
基于RoBerta的立场检测与趋势预测模型设计
2021-07-03 05:45:38赵姝颖肖宁曾华圣王海兮常明芳
应用科技 2021年3期
赵姝颖,肖宁,曾华圣,王海兮,常明芳
中国电子科技集团公司 第三十研究所,四川 成都 610000
立场检测源于人工智能自然语言处理技术,是情感分类技术的一个前沿分支,可以看作是针对特定目标话题进行的情感分析任务[1]。立场检测也是自然语言处理研究的一个热门主题,Mohammad等[2]在2016年构建了基于 Twitter数据的立场检测英文数据集,并用于SemEval 2016会议的Task 6:立场检测。由于中文语言的多义性、复杂性和语法的独特性,面向中文的立场检测更具有挑战性。2016年中国的相关学者构建了基于中文微博的立场检测数据集,并将其用于2016年的自然语言处理与中文计算会议发表的任务中,进一步推动了中文立场检测的研究。
立场检测任务使用自然语言处理(NLP)技术,根据对目标话题的文本内容分析其立场倾向是“赞成”、 “反对”,还是“中立”[3]。立场检测主要强调根据特定的目标话题环境来分析判断文本内容的立场,虽然与情感分析相似,但不同点在于情感分析侧重于一段文本中情感特征的极性,在很多情况下,分析文本内容的立场倾向仅根据文本的情感极性是无法准确判断的。 例如,某些微博在不考虑任何目标话题的前提, 其情感极性是消极反对的,但是当把它放在某个指定的话题环境中时,其立场可能与单独分析得到的情感极性恰恰相反。通过这个例子可以看出,相比于情感分析任务,立场检测任务对人工智能模型的文本理解能力提出了更高的要求,不仅需要去识别句子中能代表用户情感态度的关键词,还需要去理解完整的句意,并且通过计算机语言表述出来,即得到句意的特征表示。然后,从大量的数据集中学习到从特征表示到用户立场的映射函数,从而完成对文本所持有的立场进行精准判断。
1 相关技术研究
针对立场检测任务,国内外研究人员目前使用的方法主要包括:基于特征工程的机器学习方法和基于神经网络的深度学习方法。
基于特征工程的机器学习方法:从微博话题文本中提取出有关情感和主题的词汇,然后将这些词汇作为特征词,并使用Word2Vec进行词向量的训练,再将词向量求平均后,作为该文本的特征传给SVM分类器中进行立场检测的立场倾向分类。相关实验表明,当文本特征分析仅使用情感词时,情绪并不能准确地反映作者的立场倾向,其立场分类效果并不理想,而加入主题和情感的相关词汇共同作为特征时的选取效果更好。一些学者也探究了文本的多种特征,诸如基于同义词典的词袋特征、文本的Word2Vec的字向量和词向量等不同的特性交叉组合,分析其对立场检测的影响,并且分别使用SVM、随机森林以及决策树对进行立场分类。实验表明,对于立场分类结果,词与立场标签的共现关系同Word2Vec的字与词向量的组合的改善最为明显。
近年来,深度学习的迅猛发展,也促进了自然语言处理的进步。基于深度学习的方法是直接将文本内容全部映射为向量,再通过多层神经网络学习标签并自动提取文本特征,相比于需要人工特征抽取工作的基于特征工程的机器学习方法而言,基于深度学习的方法能够让机器智能提取特征,这是一种优势。目前,在有关立场检测的现有研究中,基于深度学习的工作主要有2种主流的思路,一是通过使用不同方式将目标话题信息添加到微博文本内容中来提升立场检测效果,二是从语言学的角度,对深度学习模型的结构进行创新,使得模型能够学习到文本的句意信息,从而达到更为精准的立场检测结果。基于卷积神经网络(CNN)的立场检测使用基于Yoon Kim的卷积神经网络对微博文本进行分类,它使用了一种模型投票机制,在每一个迭代周期训练步骤结束后,通过融合训练过程中产生的各模型结果,迭代出一些测试集数据并用于预测学习标签,最后在所有的迭代周期训练完成时,从测试集数据中选择被预测次数最多的标签并作为最终结果输出,但这仅适用于对微博文本进行了特征提取和分类,而忽略了在立场检测中目标话题的作用。针对这个问题,部分学者提出了一个双向条件编码模型将目标话题与微博文本进行拼接,其中微博文本BiLSTM的cell状态层的初始值,是通过使用BiLSTM将目标话题cell状态层的输出而来的,因而完成目标话题与微博文本序列的拼接,并且目标话题和微博文本使用隐层状态的BiLSTM编码后彼此之间是相互独立的[4]。针对目标话题,为了增强双向条件编码模型对立场检测的影响,一些学者接着提出了一种基于注意力的BiLSTM-CNN模型用来协助检测中文微博立场。该方法首先使用BiLSTM获取文本的全局特征,使用卷积神经网络(CNN)来获取文本的局部卷积特征;然后将文本的 BiLSTM输出通过使用基于注意力(Attention)的权重矩阵方法将其加到CNN的输出中;最后,向Softmax层中输入所获取到的 CNN的句子表示并对其进行立场分类。一些学者在基于注意力机制的方法上提出了基于两阶段注意力机制的立场检测模型,首先使用Word2Vec表示词向量;然后通过Attention计算微博文本的词向量和目标话题的词向量,BiLSTM用于提取微博文本的特征,将目标话题再次与所提取到的特征进行Attention 计算,并使用Softmax对最终的结果进行分类[5]。
然而以上方法的思路在实践中的效果均不太理想,随 着Google公 司BERT(Bidirectional Encoder Representations from Transformers)模型的推出,将深度学习模型对文本语义的理解能力提高到了一个里程碑的高度,该模型在立场检测领域也展现出了优异的能力。因而本项目将会基于BERT模型进行立场检测技术的研发。
2 研究模型
2.1 Roberta模型
2018年谷歌公司AI团队发布了BERT模型,该模型在机器阅读理解顶级水平测试SQuAD1.1中展示了惊人的结果:它在2个衡量指标上均超过了人类,并且还在11种不同NLP测试中获得了最好的成绩,成就包括将GLUE基准推至80.4%(绝对改进7.6%),以及MultiNLI准确度达到86.7% (绝对改进率5.6%)等方面。可以预见的是,BERT将为NLP带来重大改变,也是近两年中NLP领域最突出的进展[6]。
RoBERTa(Robustly Optimized BERT Pretraining Approach)模型是基于BERT 的一种改进版本,是BERT 在多个层面上的重大改进。RoBERTa 在模型规模、算力和数据上,主要比 BERT 提升了以下几点。
1) 更大的模型参数量(从RoBERTa论文提供的训练时间来看,模型使用1 024块V100 GPU训练了1 d的时间)。
2) 更多的训练数据(包括CC-NEWS等在内的160 GB纯文本)[7]。
RoBERTa 还有很多训练方法上的改进。
1) 动态掩码:BERT依赖随机掩码和预测token。原版的BERT实现在数据预处理期间执行1次掩码以获得1个静态掩码。而RoBERTa在每次将1个序列输入模型时都会生成1个新的掩码模式,通过动态掩码进行更新。这样,在连续输入海量数据的过程中,模型会逐渐适应不同的动态掩码策略并学习不同的语言表示特征。
2) 更大批次:RoBERTa在训练过程中使用了更大的批数量。研究人员尝试过从256~8 000不等的批数量[8]。
3)文本编码:Byte-Pair Encoding(BPE)是字符级表示和词级表示特征的混合,并支持处理自然语言语料库中的许多常见词汇。原版的BERT实现使用大小为30 KB的字符级别的BPE词汇,该词汇表是在利用启发式分词规则对输入进行预处理之后学习得到的。Facebook研究者没有采用这种方式,而是考虑使用更大的字节级别BPE词汇表来训练BERT,这一词汇表包含50 KB的subword单元,并且在输入时没有做任何额外的预处理或分词工作[9]。
2.2 立场检测模型
立场检测模块是本系统的核心组成部件,精准画像功能和群体决策预测功能皆建立在该功能模块的实现之上。本系统的立场检测技术总体来讲,结合了中文自然语言处理领域目前表现最为优异的深度学习模型RoBERTa以及Softmax分类器。通过RoBERTa预训练模型对输入的中文文本数据集进行学习,从而得到文本的特征表示,最后通过Softmax分类器对特征表示进行分类判断得到结果,其架构如图1所示。
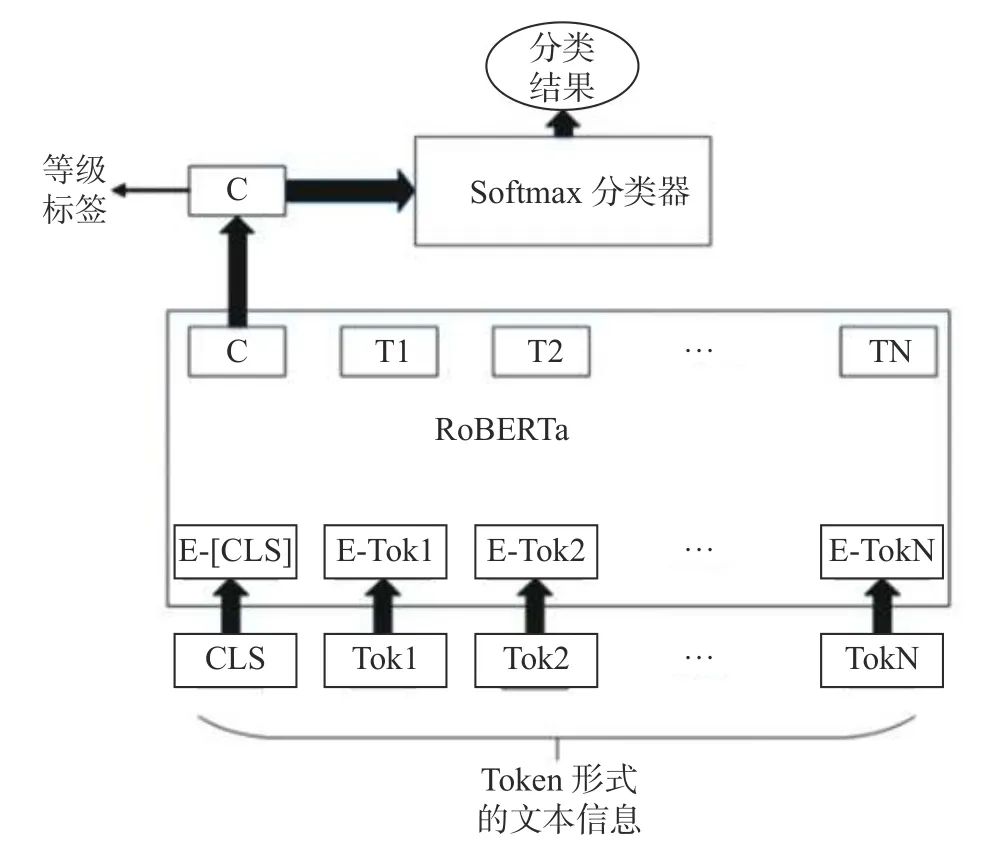
图1 立场检测模型系统框架
系统运行逻辑如下所述。
1) 立场检测模块从文件系统取“文本数据”,而后根据预先设定的字典,将文本中的文字和文字在字典中对应的数字进行映射,即Token化,形成数字序列。
2) 将数字序列输入已预训练好的RoBERTa模型,得到数字序列的特征表示,而后取这一特征表示输入进Softmax分类器进行立场识别。立场分为3种:赞同、中立、反对,分别对应分值1、0、−1。
3) 最后将立场分值附加到最初的文本数据后面,形成“文本+立场”的新数据结构,并根据控制台的指令送往输出模块或群体决策分析模块。
具体的实现方式如下。
1) 将数据采集系统采集的文本信息Token化,然后逐条输入进Pre-trained RoBERTa模型,从而通过多个Transformer层学习到文本信息的抽象表示。
2) 取Pre-trained RoBERTa模型输出层的头部位置的表示向量,将该向量输入Softmax分类器。
3) 通过Softmax分类器形成1个三元组数值,分别表示赞同、中立、反对对应的概率,概率最高的即为该文本针对某一主题的实际观点。
2.3 立场预测模型
本系统在LSTM模型的基础上构建立场趋势预测模型。模型细节如下所述。
2.3.1 数据处理
训练数据采集于互联网论坛,数据为某时间区间内某个话题的所有用户立场占比的时间序列数据,训练时一共使用了11个话题的数据。预测的输入是5个时间点的立场占比,输出是接下来的2个时间点的立场占比。因此,训练时将数据集分割成7个一组的形式,前5个数据作为输入,后2个数据作为输出的标签。
2.32 模型结构
模型采用4层LSTM加上1个全连接层(Full Connected Layer)的输出节点为2个,对应于要预测的2个时间节点。模型的loss采用MSE(Mean Square Error)均方差误差,优化器采用Adam算法。具体模型结构如图2所示。
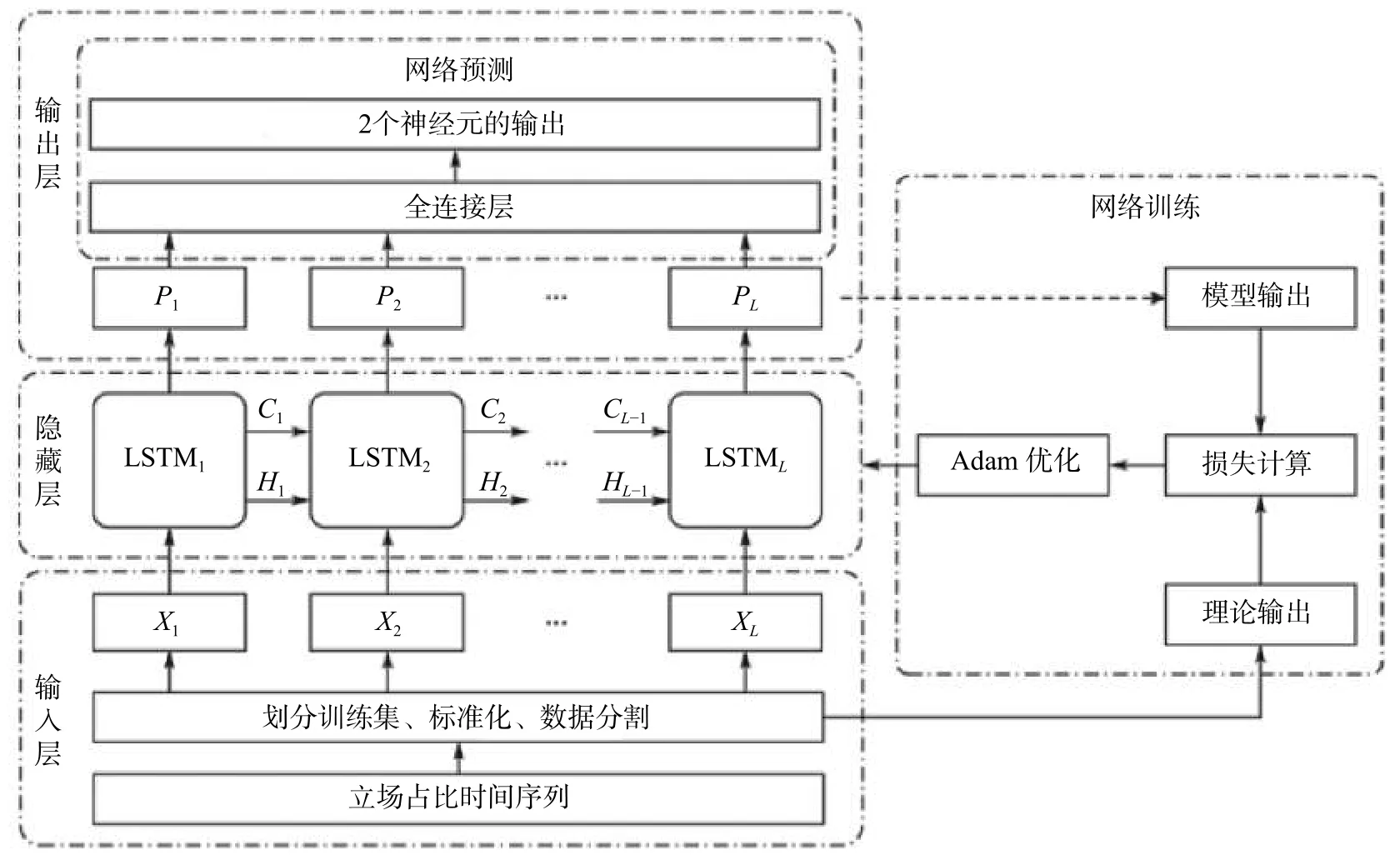
图2 趋势预测模型结构
2.3.3 与前端的交互设计
趋势预测模块采用RabbitMQ消息队列中间件与前端进行交互。具体工作流程如下:1)用户通过前端接口选择预测的“话题” “预测开始时间” “预测时间粒度”,点击“筛选”按钮后,前端将这3个数据发送到RabbitMQ消息队列;2)趋势预测模块通过订阅模式,实时地获取到前端发送到RabbitMQ中的前述数据;3)根据这些数据,从数据库筛选特定话题,特定预测开始时间的数据,以特定时间粒度整合数据,然后形成预测模型的输入;4)通过模型得到预测结果,发送到RabbitMQ队列中;5)前端从队列中读取数据,通过UI界面展示预测曲线。
3 系统设计
3.1 总体设计
系统运用立场检测算法对后端数据库抓取到的舆情数据分析出个体用户的立场,从而形成用户的精准画像。立场检测系统功能流程如图3所示。
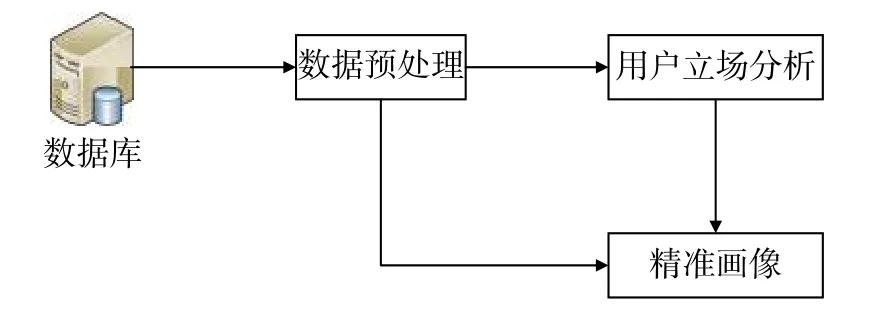
图3 网络群体决策分析系统流程图
根据图3,系统的组成部分如下。
1)数据预处理
决策分析系统首先从舆情数据采集系统的Redis和MongoDB数据库中获取原始数据,然后从原始数据中解析出2部分信息:一是用户针对某一特定话题发布的文本信息,该信息用于后续进行立场分析;二是用户的基本信息,作为精准画像功能的部分输入。
2)用户立场分析
鉴于社交媒体舆论的特点,用户的观点一般显性或隐性地体现在用户发布的文本信息中。为了便于掌握所有用户的立场和观点,让计算机学会自动识别用户立场是极其必要的。因此,本系统围绕某些有意义的话题,根据用户在社交媒体上发布的文本信息,利用自然语言处理技术对这些文本信息所透露出的观点进行立场检测,能够实现对用户潜在观点的识别,并且将此结果作为精准画像和群体决策分析的部分输入。
3.2 系统框架
根据系统的组成原理,详细的系统结构框架如图4所示。
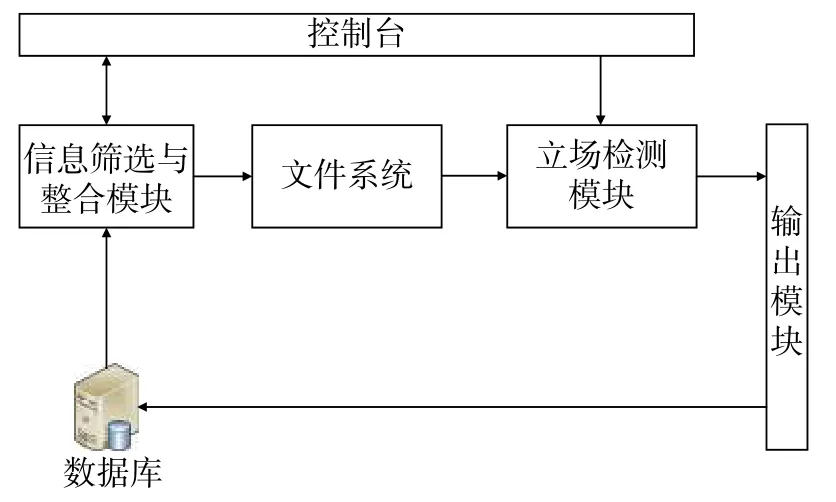
图4 系统结构框架
系统主要包括了以下的功能模块。
1)信息筛选与整合模块:从控制台接收指令后从数据库获取相应信息,并将信息通过整合,形成数据存储文件(例如txt文件)存入文件系统,并向控制台反馈结果。
2)立场检测模块:从文件系统中读取包含用户数据文件,获取用户数据,通过立场检测模型进行立场判断,给每条文本打上分数标签,而后根据控制台的指令,将打上标签的文本数据传递给输出模块或群体立场预测模块做进一步处理。
3)立场趋势预测模块:接收立场检测模块传来的数据,通过群体立场预测算法进行处理,最终形成针对某一话题的立场趋势预测,并将结果传递给输出模块。
4)输出模块:完成两方面功能。一是接收立场检测模块传来的数据,将数据进行整合和转化,形成用户新的属性标签,用以描述用户的精准画像;二是将精准画像的标签数据或立场趋势预测模块传递来的数据进行整合和处理,形成表格或图像形式的分析结果,用于前端展示,同时提供将表格或图像数据存储到数据库中的功能。
5)文件系统:对用户数据文件进行分布式存储与管理。
6)控制台:作为用户接口,进行系统配置和系统控制。
3.3 运行接口设计
系统运行的内部接口主要集中在3个方面,包括:1)用户与请求之间的接口;2)请求与数据库之间的接口;3)Java后端与Python程序之间的接口。
用户与请求之间的接口交互通过浏览器来实现,如图5所示。
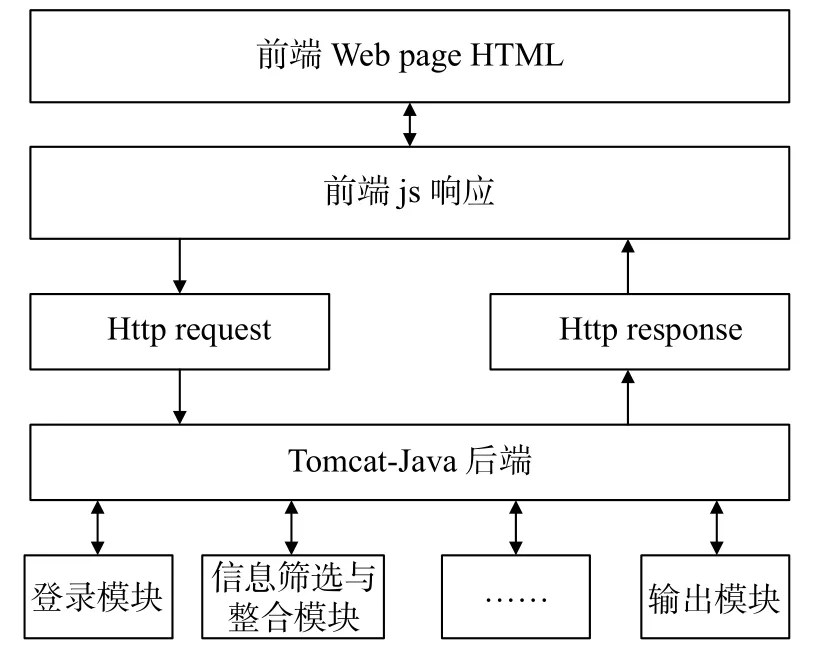
图5 用户与请求之间的接口框架
请求与数据库之间的接口描述,如图6所示。
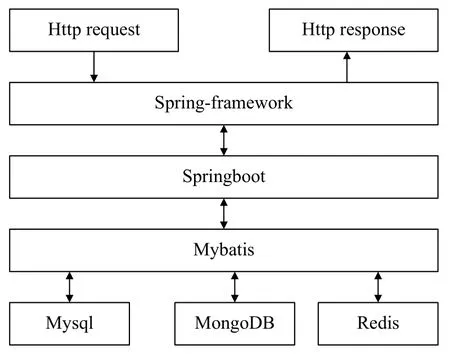
图6 请求与数据库的接口框架
Java后端和Python进程之间的通信架构通过Shell命令进行交互,后台执行Shell命令,运行python程序,获取命令行输出结果。
根据前述总体设计,本系统由控制台、信息筛选与整合模块、立场检测模块、趋势预测模块和输出模块等组成。本节将详细阐述3个核心功能块在运行过程中与其他辅助模块的信息交互,分别是信息筛选和整合模块、立场检测模块和趋势预测模块。
3.3.1 信息筛选与整合模块
信息筛选与整合模块主要由数据缓存、数据筛选和数据整合3个模块组成。其中,首先从控制台接收“取数据”指令,根据指令类型,在数据库中筛选数据,然后根据数据存储地址取数据,缓存到“数据缓存”模块中;接着通过“数据筛选”模块进一步筛选数据;通过“数据整合”模块重建数据结构;最后将处理后的数据传递给文件系统,并将处理结果反馈给控制台。
3.3.2 立场检测模块
立场检测(Stance Detection)模块是本系统的核心组成部件,精准画像功能和群体决策预测功能皆建立在该功能模块的实现之上。本系统的立场检测技术基于自然语言处理领域目前表现最为优异的深度学习模型BERT(Bidirectional Encoder Representations from Transformers)以及广泛使用的Softmax分类器。具体的运行设计如下所述。
1)立场检测模块从文件系统取“文本数据”,而后根据预先设定的字典,将文本中的文字和文字在字典中对应的数字进行映射,即Token化,形成数字序列。
2)将数字序列输入已预训练好的BERT模型,得到数字序列的特征表示,而后取这一特征表示输入进Softmax分类器进行立场识别。立场分为3种:赞同、中立、反对,分别对应分值1,0,−1。
3)最后将立场分值附加到最初的文本数据后面,形成“文本+立场”的新数据结构,并根据控制台的指令送往输出模块或群体决策分析模块。
3.3.3 趋势预测模块
趋势预测模块架构具体的运行设计如下。
1)数据预处理模块首先获取立场检测模块的输出:用户立场,对所有用户的用户立场进行连续化处理,将用户立场转换为区间[−1,1]的实数,其中,用户对目标实体的立场偏积极,则接近1;反之越消极,则越接近 −1。
2)将连续化处理后的立场输入已预训练好的HK模型,得到立场迭代稳定后的用户立场分布。同时将每轮迭代过程中用户立场的实时数据,输出至输出模块进行群体决策变化过程的可视化呈现。
3)将所有用户的立场分布输入至Softmax分类器进行群体决策识别,将结果输出至输出模块。稳定后的群体决策分为3种:达成共识、两极分化和观点分裂。
4 结果与分析
4.1 学习模型结果
本系统在确定最终深度学习模型之前,将立场检测领域主流的3种框架结构进行了一系列的对比实验,具体包括:BERT模型[10]、Ernie2.0+BiLSTM模型[11]和RoBERTa模型[12]。
在实验中,采用了论坛真实数据以及NLPCC会议的公开数据集[13−15]作为测试数据,通过分别对3个模型单独调优,得到表1的实验结果。
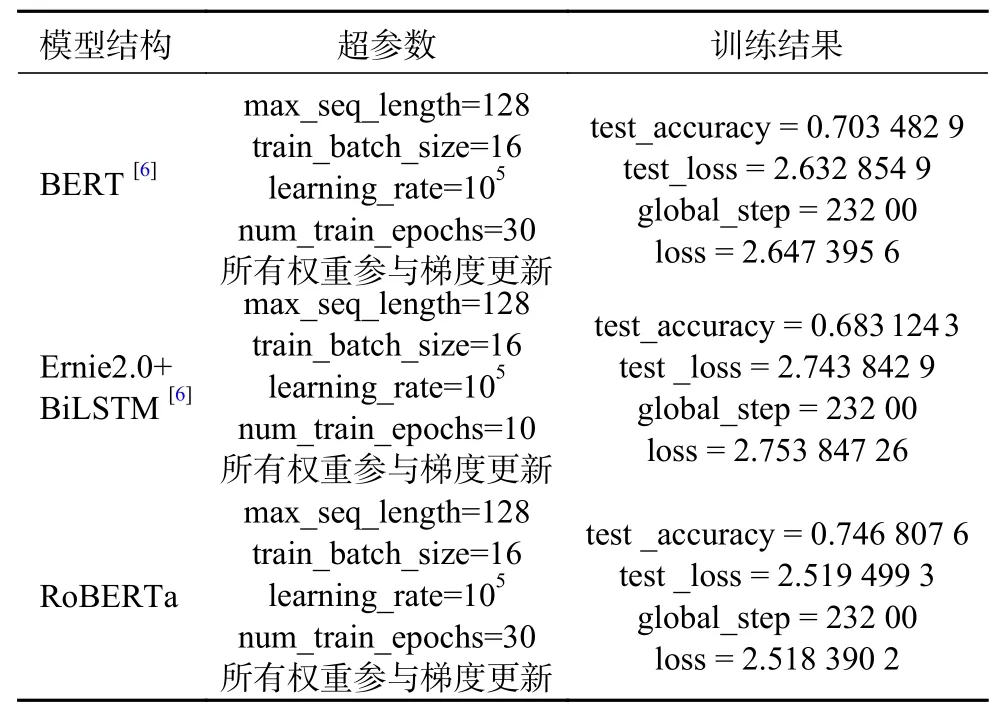
表1 学习模型准确度结果
4.2 软件可视化界面
基于学习模型,立场趋势预测软件的界面是对各个话题的趋势进行预测,如图7所示。其中,横坐标负数值为历史数据,正数值为预测的数据。点击筛选框的选择话题下拉菜单,会显示多个话题供用户选择,手动选择预测开始时间和预测粒度。
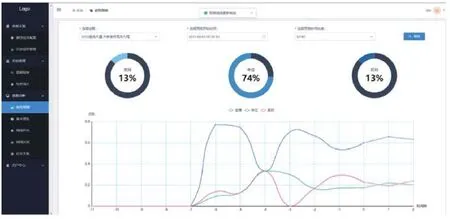
图7 立场趋势预测软件的界面
用户选择完成后点击筛选,开始获取预测图像:①若获取成功,显示图像并提示用户“曲线更新完成”;②若超时,提示用户“预测模块超时,请联系预测人员”;③若选择的时段中没有对应数据,也会提示用户“该时段没有数据,请重新选择!”。
点击预测曲线图中的某一时刻的点,饼图会联动显示“支持” “中立” “反对”情况所占的百分比。
此外,为分析用户画像,软件需要对热帖和热门用户网络行为属性进行分析展示,如图8所示。分析筛选条件包括话题、发帖日期和采集时间。选择条件后点击筛选按钮会返回指定条件下的热帖和热门用户的信息。直接进入该页面显示的信息默认筛选条件为所有话题、所有发帖日期和采集时间。
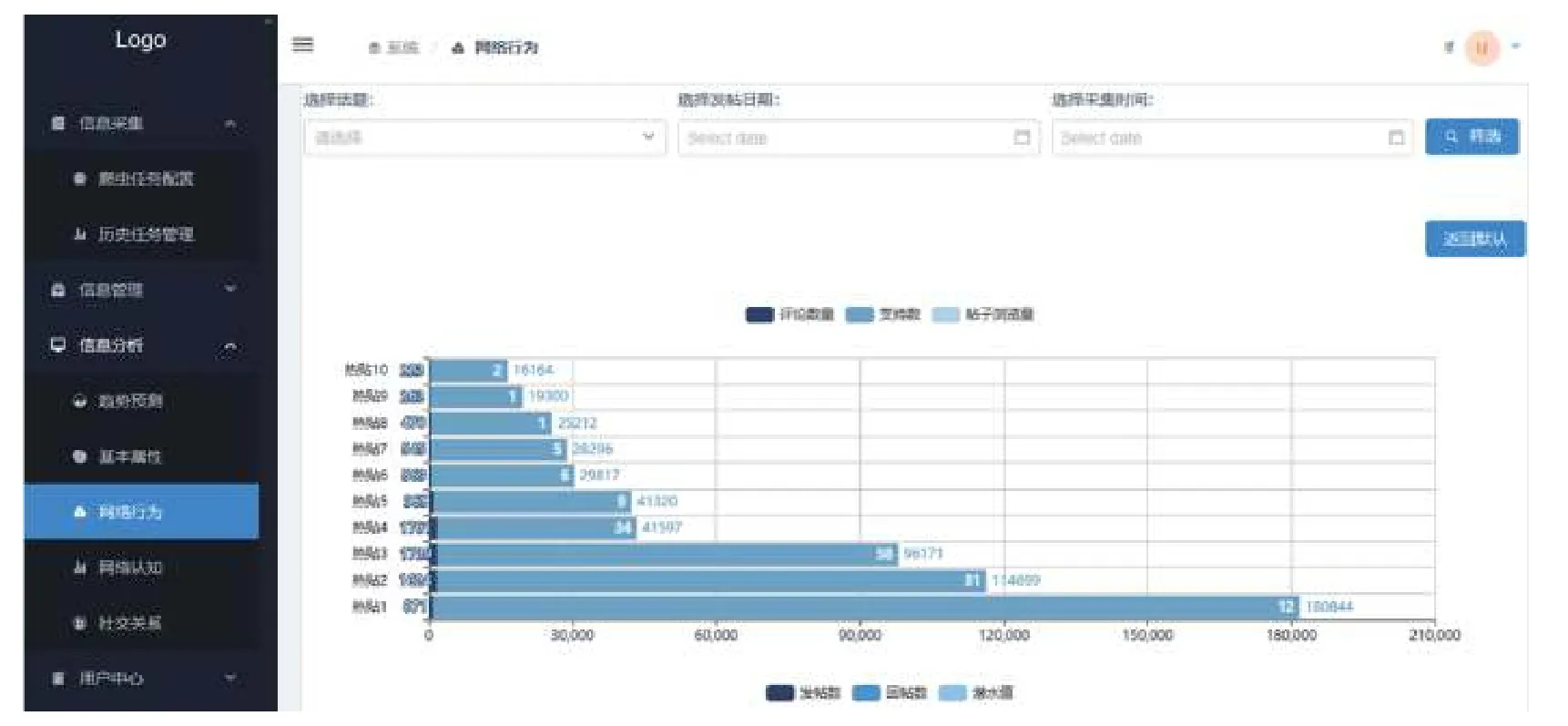
图8 用户网络行为属性分析
猜你喜欢
青年文摘(彩版)(2023年15期)2023-11-20 15:26:47
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
武术研究(2020年3期)2020-04-21 08:36:54
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
河南科技(2014年23期)2014-02-27 14:19:15
