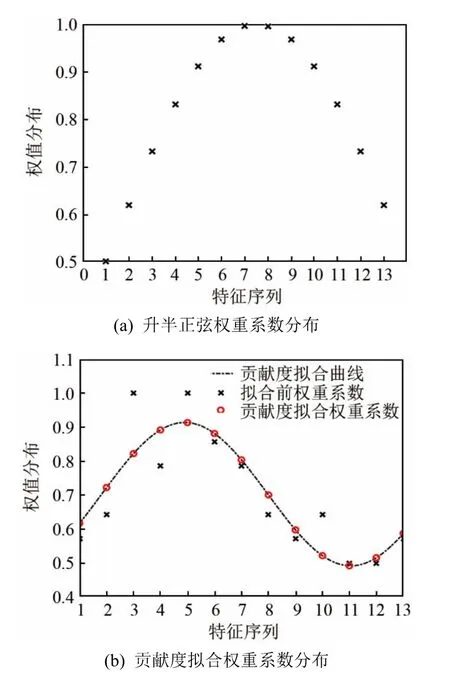
图4 不同权重系数分布对比Fig.4 Comparison of different weight coefficient distribution
(3) 将贡献度拟合权重系数对MFCC特征各个分量进行加权,即可得改进后的MFCC特征参数:

2 高斯混合模型
为了实现说话人识别,需要将提取后的特征建立相应的说话人识别模型,目前比较常用的理论模型是高斯混合模型(Gaussian Mixture Model,GMM)。在此基础上发展出来的联合因子分析(Joint Factor Analysis, JFA)[18]和全因子模型(i-vector)[19]都是对高斯混合模型的一种改进。每个GMM分量可以被认为是对隐性的声学特征进行建模,从统计意义上来说,同一个人身上提取若干段语音片段,并将从这些语音中提取出的特征放入相应的特征空间中,可以发现模型生成的方式是基本一致的。其中需要估计的多元混合高斯分布参数为
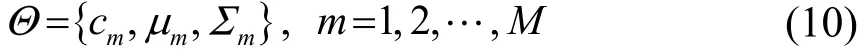
式中:M是高斯混合模型中分量的个数;cm是各个高斯分量的权重;μm是第m个高斯分量的均值;Σm是第m个高斯分量的协方差矩阵。
此外,为解决GMM由于训练语音不足导致拟合不充分等问题,挑选出除数据集外的所有说话人进行建模得到通用背景模型(Universal Background Model, UBM)[20],其本质就是一个与说话人无关的高斯混合模型。
说话人识别系统框图如图5所示。说话人识别系统主要由三个模块构成:特征提取、模型训练以及说话人识别。特征提取中,使用贡献度拟合权重系数对提取后的特征各分量进行加权。其中涉及的参数如下:帧长为20 ms,帧移为10 ms,汉宁窗,Mel滤波器的个数为24,选择信号的对数能量作为第1维特征分量,再与从语音中提取到的12维倒谱系数组合成为13维静态MFCC。
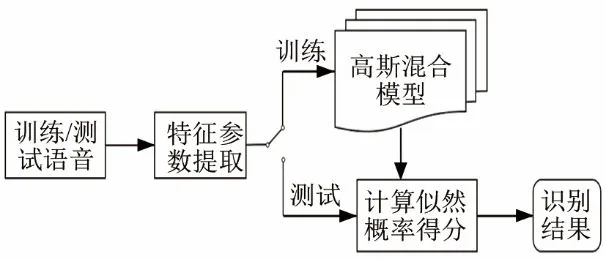
图5 说话人识别系统框图Fig.5 Framework of speaker recognition system
在模型的训练阶段根据UBM理论以及期望最大化(Expectation-Maximum, EM)算法生成每一个说话人所对应的高斯聚类模型,选定拟合高斯分布的数量为 32个。在识别阶段,计算待测语音特征在所有模型中的对数似然概率,选择得分最高的模型作为最终的识别结果。
最终的识别率计算公式为

3 识别实验与结果分析
本文采用的是 TIMIT语音库,是由德州仪器(TI)、麻省理工学院(MIT)和斯坦福研究院(SRI)合作构建的。由来自美国八个主要方言地区的630个人每人说出给定的 10个句子。其主要的特点是人声干净、发音清晰、没有环境噪声的干扰。从语音库中随机选择100人作为实验数据集,取第1句话作为训练集数据,其余9句话用于测试。
首先,使用 Matlab软件从语音信号中提取出13维MFCC特征向量,并用以下三种方法进一步提取特征:(1) 使用图1中计算出的Fisher比值进行分量筛选,并将其组合成基于F比特征筛选的向量。(2) 使用公式(6)作为特征参数的权重系数,计算得到基于升半正弦权重系数的特征加权向量。(3)同理,根据公式(8)可得基于贡献度拟合权重系数的特征加权向量。
其次,对每个说话人建立高斯混合模型,并根据测试语音的似然概率得分对识别率进行计算,改进后的特征在TIMIT数据集上的识别率结果如表1所示。
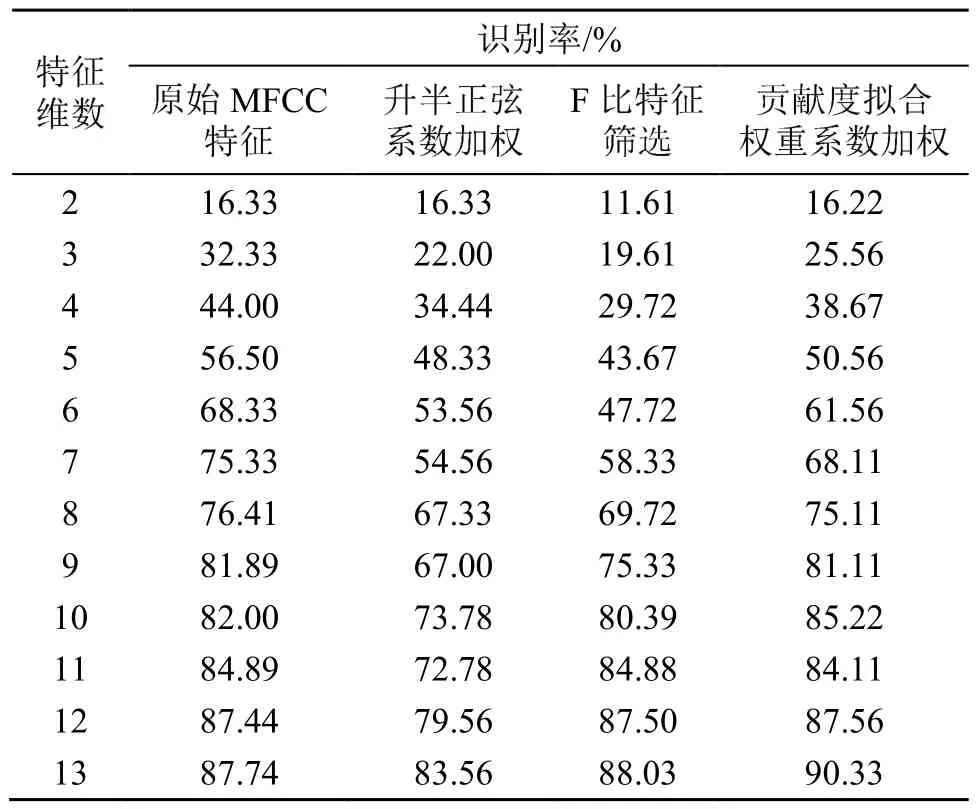
表1 几种改进方式的识别率比较Table 1 Comparison of recognition rates of different improvement methods
根据表1可以发现,基于Fisher准则的维度筛选在2~10维的特征识别准确率均不如原始特征,说明F比仅反映特征分量的区分性,筛选破坏了分量原有次序,只是将区分性较高的特征分量进行简单组合,并不能保证取得高识别率;特征加权,本质是差异化各维分量的表征能力,随着特征维数的增加,各维分量间的区分性被不断放大,将整体13维下的识别率作为特征加权改进后的效果进行分析。经升半正弦系数加权后的特征在TIMIT数据集上表现不是很理想,比原始MFCC特征分量的识别率低4.18个百分点,基于升半正弦的构造原理,原因可能是通过牺牲纯净语音集下一定程度的识别率性能,换取了特征在噪声环境下的鲁棒性提升;贡献度拟合权重系数以特征对识别率的贡献度作为加权依据,最终识别率比原始特征高出2.59个百分点。
4 结 论
特征提取是声纹识别中的关键一环,本文以传统的 MFCC特征为例,利用增减分量法对 MFCC各维特征分量对语音的表征能力进行了分析,并以此为基础改进特征的权重系数,提出贡献度拟合权重系数。与传统的升半正弦系数相比,改进后每维分量上的权重系数可以通过贡献度分布确定,能更准确地反映各维分量对识别性能的影响。实验结果表明,与基于Fisher比值的特征筛选和基于升半正弦系数的特征加权相比,经贡献度拟合权重系数加权后得到的特征能得到更高的识别率。
猜你喜欢
中学生数理化·高一版(2023年3期)2023-03-23 01:34:42
新高考·高三数学(2022年3期)2022-04-28 08:41:42
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
石河子大学学报(哲学社会科学版)(2019年3期)2019-07-27 01:33:48
中国生物医学工程学报(2019年4期)2019-07-16 08:04:10
中学生数理化·高一版(2018年6期)2018-07-09 06:00:56
制造技术与机床(2017年11期)2017-12-18 06:46:39
电力自动化设备(2015年4期)2015-09-28 02:42:54
电测与仪表(2015年16期)2015-04-12 00:44:26
