
封闭环境下暴力行为检测
2021-07-03 03:52王怡明
现代计算机 2021年12期
王怡明
(四川大学计算机学院,成都610065)
0 引言
公共场所中的暴力行为会对公民安全和社会稳定构成严重威胁。现代城市公共场所中往往都有大量的监控设备用于对突发事件的监测,产生的庞大数据给监察者带来了巨大的压力。因此,在监控数据中自动检测扰乱公共秩序的暴力事件并提示报警具有十分重要的意义。本文重点研究了监控视频中封闭环境下暴力行为检测。
传统方法的大致思路是根据专业知识从输入数据中提取复杂的手工特征,然后用机器学习中的分类算法,如支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest,RF)等,对样本进行分类。最初的做法[1]通过提取图像中的血和火等特征并辅以音频信号特征来检测暴力行为。考虑到真实生活中暴力行为的多样性以及音频信息的缺失,研究者们提出了更加合理的特征来判断暴力行为,例如剧烈运动所造成的模糊区域,连续两帧之差或计算光流得到的运动区域等。同时也提出用时空兴趣点(Space Time Interest Points,STIP)[10]、Motion Scale-Invariance Feature Trans⁃form(MoSIFT)[11]等来描述行为特征,进而对行为分类。在空间域提取兴趣点的方法有很多,例如比较常见的角点检测[2]。但空域中的兴趣点只包含图像中的空间信息,而没有图像的运动信息。Laptev 等人[3]将角点思想扩展到了时域,Dollár 等人[4]提出更完善的时空兴趣点检测方法,为更加准确识别行为提供了帮助。总的来说,传统方法使用“手工”特征来描述行为。尽管在一些情况下使用这些特征进行检测有较好的鲁棒性,准确率也能达到较高的水平,但是大多需要大量计算,其效率也不高。
与传统方法不同的是,深度学习方法可以直接作用于原始输入数据并自动提取需要的特征,大大减小了各类任务的难度,也提高了性能和计算效率。在用深度学习解决行为识别问题上有一个重要的方法——3D 卷积神经网络(Convolutional Neural Network,CNN)[5-7]。与经典的2D-CNN 不同的是,3D-CNN 的卷积核等算子都是三维的,它能在2D-CNN 的基础上进一步获取、整合数据的时间信息。其中一个经典的网络模型是C3D[7]。
然而,单纯的行为识别并不能检测出暴力行为发生的时空位置。受two-stage 目标识别算法[13]的启发,本文结合目标识别和行为识别算法,实现了暴力行为识别及定位。
1 算法实现
大部分的行为识别算法的输入为一个视频片段,然后通过相关算法计算得出结论(即输入样本的行为类型)。但是在实际生活中,视频片段中所包含的往往是多人、多行为。例如视频监控的同一画面中可能有人在打架,有人在旁边围观,有人在行走、逃跑等。所以在实际的应用中,直接对输入样本进行分类的算法可能并没有广泛的实用性及实际需求的性能。此外,大部分算法只是给输入的视频片段一个行为分类的标签,而没有行为发生的具体时间和空间位置。本文将two-stage 目标检测算法的思想扩展到暴力行为检测任务上。检测过程具体来说可以分为两个阶段,第一阶段是采用目标识别算法作为区域推荐网络,得出运动实例(即行为执行者)在每一帧上的空间位置(即边界框),将有限连续帧的所有边界框按一定的关系组合起来成为多个可能发生行为的管道(tubes)。接下来就是第二阶段,将从第一阶段得到的行为管道(action tubes)分别映射到对应原图(或者特征图)上进行裁剪。裁剪后的图像(或特征图)经过统一处理(resize 或RoI pool⁃ing 等操作)后根据不同行为管道依次送入3D-CNN 网络进行分类。
本文介绍的暴力行为检测方案的大致流程如图1所示。通过结合目标识别和行为识别领域的算法,在提高识别准确率的情况下还能得到行为发生的时空位置。接下来将详细介绍实验方案以及使用到的具体算法。

图1 算法流程
1.1 区域推荐模型
区域推荐模型的作用是获取图像中目标可能存在的位置。在本文中,我们希望用目标检测模型来获得每帧中人的位置,进而获得一段时间内运动实例的连续活动轨迹。
可用的目标检测算法有很多,本文采用了一个成熟且高效的目标检测模型——YOLOv3[9]。与上文中提到的two-stage 模型不同,YOLO 是one-stage,将目标检测作为回归问题来求解。其核心思想是将输入图像划分成网格,直接在输出层回归出以各格点为中心物体的边界框信息以及分类。由于计算流程更加简单,使得YOLO 有较高的准确度的情况下以实时速度进行检测。
本文任务是实现的是人类暴力行为检测,因此本文中使用的YOLO 稍微不同于原始模型。本文中YO⁃LO 只检测一个类别——人,并预测每帧中所有人所在的位置。此外,检测对象相对固定,因此仅在最后两不同的特征尺度下进行预测,使用的6 个先验框(anchor boxes)同样由K-means 类聚算法在数据集(描述于1.3小节)上得到,两个尺度分别分配3 个不同大小的先验框。损失函数方面,对类别和置信度使用二值交叉熵损失,对位置信息使用smooth L1 损失。
1.2 行为分类模型
在深度学习领域,行为分类模型同样有许多可以使用的方法,例如双流网络模型[12]和基于3D 卷积(3D convolution)[5-7]的神经网络模型等。双流网络模型综合RGB 图像的空间信息和光流图像的时间信息来判断样本的运动类型。由于双流网络需要引入额外的光流计算,因此在本文中采用了另一种经典的分类模型——3D-CNN。2D 卷积在图像识别方面有非常好的效果,但是由于结构上的限制,它不能有效地提取时间维度的信息。3D 卷积采用的是三维的卷积核,所以更加适合视频数据的处理,在拥有时间维度的视频上能更合理地提取相关特征。
由于暴力行为检测任务是一个二分类问题,因此我们选择设计一个小型的网络模型。本文的分类模型的网络结构如图2 所示。其中每个Conv_X 都包含一个卷积层、一个Batch Normalization(BN)层和一个Re⁃LU 非线性激活层。这里的模型结构大体与C3D[7]相同,并且输入都是包含16 帧的视频片段,分辨率为112×112。不同的是本文采用了全卷积的形式,用步长为2 的卷积层代替池化层。并且加入了BN 层来帮助加快收敛、消除了其他正则化形式的需要。AvgPool是平均池化层,Global 意思是全局平均池化。最后用一个全连接层(Full Connected layer,FC)得到预测结果,2 指的是两个类别——暴力事件和正常事件。使用交叉熵作为训练的损失函数。
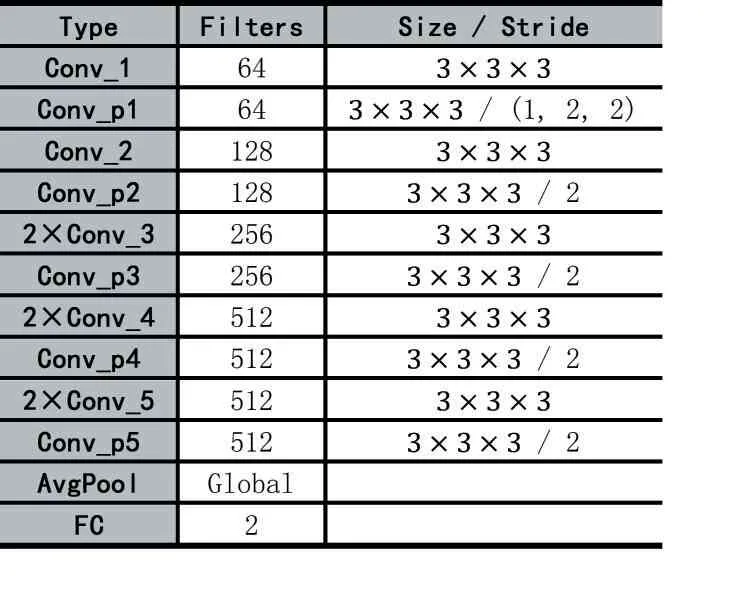
表1 分类模型网络结构
1.3 实现细节
首先将输入视频分成一系列的帧,逐帧送入区域推荐模型(YOLO)中。通过分析暴力行为的特征可发现,这是一种群体行为,至少是两个人的活动。所以在得到人的边界框后,将同一帧中边界框间的交并比(In⁃tersection over Union,IoU)和框中心点间的相对距离两个指标都在一定阈值内的框进行合并,得到一个个暴力行为可能发生的可疑区域。这种做法能帮助算法排除一些不可能发生暴力行为的区域,减少计算量。由于可疑区域包含的冗余信息更少,因此能帮助后续行为识别算法更准确地注意到暴力行为本身的特征而不是其他信息,使算法得到更精确的识别结果。
接下来就需要将不同帧中的区域按一定关系关联起来构成行为管道。由于行为分类模型的输入是包含16 帧的视频片段,因此我们首先按时间顺序依次获取包含16 个区域的行为小管(action tubelet)。构建方法如下。初始化:在第一帧中,每个可疑区域都为起始区域开始构建不同的行为小管。链接:随后帧中的可疑区域将按条件分配给现存的行为小管,条件为:①该区域未被分配,②该区域与现存小管的重叠度大于某一阈值,③该区域与某小管的重叠度大于与其他小管的重叠度。若可疑区域最终没被分配将作为新的行为小管的开始。终止:若现存某一行为小管的长度达到16,则将终止扩展并取出。若现存某一行为小管的长度小于16 且没有被分配新的区域,这个小管将被终止并抛弃。得到完整的行为小管后,需要把小管中所包含的区域映射回原始图像或者特征图上进行裁剪(在实验中我们选择映射到原始图像)组成待分类的视频样本。由于小管中区域大小可能不一致,因此我们将小管中所有区域的位置和大小统一为能包含所有区域的最小区域。 假设裁剪出的视频样本尺寸为3×16×W×H,其中3 为图像RGB 三个通道,W和H分别为区域的宽和高。视频样本将被统一调整大小至3×16×112×112,随后送入行为分类模型进行分类。
监控视频的帧率往往在20~30 fps 之间,每帧都进行检测是一项比较耗时和冗余的工作,并且经过实验发现这也不是必须的。为了减少计算量,增加行为识别所需要的时间信息,我们降低了检测的采样率,即让帧序列不是全部进入区域推荐网络,而是按一定的间隔(例如隔帧检测)。
2 实验及结果
暴力行为数据集是由我们邀请学生扮演,拍摄不同人群、不同角度下的暴力行为视频集。最后通过手工标注暴力行为在视频中的位置来得到完整的监督信息。我们的数据集有381 段视频,按照8:2 的比例划分成训练集和验证集。为了增加数据多样性,实验中使用了常用的数据增强技术。具体来说,在微调目标检测模型和训练分类模型时,对输入数据使用随机翻转、随机尺度变化和随机裁剪。注意,分类模型的输入是图片序列,因此尺度变化和裁剪的参数在同一个序列中应该是相同的。最后选择学习率为10-4、权重衰减率为5×10-4的Adam 优化器来训练优化模型。
实验中采用上述方法对数据集中的验证集进行检测,结果如表2 所示,其中Frame-AP/Video-AP 表示帧级/视频级平均查准率(Average Precision,AP),其IoU 阈值都是0.5。部分定性检测结果如图2 所示。此外,本文还从网络上下载了一些打架模拟视频进行检测,其检测结果说明了我们模型良好的泛化性。

图2 部分检测结果的展示
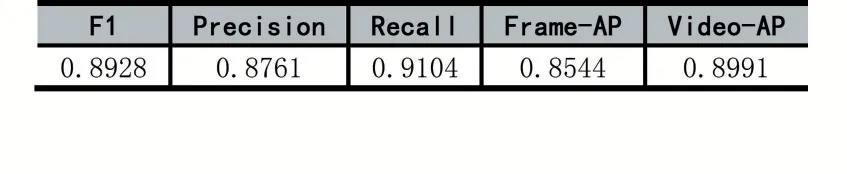
表2 实验评价指标
第一行为我们数据集中的验证样本。第二行为网络上获取的监控视频。图片左上角behavior 指的是此场景下行为的类型。红色框为行为发生的空间位置,confidence 为判断该位置为暴力事件的置信度。
3 结语
本文介绍了一个封闭环境下暴力行为检测的方案,这个方案不仅能检测到视频中是否发生了指定的暴力行为,而且能对行为者进行时空定位。并且我们在模型和其他方面提出了一些减少计算的方法,最终实现了性能和速度均衡的实时检测(即使在使用显卡的笔记本电脑上)。此外,我们的方案还能很方便地扩展到时空行为检测任务,只需要把3D-CNN 分类网络从二分类扩展到多分类即可。但是本文所提出的方法也存在不足,例如复杂环境(人群密集)下的检测、twostage 方案在时空行为检测上带来的弊端等。这些问题是接下来的工作。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
戏剧之家(2016年6期)2016-04-16
妇女生活(2015年6期)2015-07-13
少儿科学周刊·少年版(2015年3期)2015-07-07
