
对抗训练在人脸关键点序列稳定化问题中的应用
2021-07-08 09:05何卓骋
小型微型计算机系统 2021年7期
何卓骋,李 京
(中国科学技术大学 计算机科学与技术学院 云计算实验室,合肥 230026)
1 引 言
人脸关键点检测是标注图像中人脸的关键部位,如面颊轮廓、五官轮廓的计算机视觉任务.通过人脸关键点的识别,可以获取到如人脸位置,脸部特征、表情、角度等多方位图像语义信息.该任务常被作为先置任务应用于其它复杂的人脸视觉任务,如人脸识别、人脸3D重构等.
近年来,随着深度卷积神经网络训练技术的突破,以及该特定任务下网络结构的逐渐演变优化,尤其是堆叠沙漏网络(Stackedhourglass)[1]和热度图回归(Heat-map regression)[2]技术的出现,人脸关键点识别的准确度问题得到了很好的解决.另外得益于张量处理器技术的改进,以及神经网络压缩技术[3]的发展,在通用计算设备上实现实时人脸关键点检测成为了必然趋势.然而在从图像处理到视频流处理的演变过程中产生了关键点抖动的问题,即人脸在视频图像中相对平滑运动的情况下,通过神经网络模型检测出的人脸关键点会出现不规则的跳跃现象.这极大地影响了相关应用的用户体验.现有工作[4]已验证,在现有数据集上,检测准确度评价指标的进一步提升并不意味着模型准确性的真实改进,因而无法削弱关键点抖动的现象.我们需要一些额外的技术手段来使得视频流中检测出的人脸关键点的运动轨迹趋于稳定.
要使得一个坐标序列代表的点呈现平滑的运动轨迹,一般的做法是对其使用某种低通滤波器,例如卡尔曼滤波[5]进行后处理.该类方案需要在输出序列的基础上进行额外计算,在实时应用场景下会增加响应延时.且此类方案难以把握人脸在视频中的运动规律,不能很好地平衡不同的人脸运动速率,往往在快速运动的部分上呈现严重的滞后现象,导致人脸关键点检测失准.针对视频中的人脸关键点的稳定性这一特定问题,目前已知的解决方案主要有基于光流追踪的SBR[6]和FHR[7].前者对关键点的变化进行约束,要求与光流追踪所得的结果相匹配;后者分析出一部分抖动的成因来自热度图还原坐标时的浮点数精度丢失,从而通过局部高斯函数拟合的方式加以修正.
本文的主要工作如下:
1)在FHR方案的基础上设计了从热度图到关键点坐标的平滑网格逆变换(Soft Mesh Grid,SMG),不仅能够保留浮点数精度信息,防止上采样过程放大误差.而且整个过程保持可微,从而使得能够利用坐标空间的监督信号来有效指导卷积神经网络的训练,这为后续的对抗训练带来了便利.
2)对于视觉语义信息更加丰富的3D人脸关键点[4],在不存在带有稳定标注的视频数据集的条件下.提出利用参数化的人脸3D模型[8]模拟生成平稳的人脸关键点运动轨迹.在视频连续帧数据上,通过对抗训练的方式非监督地指导模型作出平滑且准确的检测.
3)针对关键点坐标序列的稳定性尚无统一量化评估指标的现状,率先提出利用近似熵(Approximate Entropy)[9]作为评估手段,并举例验证了该量化方案的合理性.
4)通过我们的方案训练所得的模型与只针对静态图像的神经网络模型结构一致,能够同时应用于图像和视频中人脸关键点的检测.在图像数据集AFLW2000-3D[10]上,我们的模型的准确度与基准模型FAN[4]保持一致.在视频数据上,我们的模型预测结果对应的近似熵要显著低于现有模型,同时呈现出的关键点轨迹在主观感受上明显更为平滑.这意味着,我们的训练方案能够在不损失检测准确度的前提下,提升视频中人脸关键点的稳定性.
2 相关工作
2.1 图像中的人脸关键点检测
人脸关键点检测任务为典型的人脸校准(Face Alignment)任务,输入为图像中带有人脸的部分,输出为与之匹配的人脸的关键点形态模型(Landmark Shape Model).人脸关键点形态模型的种类繁多,目前应用较广的是Menpo[11]68点的2D模型和3D模型.其中3D模型传达的信息更为准确且丰富,因此后文中指代的关键点模型,如无特殊说明,均为68点3D人脸关键点模型.2017年,Bulat等人利用在人体关键点检测领域获得成功的堆叠沙漏网络和热度图回归技术,构建了全角度高准确度的人脸关键点检测模型FAN[4],并讨论了现有数据集标注本身的误差问题.于是,后续的研究重点由追求更低的误差度量指标转变为各类鲁棒性的增强.例如Yuen[12]等人在原数据集上人为添加遮挡物覆盖来对数据集进行增强,并增加额外的关键点可见性预测任务,使得网络对于非可见关键点的鲁棒性大大增强.Dong[13]等人提出了通过风格化迁移的方式来增强数据,使得网络对亮度,色彩分布各异的各类风格化人脸图像上都有稳定的表现.总体上讲,静态图像中的人脸关键点检测任务已较为成熟,多数场景下能够给出准确度接近标注水平的关键点位置信息.
2.2 视频中的人脸关键点检测
对于视频流媒体中的人脸关键点实时检测问题,相较于静态图像的版本,主要有以下3方面的额外挑战:1)消除关键点抖动,还原准确且平稳的关键点运动轨迹;2)应对剧烈运动带来的运动模糊;3)平衡准确度与执行效率,应对实时场景.
针对关键点抖动,主要的工作有前文提及的SBR[6]和FHR[7].SBR通过光流追踪(Flow Tracking)的方法来辅助指导神经网络对连贯运动表现出一致性.核心思想在于将经典的Lucas-Kanade Tracking操作分解为可微计算,嵌入神经网络的梯度计算流程中,通过光流信息来约束关键点的变化.显然,这样的做法要求每个关键点均可见,因而无法应用于3D人脸关键点,以及某些大角度姿态的场景.FHR除去前文描述的浮点数精度修复之外,还设计了一个时序概率模型来对输出的坐标序列进行修正,原理上类似卡尔曼滤波一类的后处理方案.本质上后处理方案与模型训练方案之间是松散耦合的,不同的训练方案和后处理方案可以自由组合.本文中,我们将关注的重点放在训练方案上,实验证明通过我们的方案训练得到的网络模型输出,即便不应用后处理,其稳定性依然能够超越现有的带后处理的整体解决方案.
对于运动模糊,基于参数化人脸模型的一些经典方法,如级联回归(Cascade Regression)[14]往往通过从参数空间隐变量到坐标空间的还原操作,尽管无法做到准确,但能够输出尚且完整的人脸关键点信息.而基于神经网络和热度图回归的方法,则由于缺乏此类泛化能力,往往会得到极为混乱的结果,致使此部分预测完全失效.而后者在常规情况下的准确度要远远超过前者,因此有研究通过整合了业界前沿的去模糊神经网络[15],基于光流信息对后者进行修正,所得到的神经网络模型FAB[16]能够鲁棒地处理多种模糊场景.然而由于该模型的网络结构过于复杂,难以应对实时的应用场景.事实上,我们的训练方式对于运动模糊也具有一定程度的修正作用,虽无法媲美FAB的效果,但具有网络复杂度方面的优势.
至于实时场景下执行效率的提升,原理上来说,通用的网络压缩和加速手段,如知识蒸馏[17]、剪枝[3]、量化[3]、Xnor网络[18]等同样适用于堆叠沙漏网络一类的人脸关键点检测模型.此外一些针对移动平台上人脸关键点实时检测需求的特殊网络[19]也已出现.如何更快速,准确,且稳定地应对这类场景也是我们后续研究的重点之一.
2.3 人脸3D模型以及人脸3D重构
人脸关键点形态模型以及人脸3D模型同属于常见的人脸模型,人脸关键点检测以及人脸3D重构也都属于人脸校准(Face Alignment)问题中的一类.一般来说3D重构要求的建模粒度更细,准确度尚不理想.但这类模型往往能够给人脸关键点检测问题提供更多的信息,促进其准确度和鲁棒性的提升.例如3DDA[10]设计了通过单张人脸图像拟合3D人脸模型 3DMM[20]参数的算法.并通过对得到的3D模型进行旋转和重渲染,获取到各个不同角度下,同一张人脸所呈现出的不同二维图像.通过这种方式,作者在原数据集300W的基础上,构造出了新的数据集300W-LP以及 AFLW2000-3D.其中包含了一些带标注的大角度人脸图像,同时自动添加了3D人脸关键点的标注.姿态增强后的数据集以及3D人脸关键点检测逐渐成为了后续研究的主流.
我们采取的对抗训练过程,同样采用了3DMM模型进行平滑关键点轨迹序列的生成.从而以非监督的方式,将这类隐性特征传递给检测网络,对其在连续帧图像上的关键点输出的稳定性作出一定约束.
2.4 人脸边框检测
图像中的人脸边框检测为人脸关键点检测的前置任务.关键点检测网络的输入图像为原始图像中对人脸边框所在区域进行裁切后的部分像素,而网络的输出也需要对像素坐标进行仿射变换后还原到原始图像中的准确位置.人脸边框检测技术较为成熟,例如本文实验部分采取的S3FD[21]模型,在AFW[22]数据集上具有高达99.81的平均准确度,因而不会对后续的关键点检测任务产生影响.
3 视频检测中的人脸关键点抖动问题
3.1 形式化描述

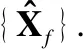
3.2 抖动成因分析
我们基于相关工作的分析,将关键点的抖动成因归结为3方面因素的共同作用:
1)泛化误差导致的关键点偏移.视频中的人脸图像相较于标准的图像测试集要更为复杂,因此对模型的泛化能力要求更高.对于鲁棒性有所欠缺的检测模型,一旦视频中出现一些大角度带遮挡,甚至带有极端运动模糊的困难帧,模型给出的关键点出现偏移在所难免.
2)后处理不当导致精度丢失.目前精度较高的关键点检测模型的神经网络输出均为热度图[2].热度图表示为浮点数矩阵H,维度W× H × 68,分别对应输入图像的宽,高以及对应的关键点标号.Hi,j,k代表了第k个关键点到第i,j个像素中心位置的距离信息.因此神经网络模型N实际上由两个映射复合而成,即从输入图像到热度图的映射g:NW×H×3→RW×H×68以及从热度图还原出关键点坐标的映射T:RW×H×68→R68×2.T通常选取为简单的argmax函数,这样会导致输出的坐标只保留了整数精度,当原始图像的清晰度较高时,我们需要乘以一个较大的常数来将关键点还原到原像素坐标空间,因而会放大丢弃的浮点数误差.
3)训练集标注误差.实验证明,NME较小的模型上抖动的情况并没有明显缓减.导致该现象的一个可能的原因是高准确度模型学习到了一部分人工标注的特异性偏差.事实上图像训练集包含多个不同的来源,不同来源的标注往往带有不同的误差倾向.而数据集特征分布往往是不均衡的,例如Menpo数据集中72.9%的图像是右侧图像.高准确度神经网络模型往往会对细小的输入差别更加敏感.这样的敏感度在很多时候匹配到了人工标注的偏差,反而有助于降低NME误差,却不利于输出稳定的关键点序列.
3.3 关键点坐标序列的稳定性度量
目前对关键点稳定性的研究尚未提出合理的量化评估手段,通常以300VW视频数据集上较为稳定的2D关键点标注为参照,通过NME指标以及定性分析的办法来说明模型输出的关键点序列的稳定性.这样的做法有诸多缺陷:1)准确性和稳定性是截然不同的两个指标,更低的NME数值并不意味着更好的稳定性;2)缺乏量化手段意味着方案之间无法单独就稳定性进行比较;3)由于缺乏带有稳定的关键点标注的视频数据,3D关键点的检测模型无法采用类似手段进行稳定性评估.
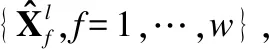
1)固定m∈N用于控制比较子列的长度,此处选取常规值2;r∈R作为ApEn对变化量的敏感度阈值,我们选取2.0,因为2个像素的抖动幅度人眼便能清晰的感知.
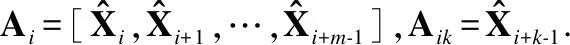
3)选取向量空间上的某种距离度量:d[Ai,Aj]=maxk‖Aik-Ajk‖2即对应关键点坐标欧式距离中的最大值.
4)计算与向量序列一一对应的计数值序列.
(1)
5)计算如下数值,代表了原序列在特定长度上的接近程度.
(2)
6)最终得到近似熵度量ApEn=Φm(r)-Φm+1(r).该数值越小,序列的稳定性越高.
4 稳定化方案设计
4.1 模型训练的整体流程
我们给出的基于对抗的模型训练方案主要包含两个训练阶段:1)利用图像数据集进行监督预训练;2)在监督训练基础上穿插利用视频数据以及3DMM人脸模型生成的关键点序列进行对抗调整.整体的训练计算过程如图1所示.

图1 模型训练计算图Fig. 1 Computation graph of the training procedure
整个过程中,所采用的人脸检测骨干网为FAN[4],即堆叠沙漏网络的结构,其中的基本卷积单元采用了Bulat等人[19]设计的结构,相较于普通的残差单元具有更好的感受野(ReceptiveField),更加适用于关键点检测一类的视觉任务.对于视频连续帧(帧数取为3)数据,我们将其放置在同一数据批(batch)中,通过重排操作使得网络输入与静态图像数据批保持一致,因此监督训练和对抗训练能够交替进行.预训练阶段,我们修改了热度图和标注坐标之间的损失函数计算方式,实验证明这样的修改有助于加快模型的收敛,且最终的NME略有降低.对抗训练时,生成器输出的热度图通过特殊设计的平滑网格逆变换(SMG)还原到像素坐标空间,再通过帧内差分以及帧间差分操作获取对应坐标的时空变化量.以此作为判别器的输入,判别器设计为简单的带Dropout的3层感知器(Multi-Layer Perceptron,MLP)结构,内部激活64维.判别器试图区分来自生成器的关键点坐标序列以及通过3DMM合成的平稳序列.生成器和判别器利用经典的对抗损失函数进行训练.
4.2 平滑网格逆变换(SoftMeshGrid,SMG)
我们设计的从热度图还原出关键点坐标的映射T解决了两个问题:
1)与FHR一样,解决了前文中提到的抖动成因之一的浮点数精度丢失问题;
2)由于保留了可微性,因而像素坐标空间的梯度信号能够向前传递给沙漏网络,从而简化了对抗训练中判别器的结构.使得“平稳性”这一个在坐标空间更容易感知的概念,能够反向通过热度图来指导神经网络进行微调.
平滑网格逆变换的基本想法为:将热度图中的数值看作是关键点出现在对应像素中的概率,因此以热度图矩阵中的浮点数Hi,j,k对各个像素中心位置的坐标进行加权,所得到的坐标数值可以看作是对第k个关键点所在坐标的估计.
(3)
(4)
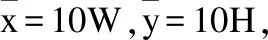
4.3 损失函数设计
生成器,即FAN网络的监督训练部分,一般的做法是通过高斯核由关键点标注生成热度图标注,H*=g(X*)(具体计算过程此处不再赘述).然后定义网络的损失函数为:
(5)
由于我们将热度图数值视作0-1之间的概率,因此在标注转化阶段引入归一化,而后以交叉熵作为损失函数极为自然.
(6)
同时我们加入了如下的坐标空间的l2距离损失:
(7)
监督训练的总体损失函数定义为以上两者的加权和.
lossall=lossbce+0.01 losscoord
(8)
其中后者能够帮助学习整体上的结构信息,主要对应沙漏网络的中腰部分,有助于前期更快速地进行学习.实验证明我们设计的损失函数相较于lossmse,监督预训练的收敛速度有显著的提升.
对抗训练部分,我们采用了原始GAN[24]论文中给出的损失函数.其中的G,D,SeqGen分别对应生成器,判别器以及4.4章详述的拟人脸关键点平稳轨迹生成过程.
lossG=EV~Pvideo[log(1-D(G(V))]
(9)
lossD=EZ~Pnoise[log(1-D(SeqGen(Z) )]+
EV~Pvideo)[log D(G(V))]
(10)
4.4 利用人脸3D模型生成关键点平稳轨迹
我们的目标是通过对抗的方式非监督地约束生成器输出尽可能平滑稳定的序列,这要求我们提供大量平稳的人脸关键点坐标序列作为对照,即在真实数据分布中进行采样.然而现实的情况是,带关键点标注的视频数据量非常有限,尤其是3D人脸关键点.而对其进行人工逐帧标注的代价太大,我们需要一个更加合理的数据来源.
好在对于关键点抖动问题而言,这个现象普遍存在于连续帧之间,因此短到长度为3的连续帧样本,其平稳性差别也足够判别器进行区分,亦能指导生成器进行优化,而长度较短的真实关键点轨迹则容易通过参数化的人脸模型,如3DMM[20]进行模拟生成.3DMM通过主成分分析(PCA)将控制人脸外貌差异的隐变量分为个体面貌参数和表情参数,此外从空间坐标到像素坐标的变换需要考虑尺寸,平移向量和旋转欧拉角等参数.我们认为三帧内人脸姿态的变化在参数空间内近似线性.因此通过3DMM生成关键点平稳序列的过程SeqGen如下:1)采样确定个体面貌;2)采样确定第一帧内人脸的其它参数;3)给定各类参数在三帧内的变化范围,根据首帧的数值采样末帧数值;4)对各类参数进行线性插值得到中间帧上的取值;5)通过模型提供的转换函数,根据各帧参数计算得到对应的关键点像素坐标.这样的生成方法基本涵盖了常规的人脸运动模式且生成的序列足够稳定.
4.5 坐标差分
判别器应该尽可能保持简洁,从而将与直观的抖动程度相关的非监督信号传递给生成器,而不是过多关注一些过于抽象的坐标空间的特征.我们将自己对于坐标序列稳定性判别所需特征的理解编码进了判别器前端的差分运算过程.我们认为有3类关键特征可以用于稳定性判别:
1)帧内相邻关键点的坐标差分,如图2所示,默认为标号相邻的关键点坐标之差,对于特殊部位的边缘起始点,差分的比较对象在图中用箭头标注.这类特征有助于分析个别关键点是否偏离其在整体人脸结构约束下的合理区域,从而能够准确判别由泛化误差导致的关键点偏移.

图2 帧内差分方向Fig.2 Inner-frame differ
2)帧间对应关键点的差分,此类特征用于把握整体的运动趋势,同时突出变动剧烈的部分.
3)对2中得到的偏移量再作类似1中的帧内差分,这部分特征有助于更加精细地判别坐标变换是否来源于合理的旋转和表情变动.
差分运算如图3所示,对于输入维度为F×68×2的序列,差分后的特征张量维度为(3F-2)×68×2.
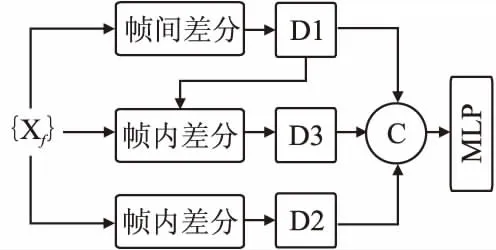
图3 3类差分特征Fig.3 Three kinds of differentiator
为了模型能够更快地收敛,我们对判别器同样作了预训练.过程中通过SeqGen生成的序列被标注为真实数据,而生成器在视频连续帧数据上的输出则标注为假数据.通过比较
是否添加差分预处理的两种判别器模型的预训练收敛速度,我们确认了差分后提取出的特征对判别器的有效性.
4.6 对抗训练算法
图1中的监督预训练部分与静态图像上的人脸关键点识别模型的训练方法一致,此处不再赘述.下面给出对抗训练与监督训练交替进行的算法.其中的函数Sample,Noise,Reshape,SMG,SeqGen,Diff分别对应于随机采样,随机噪声生成,张量维度变换,4.2章中的平滑网格逆映射,4.4中的平稳序列生成以及4.5中的差分变换.
算法1.对抗训练用于提升关键点稳定性

结果:优化后的神经网络参数,生成器ΘG和判别器ΘD
1. 对数据进行增强,D*=Aug(D*)

3.whileloss减少do
4.if根据step数值选择做监督训练then
5. 图像批采样,db←Sample(Dimg,bs·F)
6. 生成热度图,Hb←GΘG(db)
9. 更新参数,ΘG←optimizer(loss,ΘG)
10.else选择做对抗训练
11. 视频批采样,db←Reshape∘ Sample(Dvid,bs)

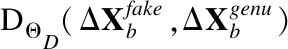
16. 更新参数,ΘG←optimizerG(lossG,ΘG)
ΘD←optimizerD(lossD,ΘD)
17.end
18. step←step+1
19.end
5 实验验证
5.1 数据集及验证方法
由于训练得到的神经网络处理视频数据时采取的是简单的逐帧检测的方式,而没有采取任何的后处理平滑追踪算法,因此模型的准确性可以简单地通过它在静态图像测试集上的表现加以评估.故而可以将准确度评估和稳定性评估分离开,不同于已有工作中难以量化的混合评估手段.对于静态图像上的准确性评估,我们以300W-LP[10]作为训练集,以AFLW2000-3D作为测试集,通过NME误差进行度量;对于稳定性,我们采取前文提到的近似熵ApEn进行量化分析比较.对抗阶段用到的视频数据来自300VW[25],但我们在训练过程中没有使用其2D关键点标注,因此理论上视频数据可以换作是任意单人脸为主体的视频.300VW包含114段人脸视频,长度从649帧-3650帧不等.我们随机选取了其中的100段视频用于对抗训练,剩余14段作为测试集,用于稳定性评估.
我们对于视频帧以及静态图像都使用了图像翻转,平移缩放,色彩调整和随机高斯模糊的数据增强手段.对于图像数据,我们还额外设计了平面旋转和添加遮挡物的方式进行增强.
5.2 监督训练的损失函数比较
我们通过修改损失函数的方式极大地提升了检测网络的收敛速度.训练过程中我们通过Tensorboard观察图像样张检测结果,部分采样结果如图4所示.图中的行从上到下分别对应了采用lossmse,lossall,losscoord进行训练的过程.从左到右则分别对应模型经过0.1k,0.5k,1.5k,5k,8k,15k步梯度更新之后的检测效果.优化器选用Adam[26],且学习率独立进行调优,因而可以判断导致收敛速度变化的主要因素为损失函数的选择.可以看出lossall,losscoord的收敛速度明显快于lossmse,后者在5k步更新之前完全无法把握人脸关键点的整体结构,预测结果集中在极小的邻域.另外,单独通过像素坐标空间的监督信号losscoord进行训练,能够获得这样的收敛速度以及准确度,说明我们设计的可微SMG逆变换确实能够有效地传递梯度信息.

图4 训练过程中的检测样张Fig.4 Sample images with predicted landmarks of different stages of the training process
5.3 鲁棒性评估
人脸关键点检测应用在实际部署时,相较于差距微弱的NME误差,更应关注模型在某些困难场景(如大角度带遮挡、运动模糊等)下的鲁棒性表现.图5给出了我们的模型对比基准模型FAN在一些困难帧上的检测结果.可以看出通过对抗训练之后,模型的鲁棒性有了明显提升.

图5 困难帧上的检测结果Fig.5 Localization results on difficult frames
由于生成器的训练目标是骗过判别器,这要求生成器在各类情况下输出的关键点坐标经过帧内差分后的特征与真实的人脸结构接近.因此这样的提升符合预期,后续研究中,我们将考虑主动获取大量的此类高难度视频数据用于对抗训练,以期获得更好的鲁棒性表现.
5.4 模型准确性评估
AFWL2000-3D测试集上的NME测试结果见表1,包含了各个侧角区间子集上的NME误差以及总体平均值.可以看出在网络结构足够复杂时,如使用4个沙漏网络结构进行堆叠时(S4HG),我们模型的整体准确性略好于基准模型FAN.考虑到实时检测的场景,我们在后续实验中采取的是单沙漏网络的结构(S1HG),即便该模型的复杂度远小于表中其它模型,依然能够取得接近FAN的准确度.而通过对抗训练修正后的最终模型,其准确性仅有略微下降,侧角度范围较小时准确度甚至有所提升.大侧角下的准确度劣化可能与SeqGen生成过程中的角度范围采样偏差有关,有待后续优化.总体来看,通过我们的训练方案得到的检测模型,其准确度与基准方案相当.
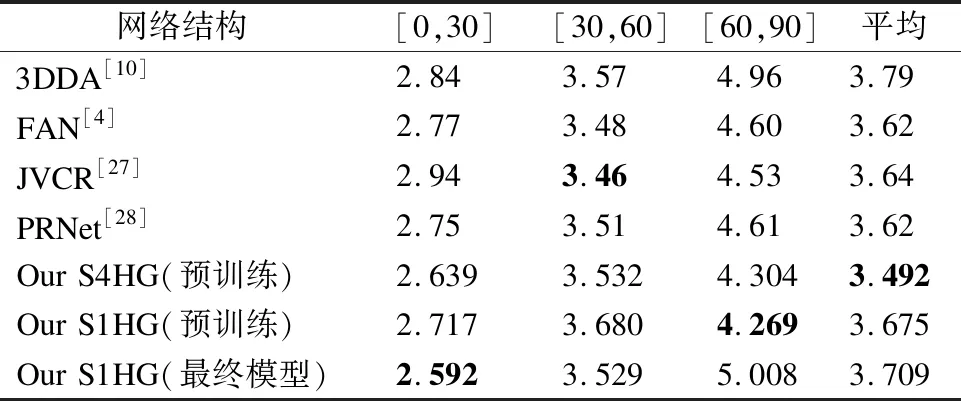
表1 模型NME对比表Table 1 NME on AFWL2000-3D
5.5 稳定性评估
我们对300VW中选取的14个测试视频分别进行稳定性分析.测试时,我们先用模型逐帧的对视频进行关键点检测,而后采取窗口长度为10的滑动窗口对关键点坐标序列进行分割,同时将68个关键点拆分成至独立序列.对每个长度为10,仅含单点坐标的子序列计算其ApEn数值.对所有与该视频相关的ApEn数值分布利用CDF(CumulativeDistributionFunction)曲线进行比较,曲线下的面积越大说明模型输出序列的稳定性越高.鉴于篇幅限制,随机给出部分测试视频上的比较结果,见图6,图6(a)-图6(h)下标表示视频编号.容易看出,我们的模型给出的预测序列的近似熵(实线CDF)整体略低于现有最优模型FHR[7],且后者带有后处理平滑算法.相比较不进行SMG修正以及对抗训练的基准模型FAN,ApEn的数值差距尤为明显,说明我们提出的两个主要的改进方案确实能够显著地提升模型输出序列的稳定性.
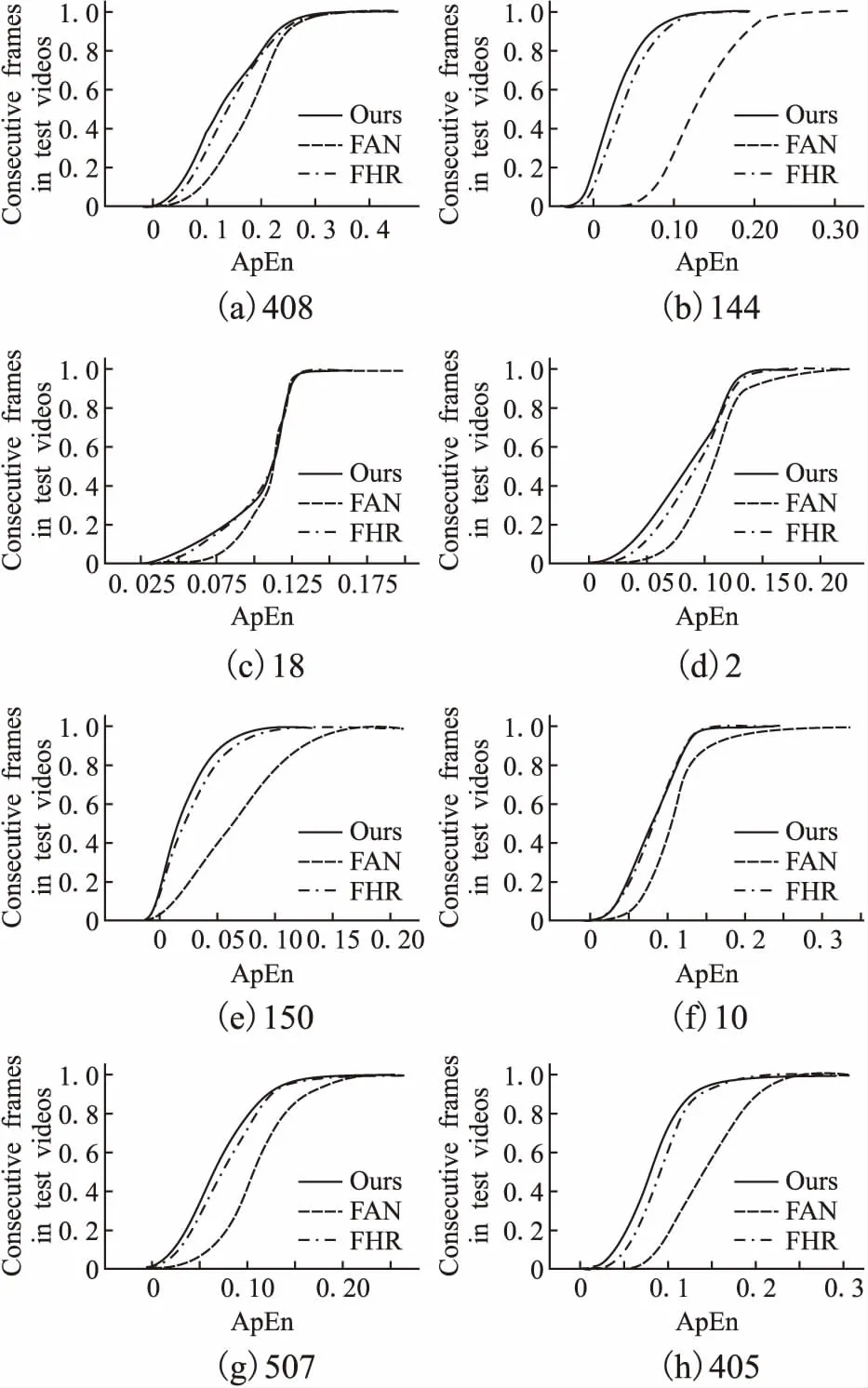
图6 300VW测试视频上的近似熵数值分布图Fig.6 Distributions of ApEn values on 300VW test videos
此外,为了说明我们提出的近似熵ApEn的量化评估手段的合理性,图7给出了3个模型在这些视频上预测出的个别关键点的整体轨迹,图中3行分别对应FHR,FAN以及我们的模型.列标则给出了视频标号和对应的关键点序号(序号含义见图4).可以看出FAN的轨迹具有明显的锯齿,此为关键点抖动现象的体现.另外两组轨迹的平滑度相近,仔细比较可知我们的轨迹要略优于FHR.以上定性分析的结果与前文通过ApEn指标定量分析的结论完美匹配,且主观感受差距越大,对应的ApEn数值的差距也越大.说明了我们将ApEn值作为人脸关键点序列的稳定性度量这一做法的合理性.
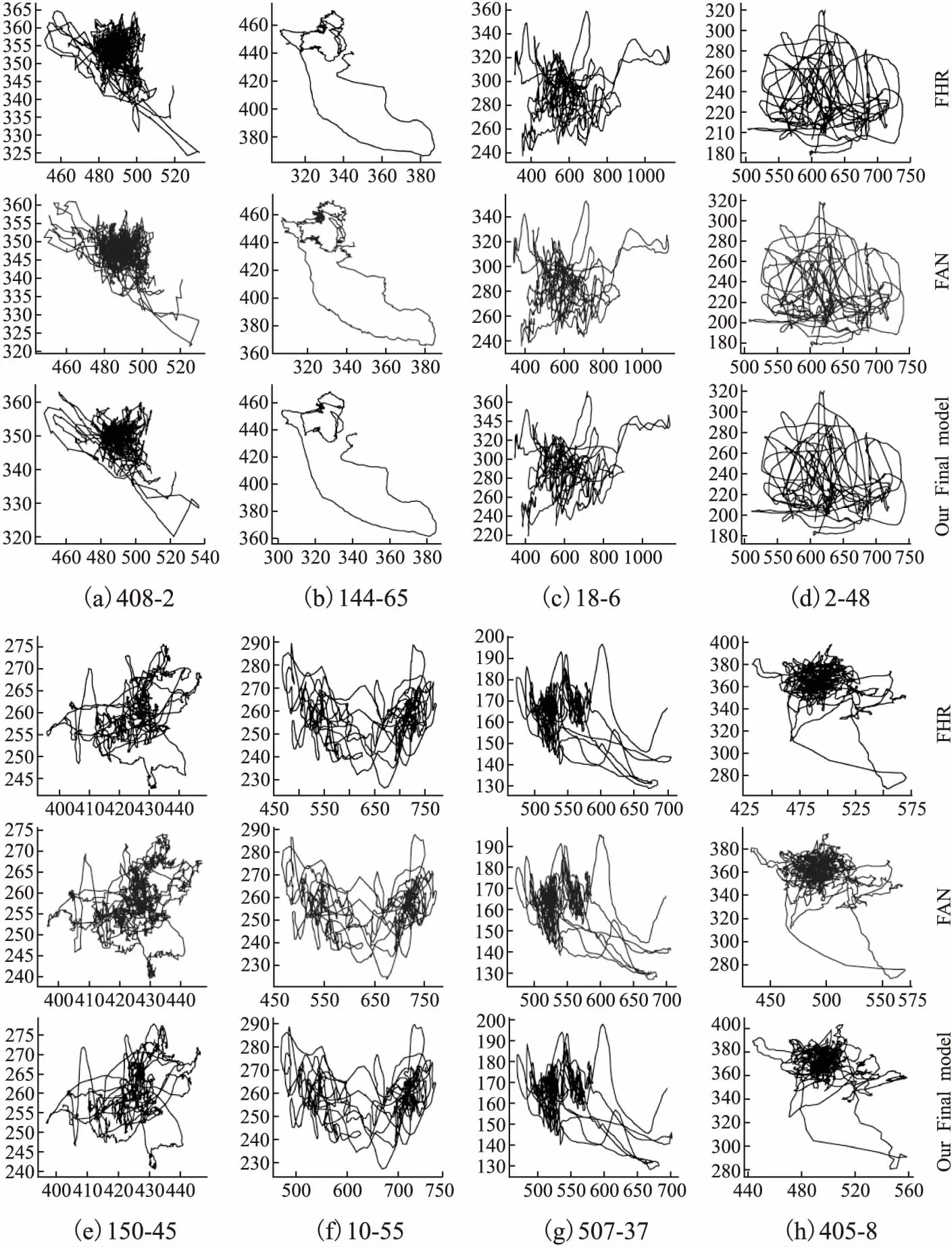
图7 测试视频上单关键点轨迹样例Fig.7 Single landmark trajectory samples of test videos
6 结 论
针对人脸关键点实时检测中的关键点抖动问题,我们设计了平滑网格逆变换和对抗训练两种技术来优化基于堆叠沙漏网络和热度图回归的神经网络训练方案.实验证明这两种技术能够在准确度基本不变的情况下显著增加关键点序列的稳定性.最终得到的S1HG网络模型能够利用GTX1080显卡达到25fps的处理速度,较好地平衡了准确度,稳定性,鲁棒性和实时性的需求冲突.
猜你喜欢
科海故事博览·下旬刊(2022年4期)2022-05-07
建材发展导向(2022年3期)2022-04-19
建材发展导向(2022年2期)2022-03-08
奥秘(2021年5期)2021-06-15
小雪花·初中高分作文(2017年9期)2018-05-21
广东教育·高中(2017年10期)2017-11-07
价值工程(2016年32期)2016-12-20
米娜·女性大世界(2016年8期)2016-08-17
考试周刊(2016年34期)2016-05-28
新高考·高一物理(2015年5期)2015-08-18
