
基于多维度匹配的知识库问答实体链接
2021-07-03 03:51张森张攀
现代计算机 2021年12期
张森,张攀
(1.四川大学计算机学院,成都610065;2.四川大学视觉合成图形图像技术国家级重点实验室,成都610065)
0 引言
近年来,随着知识图谱(Knowledge Graph,KG)技术的不断发展,其易扩展、表达友好等特性越来越被认可。KG 常见的知识组织形式有RDF(Resource Description Framework)、RDFS(Resource Description Framework Schema)和OWL(Web Ontology Language)。不同的知识组织形式也催生出了不同的KG,其中常见的有Freebase[1]、WikiData[2]、DBpedia[3]和YAGO[4]等。KG 作为一个知识库被广泛的应用在需要先验知识的智能系统之中,例如:用户兴趣推荐系统、精准搜索和问答系统。其中问答系统就是利用自然语言处理技术对问句进行语义与语法分析,理解用户问句中表达的含义,随后结合知识库搜索出用户想要的答案。
常见的KG 大多以RDF 三元组的形式表示知识,三元组通常可以表示为如下形式:<eh,r,et>其中eh代表头实体,r表示实体之间的关系,et代表尾实体。而基于知识库问答系统的工作原理为首先分析确定问句中的eh和r,然后利用正确的eh和r到知识库中查询到对应的et。在自然语言式的问句中得到eh的过程称之为实体对齐,解析出r的过程称之为关系检测或者关系抽取。
实体对齐主要分为两部分:命名实体识别(Named Entity Recognition,NER)和实体链接(Entity Linking)。命名实体识别主要将问句中的实体名(通常包含人名、地名、机构名等)标注出来。通常短文本的NER 效果很好,因此实体对齐重点往往聚焦于实体链接部分。
在KG 中可能存在多个实体名字相同或者相似的情况,但是每个实体有唯一的ID 进行辨识。其中实体名相似或相同的实体集合称之为实体候选集,而实体链接就是从实体候选集中选出正确的实体。
1 相关工作
实体链接本质上是一个实体消歧的过程,实体消歧根据不同类型的数据有不同的消歧的手段。在面向单条短问句的实体消歧过程中,常见的方法主要有两种:基于实体显著性和基于实体上下文相似度[5]。实体显著性描述的是实体固有的属性,通过对实体显著性的统计从候选集筛选出显著性最高的实体从而完成消歧的过程。通常实体显著性的各种指标均为手工定义的规则或范式,因此不具有泛化性,并且显著性特征定义的好坏会直接影响实体消歧的结果。相比显著性统计,上下文相似度的方法具有了更大的灵活性并且考虑到了实体语义层面的含义。常见的上下文相似度方法有:分类法[6]、聚类法[7]、主题法[8]、概率语言模型法[9]。随着深度学习的兴起,上下文相似度出现了新的度量方式[10-15],通常该类方法将文本嵌入到一个低维的分布式向量空间,运用不同的网络模型提取语义特征,根据语义相似度最终完成实体消歧。
虽然实体链接方法众多,但是针对简单问句的实体链接仍然具有很大的挑战性,其主要的困难主要包含以下几点:
(1)简单问句中实体名称不规范,可能出现缩写、别名以及拼写错误等情况;
(2)简单问句上下文不丰富,对实体消歧起到的作用微小甚至无用;
(3)知识库中实体的描述信息不充分甚至缺乏,导致比对候选实体上下文相似度无法进行。
针对上述问题,本文提出了一种多维度匹配方法。该方法是实体显著性与深度学习的组合。其中,文本维度匹配较大程度保证实体名不规范等情况;统计维度匹配能在不需要问句上下文的情况下完成实体链接;最后实体属性匹配利用实体属性信息进一步修正实体链接结果。该方法在合适的组合方式下能达到较高的实体链接准确度。
2 本文方法
实体对齐分为命名实体识别与实体链接两个过程。命名实体识别在简短式的问句中通常表现很好,本文主要聚焦于实体链接这个过程。
2.1 多维度匹配的总体设计
实体链接主要从文本匹配、统计匹配和实体属性匹配这三个维度展开,其过程如图1 所示。
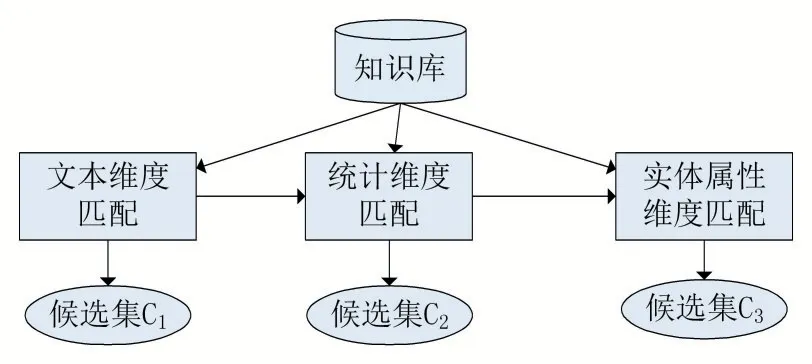
图1 多维度匹配总设计
其中文本维度匹配主要功能是产生一个合理大小的实体候选集c1,统计维度匹配利用实体的一些显著性指标(例如:实体热度)完成候选集重排序,得到新的候选集c2。实体属性匹配利用实体属性(例如:实体关系、实体类型)进一步修正实体候选集的排序,得到最终候选集c3。
2.2 文本维度匹配
问句中实体名称由命名实体识别得到,要将其链接到知识库中一个正确的实体上,首先应该进行文本维度匹配筛选出实体候选集。实体名称的文本相似度可以采用编辑距离来衡量。编辑距离是指将字符串a转化为字符串b 最小操作次数。其递推过程如式(1)所示。

其中LDa,b(i,j)表示字符串a 的前i 个字符子串转化到字符串b 前j 个字符子串所需的最少操作次数。得到编辑距离LDa,b后,再根据字符串a,b 的长度La与Lb,即可通过式(2)计算出相似度Ra,b。

不难看出,实体候选集为了尽可能地覆盖到正确答案就必须采用较小的相似度R,但是过小的R可能导致实体候选集过大同样也会影响实体链接的最终效果。通常R≥0.8 表示有微小的拼写错误,而R<0.8 则表明实体名拼写完全错误不予识别。
由于实体名拼写是否规范,通常与实体名本身复杂程度有关,针对简单且易于拼写的实体名而言,如果固定的阈值R太小,导致实体候选集过大,相反,复杂不易拼写的实体名,如果R太大,则实体候选集过小。可见,固定R很难获得一个合理大小的候选集,从而间接影响最终实体链接效果。因此,本文采用一种多级阈值的方法生成实体候选集。即设置一组从大到小的阈值依次进行匹配,其中本文设置三级阈值分别为:精确匹配阈值(R=1.0);较精确匹配阈值(R≥0.9);一般匹配阈值(R≥0.8)。其中下一级阈值只在上一级阈值没有匹配到实体的情况下生效。
2.3 统计维度匹配
文本维度匹配生成实体候选集,在统计维度匹配中利用实体显著性特征对进行实体候选集进行重排序。其中统计维度匹配主要是统计实体热度,然后根据热度对初始候选集进行重排序。
在Freebase 知识库中,每条知识按照三元组(<eh,r,et>)方式组织。因此,实体热度大小用该实体在知识库中r的数量表示,r的数量越多热度越高。反之越低。其中实体作为eh出现,那么所有r的数量总和称为出度。实体作为et出现,那么所有r的数量总和称为入度。通常出、入度之和代表实体热度。但是本文只用出度代表实体热度。其第i 个实体热度得分scoreh(i)由热度值hoti归一化得到,其计算方式如式(3)所示:
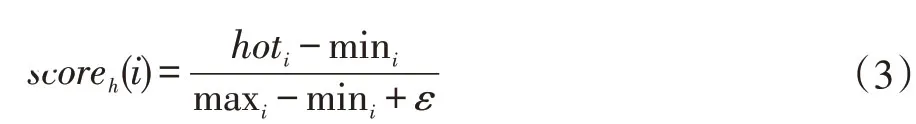
其中maxi、mini为最大与最小热度值,ε参数为防止下溢,本文取0.001。
2.4 实体属性维度匹配
在统计维度匹配后,可以根据实体排名先后选出top-1 或者top-k 的实体作为最终链接结果。但是实体热度高不一定是链接的目标实体,因此为进一步提高链接准确度,再利用关系属性对实体候选集进行新一轮排序。
在Freebase 知识库中实体一般包含多种关系,不同实体由于类型不同包含的关系也不同。例如针对于“苹果”这一词,在知识库中与之对应的可能是水果也可能是公司,但是对于问句“苹果现在的市值是多少?”可以得到其实体为“苹果”,预测的关系为“股票总市值”,而水果类型的苹果肯定不包含“股票总市值”这一关系,因此通过实体关系是可以达到区分实体的目的。
实体类型预测作为一种分类任务,其采用整个问句作为预测上下文,即从问句完成到实体关系的一个分类过程。为了达到更好的预测效果,本文提出了一种基于Transformer[16]的关系预测模型。其模型架构如图2 所示。该模型为一个典型的编码器(Encoder)-解码器(Decoder)结构,其左边为编码器部分,右边为解码器部分。

图2 Transformer关系预测模型
该模型的编码器部分主要由两部分组成,第一部分为输入预处理部分,完成对问句的词嵌入(Questions Word Embedding)与位置编码(Positional Encoding)任务。第二部分为问句编码部分,主要有三个模块:多头注意力(Multi-Head Attention)模块;层归一化(Norm)模块;全连接前馈神经网络模块(Feed Forward)。此外,每进行一次多头注意力或全连接前馈神经网络模块都会进行一次残差连接。
解码器部分与编码器类似,主要包括三个部分。第一个部分为输入预处理,该输入是针对实体类型进行的,其中实体类型的词嵌入(Entity Types Word Em⁃bedding)与编码器中问句的词嵌入共享参数。第二部分解码部分,解码器进行了两次多头注意力模块的计算,第一次多头注意力机制是对实体类型进行的,第二次多头注意力机制是对问句与实体类型共同进行的。最后为输出预测部分,通过一个单向的GRU 得到一个全局的语义表示,该层是为了进一步提升语义抽取与位置信息表达的能力,最后通过一个线性映射和Soft⁃max 层输出某种实体关系。
由于关系预测总会存在错误,因此本文额外选取了top3 实体预测关系进行候选集匹配,其第i个实体得分scorer(i)计算如式(4)-(5)所示。

其中α为权重参数,rx表示第x个预测关系,vx则为对应关系权重,Ri为第i个实体所有关系集合。
3 实验
本节主要验证本文提出的多维度匹配方法在实体链接中的有效性,以及多维度相比单维度的提升效果。因此,实验主要包含统计维度匹配实验,以及实体属性匹配中的关系预测实验。
3.1 实验数据
本文实验选取的数据集为SimpleQuestions[17],它是一个基于Freebase 知识库的问答数据集,其训练集与测试集样本数分别为75910、21687 条,其样本如表1所示。

表1 原始数据集
Freebase 在2016 年停止运维,因此本实验采用Freebase 的子集FB2M[17]作为知识库,由于原始的Sim⁃pleQuestions 数据集某些样本的实体无法识别以及无法在FB2M 中查询到,因此经过整理后其数据信息如表2 所示。
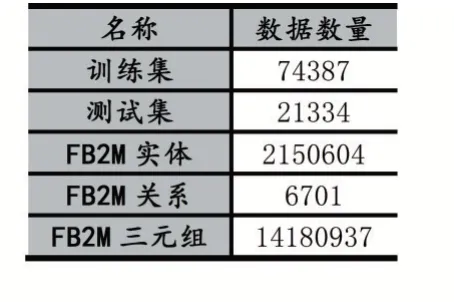
表2 数据信息
此外,由于SimpleQuestions 数据集只包含真实的实体ID,没有对应的实体候选集,因此需要根据实体ID 在FB2M 中查询出该实体名称,利用文本维度匹配方法,即在知识库中筛选出所有与该实体名称相似的所有实体ID,生成初始的实体候选集。其数据如表3所示。

表3 实体链接数据集
3.2 统计维度匹配实验
(1)实验设计
首先文本维度匹配生成对应的实体候选集,在统计维度匹配中,统计出实体热度,然后根据式(3)算出scoreh,利用scoreh大小对候选集重排序,最后选出得分最高的实体作为最终链接结果,其中评价标准采用准确率(Accuracy,ACC)。
(2)实验结果与分析
实体热度采用入度、出度、入度+出度分别进行实验,其实验结果如表4 所示。
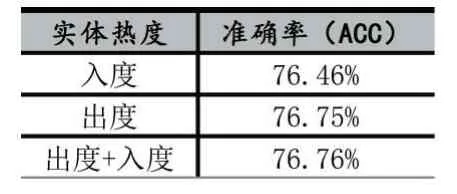
表4 统计维度匹配结果
从实验结果可以得知,采用出度+入度的方式能达到最佳效果,但是三种衡量实体热度的实验结果差异不大,尤其是在只用出度表示实体热度时。因此,只用出度代表实体热度时,不仅不会造成准确度大幅下降,而且还能很大程度减少统计时间,尤其是在知识库体量很大时,效果提升明显。为此,本文额外采用了一个Freebase 的子集FB5M[17]作为对比,它包含比FB2M 更多的实体与关系,并在测试集下进行时间统计测试,其结果如表5 所示。

表5 统计耗时对比
3.3 实体属性匹配实验
该实验分为两部分,首先利用基于图2 所示的关系预测模型对实体关系进行预测,其次利用预测关系对候选集进行匹配,最终得到实体链接结果。
(1)关系预测实验设计
关系预测即利用问句与实体类型预测出对应的问句中包含的关系。此外,为了缓解关系预测错误带来的影响,本实验同时预测出top-1 与top-3 的实体关系,其中衡量指标仍采用ACC,最后为了验证模型有效性,实验同时还构建了BiLSTM[18]、BiGRU[19]、Transformer共3 种关系预测模型作为对比研究。
(2)关系预测实验结果与分析
关系预测实验采用GloVe 作为预训练词向量,优化器采用Adam,同时为了防止过拟合引入了Dropout,其模型主要配置参数如表6 所示。
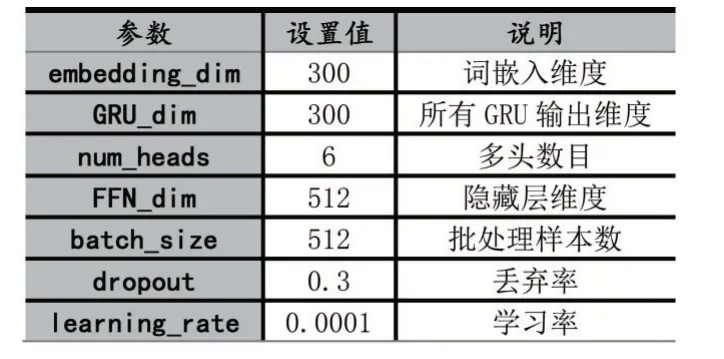
表6 Transformer 关系预测模型主要参数
关系预测模型实验结果如表7 所示。

表7 关系预测结果
通过表6 可知,基于Transformer 的关系预测模型无论是在top-1 还是top-3 上都表现更好。其次相比于top-1,top-3 能明显提高正确关系的覆盖率。
(3)关系匹配实验设计
实体关系匹配利用预测出的实体关系对实体候选集进行再次重排序。该实验分别对第一个预测关系(top-1 rel)和前3 个预测关系集合(top-3 rels)进行候选集匹配,同时加入正确的关系(true rel)进行对照。
(4)关系匹配实验结果与分析
该实验中的top-1 rel 与true rel 方案只包含一个关系,因此从实体候选集选出scoreh值最大,并且包含该关系的实体即为最终结果,而top-3 rels 则是根据式(4)-(5)计算出关系得分scorer,然后将scorer值最大的实体作为最终结果。该实验最终实体链接结果如表8所示。

表8 实体属性维度匹配结果
利用true rel 进行实体候选集匹配,其最终实体链接准确度能达到85.64%,相比只用统计维度实体链接准确度(76.75%)有了明显提升,证明实体关系能修正实体链接结果,同时多维度匹配的有效组合能大幅度提高实体链接准确度。此外,对比top1 rel 与top3 rels实验,说明选取top3 实体关系提升了实体链接效果,其主要原因是缓解了实体关系预测错误而造成的错误累计问题。
此外本文还对比了state-of-the-art 方法,其结果如表9 所示。值得一提的是,本文前面的工作提前对不能识别出实体的样本做了预处理,因此为了更加客观公正地做出对比,实验数据将不做预处理(测试集样本数由21334 重新调整为21687)。
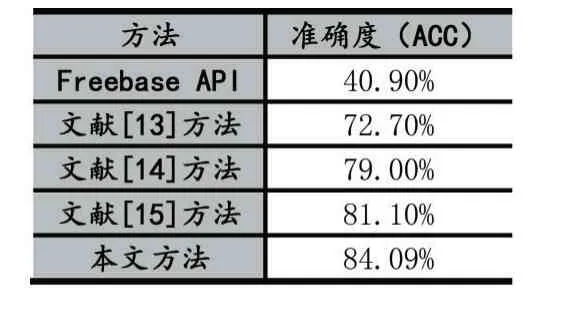
表9 实体链接方法对比
从表9 可知,本文提出的多维度匹配方法更能改善实体链接效果,并且方法中每个维度的匹配都为最后实体链接起到积极作用。此外,在不做预处理的情况下本文方法的ACC 下降到84.09%,说明预处理能提升最终实体链接效果,尤其是在噪声很大的数据集上。
4 结语
本文针对简单问句因实体名不规范、缺乏上下文等问题,提出了一种多维度匹配的方案。实验表明文本匹配维度的多级阈值方法能较大程度上缓解实体名不规范问题,统计匹配维度能大幅度提高实体对齐效果,实体属性匹配维度利用有限的问句上下文信息进一步修正了实体对齐的结果。最终多个维度组合能大幅度提高实体对齐准确度。
其次,为了避免流水线方式带来的错误累计,每个维度匹配仅进行重排序,而维度叠加可以有权重系数控制每个维度重要性,从而到达最佳的实体对齐结果。其中最为核心的关系预测模块,采用基于Trans⁃former 的预测模型,实验表明相比其他关系预测模型该模型拥有更好的语义抽取能力,同时采取top-3 rels 的手段也能有效缓解关系预测错误带来的影响。
最后,本文通过对实验结果的分析发现,一些不能对齐的实体大多是由于实体名拼写不规范以及实体不具有显著性(实体热度、关系都相同或相近)。因此,针对于以上问题将来的工作主要是解决实体名纠错,以及引入额外知识增加实体显著性。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
北京大学学报(自然科学版)(2022年1期)2022-02-21
计算机系统应用(2021年11期)2022-01-06
大东方(2019年1期)2019-09-10
当代陕西(2019年5期)2019-03-21
中国知识产权(2018年12期)2018-12-29
21世纪商业评论(2018年3期)2018-03-02
中国知识产权(2017年5期)2017-05-25
现代出版(2014年6期)2014-03-20
——基于与QuestionPoint的对比
新世纪图书馆(2014年11期)2014-02-23
