
基于深度置信网络的室内指纹定位算法
2021-07-03 08:13秦益文封志宏苏楠马丁李小菲
河北大学学报(自然科学版) 2021年3期
秦益文封志宏苏楠马丁李小菲
(1.兰州交通大学 电子与信息工程学院,甘肃 兰州 730070;2.河北大学 网络空间安全与计算机学院,河北 保定 071002;3.河北大学 信息技术中心,河北 保定 071002)
自20世纪90年代,全球定位系统(global positioning system,GPS)已在全球进行了定位覆盖,为民众的生活提供了极大便利[1-2].虽然全球定位系统(GPS)是应用最广泛的定位技术,但有统计信息显示,人们在室内的时间超过79%,说明室内定位有着更多的需求空间.然而室内有着更多障碍物遮挡和多径效应的干扰[3],因此至今还没有应用广泛的室内定位技术[4].由于WiFi无线接入点(APs)和移动设备的普及,在声学、磁场、加速度计和接收信号强度(RSS)等室内环境的替代定位技术中,RSS是最受欢迎的定位技术[5].因此,利用智能手机和APs之间的RSS等无线电信号测量成为室内定位最实用的解决方案之一.然而,虽然诸如[6-7]这样的指纹识别算法有可接受的定位精度,但在实时位置估计之前,需要进行大量测量所谓的指纹,为离线训练阶段建立指纹数据库.这在实践中对定位系统的自主部署施加了限制,特别是大型且复杂的空间.在大范围使用指纹定位系统还需要从指纹数据库获取大量数据并存储在移动设备中进行位置估计.即使可以进行费力的指纹识别以后,环境还可能会频繁变化,指纹系统的准确性也会大大降低.因此,指纹识别方法需要定期更新指纹数据库以保持较高的准确性.这些问题严重影响了基于指纹的室内定位系统的应用.
现在已有了许多减少位置标记签名繁琐收集的方法.然而,这些方法使用的降维方案均不能学习定位指纹的隐藏特征.因此,本文提出利用学习隐藏特征的深度学习方法,一方面原因是它能推断单层表示.另一方面,深度学习方法,如深度置信网络(deep belif network,DBN),可以利用生成概率模型来表示不同隐含层的层次隐含特征.每个隐层单元将学习底层单元之间的统计关系;较高的层往往变得更加复杂.本文为了解决位置标记签名繁琐收集的问题,利用无监督预训练阶段,在尽可能保持定位精度的前提下减少标记指纹.DBN 的培训包括2个阶段:预培训和调优.预训练以无监督的方式从未标记的样本中学习概率分布,以减少RSS指纹定位标注的工作量,再进行深度特征学习.
1 相关工作
1.1 无监督学习
假设有未标记的训练数据,无监督特征学习的关键思想是应用反向传播[8].图1所示即自编码神经网络,可用于训练网络来获取一个函数hw,b(x)≈x以近似输出类似于x,其中,x为训练数据,hw,b(x)为通过训练网络得到的关于x的函数,y为输出.模型的参数w进行训练后,任何新输入的值,都可以计算出相应的无监督特征,图2所示即隐藏单元的激活,其中,x为输入的训练数据,hw,b(x)为训练模型,a为计算出的相应的无监督特征.
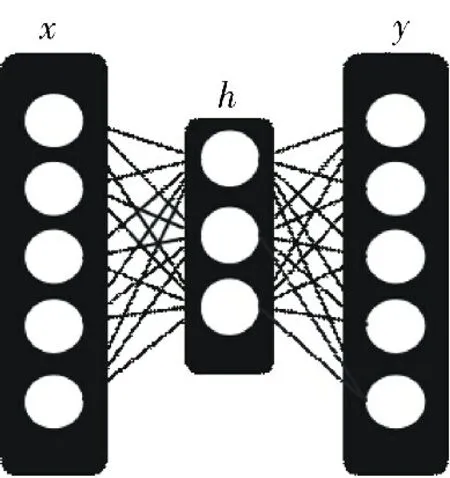
图1 自编码神经网络Fig.1 Unsupervised feature training architecture with autoencoder
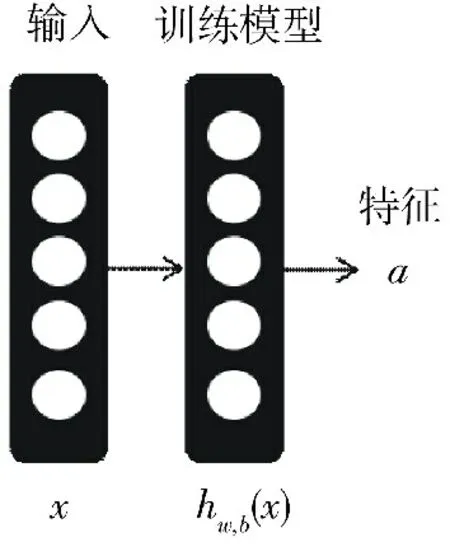
图2 利用已知激活单元的无监督特征学习模型Fig.2 Model for unsupervised feature learning using known activation units
以奇异值分解(singular value decomposition,SVD)为核心的主成分分析法(principal component analysis,PCA)是一种线性特征学习方法[9].由于PCA 只利用数据的浅层表示、输入数据的一阶和二阶矩,因此,它是一种浅层特征学习,且所学习的特性(激活)的数量不能大于输入的维度,这使得PCA 不能很好地描述复杂和非结构化数据的隐藏特征.
1.2 深度置信网络
Hinton等发现[6],DBNs可以通过叠加限制玻尔兹曼机(restricted boltzmann machine,RBMs)来构建.这种RBMs模型可以通过贪婪的方式进行训练,并提取训练数据的深层层次来表示.观测矢量x与l层隐层hk之间的联合分布,其模型如下:
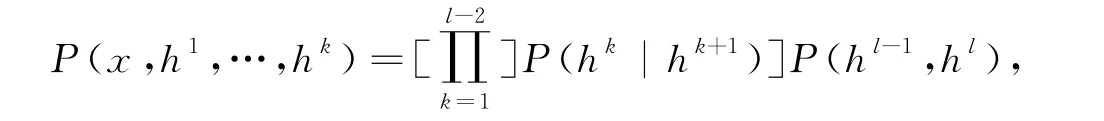
其中,x=h0,P(hk-1|hk)是基于层次k的RBM 隐藏单元的可见单元的条件分布,P(hl-1,hl)是顶层RBM的可见-隐藏联合分布.DBN 可以在图3中可视化为一个RBM 堆栈[10],其中虚线箭头用未标记的数据显示训练前的情况;实线箭头用标记的数据显示微调后的情况.
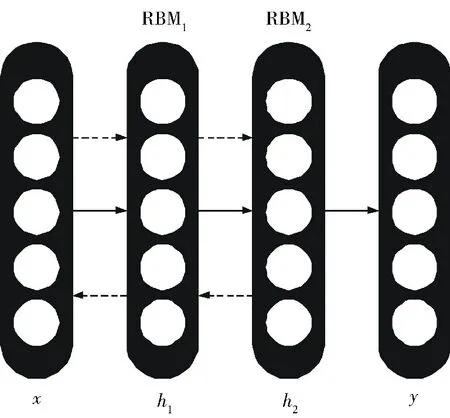
图3 深度置信网络的网格结构Fig.3 Network architecture of deep belif network
训练DBN 网络时,首先用未标记的数据对网络进行预训练.图3中的虚线箭头表示训练前的路径.通过此,得到相应的训练后的RBM 模型,以用来计算特征向量.由于这个自动编码器包含了大量的深度学习模型,RBMs可以提供更好的隐藏特性.这种基于RBM 的方法称为深度特征学习.
2 无监督深度特征学习的深度置信网络指纹定位算法
2.1 算法描述
假设可以获得有限的标记指纹和大量的未标记指纹.本算法将展示基于DBN 的无监督特征学习指纹定位方法,分为离线和在线2个阶段,如图4所示.
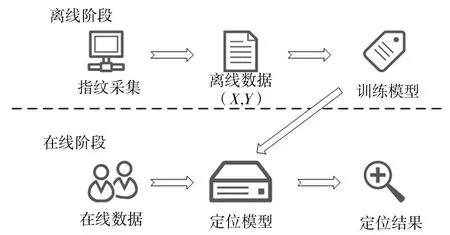
图4 指纹定位模型Fig.4 Model of fingerprint location
在离线阶段,首先利用带标记和未带标记的指纹进行无监督的浅特征学习,然后利用训练好的浅特征学习模型将指纹转化为浅特征.其次,将浅特征用于无监督的深度特征学习.最后,利用浅特征和深度特征学习模型将带标记的指纹转化为带标记的深度特征,然后利用这些深度特征及其位置标签训练监督位置估计模型.在在线阶段,利用离线阶段中训练好的无监督特征学习模型,将未知/测试位置的指纹转化为深度特征.然后利用测试数据的深度特征,利用训练后的监督位置估计模型来推断未知位置.
2.2 特征学习优化
在大型建筑中,通常有许多APs,然而,由于WiFi通信范围的限制,并不是所有的手机都可以从特定的位置进行扫描.例如,图5显示了根据UJIIndoor Loc数据集[7]智能手机扫描的APs的直方图.每部智能手机扫描的平均接入点为18个,而总共有520个接入点.数据集是通过20多个不同的用户和25个不同的Android设备收集的.
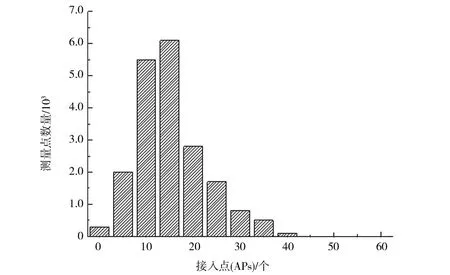
图5 不同APs下的可测点的数量直方图Fig.5 Histogram of the number of measurable points under different APs
由于在每个测量中扫描的APs的数量与可用的APs的数量相比太少,因此测量的很多RSS值都是不可用的.因此,输入在某种程度上是多余的.此外,相邻的APs高度相关因此它们提供非常相似的RSS值.由于冗余和相关性[11],使用核心主成分分析采用SVD[12]来有效地降维.注意,PCA 和SVD 还允许以非监督的方式提取浅隐藏特征,就像文献[7]中研究的那样.
此外,WiFi无线电信号对物体和环境非常敏感,尤其是对人体更为敏感[13].换句话说,RSS测量是有噪声的,因此,使用PCA 白化来降低噪声的影响.
这些浅层特征经过噪声白化和降维处理,作为下一步深度特征学习的输入.需要注意的是,这些浅层特征也可以作为输入来训练指纹模型.在高度动态的室内环境中,由于浅体系结构的泛化程度较低,仅使用前面步骤中学习到的浅特征的定位系统无法长期保持高性能.因此,像DBN 这样的架构可以深度学习代表动态室内环境的高级特征.在这项工作中,本算法采用的预训练阶段.DBN 模型的无监督培训,使用浅的特征标记训练集的RSS测量.使用隐藏层的逐层贪婪预训练算法,保证了一个快捷方式进行近似推理训练每一元.在使用验证集和测试集时,利用训练好的深度特征学习模型将浅层特征转化为深度特征.
为训练能够在在线阶段用于位置估计的指纹模型,本文使用了SVM 的浅监督回归/分类算法.当想要估计的位置在坐标水平时使用回归算法;但当用来估计的位置在房间和地板水平时,将用分类算法来标记指纹以训练监督指纹模型.标记的指纹首先会被转换成浅特征,然后将浅特征转换为深特征.这些深层特征将被用作回归/分类算法的输入.训练后的回归/分类模型存储在服务器上,用于在线阶段的位置估计.
2.3 实时指纹定位
利用离线阶段训练的模型:浅特征学习、深特征学习、位置回归或分类[14],在在线阶段,用户向基于位置服务(location based service,LBS)请求位置估计[15],服务器收集指纹样本并利用训练过的特征匹配算法进行位置估计,最终向用户的智能手机发送新位置的估计.智能手机在未知位置测量的Aps中的原始RSS值将首先用于提取浅层特征,然后提取深层特征.这些未知位置的深度学习特征将作为回归/分类模型的输入,用于估计未知位置[16].
利用离线阶段中训练好的无监督特征学习模型,将未知/测试位置的指纹转化为深度特征.然后利用测试数据的深度特征,利用训练后的监督位置估计模型来推断未知位置.
3 实验评估
3.1 数据环境及数据集
实验环境:操作系统使用Ubuntu 14.04,编译环境使用python3.7,IntelI CoreI i5-5200 CPU @2.20GHz 2.20GHz,DDR3L 4.00GB RAM.
数据集使用UJIIndoor Loc数据集来验证本文提出的方法,它被认为是室内定位的基准.数据集收集于3栋建筑,总表面积108 703 m2.数据集包括19 937个训练测量值和1 111个测试测量值.测试集在训练集之后4个月进行,以确保数据集的独立性.在数据集中,有520个Aps被智能手机扫描.这项实验是由20多名用户携带25款不同型号的智能手机进行的.
在本文中,由于其他2个建筑物的结果相似,将只给出数据集中第1个建筑物的定位结果.第1个建筑物中,在训练集中有5 249个测量值,在测试集中有536个测量值.每个测量值包含520个RSS值,对应于520个Aps,即输入520个维度.所有的标签都标明了实际位置.为了验证无监督特征学习方法的有效性,将训练集随机分为2部分,其中一部分被认为是已标记数据集,另一部分被认为是未标记数据集.这种划分以不同的比例重复,从1%到99%不等.
3.2 评估标准
本算法采用均方根误差(root mean squared error,RMSE)来表示SVM 算法结合浅特征学习和深特征学习的总体性能.定义如下式,计算结果越小,总体性能越优.
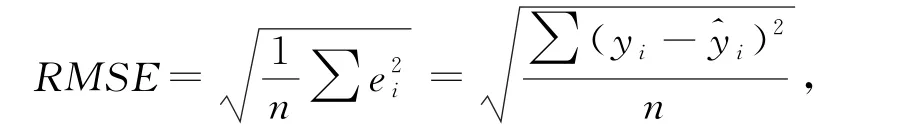
其中,预测误差ei是RSS的实际观察值yi与预测估计值^yi之差,n是测试集.
本算法采用累计分布函数(cumulative distribution function,CDF)详细研究SVM 算法结合浅特征学习和深特征学习的性能.CDF的平滑趋势出现的越早,则性能越稳定.CDF定义如下:
FX(x)=P(X≤x).
3.3 参数设置
为了研究无监督深度特征学习的本地化性能,将SVM 作为回归模型,即所谓的SVR(support vactor regerssion).在先前的研究中,已经表明SVM 优于其他技术.所实现的SVR 融合了深度特征学习和浅层特征学习.因此,基于浅特征学习PCA 的SVR 是传统指纹识别的最佳方法之一.
针对UJIIndoor Loc数据集,首先使用SVD 求解器建立基于PCA 的浅特征学习的参数.由于每部智能手机在建筑训练集中扫描的平均ap数为16,所以将下维数设置为48,以保证足够覆盖信息通道.设置一个大于48的值会导致增加冗余维度和计算量.
对于基于DBN 的预训练阶段的深度特征学习,本算法将网络架构设置为3个200节点的隐藏层.RBM的epoch数量设置为150.RBM 的学习率设置为0.02.该矫正线性单元(Rectified linear unit,Re LU)用于加快训练过程.此设置仅基于使用训练数据集对DBN 的各种体系结构进行的启发式尝试,这些架构考虑了准确性和运行时间方面的性能.
由于位置监督训练与估计是基于SVM 的,且基于POLY 核的神经元网络是一种有效的位置估计方法,因此将SVR 的核设为POLY,多项式核函数次数设置为4,被所有其他内核忽略.
3.4 对照实验及结果分析
图6为SVM 算法结合浅特征学习和深特征学习的总体性能RMSE.在图6中,改变了标记的AP测量值的数量:从52(对应于1%的测量值)到5 246(对应于100%的测量值).当与深度特征学习结合使用时,SVM 可以提供更好的位置估计.但SVM 在与RSS测量的原始值配对时表现不佳,因此本文排除了此结果.
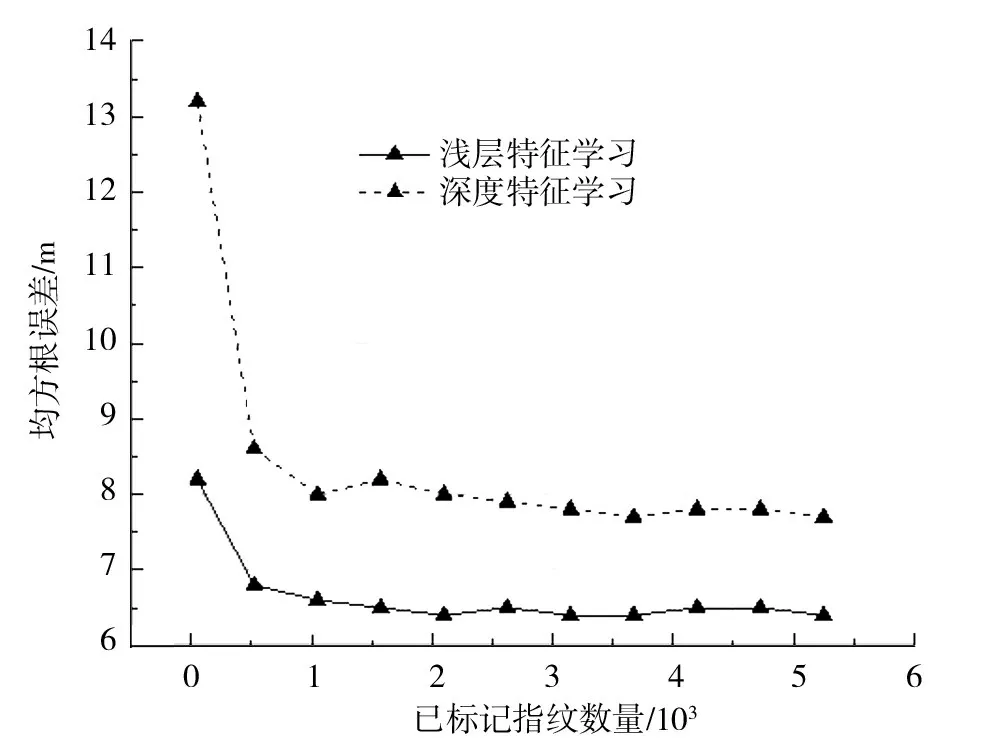
图6 不同指纹数量的均方根误差(RMSE)Fig.6 RMSE of different fingerprints plot
从图6中可以看出,当标记的度量值更多时,2种方法的性能都得到了改善.然而,只有当未标记的测量值低于524时,这种改善才会显著增加.这说明不断增加标记的度量并不一定会提高定位性能,但会显著增加数据收集和注释的成本.
另外还可以看出,深度特征学习可以帮助SVM 算法在标记量较低的情况下保持其定位性能.尽管只使用了78个标记测量值,但深度特征学习SVM 仍可以提供较好的结果.与使用5 246个标记的测量值相比,RMSE只增加了1.876 m(从6.343 m 增加到8.232 m).此外,与使用100%标记指纹的最接近基线方法相比,仅使用15%标记指纹时,本文的方法将定位精度提高2.6 m.
由于图6仅显示了RMSE方面的总体性能,因此使用图7和图8所示的累积分布函数(CDF)图来详细研究定位性能.图7和图8所示的分布是当分别使用78个和5246个标记的测量值时的定位误差.
从图7可以看出,仅使用78个标记时,结合深度特征学习的SVM 仍然表现良好,其中90%的测试位置误差小于19.4 m.从图8还可以看出,结合浅特征学习的SVM 的性能受标记测量值缺失的影响较大,90%的测试位置误差小于29.3 m.
如图8所示,在使用100%标记指纹的情况下,当标记测量量丰富时,浅特征学习和深特征学习的定位性能差异要小得多.此时,结合浅特征学习和深特征学习的SVM 的性能都比较好,非常相似.结合浅层特征学习的SVM 的性能与结合深度特征学习的SVM 的性能有很大的差距.
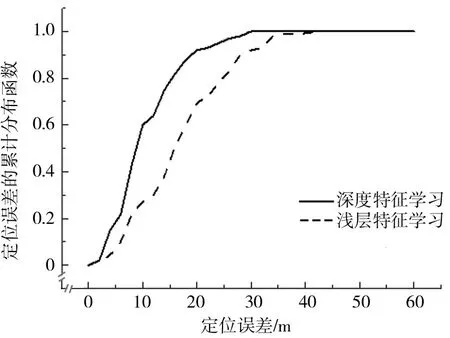
图7 使用78个标记测量值时的累计分布函数(CDF)Fig.7 Cumulative Distribution Function(CDF)with 78 labeled measurements
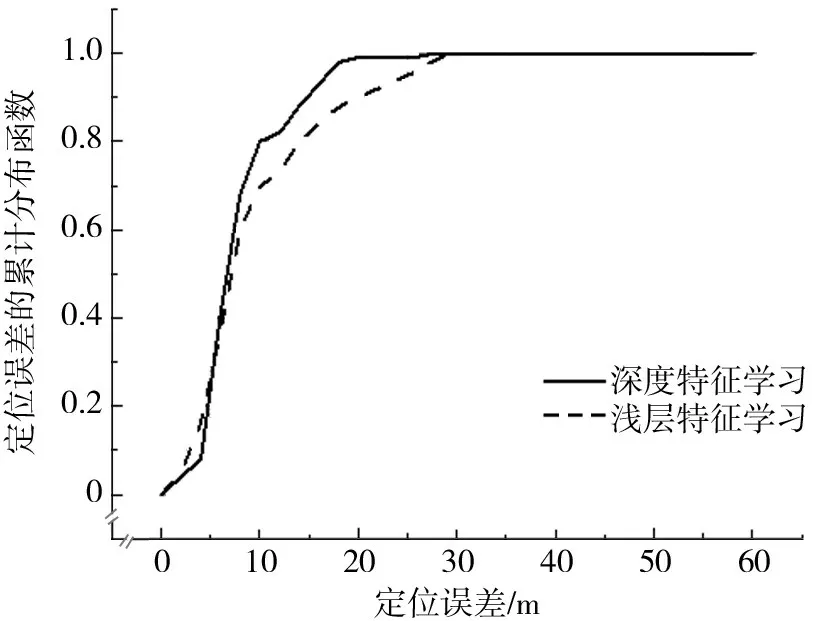
图8 使用5 249个标记测量值时的累计分布函数(CDF)Fig.8 Cumulative Distribution Function(CDF)with 5 249 labeled measurements
4 结束语
提出了一种可以在有限数量的标记指纹上表现良好的新的指纹定位方法.深度信念网络(DBN)的预训练阶段,通常用于为监督分类或回归问题预训练数据.然而,本文使用预训练阶段来训练一个无监督的深度特征学习模型,然后利用该模型提取标记指纹的深层特征进行定位估计.通过上述方法,由于未标记的数据不需要位置注释且对用户的隐私不那么敏感,所以收集起来更方便.此外,与传统的使用标记指纹的方法(如使用原始RSS值和浅特征)相比,从大量未标记指纹中学习深度特征可以提供更好的定位精度.
使用支持向量回归(SVR)和一个最通用的真实世界数据集来验证本文的算法,该数据集包含大量样本.实验结果表明,SVM 与深度特征学习相结合的新方法优于传统的SVM 与浅层特征学习或原始数据相结合的方法.此外,即使使用只有1.5%标记指纹的深度特征学习,均方根误差(RMSE)仍然与使用100%可用标记指纹的传统浅层特征学习一样好.
在未来的工作中,将使用更多的基于WLAN 的指纹数据集来验证本文算法,并开发深度转移特征学习技术来从不同的数据域提取隐藏特征,如可以从其他不同的室内环境中采集到的未标记指纹中提取出室内环境的隐藏特征.
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
小天使·一年级语数英综合(2020年10期)2020-12-16
中国外汇(2019年20期)2019-11-25
福建基础教育研究(2019年6期)2019-05-28
海峡姐妹(2018年2期)2018-04-12
人大建设(2018年12期)2018-03-21
杂文选刊(2018年1期)2018-01-09
儿童时代·快乐苗苗(2016年2期)2016-10-22
青少年科技博览(中学版)(2015年7期)2015-08-12
