
改进U-Net网络的水下图像增强
2021-07-03 05:45:38李微毕晓君
应用科技 2021年3期
李微,毕晓君
1. 哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
2. 中央民族大学 信息工程学院,北京 100081
水下图像的质量对海洋军事、海洋资源开发等领域的研究具有至关重要的影响。然而,由于光在水中的衰减,造成获取的水下图像呈现出色偏、对比度低以及不清晰等问题,因此,对水下图像进行增强成为研究者们关注的热点。现有的水下图像增强方法分为基于深度学习的水下图像增强算法和基于传统算法的水下图像增强算法[1]。传统的水下图像增强方法能够对特定场景下的水下图像进行增强,但是传统算法对于图像中出现的不均匀光照、图像雾化等不同场景下的图像,容易出现局部区域过度增强而背景区域增强不够且增强效率低的问题,实际应用价值有限。而近年来,深度学习方法[2]在对图像进行处理上具有良好的效果以及较高的效率,因此,将深度学习方法应用到水下图像增强中具有重要意义。
由于深度学习方法在提取图像特征方面的表现良好,本文提出采用深度学习网络作为水下图像增强的网络。首先本文提出采用生成对抗网络合成水下图像,制作数据集,之后在制作的数据集的基础上训练一个能够充分提取水下图像特征的改进U-Net网络[3]用于真实场景下的水下图像增强。
1 相关工作
深度学习方法需要规模庞大的数据集对模型进行训练,然而这在深海环境中很难得到,因此需要制作水下数据集,接着利用深度学习网络提取数据集中的水下图像特征,使网络能够应用到真实场景下的水下图像增强。
Wang等[4]提出一种端到端的基于卷积神经网络的水下图像增强模型(underwater image enhancement-net,UIE-Net),该方法首先利用水下成像模型合成了水下数据集,再将UIE-Net中的去雾子网络和颜色校正子网络分别用于图像去雾和校正色偏2个任务,同时采用像素破坏策略来提取图像局部模块的固有特征,并且减少噪声的干扰,从而极大地加快了模型的收敛速度和精度。Li等[5]提出一种能够合成水下风格图像的生成对抗网络,称为WaterGAN,WaterGAN通过无水图像和深度图像经过真实水下图像的渲染合成模拟的水下图像,然后将模拟的水下图像和无水真实图像以及深度图像都用于提供两阶段的深度学习网络,网络可以用来校正真实场景下的水下图像。Fabbri等[6]提出一种鲁棒性高的生成对抗网络,该网络首先使用循环一致性生成对抗网络在未失真的图像基础上重建失真的图像,然后对成对的水下图像进行训练,训练出一种鲁棒性高的网络,该网络可以将模糊的水下图像转换为清晰的高分辨率图像。Li等[7]提出了一种基于水下场景先验的卷积神经网络模型,称为UWCNN。该模型结合水下成像模型和水下场景的光学特性,通过不同场景下的真实水下图像合成了涵盖不同水类型和退化程度的水下图像退化数据集,利用相应的训练数据对网络进行训练,得到的模型能用于真实水下图像的增强。此外,基于该网络的参数少、运算速度快,UWCNN模型可以扩展到水下视频中进行逐帧增强。
现有的深度学习方法已经在水下图像增强领域取得了重大的突破,能够对部分图像进行有效地增强。但是现有方法合成的水下数据集与真实场景下的水下图像还存在差距,以及现有深度学习模型不能充分提取不同风格水下图像的全部特征,从而不能应用到不同风格的水下图像中的问题,模型缺乏通用性。针对水下图像合成质量的问题,本文首先提出一个水下成像模型,然后使用生成对抗网络模拟水下成像模型的过程,并对水下成像模型的参数进行自适应的学习,解决了基于水下成像模型人工设计参数的不足,同时训练好的网络恰好能拟合水下退化的真实过程。针对现有水下图像增强方法不能充分提取水下图像特征提取而导致模型通用性不足的问题,本文采用特征提取能力出色的U-Net网络作为水下特征提取的基础网络,引入注意力机制[8]对水下图像目标区域和背景区域的对比度进行增强,从而提升图像整体质量。
2 本文算法
2.1 水下数据集制作
目前,基于深度学习的水下图像增强方法研究的难点为水下数据集的获取。模型的训练需要同一位置的无水图像和退化图像,但是无水图像很难得到。因此,本文首先通过提出一个新的水下成像模型,利用生成对抗网络,将无水图像经过真实水下图像的渲染生成无水图像对应的合成水下图像,从而建立成对的水下数据集。
2.1.1 水下成像模型
光在水中传播过程中,由于水体对光的吸收和散射造成光的衰减,水下环境中还存在水中悬浮颗粒、浮游微生物和无机盐等都能吸收光能,同时产生光的散射效应而改变光的传输路径,从而使在水下获取的图像出现色偏、不清晰以及对比度低等问题。经典的水下成像模型为
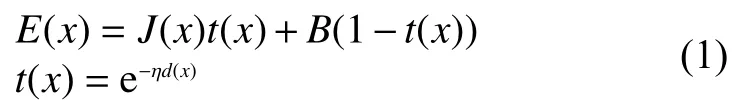
式中:x为 图像中的每个像素;J(x)为无水图像;t(x)为传输效率;E(x)为退化图像;η为衰减系数;d(x)为目标到水下相机的距离;B与图像远处的背景光相关。
经典模型只考虑了光在水中的直接衰减和后向散射衰减的影响,然而,水下环境中由于温度低,使得水中的小水滴和水汽凝结形成水雾,水雾会使得光传输衰减。当水下相机获取图像时,图像场景深处的雾化程度和场景浅处的雾化程度不一致,从而造成水下图像的不同地方因为雾的影响而造成的能见度低下的程度不一样。而普通的水下模型没有考虑场景深度与雾化程度的影响,在场景深度变化大的图像中合成效果差,难以模拟出图像在场景深处的雾化效果。因此,其合成的水下图像就不能很好的模拟真实水下图像成像的特性。本文结合场景深度对图像雾化的影响,并对直接衰减和后向散射衰减提供2个不同的衰减系数,提出的水下成像模型为
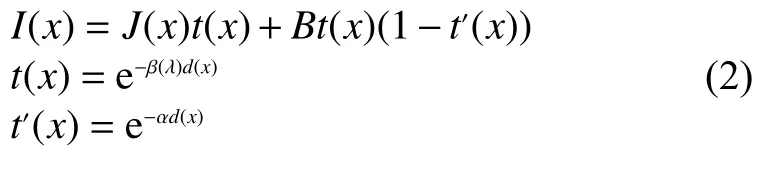
式中:x为 图像中的每个像素;J(x)为无水图像;t(x) 为水中自然衰减的传输效率;β(λ)为水中不同波长的光在水下的衰减系数;d(x)为目标物到水下相机的距离;t′(x)为水中雾化情况下光的传输效率;α为衰减系数;I(x)为退化后的图像。
2.1.2 基于生成对抗网络的水下图像生成模型
近年来生成对抗网络在图像生成领域表现良好,本文利用生成对抗网络模拟水下成像模型的衰减、散射以及雾化进行生成对抗网络结构的设计,能够自适应地学习水下成像模型的参数,网络结构如图1所示。具体方法为采用无水深度图像作为生成器的输入,利用真实场景下的水下图像作为判别器的监督图像,来引导生成器生成图像的风格,从而使得生成器生成的图像与真实场景的水下图像难以区分,达到生成的图像与真实的图像具有相同水下风格的目的,从而制作成对的水下数据集。合成的2种风格的图像如图2所示,图2(a)列为无水图像,图2(b)列监督图像为浅水图像对应的合成水下图像,图2(c)列监督图像为深水图像对应的合成水下图像。
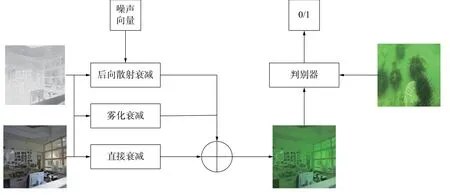
图1 水下图像生成网络整体框架

图2 2种风格的合成图像示例
2.2 水下图像增强模型
本文提出在U-Net网络的基础框架上引入注意力机制作为水下图像增强的模型,模型整体框架如图3所示。
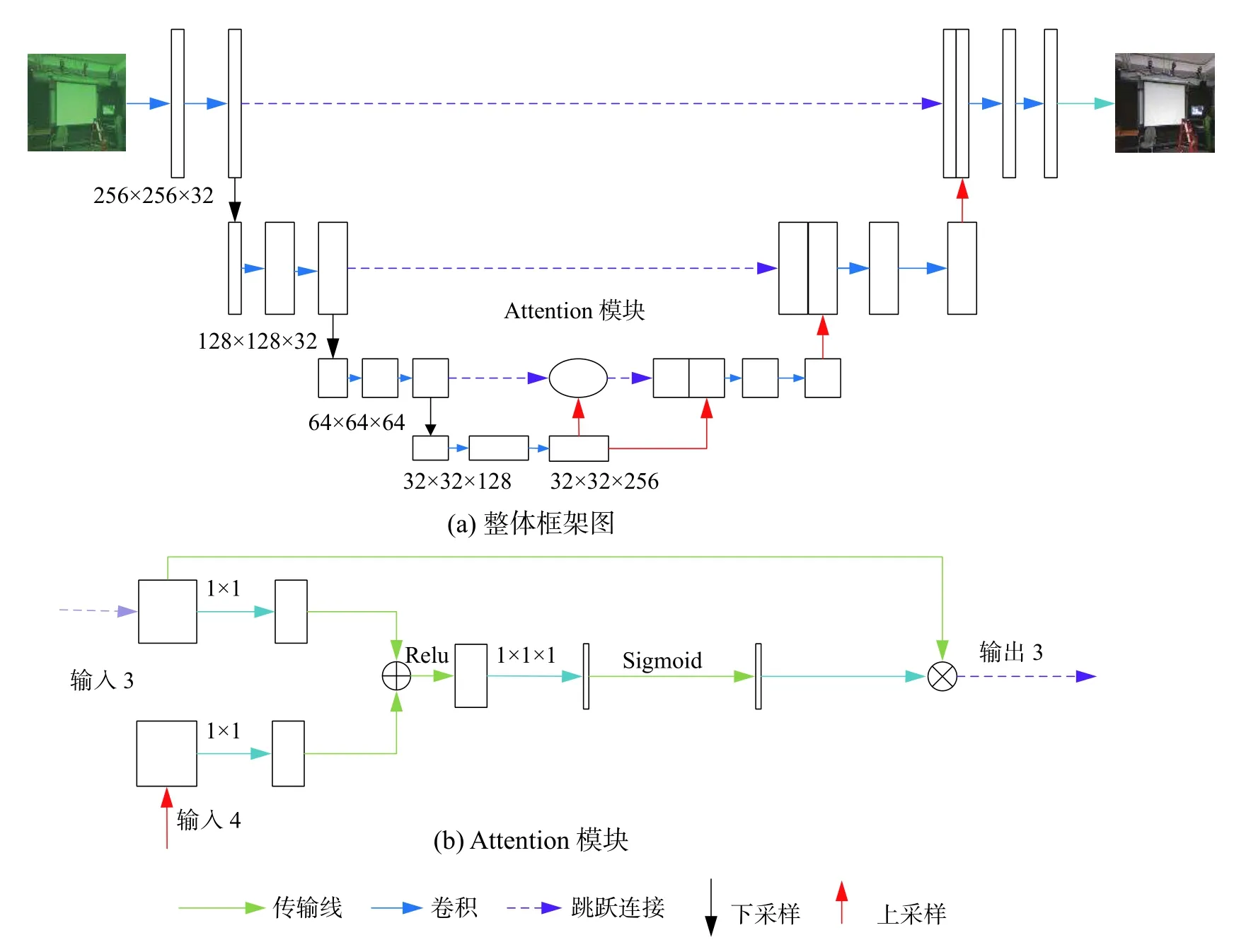
图3 水下图像增强整体框架
2.2.1 特征提取
本文水下图像增强模型一共4层,模型输入像素为256×256的彩色图像,压缩路径在第1~4层的卷积核数量依次为32、64、128、256;2层之间进行1个2倍收缩的下采样,每1层图像大小依次为256×256、128×128、64×64、32×32;扩增路径与压缩路径对称,在2层之间采用1个2倍扩增的上采样,在同层之间使用跳跃连接融合扩增路径与收缩路径的特征信息,在第3层的跳跃连接之间引入1个注意力机制模块,提高深层抽象特征的学习能力,注意力机制模块的输入为收缩路径第3层的输出和经过上采样的第4层输出,获得抽象特征的注意力概率分布之后,注意力机制的输出再与经过上采样的第4层输出进行信息融合。收缩路径与扩增卷积的卷积层的卷积核大小均为3×3,每个卷积层后面跟1个非线性激活函数Relu,模型输出的卷积核数量为3。
2.2.2 损失函数
在水下图像增强网络中,选择一个合理的损失函数引导网络增强后的图像能够逼近监督图像尤为关键,同时可减少网络的训练时间,帮助网络更好地训练。L1损失广泛应用于图像增强领域中,同时图像的结构相似程度也是衡量图像增强质量的一个重要指标,因此,采用式(3)作为总的损失函数:
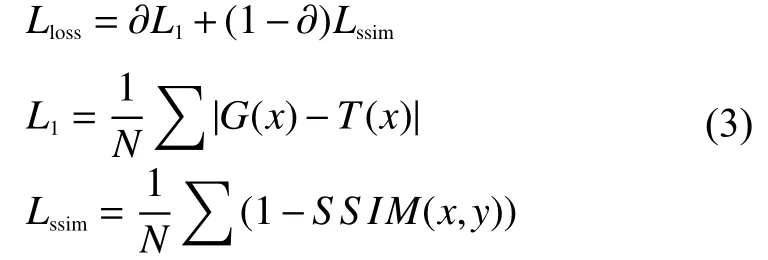
式中:Lloss为总损失;L1为绝对误差损失;Lssim为 结构相似度损失;T(x)表示监督图像中像素x的值;G(x)表示增强图像中像素x的值;∂为2个损失各自的权重系数。
3 实验结果与分析
3.1 实验环境与参数设置
本实验的硬件环境配置Intel®CoreTMi7-7700 CPU@3.6 GHz×8,64位处理器,采用GeForce GTX 1080TiGPU进行运算加速,操作系统为64位Ubuntu 16.04,采用TensorFlow2.0框架以及python3.6进行程序实现。
水下图像生成模型的训练代数为10,批量大小为8,优化器为Adam,指数衰减因子0.5,学习率2×10−4;水下图像增强模型的训练代数为200,批量大小为32,优化器为Adam,指数衰减因子0.9,学习率2×10−4。
3.2 数据集选取
采用NYU Depth dataset V1[9]和NYU Depth dataset V2[10]中的无水图像以及对应的深度图像共3 728张,经过水下机器人大赛官方提供的浅水区域和深水区域2种风格的真实水下图像的渲染,合成无水图像对应的水下图像,从而构造了水下数据集。将合成水下数据集分2部分,用3 712对合成图像进行水下图像增强模型的训练。测试集包括3个数据集:数据集1为16对合成数据集;数据集2为水下机器人官方提供的数据集,包括浅水区域图像2 069张,深水区域图像2 173张;数据集3为多场景的UIEBD数据集[11],共890张。
3.3 测试结果与分析
为了验证本章所提出模型的有效性和先进性,进行了一系列对比实验,对比方法包括以HE[12]、Fusion[13]为代表的基于像素值重新分配的水下图像增强方法,以UDCP[14]、IBLA[15]、MIP[16]为代表的基于水下成像模型的水下图像增强方法,以UWCNN[7]为代表的基于深度学习的水下图像增强算法。
3.3.1 算法有效性验证
首先,为了验证添加注意力机制模块的有效性,使用数据集1中的训练集分别对添加注意力机制的U-Net水下图像增强网络与未添加注意力机制的U-Net水下图像增强网络进行训练。使用合成的水下图像作为网络的输入,将相应的无水图像作为网络的监督图像,通过训练集的训练得到训练好的模型。由于数据集1中的合成水下图像具有对应的无水图像作为监督图像,因此,在数据集1中的测试集中采用有参考图像的评价标准峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(Structural SIMilarity,SSIM)进行不同方法测试效果的对比,结果如表1所示。
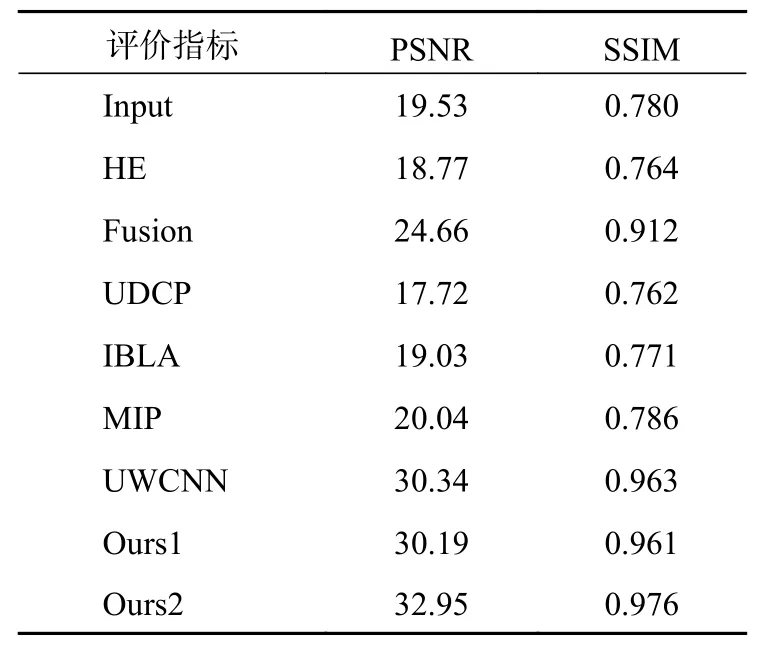
表1 不同方法的PSNR和SSIM结果对比
表1中,Ours1为未添加注意力机制的U-Net水下图像增强网络的实验结果,Ours2为添加注意力机制的U-Net水下图像增强网络的实验结果。对比二者可以看出,在U-Net网络中添加注意力机制模块能够有效提升图像的SSIM值与PSNR值。同时,由表1可知,基于深度学习的水下图像增强方法通过对训练集特征的提取,在与训练集同分布的数据集1上的增强表现优于其他方法,证明了深度学习方法在数据集1上的优越性。
3.3.2 算法先进性验证
为了验证模型在不同风格水下图像中的泛化能力,采用数据集2这种真实场景下的水下图像作为测试集能够更有效地说明模型对真实场景下图像的增强效果。而本文所提出的模型是在数据集1中的水下风格合成图像上进行训练的,而数据集1的水下风格来源于数据集2,因此,模型经过训练能够学习到数据集2中2种水下风格图像的特征,以此作为先验信息,从而在类似风格的水下图像中增强效果明显。为了验证本文所提出的模型能够对不同风格的水下退化图像进行增强的通用性,在含有丰富水下场景的数据集3上进行实验。如图4—图6所示。

图4 不同算法对示例1的增强效果

图5 不同算法对示例2的增强效果图

图6 不同算法对示例3的增强效果
图4—图6分别为不同算法在数据集2中浅水区域的水下图像增强效果示例、数据集2中深水区域的水下图像增强效果示例以及数据集3中水下图像增强效果示例。由图4—图6可以看出,HE方法能够显著提升图像的亮度和色彩度,但是对水下物体会出现由于过度增强而导致失真的情况;Fusion方法增强之后的图像在场景深度深处增强不彻底,同样会出现失真的情况;UDCP方法增强的图像偏暗;IBLA方法增强的图像会使颜色更深,MIP方法仅能够降低水下衰减的程度,对图像全局改善有限;UWCNN增强的图像能够贴近没有水下衰减的情况,但是图像整体偏暗;本文算法能够显著提高图像的对比度与清晰度,校正图像色偏,彻底去除水下衰减的影响,尤其在场景深度深的背景区域,增强效果明显优于其他方法。
为了客观验证本文算法的先进性,采用无参考图像评价指标UIQM这种能够对图像色彩丰富度、图像清晰度以及图像对比度综合考虑的评价指标对图像质量进行评价。图4—图6中图像的UIQM值如表2所示。
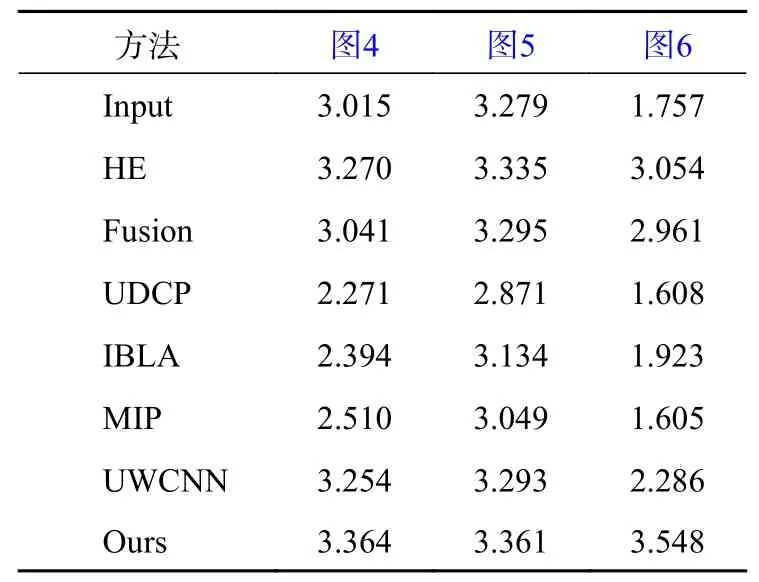
表2 不同方法的UIQM值对比
由表2可以看出,本文算法在3张图中的UIQM值都为最高,展现出本文算法的优越性,同时,HE算法的UIQM值也较高。
对3个数据集的所有水下退化图像进行测试,得到的UIQM均值如表3所示。
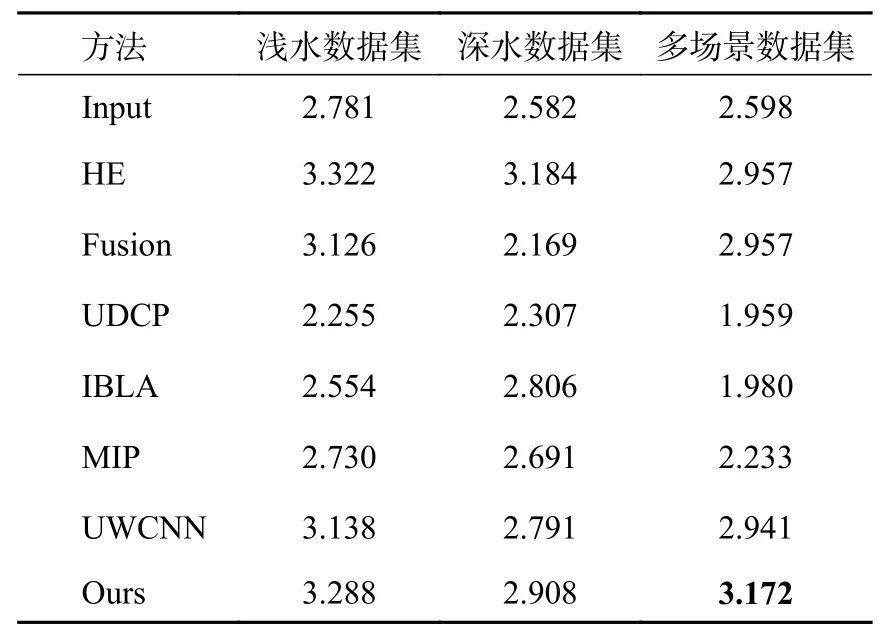
表3 不同方法在3个数据集上的UIQM均值对比
UIQM值近似看作与图像质量呈正相关。表3中,浅水数据集和深水数据集中的HE方法的UIQM均值最高,然而HE方法是通过像素的重新分布,对图像的色彩度和亮度进行过量提高,从而UIQM值也偏高,同时图像也会出现失真的现象,因此UIQM值不一定能够准确地衡量图像质量。基于主观视觉与客观指标的综合评价,本文算法能够对3个数据集的水下退化图像进行有效地增强,且使增强后的图像符合人类视觉感知,模型的泛化能力强。
表4为不同算法在数据集3中890张图像上生成增强图像的平均速度。结果表明,基于深度学习的方法包括UWCNN与本文算法的增强效率优于传统算法。
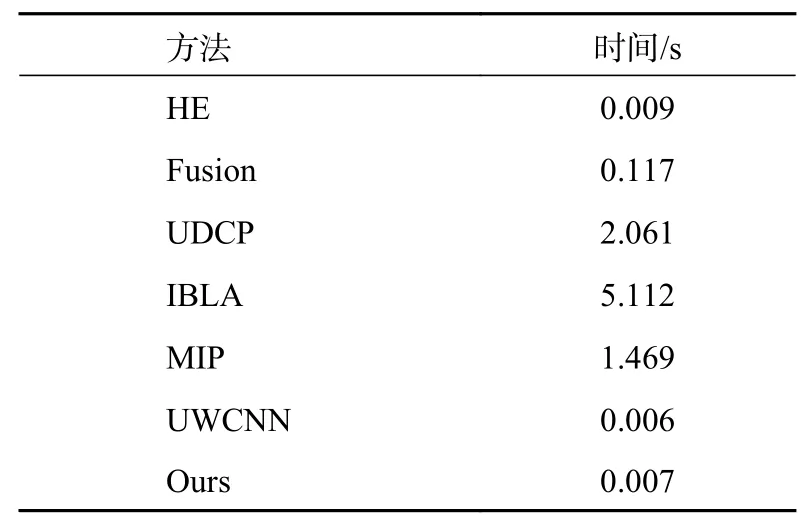
表4 不同算法在单张图像上的平均增强速度
结果表明,基于深度学习的方法包括UWCNN。
4 结论
本文首先提出一个新的水下成像模型用于合成具有水下特征的数据集,通过改进U-Net网络对合成的数据集进行训练得到增强网络模型。通过在3个不同的数据集上进行算法的有效性和先进性验证。结果表明,经过本文算法增强后的图像提高了图像的对比度和清晰度,同时能够有效校正图像色偏,提高水下图像的整体质量,能够有效地对不同场景下的水下图像进行增强,模型通用性强。同时在主观视觉上,增强后的图像符合人类视觉感知,贴近真实。且增强的效率高,为水下图像的实时增强提供了可能。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
燃气涡轮试验与研究(2021年6期)2021-08-01 03:09:10
海洋信息技术与应用(2020年4期)2021-01-18 06:21:36
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
作文小学中年级(2020年6期)2020-07-24 08:33:10
中国生物医学工程学报(2019年5期)2019-07-16 07:56:50
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
北京航空航天大学学报(2017年3期)2017-11-23 05:14:58
