
基于声道低频能量比的自同步数字音频水印算法研究
2021-07-01 02:30滕焱
齐齐哈尔大学学报(自然科学版) 2021年5期
滕焱
基于声道低频能量比的自同步数字音频水印算法研究
滕焱
(阜阳幼儿师范高等专科学校,安徽 阜阳 236015)
目前数字音频水印算法,未曾在音频中嵌入同步信号,导致嵌入水印的音频存在不可感知性、抗攻击性和鲁棒性等性能差问题,为此提出基于声道低频能量比的自同步数字音频水印算法研究。采用降维和加密的方式,预处理数字水印;分段处理数字音频,并嵌入同步信号,采用声道低频能量比技术,将数字水印图像,嵌入数字音频;设计水印图像提取步骤,提取水印图像。实验结果表明,确定数字音频攻击方式,不可感知性、抗攻击性和鲁棒性等性能指标的计算公式,对比3组算法的不可感知性、抗攻击性和鲁棒性,此次研究的自同步数字音频水印算法,具有较优的不可感知性、抗攻击性和鲁棒性。
声道低频能量比;自同步数字;数字音频;水印算法
当前人类已经迈入数字化信息时代,通过数字媒体,传播、获取音频、视频等网络信息,极大丰富了人们的生活,提高了信息的传输效率。但是,随着数字化技术的发展,引发了数字化信息的安全问题,如侵犯版权、非法拷贝软件或文档、肆意篡改数字信息等,面对这些问题,有学者在信息加密技术、数字签名技术和数字水印技术的基础上,提出数字音频水印技术,保护数字信息的版权保护和安全,引起了国际学术届的广泛关注和深入研究[1-3]。
目前国内外对于数字音频水印研究,分为算法和系统框架两个方面,主要研究成果集中在算法方向,并根据音频载体的类型,将算法分为压缩和非压缩两种。根据算法的效率以及算法的特点,还可以将算法分为时域算法和变换域算法两类,可以将水印嵌入到适当的变换域系数中,保护音频和视频版权。压缩域数字音频水印算法的研究,可以分为基于MPEG的压缩域数字音频水印算法、比特流音频水印方法、组合压缩音频水印算法三类[4-6]。然而,上述研究的数字音频水印算法,却存在抗攻击性能低下的问题,为此引入声道低频能量比,提出基于声道低频能量比的自同步数字音频水印算法研究。
1 研究基于声道低频能量比的自同步数字音频水印算法
1.1 预处理数字水印

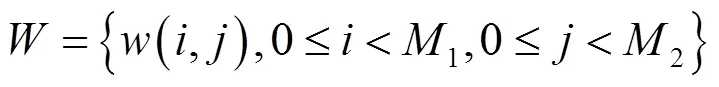
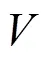
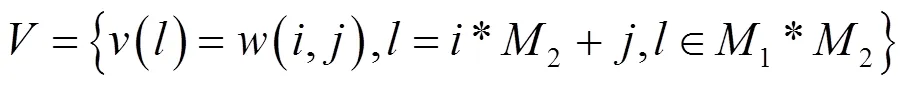
(2)水印图像加密。置乱处理式(2)得到的数字水印图像序列,需要采用Logistic混沌映射,产生二值混沌序列,其处理公式如下:

根据式(3)得到的加密数字音频水印图像,利用混沌序列对初始值的敏感性,对数字水印图像进行加密处理,得到的水印频谱具有较高的均衡性和安全性。
1.2 嵌入同步信号
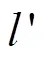

1.3 基于声道低频能量比嵌入数字音频水印
数字音频水印图像预处理后,在数字音频中,嵌入同步信号,此时,即可采用声道低频能量比技术,将数字水印图像,嵌入数字音频中,其嵌入过程如下:

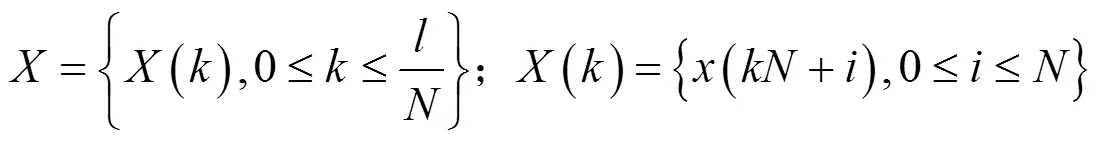

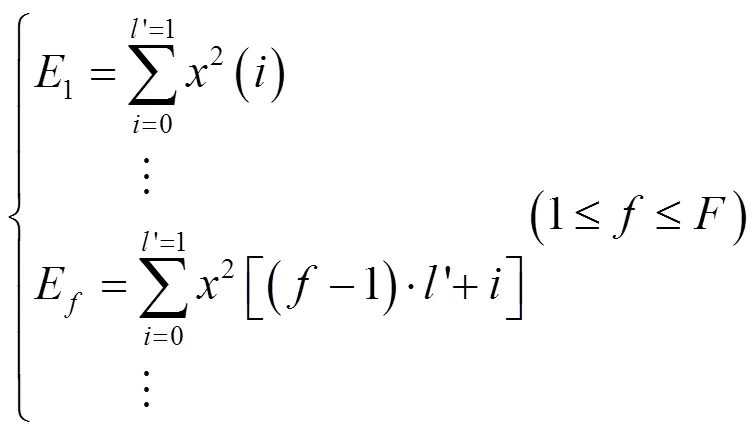
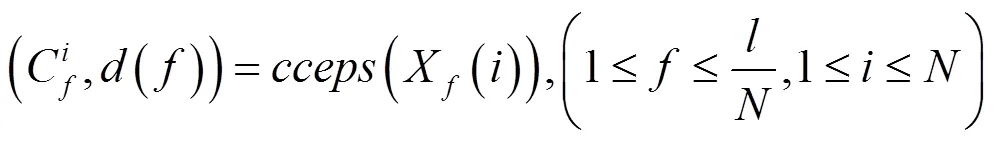

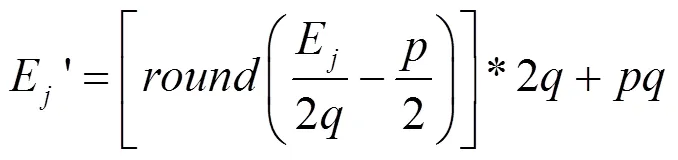
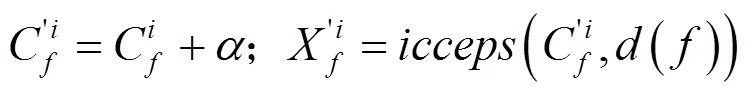
(7)重复步骤3~6,直至所有水印信息全部嵌入整段数字音频信号中,完成了水印的嵌入。
1.4 提取数字音频水印
依据上一节设计的数字水印图像嵌入过程,提取数字音频水印,其提取过程如图1所示。

图1 水印提取过程
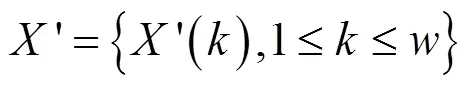
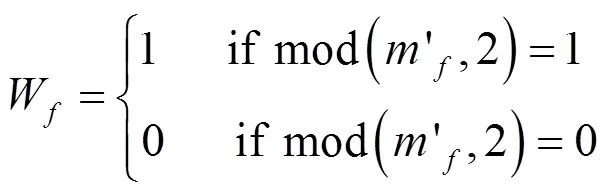
根据Logistic混沌映射,产生二值混沌序列,对逆置乱前的水印序列进行解密,得到一维序列;将一维序列升维,得到二维图像,其升维过程为水印图像预处理中,降维的逆过程。
2 仿真实验
采用对比仿真实验的方式,以声道低频的音乐作为此次实验的原始数字音频,在MATALB仿真软件上,验证此次研究的自同步数字音频水印算法。并将此次研究的自同步数字音频水印算法,记为A算法,选择两组传统的自同步数字音频水印算法,分别记为B算法和C算法。
2.1 实验准备


图2 算法运行环境拓扑结构图
2.2 实验结果
2.2.1 第1组实验


选择MATALAB软件,对本组实验选择的流行音乐,选择MP3压缩、随机剪切、低通滤波、下采样攻击、添加高斯白噪声、去噪攻击、重量化、上采样攻击等攻击方式,攻击此次实验选择的三种算法,采用式(12)计算3种算法的相关系数,验证3种算法的对攻击的抵抗能力,其实验结果如表1所示。从表1中可以看出,B算法和C算法在此次实验设置的攻击方式的攻击下,其相关系数与未受攻击之间分别存在0.18和0.16的差距,表明两组算法所提取的水印信息与原始水印的相似度较低,受到攻击时抗攻击性能较差;而A算法在此次实验设置的攻击方式的攻击下,其相关系数与未受攻击之间仅存在0.02的差距。由此可见,此次研究的自同步数字音频水印算法,所提取的水印信息与原始水印的相似度较高,受到攻击时具有较优的抗攻击性。
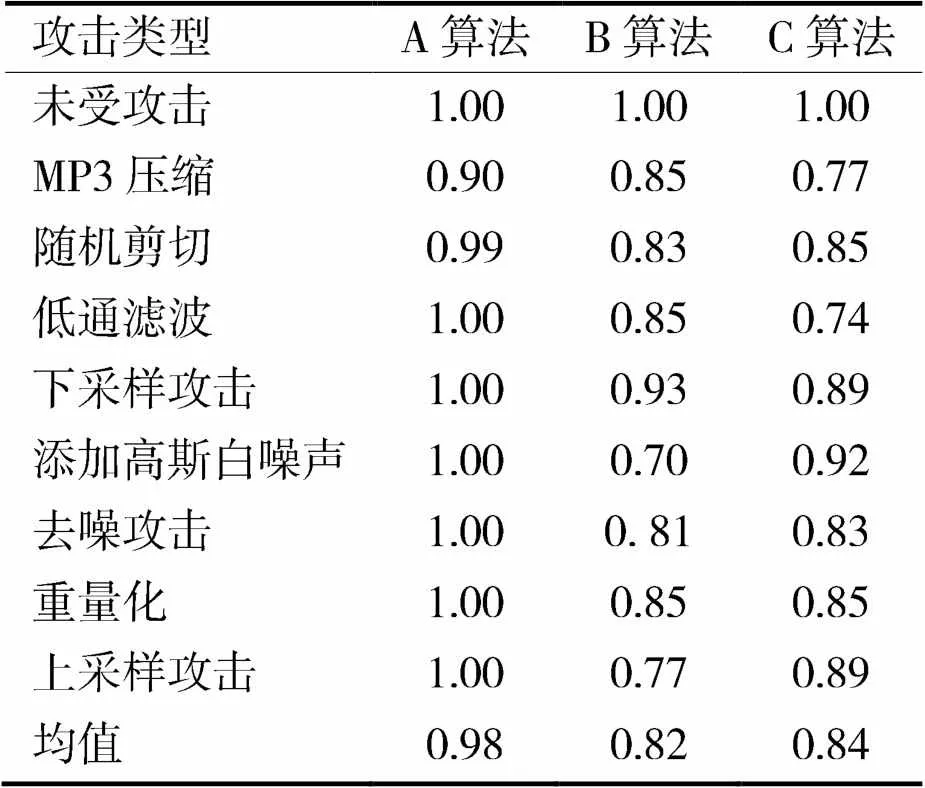
表1 对攻击的抵抗能力测试结果
2.2.2 第2组实验

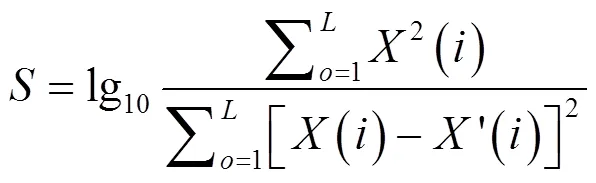
采用3组算法,分别在此次实验选择的古典、乡村、爵士、流行、蓝调五种类型的音频中,嵌入水印,并采用式(13)计算3组算法,分别5种类型的音的信噪比,验证3组算法的不可感知性,其实验结果,如表2所示。

表2 不可感知性对比结果 dB
从表2中可以看出,3组算法所得到的信噪比均大于音频信噪比的最低要求。但是B算法的信噪比明显低于A算法和C算法的音频信噪比,其不可感知性最差;而A算法的信噪比明显高于B算法和C算法的音频信噪比,可见,此次研究的自同步数字音频水印算法,其嵌入水印对数字音频质量损伤较小,与原始音频之间几乎不存在差距,具有较优的不可感知性。
2.2.3 第3组实验
基于第1组和第2组实验结果进行第3组实验,从此次实验选择的5种音频中选择其中的古典音频作为第3组实验的实验对象。通过误码率验证3组算法的鲁棒性。算法的误码率越接近于0,所提取的水印信息与原始水印的错误数越小,鲁棒性越好,则算法的误码率计算公式如下:
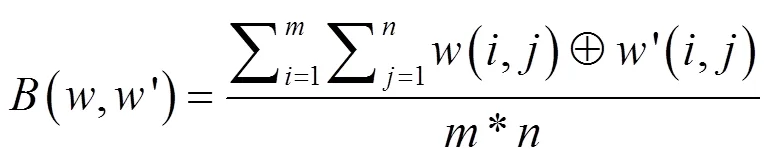
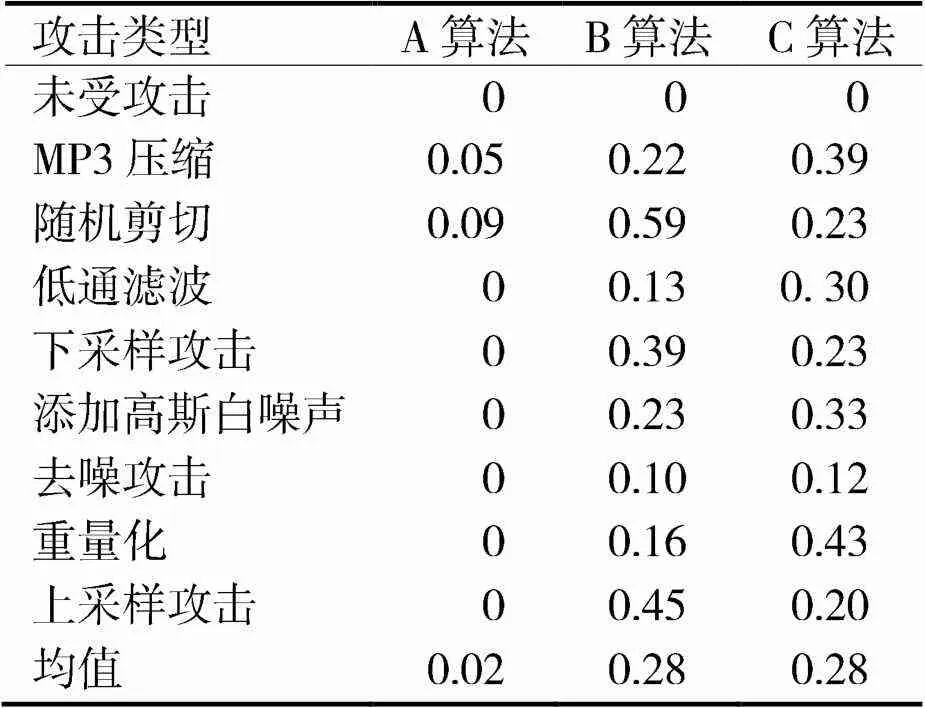
表3 算法鲁棒性测试结果
从表3中可以看出,B算法和C算法在此次实验设置的攻击方式的攻击下,算法的误码率较为接近,然而,B算法和C算法的误码率与未受攻击之间存在0.28的差距,表明两组算法所提取的水印信息与原始水印的错误数较大,算法的鲁棒性较差;而A算法在此次实验设置的攻击方式的攻击下,其误码率与未受攻击之间仅存在0.02的差距。可见,此次研究的自同步数字音频水印算法所提取的水印信息与原始水印的错误数较小,具有较优的鲁棒性。
3 结束语
综上所述,此次研究自同步数字音频水印算法,充分利用声道低频能量比,在数字音频中嵌入水印,提高水印的不可感知性、抗攻击性和鲁棒性。虽然此次研究的自同步数字音频水印算法已经具有较优的不可感知性、抗攻击性和鲁棒性,但是还需深入研究不可感知性、抗攻击性和鲁棒性的平衡效果。
[1] 邱皓扬,郭现峰. 基于Fibonacci-DWT-DCT-SVD的音频数字水印算法[J]. 西南民族大学学报:自然科学版,2020, 46(06): 631-637.
[2] 金胡考,陆燕菲. 基于复倒谱变换的音频数字水印算法[J]. 电子技术,2020, 49(05): 30-31.
[3] 刘慧超,王志君,梁利平. 基于纹理特性的能量差调制视频水印算法[J]. 湖南大学学报:自然科学版,2020, 47(10): 116-123.
[4] 邱一城,薛峰,唐晶磊. 时空特征分析结合随机密钥的压缩域数字视频水印嵌入和提取方法[J]. 计算机应用研究,2019, 36(09): 2813-2817.
[5] 丁洁. 基于机器学习的音频信号脆弱水印嵌入方法研究[J]. 现代科学仪器,2019(02): 93-96.
[6] 代航涛,田丽华,李晨. 基于色度DCT的抗重压缩的视频水印算法[J]. 计算机工程与设计,2019, 40(05): 1218-1224.
[7] 徐草草,杨启明,尹福成. 基于数字水印的图像加密技术[J]. 计算机与数字工程,2019, 47(09): 2273-2275, 2305.
[8] 陈亮,李德. 基于PN序列和完全互补码的鲁棒音频水印算法[J]. 延边大学学报:自然科学版,2019, 45(03): 228-233.
[9] 牛盼盼,杨思宇,王丽,等. 基于稳健特征点的平稳小波域数字水印算法[J]. 通信学报,2019, 40(11): 187-198.
[10] 郑梦怡,李晨,田丽华. 基于音频基频特征的鲁棒零水印算法[J]. 计算机应用研究,2019, 36(02): 538-542.
[11] 朱杰,廖群英. 关于方程()=(SL())的正整数解[J]. 四川师范大学学报:自然科学版,2020, 43(04): 451-457.
[12] 陈强,陈雨,杜婷婷. 基于纠错编码的回声隐藏音频水印算法[J]. 科学技术与工程,2019, 19(30): 227-231.
[13] 刘影,陈怡,高戈,等. 适用于声学传输的鲁棒交叉扩频水印算法[J]. 计算机工程与设计,2018, 39(02): 492-498, 536.
[14] 曹军梅. 一种基于LWT和混沌加密的音频水印算法[J]. 电子设计工程,2018, 26(06): 7-10, 15.
[15] 李晨,王可鑫,田丽华. 基于声道低频能量比的MP3压缩域音频水印算法[J]. 计算机应用,2018, 38(08): 2301-2305, 2352.
[16] 韩颖铮,邓国强. 基于置乱加密和DWT的音频双水印算法[J]. 电子设计工程,2018, 26(12): 153-156.
[17]杨志疆. 基于循环码的LWT-DCT半脆弱音频水印算法[J]. 铁道学报,2018, 40(08): 91-97.
[18]李景丽. 基于振幅差值比较的时域音频数字水印算法[J]. 黄河水利职业技术学院学报,2018, 30(04): 41-44.
[19]杨志疆,叶阿勇,徐镇辉. 基于LWT-SVD的鲁棒音频水印算法[J]. 光电子·激光,2018, 29(11): 1221-1227.
[20]吴嘉彦. 基于网络云平台的音频文件防篡改数字水印算法改进方案[J]. 广播与电视技术,2018, 45(12): 123-127.
Research on self-synchronization digital audio watermarking algorithm based on channel low frequency energy ratio
TENG Yan
(Fuyang Preschool Education College, Anhui Fuyang 236015, China)
At present, digital audio watermarking algorithm has not embedded synchronous signal in audio, which leads to the poor performance of imperceptibility, anti-attack and robustness. Therefore, a self-synchronous digital audio watermarking algorithm based on the low frequency energy ratio of sound channel is proposed. Using dimension reduction and encryption to preprocess the digital watermark; segmenting the digital audio and embedding the synchronous signal, using the low-frequency energy ratio technology of sound channel to embed the digital watermark image into the digital audio; designing the watermark image extraction steps to extract the watermark image. The experimental results show that determine the digital audio attack mode, the calculation formula of imperceptibility, anti attack and robustness, and compare the imperceptibility, anti attack and robustness of the three groups of algorithms. The self-synchronization digital audio watermarking algorithm in this study has better imperceptibility, anti attack and robustness.
channel low frequency energy ratio;self-synchronization digital;digital audio;watermarking algorithm
2021-04-15
2020年度安徽省质量工程省级教学研究项目“基于知识社会创新形态下运用微课提升高职音乐教学质量的路径探索”(2020jyxm1425);2020年度安徽省质量工程省级教学团队(音乐教育专业实践课教学团队)(2020jxtd192)
滕焱(1980-),女,安徽阜阳人,讲师,硕士,主要从事音乐学应用研究,tennn999@163.com。
TN912
A
1007-984X(2021)05-0006-05
猜你喜欢
家庭影院技术(2021年10期)2021-11-20
黑龙江工业学院学报(综合版)(2021年8期)2021-10-27
家庭影院技术(2021年1期)2021-03-19
家庭影院技术(2020年7期)2020-08-24
电子制作(2019年20期)2019-12-04
家庭影院技术(2018年10期)2018-11-02
电子制作(2017年10期)2017-04-18
现代商贸工业(2016年22期)2016-12-27
电脑知识与技术(2016年28期)2016-12-21
现代商贸工业(2016年35期)2016-04-09
