
面向数字电网的基于容器技术的边缘计算数据处理机制
2021-07-13 08:30:50杨漾敖知琪刘佳陈若江瑾
南方电网技术 2021年5期
杨漾,敖知琪,刘佳,陈若,江瑾
(1. 南方电网数字电网研究院有限公司平台安全分公司,广州510663;2. 南方电网数字电网研究院有限公司数字电网分公司,广州510663;3. 南方电网深圳数字电网研究院有限公司,广东 深圳518052)
0 引言
2018年4月,在全国网络安全和信息化工作会议上,习近平总书记提出“推动产业数字化,对传统产业进行全方位、全角度和全链条的改造,提高全要素生产率,释放数字对经济发展的放大、叠加、倍增作用”[1]。2019年1月,国家电网提出“三型两网”发展战略,明确提出运营好“坚强智能电网,泛在电力物联网”的发展目标,将充分利用移动互联、人工智能等现代化信息技术,实现电力系统各环节万物互联,建设具有状态全面感知、信息高效处理和应用便捷特征的智慧服务系统[2]。2019年4月,南方电网公司制定了《公司数字化转型和数字南网建设行动方案(2019年版)》,提出了数字南网的建设目标,利用数据驱动对公司业务、流程和服务进行优化完善,促进电网管理、业务和商业模式转型,提升公司生产力[3]。
麻省理工学院自动识别实验室的物联网合作研究计划(ICRI)中提出了物联网技术(Internet of Things,IOT),通过各种接入网与互联网,将各种信息传感设备(如传感器网络、射频标签阅读装置、条码与二维码设备、全球定位系统和短距无线自组织网络等)结合起来,形成的一个巨大智能网络[4]。大量“万物互联”的智能设备运行时会产生海量的数据,这些数据在云计算侧无法被高效的存储和处理,如何高效存储和处理数据是具备分布式处理能力的边缘计算模型[5]研究的关键问题。
在泛在电力物联网和数字电网中[6 - 7],物联网和边缘计算技术都是当前电力产业“源-网-荷-储”各环节信息流的采集、处理工作的最核心环节。数字电网是基于云架构与电网末端设备,通过物联网联接各类监测以及自动化终端,通过大数据中心和数字电网平台以构建电网管理、调度运行、运营管控和客户服务等一系列柔性应用。
本文针对数字电网场景,提出了一种基于容器技术的边缘计算数据处理模型,采用云边协同的边缘侧数据处理架构,对基于容器技术的边缘计算嵌入式数据库及云边数据同步的关键技术进行研究,提出一种根据事务操作优先级对事务进行数据筛选和重构机制,并进行基于容器技术的嵌入式数据库的性能研究测试及云边协同的数据同步试验研究。
1 数据采集及处理模型
边缘计算类型包括5G分片技术[8]、云计算任务迁移、视频监控[9]、环境及设备类监测[10]、智能分析和辅助决策类计算任务类型[11]。容器技术在边缘计算节点应用端能够有效隔离不同用户的使用环境及服务环境[12],数据处理框架具有敏捷、高效、可控制性强、可移植性强、标准化强、安全性强等特点。基于容器技术的典型边缘计算场景如图1所示。边缘计算设备可以产生和消费数据,功能包括数据通信、计算、归集及处理。为满足多源数据处理要求,边缘计算的核心处理设备通常采用容器[12]技术。容器内应用具有相对单一、不涉及复杂的跨数据库操作的特点。

图1 基于容器技术的电网边缘计算场景Fig.1 Edge computing scene of power grid based on container technology
多源数据采集及分析的边缘计算如图2所示。数据通过通信模块汇集至边缘计算设备中,边缘计算设备通过同步该操作完成云边数据协同操作。由于不同类型的应用容器存在相互隔离,因此在边缘计算的设备中需要建立板级嵌入式中心库,通过不同库表管理不同容器中的数据,跨容器的数据通过跨表进行操作。
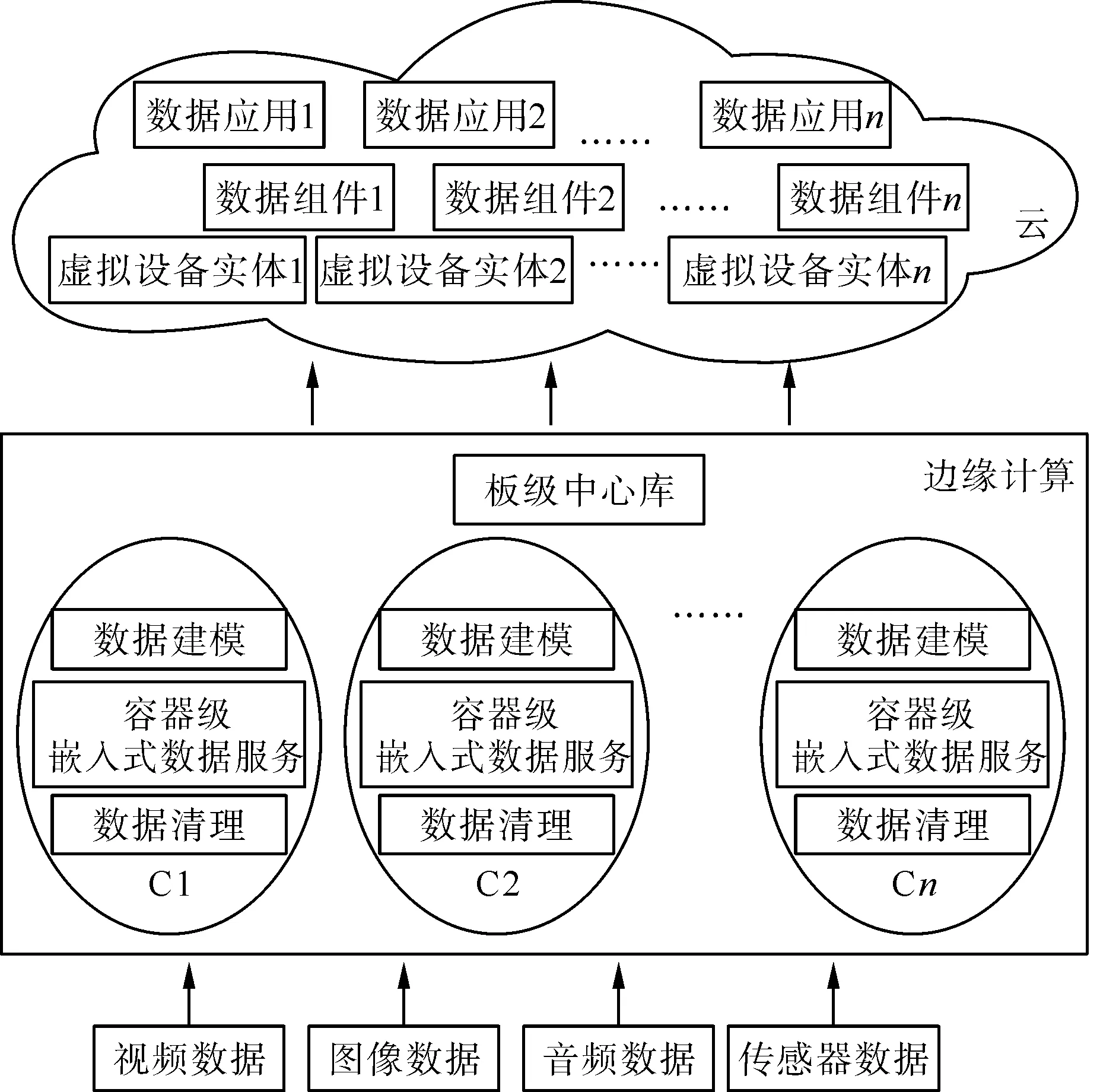
图2 基于容器技术的电网边缘计算数据处理模型Fig.2 Edge computing data processing model of power grid based on container technology
2 总体架构
本文设计了满足电网数据采集和处理要求的数据处理总体架构,如图3所示。通过嵌入式数据库完成边缘侧嵌入式智能终端设备的管理;为每一个容器内应用建立一张数据库对应表,通过嵌入式数据库服务的形式完成跨容器的多元数据库的数据管理;采用事务型处理机制进行数据消息包的传输,使用同步功能模块完成云边数据高效协同工作。

图3 基于容器技术的电网边缘计算数据处理总体架构Fig.3 Edge computing data processing architecture of power grid based on container technology
边缘侧数据采集终端的数据保存在嵌入式数据库中,需要对数据进行实时同步发送;当数据库执行事务提交操作时,数据同步模块将事务封装成特定的数据同步消息格式,使用加密算法对消息包进行加密,并将其存放在待处理的事务队列中,等待消息发送模块进行处理;消息发送模块使用TCP/IP协议将同步消息发送至目的端接收模块进行处理。
云端接收执行子系统在接收到源端消息后,对源端消息进行解密,逆向生成为事务SQL语句,在目标端数据库中执行完成信息同步,并修改已完成的同步位置。
3 关键技术研究及实现
在面向数字电网、跨容器技术的边缘计算数据处理机制中,基于容器的嵌入式数据库管理和云边协同的高效同步系统两项关键技术亟待研究,本文对这两项关键技术进行研究和实现。
3.1 边缘计算嵌入式数据库关键技术
使用嵌入式数据库对边缘侧数据进行管理,包括大对象数据的存储等,采用微内核和自优化技术,利用文件锁进行并发访问控制,设计并实现了云边协同的同步模块。

图4 基于容器技术的电网边缘计算嵌入式架构Fig.4 Edge computing embedded architecture of power grid based on container technology
3.1.1 数据库的微内核技术
在电网边缘侧设备上采用微内核技术实现数据库的轻量级应用,并紧缩其系统结构以满足电网设备应用的轻量化要求,同时可以依据应用的实际需求进行定制和裁剪,具有占用资源少的特点,运行时最低仅占用600 KB内存和500 KB的磁盘空间。
3.1.2 数据库的自主优化技术
通过分析电网边缘侧设备的硬件配置和业务场景,数据库系统采用自适应配置运行参数,包括工作线程、IO线程和SQL执行相关缓冲区等参数,使数据库系统运行达到最优配置。数据库系统自适应配置过程无需额外管理,使用API接口对数据库进行调用,达到合理调配设备资源的效果。通过细粒度内存管理机制、典型场景自优化等技术,减少了IO交互,降低了CPU占用,内存使用更加合理,能更加有效地进行数据库操作。由于不需要数据库管理员进行人工干预,因此能保证用户数据的安全性,实现无人值守运行。系统同时提供数据库备份和还原功能,降低数据损坏风险。
3.1.3 大对象存储技术
电网边缘侧设备需要存储视频等大对象数据,利用嵌入式数据库大对象存储功能实现电网边缘侧大对象的数据存储,并且根据设备的实际硬盘空间,实现管理GB级别的BLOB数据规模及总体TB级别的数据规模。
3.1.4 安全技术
采用基于关系模型的事务型嵌入式数据库管理系统,支持事务ACID特性,支持事务的提交、回滚功能,提供可串行化的事务隔离级,保证了数据库数据的完整性和一致性。嵌入式数据库采用WAL的先写入日志技术,数据库操作之前,先把内存中的数据快照保存到特定的磁盘空间,事务提交成功后才将内存中的数据缓存回写进磁盘,成功后删除数据快照;事务提交失败时,将数据快照重新加载入内存并回写进磁盘,同时删除快照。在嵌入式数据库中,还可以使用对称加密和非对称加密相结合的加密技术,对数据库的数据文件进行加密,对数据传输、数据库登录进行SSL加密,确保数据库访问和数据存储都处于加密状态,从而保证数据库的安全特性。
3.1.5 数据库的并发访问技术
为提高嵌入式数据库的访问效率,使用文件锁进行多线程间、多进程间的并发访问控制。多个边缘侧设备上的电网应用可以通过网络访问同一个设备上的嵌入式数据库系统,一台设备上的多个电网应用可以通过接口对同一个嵌入式数据库的数据文件进行读写操作,相互之间无需排队等待,提高了数据库访问的效率。
3.2 云边协同实时同步系统关键技术
3.2.1 边缘侧智能终端数据实时采集及同步
在边缘侧智能终端上,数据采集程序采集到数据后将其存储到嵌入式数据库中,数据同步功能模块实时对事务信息进行消息封装和加密处理,封装后的消息包在内存事务队列中等待网络模块进行发送处理。消息包内容包括事务操作ID、操作数据和操作时间等。
传统的基于软件的数据库数据同步技术,需要解析数据库日志文件才能对事务信息进行组装。本文的数据同步功能模块作为嵌入式数据库管理系统的扩展功能模块,可以直接获取内部事务信息,无需对日志文件的进行捕获解析,提高了增量数据捕获的发送效率。
3.2.2 执行子系统SQL逆向生成技术
数据同步的目的端不能直接应用源端所发送的消息包数据,需要逆向还原为SQL语句使用。目的端通过执行逆向生成的SQL语句,来实现事务消息同步的最后转化步骤。由于采用了SQL逆向生成技术,源端可以像对待常规应用系统一样,采用通用的方式对数据进行同步存储。
3.2.3 事务筛选及重构
为保证源数据库和目标数据库的数据一致性,数据同步系统以源数据库的事务为最小复制单位,严格按照源数据库事务顺序进行实时数据复制,保障目标数据库与源数据库事务的完整性和一致性,确保目标数据库符合源数据库的事务逻辑。同时,由于在边缘侧采集的数据并不具有完全的应用价值,使用传统方法需要对数据进行汇总处理,过滤无用的数据。本文的数据实时同步系统可以通过构建同步规则对事务进行重构、筛选来达到提前过滤无用数据的目的。本文数据实时同步系统以事务为最小粒度的同步模型,给事务重构和筛选提供基本保证。
3.2.4 通信消息加解密
为保证边缘侧数据传输的安全性,在边缘侧源端,同步功能模块在获取到应用操作的事务信息后,需要对事务信息进行加密处理;网络发送模块通过网络来传输加密的事务数据;在云端汇总库中,日志接收执行子系统,接收到加密的消息后,使用解密算法进行解密,完成数据同步。
3.2.5 同步事务一致性保障技术
数据同步以源数据库的事务为单位,严格按照终端业务系统事务顺序实施数据同步,保证了目标端数据库与源终端数据库的事务级完整性和一致性,确保目标端数据库符合源业务系统的事务逻辑。数据在传输过程中可能因为网络故障而导致传输中止,为保证传输的数据无丢失,使用检查点机制实现数据断点续传。数据断点包括两部分,即源端事务抽取位置检查点和目标端执行已同步位置检查点。源端模块与目标端模块使用完备的消息应答机制来保障数据传输的可靠性和完整性。源端模块在得到确认消息后才认为数据传输完成,否则将自动重新传输数据。
4 试验
4.1 试验环境介绍
试验在数研院GEM1901边缘计算开发板上进行,该核心板具有双核800M主频的CPU,1G RAM,8 GByte ROM,128 GB SD高速存储卡,千兆网卡,开发板装有SSX1805型国密型号安全芯片。使用Ubuntu 16.04片上操作系统,嵌入式数据库DMEDB及嵌入式数据库DMEDB同步功能模块、嵌入式数据库目的端同步工具进行软件支撑。
使用x86架构的Intel Core i7的PC机作为云端数据库载体,主频3.6 GHz 16核CPU,内存128 GB,1T固态硬盘,以太网千兆网卡,Ubuntu 16.04版本操作系统,DMV7.6企业版关系型数据库,并安装达梦同步软件。
4.2 容器与板级中心库试验
针对面向容器的嵌入式数据库,开展了读写性能测试。在不同数据量下,分别对查询、写入、导入、导出性能进行了重复测试,测试结果为100次操作的均值,结果如图5所示。

试验结果表明,嵌入式容器级数据库能高效的完成查询、写入、导入及导出的常规数据库操作,性能达到同等条件下传统数据库操作性能的88%以上。在性能相差最大的为10 000条数据写入的试验中,容器操作与原操作性能比为88.85%;在性能相差最小的为1 000条数据的导出试验中,容器操作与原操作性能比达到97.08%;在各数据规模下,查询性能可达93%。
4.3 数据同步试验
数据同步试验基于嵌入式数据性能测试的表及数据,通过同步软件,把边缘侧设备上的数据同步到云端的关系数据库中,通过与传统方式进行对比,验证同步软件性能。数据同步中,分为全量同步和增量同步2种方式。在全量同步中,传统方式需要获取数据阶段、网络传输阶段和云端数据库加载阶段3个阶段;增量同步由于需要涉及数据时间戳、MD5校验等环节,传统方式无法完成增量同步,因而对比试验采用直接从嵌入式板端同步相应数据量到云端的方式进行对比。本研究对比了全量同步性能测试,并开展了云端和边缘侧的增量同步测试。
4.3.1 全量同步性能测试
在全量同步性能测试中,传统同步方式以时间戳方式获取增量数据与同步软件进行同步性能对比。本试验基于嵌入式数据,分别构建5张表,在100 MB、200 MB、400 MB、600 MB、800 MB 5种不同规格的表进行。试验表明,传统的导出方式中,嵌入式数据库的表现:获取数据阶段读取性能不低于80 MB/s,写入性能不低于40 MB/s;在边缘计算核心板和云端的网络传输阶段中,网络传输性能不低于45 MB/s,云端数据库加载的性能不低于200 MB/s,测试结果如图6所示。

图6 性能测试结果示意图Fig.6 Schematic diagram of performance test results
试验表明,通过同步软件方式进行的“边缘同步组”的数据远远好于“传统导出组”的数据,通过同步软件进行全量同步的数据中,在400 MB有个拐点,这说明在通过同步软件进行云边协同操作时,当数据量在200~400 MB的区间中,传输IO的速率在该数据量下达到峰值,后续操作的时间基本随着数据量的增加呈线性增加。
4.3.2 增量同步性能测试
增量同步性能测试分单表单行插入的数据同步、单表批量插入的数据同步、4表单行插入的数据同步以及4表批量插入的数据同步4个场景,批量插入的数据条数均为500条。记录数据在边缘侧提交后,数据完全同步至中心端的数据延迟时间。同步软件增量同步至云端的时间和嵌入式数据库增量同步到云端的时间公式如式(1)—(2)所示。
Tq=Ts+Tt+Tw
(1)
TE=Ts+Te+Ti
(2)
式中:Tq为同步软件增量同步至云端的时间;Ts为查找增量数据时间;Tt为同步传输时间;Tw为云端中心库写入时间;TE为嵌入式数据库增量同步到云端的时间;Te为增量数据导出时间;Ti为云端中心库导入时间。
由于传统嵌入式数据库无法完成增量数据查找及选择,将其取0,嵌入式数据库增量同步时间约等于从嵌入式数据库导出等量数据的导出时间加上云端侧的导入时间。试验结果如表1所示,其中表格列表示边缘侧设备嵌入式数据库和云端关系数据库数据同步延时。试验结果表明,同步软件在进行增量同步时,其效率远高于传统数据库导入导出的方式,500条数据规模情形下,性能提高3倍以上。

表1 增量同步性能测试结果Tab.1 Performance test results of incremental synchronization
5 结语
本文深入研究云边协同实时同步系统关键技术,提出了一种云边协同的数据处理架构,对边缘侧智能终端数据实时采集及同步、执行子系统SQL逆向生成、事务筛选及重构、通信消息加解密、同步事务一致性保障等关键技术进行研究,实现了一套云边协同的数据同步解决方案。试验表明,本方案能有效地实现结构化和多媒体数据的实时同步,满足终端硬件环境下的应用要求。
猜你喜欢
现代计算机(2023年20期)2024-01-08 12:14:06
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
中国交通信息化(2021年6期)2021-08-13 09:03:50
青年文学家(2020年28期)2020-11-02 13:20:37
东坡赤壁诗词(2020年3期)2020-07-04 02:50:05
河南水利年鉴(2020年0期)2020-06-09 05:43:44
现代装饰(2020年5期)2020-05-30 13:01:58
丝路艺术(2017年5期)2017-04-17 03:11:50
初中生(2017年3期)2017-02-21 09:17:43
