
结合ONLSTM-GCN和注意力机制的中文评论分类模型
2021-07-08 08:27邵党国黄初升
小型微型计算机系统 2021年7期
邵党国,张 潮,黄初升,相 艳
(昆明理工大学 信息工程与自动化学院,昆明 650504)
1 引 言
进入web2.0时代互联网发展迅速,社交媒体(如新浪微博,知乎等)和电商平台(如淘宝,美团等)的用户急剧增加并且评论功能均对用户开放,因此海量的评论被生成.对评论文本正确分类具有巨大的社会价值和经济价值,譬如对社交媒体评论正确情感分类可获取用户对于特定话题或社会事件的看法其分类结果可用于舆情分析等方面.而对商品评论情感分类可分析消费者对于商品的主观感受,对于其他消费者的商品推荐具有极大的参考价值同时是商家改进自身营销策略的重要依据.
文本情感分类是情感分析的基础任务,指的是通过对文本的情感极性进行分类从而检测出作者的情感倾向.文本情感分类总的来说可以分为3种方法分别是基于词典统计的方法,基于机器学习的方法和基于深度学习的方法[1].
基于词典统计的方法首先需要手动构建情感字典.情感字典是指具有情感意义词语的集合包含情感词,否定词,程度词等.该类方法首先手动对情感词语设定适宜的权重并通过对文本中所含情感词的权重进行计算从而得到文本最终得分,但该类方法存在灵活性低,分类效果差的特点.
基于机器学习的方法包括k-means,决策树,SVM等.通过在训练过程学习训练集特征,构建分类模型进而做出分类抉择.但该类方法存在特征向量稀疏,维度爆炸[2],特征提取困难等缺点.
目前得到广泛应用的文本情感方法是基于深度学习的方法.深度学习可以通过多层次的学习自动的抽取到数据的本质特征表示,避免了大量的人工提取特征的工作并且能在分类任务取得较高的准确率.2014年Kim[3]提出TextCNN(Text Convolutional Neural Network)首次将CNN用于文本分类,CNN首先将单词做嵌入转换为词向量然后使用多个尺寸不同的一维卷积核对词向量做卷积,后接池化,分类.递归神经网络因为其时序性相较于CNN更贴近自然语言模型,故递归神经网络及其变体被广泛应用于自然语言处理各项任务中.Tang et al[4]提出层次化RNN用于文本分类,但RNN并未解决长距离依赖的问题.Basnet[5]使用LSTM[7](Long Short-Term Memory)做新闻文本分类,LSTM用一种门结构记忆单元实现长短信息的选择和遗忘,有效解决梯度消失和梯度爆炸.2018年Shen[6]等提出ONLSTM(Ordered Neurons Long-Short Term Memory)这是首次在LSTM结构上引入层级结构,该模型可以提取文本的层次结构.近年来注意力机制引起学界的广泛关注,基于注意力机制的神经网络被运用到自然语言处理的各项任务中去.注意力机制模仿人类的感知方式,将注意力集中到重要的部分.Pappas[8]提出分层注意力对文本进行分类,使用双向门控循环单元(BiGRU)获取文本特征以及构建两个不同的注意力机制获取不同层级的信息.
从整体上来看,现有深度学习方法能在语义层面上提取特征但却无法充分利用文本的句法信息[16].但评论文本具有上下文依赖性强的特点因此使用句法信息显得至关重要,特别是对于包含同一组词但语法不同的评论文本.例如以下拥有相同的词但是情绪截然不同的两个句子(句1表正向,句2表负向):1“我不知道这有多好吃”,2“我知道这有多不好吃”.依赖解析树和ONLSTM均能揭示文本的句法依赖关系受此启发本文提出OG-ATT混合模型(模型结构图见图4)用于中文评论的情感分类.详细步骤如下:
1)评论文本经过预处理后,本文使用哈工大的LTP句法树工具从评论文本中解析出句法依存树(图1:句1,2句法依存树).
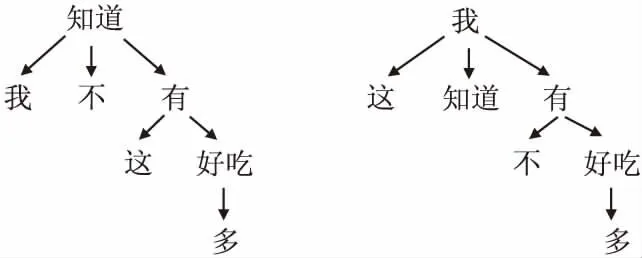
图1 句1,2语法解析树Fig.1 Sentence 1,2 syntax parse tree
2)将评论文本的嵌入向量输入到ONLSTM层中提取文本的语义及句法特征.
3)在GCN[9]层对句法解析树和ONLSTM层输出的词特征做图卷积并与ONLSTM输出词特征做残差相加.
4)ONLSTM-GCN特征提取器提取特征后再接Self-Attention层进一步提取特征从而使得重要信息获得更高权重.
实验结果证明,该模型能充分挖掘句子的句法信息.根据准确率,召回率,精确率,F1值等衡量指标表明本文所使用的模型相对于其他算法效果更优,实现了良好的分类效果.
2 系统框架
本文模型对中文评论文本进行情感分类,处理流程包括:文本预处理,词向量训练,ONLSTM-GCN特征提取,Self-Attention层,分类器5部分组成.分类器也包括3层:1)dropout层;2)全连接层;3)softmax层.
2.1 文本预处理
本文语料为网络评论语料,一般具有偏向口语化,网络用语化,字符表示复杂化等特点.为了分类任务能够使用更加可靠的文本数据,故需要对评论文本进行数据清洗和预处理操作.数据清洗主要进行下面两个操作:
1)数据去重.重复的数据输入容易造成模型对信息的过度学习从而加深模型的过拟合程度,因此去除重复的数据是必要的.对于评论中经常重复的数据,比如“哈哈哈哈哈哈哈哈”,“66666666666”等.为解决这个问题,将语料中连续出现3次及以上的字均截断为两次出现;
2)数据格式化.评论文本经常伴随着冗余的标点符号或者特殊的符号(如链接网址),为了不让模型学习到这些乱七八糟的特征需要将这些多余的信息去除掉比如删除链接网址等.
经过数据清洗得到干净语料后,文本预处理包括分词和解析句法依存树.本文模型采用哈工大的LTP分词工具进行分词,哈工大的LTP语法树工具解析句法依存树,文本分词之后词与语法解析树的节点存在一一对应关系.
2.2 词向量训练
机器学习算法需要将输入表示为固定长度的特征向量,将词表示为一个固定长度的特征向量是将机器学习引入文本分类的首要步骤.本文模型词向量是用谷歌开源的word2vec[10]训练得到的,实验中采用512维词向量.
2.3 ONLSTM
自然语言通常可以表示为一些层次结构,如果这些结构被提取出来就是语法信息.CNN,RNN,LSTM以及其他变体(如GRU)等神经网络虽被广泛用于文本情感分类但只能学习语言的语义特征,不能处理语言的层次结构.而ONLSTM将神经元通过特定排序将层级结构(树结构)整合到LSTM中去,从而允许ONLSTM能自动的学习到层级结构信息[6]、
详细的ONLSTM结构如图2所示.ONLSTM[6]是一种基于LSTM改进的网络结构,首先ONLSTM的门结构和输出结果仍然和普通的LSTM[7]一样:
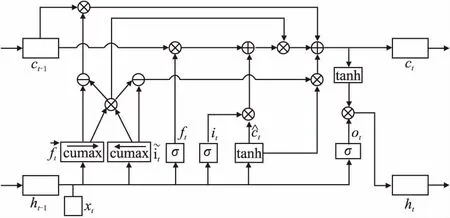
图2 ONLSTM 结构图Fig.2 ONLSTM structure diagram
ft=σ(Wfxt+Ufht-1+bf)
(1)
it=σ(Wixt+Uiht-1+bi)
(2)
ot=σ(Woxt+Uoht-1+bo)
(3)
(4)
ht=ot∘tanh(ct)
(5)
其中输入是历史信息ht-1和当前信息xt.输入门it决定当前时刻输入向量xt对存储单元中信息的改变量,输出门ot用以控制当前存储单元中信息的输出量,遗忘门ft决定上一时刻历史信息ht-1对当前存储单元中信息的影响程度,ht为ONLSTM单元t时刻的最终输出,σ(·)为Sigmoid激活函数,tanh(·)为双曲正切函数.
(6)
(7)
(8)
(9)
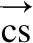
2.4 GCN
传统的神经网络适合处理欧几里得数据,既节点数量,位置以及邻点数量均同质的数据,如图像,影像和音频数据等.但在现实世界中存在大量非欧几里得数据以一种拓扑结构表达,如网页链接网络,论文引用网络,生物遗传信息结构等.拓扑结构数据的节点数量,连接数量及连接强度可以是异质的是一种类似于图结构(graph)的数据.图卷积神经网络的提出为处理这类异质的图结构给出了思路和解决方法.近些年来,GCN引起了研究者的广泛关注,并被广泛应用到web推荐系统,生物化学,网路分析等领域[14].在NLP任务中,GCN在语义角色标志[12],事件检测[13]提取上取得良好的表现.
文本中词与词之间的句法关系可以表示为一个图.其中词是节点,边是词语之间的句法依存关系.Ltp库可以提取语言中句法依存关系并将其表示为图表示(图1表示句1,句2的Ltp提取句法图表示).具体来说,句法依存[15]是指主谓,状语和其他语法,然后分析句子中不同成分之间的关系.对于每条评论文本,对应其LTP句法依存树建立一个图G=(V,E),其中V是文本中所有词构成的顶点集,E是包含词之间依赖关系的边集.根据Kpif & Welling[14]和 Marcheggiani & Titov,为便于引入GCN本模型在E中引入自环并将句法依存树中的单向依存改为双向依存.基于这个规则,我们为每个评论文本建立句法解析树的对称邻接矩阵A(句2的对称邻接矩阵见图3),其中0代表“无依存关系”,对角线上的1代表“自依存关系”,非对角线上的1代表“双向依存关系”,对于同一评论中不同句子的词,LTP自动不考虑它们之间的关系,边标签均为0.句2句法依存树的图A见图3.
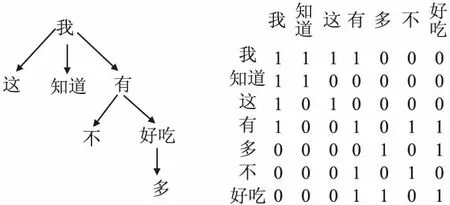
图3 句法依存树的图表示Fig. 3 Graphical representation of syntactic dependency tree
一般的GCN是一个多层(通常是两层)神经网络,它直接卷积在一个图上并根据节点领域的性质归纳出节点的嵌入向量.对于GCN的单个卷积层,计算公式如下:

(10)

2.5 ATTENTION
受人类的注意力机制启发,本模型在ONLSTM-GCN模块后加入Self-Attention[15]层来对文本表示中重要的信息给与更高的加权权重.注意力机制是一个编码序列的方案,其核心在于点乘注意力[15],计算公式如下:
(11)
其中Q∈Rn*dK,K∈Rm*dK,V∈Rm*dV,分别对应query,key,value.dK(K的维度)是缩放因子起调节作用使得内积不至于太大.而本模型采用的是自注意力机制,通过GCN层得到的词表征为X={x1,x2,…,xn}既自注意力层的输入.因此,自注意力机制可以写为.
self-Atten(X)=Attention(XWQ,XWK,XWV)=
(12)
其中WQ,WK,WV∈Rm*m为自注意力层的学习参数.通过上述公式,自注意编码后的每个词表示都对应一个加权向量来编码上下文信息从而捕捉任意距离的依赖关系.
2.6 OG-ATT模型
OG-ATT模型结构图如图4所示,同引言中模型介绍相同.本模型主要由4部分组成:1)使用ONLSTM提取词的初

图4 OGATT模型图Fig.4 OGATT model diagram
步语义及层次特征;2)将ONLSTM层输出的词特征和句法依存树所转化的图A送入GCN层做图卷积[11](本模型采用一层GCN故仅对依存树存在直接依存关系的词做特征融合)得到基于依存树融合的词特征并与ONLSTM原始输出相加得到最终的词表示;3)对ONLSTM-GCN特征提取器所得到词特征做自注意力得到最终文本表示;4)文本表示经过分类器得到最终分类结果.
本模型首先使用ONLSTM抽取初步词特征相较于CNN,RNN,LSTM等传统模型不仅能提取语义表示并且能提取文本的层次表示,并在第2层使用GCN层使得预训练模型(LTP)所提取的句法依存树动态调整文本的最终表示.第3层Attention层模仿人类注意力机制使得文本中重要信息得到更高的决策权重.
3 实验结果及分析
3.1 实验环境
本文实验环境及机器配置如表1所示.
表1 配置表Table 1 Configuration table
3.2 数据集和评价指标
为验证本模型的可行性,本文采用携程酒店评论数据集ChnSentiCrop,微博评论数据集NLPCC2014.由于数据集没有明确划分训练集和测试集,本文对上述数据集均采用10折交叉验证.数据标签为二分类:正向和负向.具体数据信息见表2.

表2 数据集介绍Table 2 Data set introduction
本文采用4个评价指标:准确率(Accuracy),精确率(Precision),召回率(Recall),具体计算公式如下:
(13)
(14)
(15)
(16)
3.3 实验超参数设置
本文采用Ltp分词工具对评论文本进行分词,利用Ltp语法树工具获取文本的语法解析树.使用Word2Vec来训练文本分词后的词向量,单条文本的最大长度设置为512,词向量维度设置为512.为防止模型对训练数据过拟合,在self-attention层后加入dropout再连接全连接层,dropout率设置为0.5.学习率设置为0.001,学习率指数衰减率设置为0.9,迭代次数设置为20,批次数设置为32.
3.4 实验结果分析
为检验模型的效果,本文将其与基准深度学习方法进行对比,基准模型分别包括分别为:卷积神经网络(CNN)[3],循环神经网络(RNN)[4],双向长短时记忆网络(BILSTM)[17],基于注意力机制的双向长短时记忆网络(Attention-BiLSTM)[18],融合卷积神经网络和注意力网络(ADCNN)[19].表3列出6种网络在不同数据集上的实验结果:
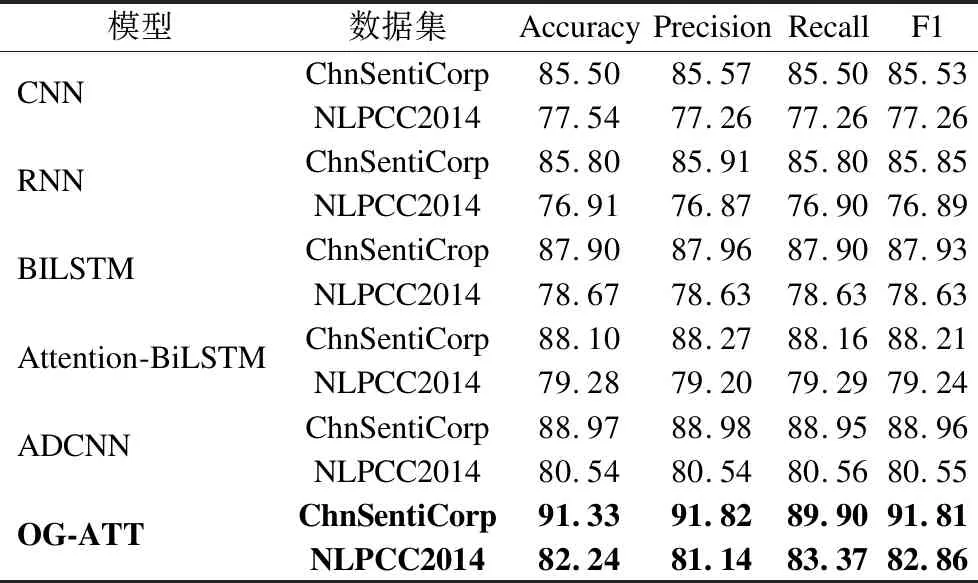
表3 模型结果对比Table 3 Comparison of model results
通过对比实验发现,本文模型在上述两个数据集上4个评价指标均相较于上述方法均得到提升.其ChnSentiCrop数据集上Accuracy相对于CNN,RNN,BILSTM,Attention-BILSTM分别提高了5.83%,5.53%,3.43%,3.23%,2.36%.而在NLPCC2014微博数据集上Accuracy相对于上述5个基线方法分别提高了4.7%,5.3%,3.57%,2.96%,1.7%.
比较BILSTM与Attention-BILSTM的效果发现Attention-BILSTM在中文评论文本中效果较BILSTM上有所提升,这是因为Attention机制在评论文本中可以使得文本中重要信息能得到更高的分类决策,而比较本文模型与Attention-BILSTM,ADCNN的效果,可以发现本模型在4个评价指标上均有大幅提升这表明本文模型的ONLSTM-GCN特征提取器在提取文本的层次结构后分类效果的确优于仅利用语义信息的传统机器学习方法(BILSTM,CNN).综上所述本文模型较传统机器学习模型在提取语义信息的基础上还能充分挖掘文本的句法信息,并进一步使用Attention机制来挖掘文本重要信息.从结果上说,本文提出的模型是可行的.
4 结 论
本文提出了一种新的中文评论文本分类模型OG-ATT.基于文本中词与词之间的语义依存关系,本文模型利用ONLSTM-GCN提取文本的语义及句法的融合表示,并利用Self-Attention对文本中重要信息给与更高分类权重.实验表明,OG-ATT充分利用句子的句法关系,在中文评论文本数据集上的性能优于现有主流模型.
本文模型存在对评论长文本无法分类的限制,因为PYLTP语法解析树工具无法对过长文本提取句法依存树.本文将长度长于512的文本截断为512词这限制本文模型的应用范围,如何将该模型部署到长文本的分类以及如何处理中文评论中大量混杂其他语言的情况还需进一步考虑.下一步工作为将该模型适配到长文本和其他语言中.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
华文教学与研究(2022年1期)2022-04-27
小雪花·成长指南(2022年1期)2022-04-09
中华诗词(2018年3期)2018-08-01
中国房地产业·上旬(2018年1期)2018-05-14
中华诗词(2018年11期)2018-03-26
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中学英语之友·高一版(2008年10期)2008-12-11
