
基于深度学习的意图识别与语义槽填充联合建模研究
2021-06-29 10:33王明星
数字技术与应用 2021年5期
王明星
(北方工业大学,北京 100144)
0 引言
近年来,对话系统被应用于各方各面,比如Siri、Echo、天猫精灵等,通过对话交互帮助用户完成任务。自然语言理解(NLU)是对话系统的核心模块,其目的是提取出用户表达中的用户意图和与意图相关的重要语义信息,并将其表示成计算机能够理解的结构化形式。在特定领域类,自然语言理解可以拆分成两个子任务,即意图识别和语义槽填充。
意图识别是一个预测意图标签yi的分类问题,语义槽填充是一个序列标记任务,将输入单词序列x=(x1、x2、…、xT)映射到语义槽标签序列YS=(YS1,YS2,…,YST)。基于递归神经网络(RNN)的方法,特别是门控递归单元(GRU)和长短期记忆(LSTM)模型,在意图分类和插槽填充方面取得了最先进的性能。最近,研究者们提出了几种意图分类和语义槽填充的联合学习方法来利用和建模这两个任务之间的依赖关系,并提高了独立模型的性能[1]。先前的工作表明,注意力机制[2]有助于循环神经网络处理远程依赖关系。因此,基于注意力的联合学习方法被提出,并实现了联合进行意图识别和语义插槽填充得最好的性能[3]。
由于缺乏NLU 和其他自然语言处理(NLP)任务的人工标记数据,导致泛化能力较差。为了解决数据稀缺的问题,提出了各种技术来训练。通用语言表示模型,使用大量未注释的文本,如ELMo[4]和GPT[5]。预训练的模型可以在NLP任务上进行微调,并很多自然语言处理领域取得了显著的效果。最近,一种预训练模型BERT被提出,它在各种各样的NLP任务都取得了最好的效果,包括问题回答、自然语言推理等。然而,没有人在自然语言理解任务上使用BERT模型进行联合建模。本文的贡献包括以下两个方面:第一,使用BERT预训练模型,以解决自然语言处理任务泛化能力差的问题;第二,提出了一种基于BERT-crf的意图识别和语义槽填充联合模型,并通过实验证明了该模型在意图识别和语义槽填充上取得了显著的提高。
1 相关工作
深度学习模型在自然语言理解上有很多的探索,主要包括两种方法来解决自然语言理解问题,分别是独立建模方法和联合建模方法。
针对意图识别任务,主要有基于规则模板、统计机器学习、深度学习几种方法。Kim 等人首次使用CNN 来处理意图识别问题,并且获得了很好的效果。Al-Sabahi K等人通过引入自注意力机制来获得句子表示,使用多个句向量来表示不同的语义信息,通过在双向的LSTM上执行,最终得到的句子向量通过对双向LSTM的隐藏层状态加权求和获得,在意图识别任务上取得了不错的效果。Xia等人首次将胶囊网络应用在意图识别任务上,使用路由机制将贡献度不同的各种语义聚合起来,形成更有代表的语义表示向量,进而达到意图识别的目的。针对语义槽填充任务,主要有基于字典、规则、统计、深度学习的方法。Lane等人使用两个RNN模型来构建编码和解码器,实现输入和输出的对齐,并应用在语义槽填充任务上,取得了很好的效果。Yao 等人使用LSTM 来解决语义槽填充问题,并且在LSTM 模型中加入CRF机制,这种建模方式极大地提升了语义槽填充的效果。Zhu等人使用双向的LSTM 模型作为编码器,同时加上注意力机制,在语义槽填充任务上取得了极大的进步。
针对联合建模,Jeong等人采用三角链条件随机场模型捕获了意图识别和语义槽填充这两者的内在联系,虽然该模型在联合识别上作出了一定的贡献,但是却有着传统机器学习方法的不足,并且需要足够多的训练语料。Guo等人使用递归神经网络和Viterbi算法联合解决意图识别和语义槽填充任务,该方法将句子以语法树的形式表示出来,利用RNN学习数中每个节点的特征,极大地提高了联合识别的性能,然而在语义槽填充任务中会产生一定的信息损失。
2 方法提出
本章首先简要介绍了BERT 模型进行介绍,然后介绍了所提出的基于BERT-CRF 的联合模型。
BERT的模型架构是一种多层的双向transformer编码器,每个单词的输入表示有三部分构成,即词向量token embedding,句子向量(segment embedding)和位置向量(position embedding)。使用一个特殊的分类嵌入([CLS])作为第一个标记,并添加一个特殊的标记([SEP])作为结尾标记。对于给定输入序列x=(x1,…,xT),BERT的输出为H=(H1,…,hT)。BERT利用MLM进行预训练并且采用深层的双向Transformer组件来构建整个模型,因此最终生成能融合左右上下文信息的深层双向语言表征,并可用于各种任务,比如本文的研究内容,意图识别和语义槽填充。
本文提出的联合模型结构图,如图1。将待理解的句子向量化后输入到BERT模型中,BERT模型将句首[CLS]标记对应的隐藏状态输出出来,通过soft max函数,获得意图标签的概率分布,根据概率分布获得最终的意图;同时BERT 模型将其余的隐藏状态输入到CRF 层中,CRF 层负责寻找语义槽标签之间的关系,最后从CRF层中输出语义槽标签。

图1 BERT-CRF 联合模型Fig.1 Bert-crf joint model
BERT可以很容易地被扩展到一个意图识别和语义槽填充联合模型。根据第一个特殊标记([CLS])的隐藏状态h1,预测意图为:
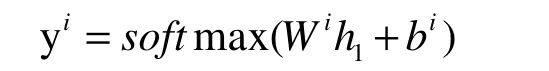
对于语义槽填充,其预测取决于对周围单词的预测,CRF能够很好的解决该问题,于是将h2,…,ht的最终隐藏状态输入到crf层,以便在槽填充标签上进行分类。为了使此过程与单词序列中标记相兼容,这里将每个标记化的输入字输入到一个单词标记器中,并使用与第一个标记对应的隐藏状态作为输入,其最大似然函数为
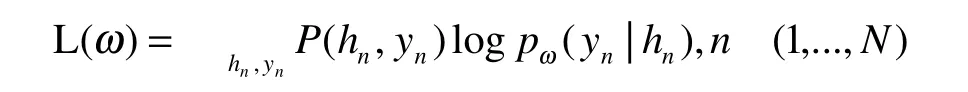
其中,hn对应输入xn之后得到的隐藏状态。
对于意图识别与语义槽填充联合模型的目标函数,可以设定为:

通过不断的进行训练使条件概率p(yi,ys|x)最大化,该模型是通过最小化交叉熵损失来实现对模型参数的调整。
3 实验与分析
本文在自然语言理解两个比较公认的数据集ATIS和Snips上评估了所提出的模型并加以分析。
ATIS 数据集有航空飞行方面相关的对话构成,该数据集中共包含4478条数据训练数据,500条验证数据,893条测试数据。Snips数据集是通过收集Snips虚拟个人语音助手中的数据得到的,是一个开源的语料库。该数据集中有诸多领域的查询话语,比如天气查询和酒店预订,该数据集中共包含13084条训练数据、700条验证数据、700条测试数据。
本文使用的BERT版本是BERT-Base,它有12层,768个隐藏状态,12个头部,参数规模110M。对于微调,所有超参数都在验证集上进行调优。最大长度为50。批量大小为128。adam用于优化,初始学习率为5e-5。dropout率为0.1。训练轮数分别为[1,5,10,20,30,40]。
表1显示了在Snips和ATIS数据集上,本文的模型和其他联合模型的效果比较,其中用准确率作为意图识别的评价标准,使用F1分数作为语义槽填充的准确率。

表1 在ATIS 和Snips 数据集上,不同模型效果对比Tab.1 On ATIS and snips datasets,the effects of different models are compared
在表1中,与本文模型进行对比的模型都是现在表现最好的模型,其中包括基于BiLSTM 的联合模型、基于注意力机制的循环神经网络联合模型以及基于门控机制的联合模型。
在ATIS 数据集上,本文提出的BERT+CRF 联合模型在意图识别任务上的意图识别准确率为97.8%,语义槽填充F1分数为96.0%;在Snips数据集上的意图识别准确率为98.4%,语义槽填充F1分数为96.7%。从中可以看出,本文提出的联合模型不管是在意图识别还是语义槽填充上效果都要比其他模型更好。
如图表2显示的是在不同训练轮数下,本文提出的联合模型在意图识别的准确率和语义槽填充的F 1 分数对比,可以发现在意图识别任务上,随着训练轮数的增加,会产生过拟合现象,在到第20轮的时候效果达到最佳。然而在语义槽填充任务上,模型的效果随着训练轮数的提高而不断提高,说明语义槽填充任务相对意图识别来说更加复杂,需要更多的数据量。
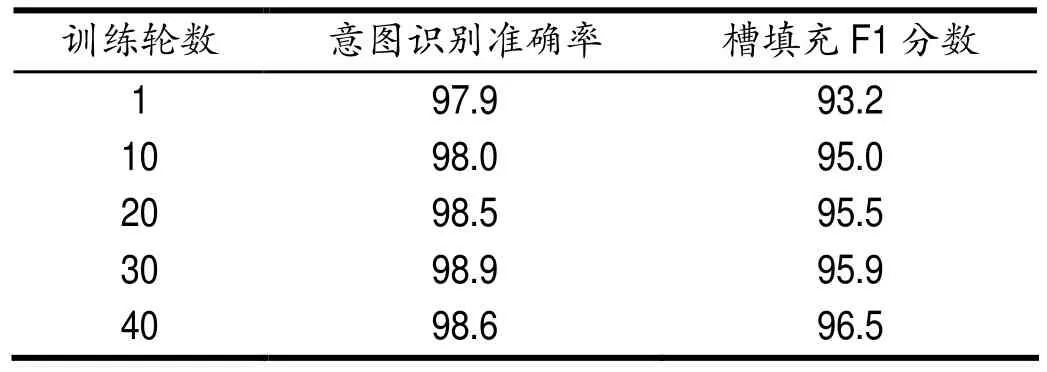
表2 不同训练轮数下的效果对比Tab.2 Effect comparison of different training rounds
4 结语
本文提出一种基于BERT-CRF的意图识别和语义槽填充联合模型,不仅解决了自然语言理解任务的泛化能力问题,而且实验结果表明,本文提出的联合模型在意图识别和语义槽填充任务上都有出色的表现,证明了利用这两个任务之间关系的有效性。与之前表现最好的模型相比,本文提出的模型在ATIS和Snips数据集上对意图识别和语义槽填充任务都有显著的提高。未来的工作会集中在探索将外部知识与BERT模型相结合的有效性以及在其他更大规模和更复杂的数据集上进行评估和分析。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
开放教育研究(2020年2期)2020-03-31
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
延河(下半月)(2014年3期)2014-02-28
