
基于Neo4j 的数据空间多源异构数据集成管理研究
2021-07-03 03:52李帅郭妍彤周文迪
现代计算机 2021年12期
李帅,郭妍彤,周文迪
(四川大学计算机学院,成都610065)
0 引言
随着制造业信息化和工业化不断融合,制造过程中涉及到的数据呈现多源化、异构化,数据具有典型的“4V”特征[1],这些数据涉及人、机、料、法、环,能够帮助制造商提高设计和生产效率,降低缺陷和返工,更好地满足客户需求和进行有效的营销[2]。涉及人、机、料、法、环的数据是多源异构的,制造企业中数据来源多方、结构各异,如何集成这些数据才能打破“数据孤岛”[3]、建立数据生态、降低企业成本、开发潜在价值是目前诸多企业迫在眉睫的任务。
传统关系型数据库储存的是结构化数据,一个数据库通常只储存一种类型数据,不同数据库间可能存在关联关系,但是数据库之间的关系却得不到体现,不能有效满足查询需求。特别地,这一问题在企业数据上尤为突出。随着企业发展,数据越来越多,呈现指数级增长趋势,各数据库是自治的,逻辑上存在联系,但物理上却是分开的。有学者用分布式系统[4]实现这些数据库的联系,但存在并行带来的高开销问题,数据一致性得不到保障,对非结构化数据存储管理不足[5]。随着多维数据、半结构化数据和非结构化数据越来越多(Web 页面、视频、音频、图片等),企业面临的数据管理问题愈加严重,如何集成这些多源异构的数据显得尤为困难,人们开始考虑迁移到其他数据库[6],许多学者提出过多种数据存储架构,包括数据仓库[7]、数据湖[8]、数据中台[9],但效果并不理想。
数据空间是指某一实体拥有的所有信息以及从这些信息中抽象出来的一些关联数据的集合[10],在逻辑上是一张图,其构建过程为pay-as-you-go 的方式[11],不像传统数据集成时pay-before-you-go 的构建方式,也不像数据湖弱化多源异构数据的数据关系。数据空间是以图结构的形式集成多源异构数据,降低数据存储空间,保障源数据可寻,不受数据格式影响,打破多源数据之间的壁垒,构建数据生态。本文提出的基于Neo4j 的数据空间模型由本体关系、包装代理、身份识别、数据集成四个部分组成。
1 数据空间架构
数据空间不再是数据库的简单聚集,而是多源异构数据的代理。数据空间的构造途径是集成、更新多源异构数据集,主要包括本体关系、包装代理、身份识别。数据空间主要包括三类数据:关系数据、元数据、数据内容。关系数据是指数据集间关系或构建的实例间关系,例如制造企业中工人与车间的关系;元数据是指数据内容的描述信息,包括数据名称、数据格式、数据基本属性等;数据内容是指数据项的具体内容,既对应的视频文件、音频文件、表文件等。如图1,关系数据源自本体关系,元数据源自包装代理,数据内容与身份识别对应。

图1 数据空间中各模块集成数据流程
数据空间作为一种数据管理技术面临着诸多挑战,既要求集成多源异构的数据,同时具备对数据的增加、删除、查找、修改等传统问题。数据空间集成了RDBMS、Email、Document、Mobilephone、WebPage、XML、Image 等数据源。如图2,数据空间中的数据是高度异构的,但是在数据操作时要求数据具有大致相同的格式,因此数据扩展是数据集成的第一步,既对源数据建立包装代理(wrapper),抽取特定格式的数据对象建立图数据库,在数据空间中通过链接访问源数据。
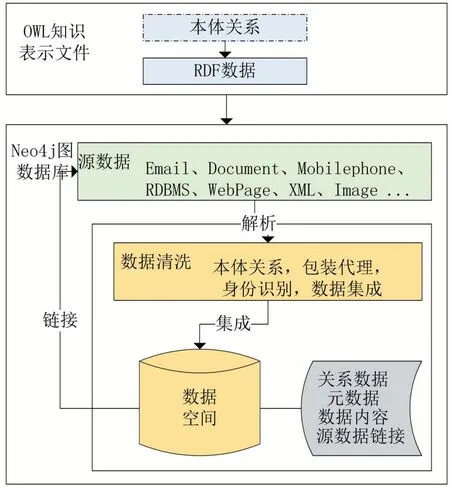
图2 数据空间架构
本文提出的基于Neo4j 的数据空间多源异构数据集成模式是将源数据与数据空间分离的模式,源数据解析到数据空间,保证了数据可变但模式稳定。数据空间的任务是对多源异构数据(RDBMS、Email、Docu⁃ment、Mobilephone、WebPage、XML、Image)建模,包括构建本体获得本体关系、包装代理、新数据身份识别、数据集成,获取关系数据、元数据、数据内容和源数据链接。Neo4j 图数据库存储数据和关系,并具有数据挖掘功能[12],节点信息包含元数据、数据内容以及源数据链接,关系数据表示节点与节点的关系。通过链接对源数据操作,解决数据一致性问题,同时也避免了数据空间因源数据导入而导致存储空间快速激增问题。
2 本体关系
Protégé编辑本体,获得一个用OWL 表示的知识表示文件。对于结构化数据,利用D2RQ 转化工具把表数据转化成虚拟的RDF 数据[13],使数据在RDF 层面实现数据格式的统一。对于非结构化数据,需要对本体数据“包装代理”处理,以建立链接方式获取数据源。如图3 所示,将数据存储到图数据库Neo4j 中主要包括两个部分,其一为将本体数据转化为RDF 数据,其二为把RDF 文件映射到Neo4j。RDF 是三元组数据<主体,谓词,客体>,一般情况下RDF 三元组转换到Neo4j 图数据库分为两种情况,第一中是转化为两个节点,以及这两个节点对应的关系,第二种是转化为一个节点和节点对应的属性。具体转化方式根据实际情况而定。

图3 OWL文件存入Neo4j数据库流程
3 包装代理建立
数据库集成面临的最大困难是多源数据格式不统一,使得存储、查询、修改等不能得到解决,包装器的目的是对多源异构的数据进行统一表示,经由包装器把RDBMS、Email、Document、Mobilephone、WebPage、XML、Image 等数据集成到数据空间,交由图数据库管理。
定义1:将源数据视为node,把该node 用五元组(εDB,πDB,ωDB,γDB,τDB)表示,其中εDB是源数据名称,πDB是源数据标示信息,ωDB是源数据内容,γDB是源数据内容标示信息,τDB是识别数据。
εDB(源数据名称):εDB=DB,DB是源数据库名称,εDB可为NULL。
πDB(源数据标示信息):πDB=<C,T>,其中C,T表示源数据的标示信息,包括源数据初次创建时间,数据库大小,以及数据的更改时间,既C=(creat time:data,size:int,modidied time:data),T=(data1,int,data2)。
ωDB(源数据内容):源数据的每个字符为ωi,则ωDB=∑ωi,表示所查数据的所有内容。
γDB(源数据内容标示信息):令γDB=<N,Nf,Ro>,表示源数据内容的标示信息,其中文件名N=<dc1,dc2,dc3,dc4…>,文件格式Nf= <.txt, .doc,.pdf,.xml, .jpg, .mp4…>,列名Ro= <col1,col2,col3,col4…>。

根据τDB建立各源数据间关系,对源数据间关系定义如下:

4 身份识别
当有新数据加入数据空间时要判断数据相关性,数据空间会在存储数据时对数据进行评估,如果数据对象与主体相关,则存储,否者放弃该数据对象。身份识别步骤如下:
(1)通过包装代理提取新数据NewDB的识别数据信息τNew;
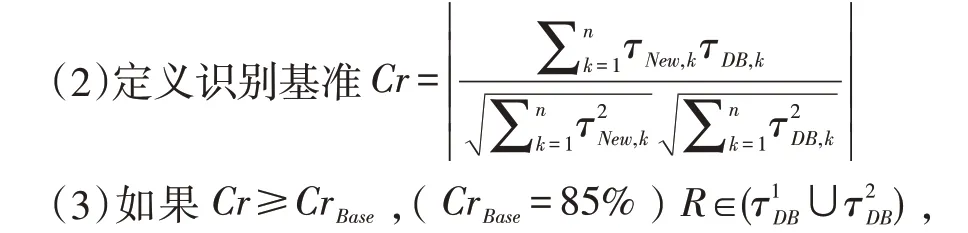
则识别成功;
(4)如果Cr<CrBase,放弃该数据对象;
(5)建立节点加入NewDB
身份识别流程如图4。

图4 身份识别流程
5 数据空间集成
数据空间是对多源异构数据集成管理的系统,是由数据构成的高维空间,它包含数据内容以及数据之间的关联关系,这些数据以图结构形式集成,反映数据间的生态关系。在制造企业中,与产品相关的五大因素为:人、机、料、法、环。“人”指生产设备的操作人员,“机”指生产的执行设备,“料”指生产加工使用的原料及工具,“法”指生产加工的方法,“环”指生产环境[14]。数据空间则是集成管理人、机、料、法、环相关数据。

实体用三元组表示:节点(Node)、关系(Relation⁃ship)、属性(Properties)。其中,可以为节点、关系赋予相应属性。在节点上赋予属性,当数据储存时,内存消耗可以得到有效解决;为关系赋予属性,则可以更加灵活扩展模型。无论是节点还是关系,都可以拥有多个属性用来描述其特征,节点间可以相互建立关系,每个节点可以设置多个属性的键值对(Key,Value),每个关系有from Node 和to Node,同时每个关系可以设置多个属性的键值对(Key,Value)。
RDF 是三元组数据<主体,谓词,客体>,其中主体或者客体对应Neo4j 中的节点,谓词对应于节点与节点之间的关系,存入Neo4j 后由于节点名称的存在,如果要在数据库中找到存放的节点,必须要建立索引。

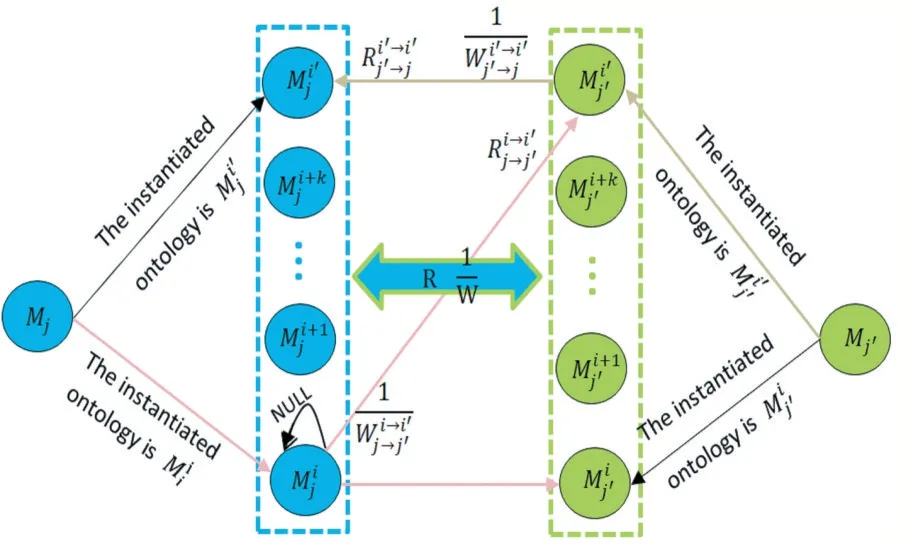
图5 数据空间节点存储模型


目标问题的求解算法:
输入:源数据
输出:元数据、实例化主体

其中,P 表示问题的答案范围,当P 可以由DB 直接得到时,不需要进行额外元数据提取,只需完成步骤一。adhoc()是元数据提取函数,Function(R)是节点关系函数。当目标P 的范围超过DB 但小于πDB时,继续步骤二,返回源数据名称εDB。当目标P 的范围超过πDB但小于εDB时,继续步骤三,返回源数据内容ωDB。当目标P 的范围在关系R 的范围内,返回识别实例化主体τDB。当新数据加入到数据空间时,如果CrNewDB>CrBase,则循环以上所有步骤。
6 实验与分析
6.1 实验环境
处理器Intel Core i7-7700HQ CPU @ 2.80 GHz,RAM 8.00 Gb,64 位操作系统,Protégé5.2.0,Neo4j-com⁃munity-3.5.9,Java1.8.0_181,Eclipse4.3.0。
6.2 实验结果与分析

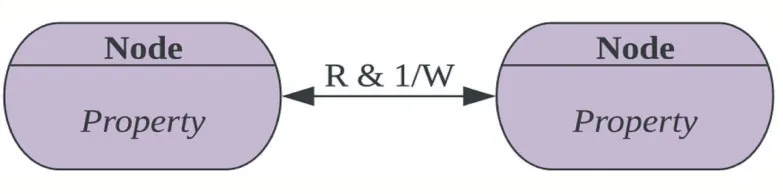
图6 节点与节点关系
集成人、机、料、法、环相关数据到数据空间如图7,数据空间是一个复杂网络,包括节点、关系、权重以及节点属性。节点是源数据中的实体,关系是指实体之间存在的关联关系,权重是指关联关系的重要程度,属性是源数据的值。通过源数据的相关记录,基于Neo4j图数据库建立实体之间关系。
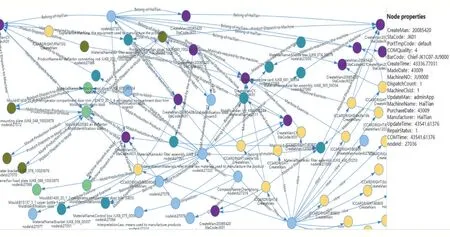
图7 集成人、机、料、法、环数据


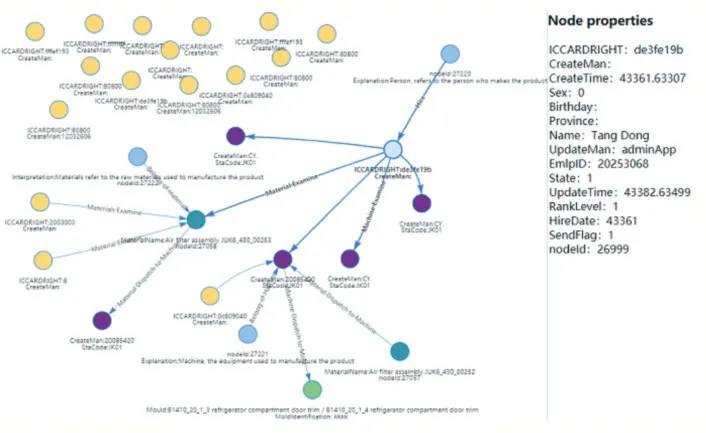
图8 集成“人”相关数据
因为数据空间的复杂性,在查询数据时需要对节点数目限制,根据实例化本体的限制,得到的节点个数和关系也是受到限制的,这样的好处在于选取复杂网络的部分结构,从而避免复杂网络造成不易理解的弊端。根据查询节点的不同,数据空间也不同,如图9 所示,限制节点数为15,实例化“机”本体,得到数据空间中集成的机器数据以及与其相关的信息组成的关联网络。同样限制节点数为15 时,集成在数据空间中与“料”相关的信息如图10 所示,包含了由人、机、料、法、环构成的关联网络。
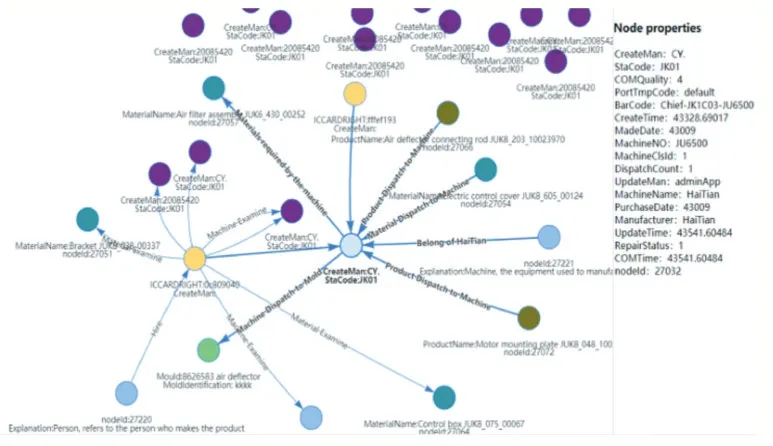
图9 集成“机”相关数据

图10 集成“料”相关数据


图11 是把本体“人”实例化后在数据空间集成的效果。节点属性除了包括节点的基本信息外还包括源数据链接,通过链接访问源数据。这里的链接是指多源异构的数据的存储路径,可以是本地路径也可以是远程路径。这样集成数据的好处有以下两方面:一方面减少数据储存空间的消耗,另一方面是当需要查询源数据时有路径可寻。
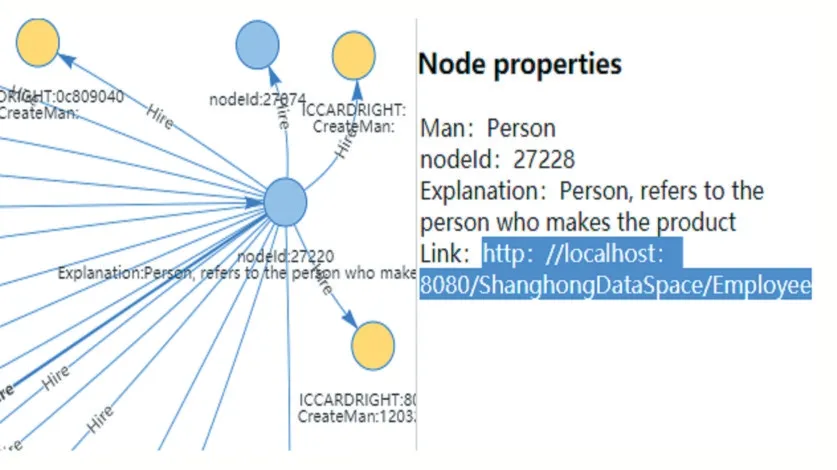
图11 数据空间链接到源数据

图12 节点数目改变时实体数量与关联关系
7 结语
数据空间打破“数据孤岛”,集成管理多源异构数据。使以前独立存储于各数据库的数据有了关联,组成数据生态,数据与数据产生联系,为数据赋予了新生命的同时也产生潜在的不可估量的价值,这为数据挖掘和数据分析提供便利。在生产制造过程中,根据数据空间生产线权重变化,不断调整企业“人机料法环”的配比,确保生产安全,降低生产成本,提高产品质量,数据生态良性循环。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
导航定位学报(2022年4期)2022-08-15
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
齐鲁艺苑(2022年1期)2022-04-19
现代电子技术(2022年4期)2022-02-21
智能计算机与应用(2021年4期)2021-06-05
哈哈画报(2021年10期)2021-02-28
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年11期)2019-05-28
