
一种面向符号社交网络的负链路预测方法
2021-07-12 08:00:10薛苗苗刘沫萌
西安工程大学学报 2021年3期
王 伟,薛苗苗,刘沫萌
(西安工程大学 计算机科学学院,陕西 西安 710048)
0 引 言
在现实社交网络中,用户之间的关系大致分为正面和负面,即节点之间的链路可以用正负号标识,这种既有正链路又有负链路的社会网络被称为符号社交网络。其中正链路表示正关系,如朋友、信任等关系;而负链路与正链路刚好相反,负链路表示负关系,如敌人、不信任关系等。目前,关于符号社交网络的负链路预测研究相对较少。其主要原因在于:第一,大多数社交网络更倾向于对用户表达正面评价,而负面预测的数据集因涉及隐私等原因往往来源有限,这使得负链路的预测未得到足够重视;第二,正面关系在网络中具有传递性,而负面关系无法在网络中进行传递,这给负链路预测的研究带来很大的挑战。尽管如此,负关系的挖掘及预测在许多现实应用中具有极其重要的意义。例如,负面链接的预测可以提高推荐系统的性能[1-2],有助于在社交网络平台上寻找可信的用户,还可帮助用户避免欺诈或者矛盾爆发[3]等。
近年来,国内外学者主要从基于结构平衡理论和基于社会地位理论2个层面展开研究。在2种基本理论中,结构平衡理论是人们对事物态度的平衡模型,该理论认为[4]:①我的朋友的朋友是我的朋友;②我的朋友的敌人是我的敌人;③我的敌人的朋友是我的敌人;④我的敌人的敌人是我的朋友。其中包括4种可能有的三元组关系,分为2种平衡关系和2种不平衡关系。而社会地位理论反映的是正负号的地位高低关系,即地位低的指向地位高的属于正方向,而地位高的指向地位低的属于负方向[5]。
针对上述2种理论,文献[6-7]通过网络拓扑分析了符号关系,并提供了有用的见解。在文献[8]将2种理论结合起来在网络结构中进行符号预测,通过提取出23个特征来预测社交网络中可能存在的正面和负面链接,其中包括基于度的7个特征和基于三角关系的16个特征,这是最早的基础预测方法,但只是利用了局部信息[9]。在CHIANG等探索了提取网络全局结构特征的方法之后[10],YE等也从全局的角度并提供了新的迁移学习的网络结构信息提取方法[11]。张维玉等对连边符号机理进行了深入分析,融合出一组最能反映连边符号的特征,实验表明较已有模型有了更好的预测效果[12]。上述研究都是使用了网络结构特征进行预测的,但仅利用这些网络结构信息仍存在一定的局限性[13]。例如,根据网络上下文也可挖掘出不同的特征信息[14],故应结合网络上下文的信息综合起来进行预测。ZOLFAGHAR 等将4个关键因素映射到相应的可评估特征中进行符号预测,并根据结果发现了基于结构的特征比上下文更重要[2]。BORZYMEK等结合网络上下文的信息将特征分为2类,一类是基于图的特征,一类是基于评述的特征,两者结合达到了较好的效果[15]。
为克服现有负面数据集信息较少的问题,文献[16]提出了负链路预测的NELP框架,利用网络中的正链接信息和以内容为中心的交互信息来预测负链接。文献[17]提出基于元路径特征的方法,考虑路径长度对链路预测问题的影响,从而提升了负链路预测的效果。
本文以文献[8]提出的负面预测方法为基础,结合现有的负链路预测方法,从改进预测性能的角度,考虑符号不同方面的属性,抽取出更能反映节点和边之间的符号特征组合,该方法可以归类出4种与负符号相关的特征,将这4类特征进行融合并利用逻辑回归算法进行实验,提高了负链路预测的性能。
1 方法的提出
1.1 问题描述
给定一个有向图G(V,E,P),其中V表示节点集,E表示边集,P表示中边对应的符号集。P(i,j)∈P且P(i,j)={+1,-1,0}。用ei,j表示从i到j的边,其中ei,j∈E,当ei,j=1时,节点i到j之间存在链接;当ej,i=1时,节点j到i之间存在链接;当ei,j=ej,i=0时,节点i和j之间不存在链接。P(i,j)=+1表示边ei,j的符号为正,P(i,j)=-1表示边ei,j的符号为负,P(i,j)=0表示边ei,j的符号未知。若其中一条边符号未知,则可根据周边的网络链接状态来进行预测。本文目标就是要预测出P(i,j)=-1,即节点i到j之间存在负链接。
1.2 系统框架
负链路预测主要是预测未来哪些边存在负面的关系,本文利用机器学习的技术将其看作有监督学习的任务进行研究。所提出的链路预测框架如图1所示。

图 1 链路预测框架图Fig.1 Link prediction framework diagram
图1中,系统首先对用户的节点特征、结构特征、相似性特征和评分特征等4类特征进行提取;然后对特征进行融合,最后将问题看作为二分类问题来判别2个用户是否存在负面关系[18],即预测社交网络中存在负面链接的可能性。
2 特征构造
特征提取与构造是链路预测重要的部分之一[19]。本文抽取4大类特征,如下所述。
2.1 节点特征
依据文献[20]对节点特征的描述,本文对于节点i不信任的节点集合(负出度)和不信任节点j的节点集合(负入度)定义如下:
O-(i)={j:(i,j)∈E,P(i,j)=-1}
(1)
I-(i)={j:(j,i)∈E,P(j,i)=-1}
(2)
O+(i)={j:(i,j)∈E,P(i,j)=1}
(3)
I+(i)={j:(j,i)∈E,P(j,i)=1}
(4)
式中:O-(i)和I-(i)分别为节点i不信任的节点集合,不信任节点i的节点集合;O+(i)和I+(i)为节点i信任的节点集合,信任节点i的集合。进一步地,通过特征变换构造出以下节点度的特征。
1) 节点i的负出度占比C1(i)。C1(i)表示节点i出发的链接中负链接的比例,当节点i出发的正负链接总数相同时,负链接的出度数越大,越有可能形成负链接,可表示为
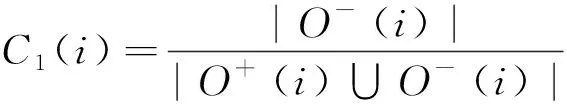
(5)
2) 节点j的负入度占比C2(j)。C2(j)表示指向节点j的链接中负链接的比例,当指向节点j的正负链接总数相同时,负入度越大,越有可能形成负链接,可表示为
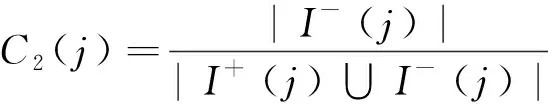
(6)
2.2 结构特征
根据2种基本理论,链接的结构信息影响着符号预测。因此,本文使用三元组比率来表示链接的结构信息。由于文献[8]证明了不平衡的三元组将会导致符号社交网络的不平衡,故本文采用负三元组特征。若节点i和j与共同邻居持相反的态度,用社会心理学结构平衡理论解释就是“我敌人的朋友是我的敌人”,或者“我的朋友的敌人是我的敌人”。从该理论说明三元组关系中至少有一正一负2种边的符号。为了在现实符号社交网络中能保持平衡,则三元组就应当保持平衡。对于节点i、节点j和节点k之间的三元组关系(i,j,k),如果(i,k)的符号与(j,k)的符号不同,为了保持三元组(i,j,k)平衡,符号应为负,但该三元组为正三元组;否则,三元组(i,j,k)不平衡,称为负三元组。(i,j)的负三元组比是指节点i、节点j及其公共邻居m之间的所有三元组中节点i、节点j及其公共邻居之间的负三元组的比率,可表示为

(7)
式中:m为节点i和节点j的公共邻居;|M|是i和j的公共邻居的数目;I(·)为负三元组的数目,这需要s(i,k)和s(j,k)的符号不同。
2.3 相似性特征
本文采用余弦相似性表示两节点间的相似性程度,根据2种负相似度[21]和Salton指标来衡量,具体如下所述。
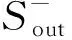

(8)
(9)
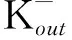

(10)
式中:ri,o和rk,o分别为从节点k和节点i指向节点o的链路符号;Oout为i和j都给出链接的节点集。
(11)
式中:ro,j和ro,k分别为从节点o指向节点j和k的链路符号;Oin为j和k都接收到的链接的节点集。
2) Salton指标。Salton指标是度量节点x和y之间的余弦相似性的指标[19],可表示为
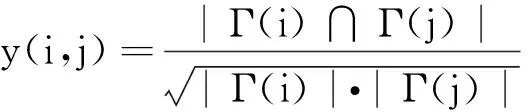
(12)
式中:Γ(i)是节点i的邻居集合,|Γ(i)|是节点i的邻居数。
2.4 评分特征R(i)
根据用户接收的负面意见和正面意见,如果负面意见所占的比例越大,则该用户越容易与其他人产生负面链接。评分特征采用负面评分比R(i),可表示为
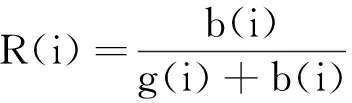
(13)
式中:b(i)为节点i接收到的负面意见数;g(i)为节点i接收到的正面意见数。
基于上述4类特征,符号预测模块采用Logistic回归模型,将从节点i指向节点j的链路符号分为2类:正的或负的。符号预测函数可表示为
(14)

3 算法描述
本文采用的面向符号社交网络的负链路预测算法描述如下:
1) 加载数据集N,在矩阵(N1,N2,…,Nn-1)上对数据进行处理,得到新的矩阵M;
2) 对特征进行提取,得到特征矩阵P(Mi,Nj);
3) 应用逻辑回归分类器生成训练集和测试集;
4) 根据训练集训练分类器,进行负链路预测。
在算法中,首先加载数据集,进行数据预处理步骤,包括对数据进行清洗以及标准化等。接下来,对特征进行提取,构造节点对的特征向量;然后对给定的数据集利用交叉验证法对数据集进行划分,划分为训练集和测试集(8∶2),反复进行训练与测试,根据训练集选择逻辑回归分类器进行预测,进行最终的负链路预测。算法从时间复杂度上来说,实际环境中,由于节点的度数遵循指数分布,所以网络中的平均链接个数不多且不会迅速增加。
4 实 验
4.1 数据描述
本文采用Epinions和Slashdot来验证该方法的性能。数据来自符号网络常用数据集Epinions和Slashdot且公开,Epinions数据集是一个典型的消费者评论网站,用户可以在该网站中创建对其他用户的信任和不信任链接,其中1表示信任,-1表示不信任[22]。Slashdot是一个技术新闻评论网站,用户可以通过评论和回复帖子对用户表达积极或消极的意见,从而建立朋友或敌人的关系。对这2种网络数据集进行数据预处理,过滤掉没有任何积极或消极的联系,得到的基本数据集信息进行了统计。其中,Epinions数据集的节点数为131 828,正链接和负链接数分别为717 702和123 670,三角形数为4 910 076;Slashdot数据集的节点数为82 144,正链接和负链接数分别为425 072和124 130,三角形数为579 565。
4.2 系统评估指标
本文采用的符号预测方法属于二元分类,对于已有的真实符号社交网络中负链接的数量要远远小于正链接的数量,采用综合评价指标F1分数和精确率、召回率以及准确率来作为评价标准,将负链接作为正元组。通常用一个混淆矩阵来表示分类器的性能。其中TP是被正确识别的正元组的数量,FN是被错误识别为负类的正元组的数量,FP是被错误识别为正类的负元组的数量,TN是被正确识别的负元组的数量[23]。常用的分类器性能评价指标包括本文要采用的精确率P、召回率R、准确率A以及F1分数,分别用如下公式计算:
(15)
(16)
(17)
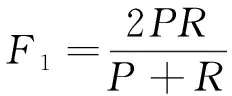
(18)
4.3 实验结果与分析
为了验证特征融合方法的有效性,本文考虑将文献[8]经典方法中最基本的23个特征向量(all23)与本文提出的7大特征向量(new7)组合进行对比,在Epinions和Slashdot上进行测试,利用十折交叉验证的方法,进行10次训练-测试过程,最终以计算10次过程中性能指标的平均值作为结果。需要注意的是,本文实验所采用的特征与文献[8]所采用的特征显著不同,所以需要验证本文特征的有效性。利用上述4种指标进行评估,结果如图2、3所示。
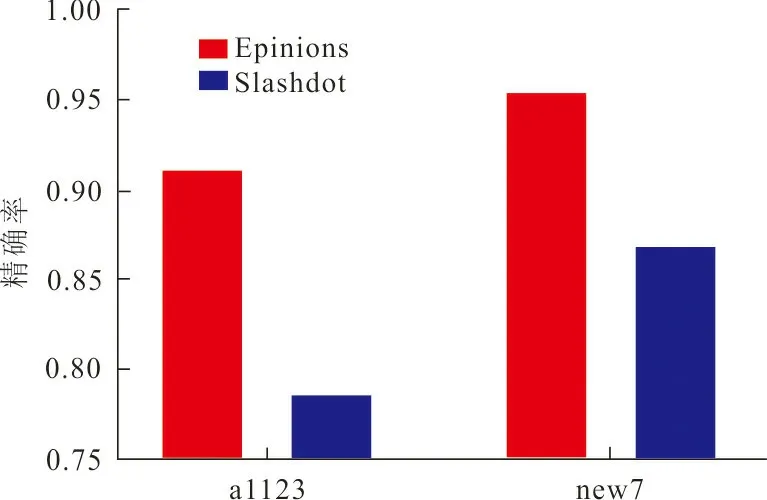
(a) 精确率
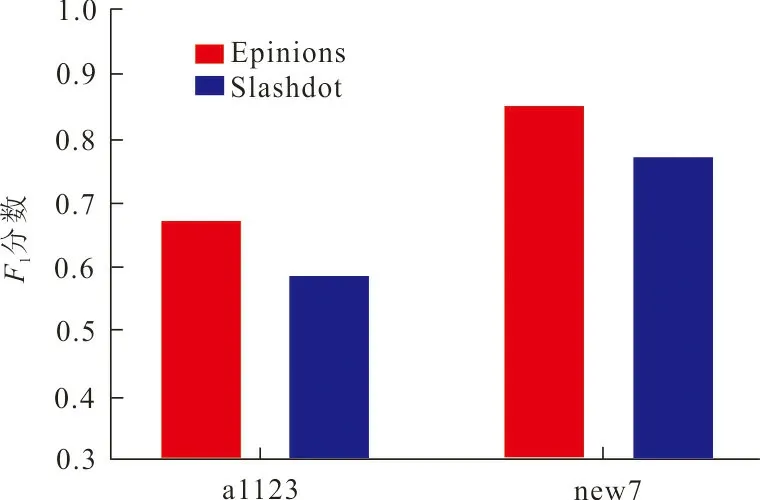
(b) F1分数图 2 精确率和F1分数的预测结果对比Fig.2 Comparison of prediction results of precision and F1 score

(a) 准确率
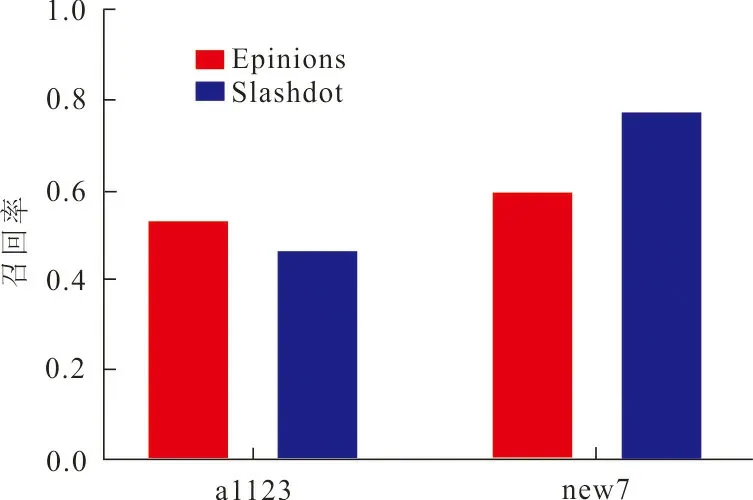
(b) 召回率图 3 准确率和召回率的预测结果对比Fig.3 Comparison of prediction results between accuracy and recall
在图2、3中,比较了4种不同的评价指标在2个不同的数据集上测试的效果。在本文构造的特征向量组合new7的性能相比于最初的23个特征向量all23的性能都有了一定的提高,其中精确率和F1分数提高比较明显。在Epinions和Slashodot数据集上,精确率由原来的0.910 8、0.786 7提高到0.951 6、0.868 3,精确率在2个数据集上分别提高了约4.5%和10.4%,F1分数由原来的0.670 4、0.589 4提高到0.853 4、0.775 3,分别提高了约27.3%和31.5%。这是因为与本文使用的特征向量有很大关系,在实际的符号社交网络中,各个特征指标对链接的形成做出的贡献不同,最初的23个特征向量中并不是所有的特征都对链接的形成起着一定的作用,本文对特征的规模进行缩小,抽取出更能反映节点和边的特征组合,可见对特征进行选择是非常有必要的。
另外,为了分析评分特征对结果的影响,本文将准确率和F1分数作为评价标准,分别在数据集Epinions和Slashdot上进行评估,其结果如图4所示。
由图4可以看出,不管是准确率还是F1分数值,在去掉评分特征之后,预测效果有所下降,这说明本文提出的评分特征可有效提升链路预测的效果。这是因为负面交互与负面链接大多有着相关性,用户对彼此表达负面评分的数量越多,会促进负链接的形成。一方面说明了提取符号网络中上下文信息特征是有效的;另一方面验证了将网络结构和上下文信息进行融合能够更好的进行预测。此外,缺少评分特征对应的预测结果相比采用全部特征的预测结果降低的幅度较低,这可能是因为提供连边信息具有重叠性,特征之间也存在着许多相似性。

(a) 准确率
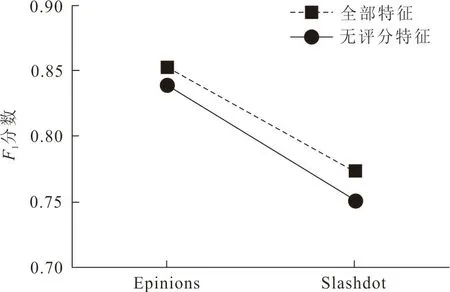
(b) F1分数图 4 评分特征对准确率和F1分数的影响Fig.4 The impact of scoring features on accuracy and F1 score
综上所述,与已有的方法相比,该方法具有更好的预测效果,说明将网络结构和上下文信息融合在一起可获得更多有利于符号预测的信息,预测结果显著提高。
5 结 语
针对符号社交网络的负链路预测研究中存在未充分利用各个特征的优势,以致预测性能较低的问题,本文在已有特征的基础上进行融合,提出一种新的面向符号社交网络负链路预测方法,并在2个真实的社交网络数据集上进行了有效性验证,达到了性能提升的效果。该方法挖掘出了符号形成的几个关键因素,可明显改善负链路预测的效果。由于在不同网络中特征对链接信息形成所做的贡献有所差异,在后续研究中,将把挖掘其他有效的特征以及对特征进行重要性排序作为重点。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:18:10
计算机与数字工程(2023年5期)2023-08-31 08:40:44
移动通信(2021年5期)2021-10-25 11:41:48
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
能源(2018年8期)2018-09-21 07:57:22
知识经济·中国直销(2018年6期)2018-06-29 07:55:52
中国交通信息化(2014年3期)2014-06-05 03:07:09
现代防御技术(2014年6期)2014-02-28 18:26:29
自动化与仪表(2014年10期)2014-02-26 08:21:17
