
基于公交IC卡刷卡数据的站点客流推算
2021-06-28 06:10孙凯郑长江
贵州大学学报(自然科学版) 2021年2期
关键词:土地利用
孙凯 郑长江
摘 要:公交客流数据是公交组织调度、线网优化和场站规划的基础性数据,随着计算机信息技术的发展,通过对公交刷卡数据进行分析处理即可得到全面准确的公交客流信息。以桂林市公交系统数据为例,首先,对公交IC卡刷卡数据和定位数据结构进行分析并对刷卡数据进行预处理,筛选出客流推算所需数据并剔除异常数据;其次,融合刷卡数据与定位数据匹配乘客上车站点;再次,根据站点吸引强度和乘客出行站数规律计算各站点下车概率,推算站点下车人数和线路OD(origin-destination)矩阵,其中吸引强度结合了站点上车人数和站点周边土地利用规划;最后,对计算结果与实际调查值的各项误差指标进行分析,表明研究结果的合理与准确性。
关键词:公交客流预测;OD推算;公交IC卡;土地利用
中图分类号:U491.1;C811 文献标志码:A
公交客流信息是公交运营调度、组织优化的基本依据,随着城市规模逐渐扩大,公交站点与线路的数量都在不断增加与变化,传统的人工调查方法获取公交客流数据变得愈发困难。随着公交移动刷卡支付使用普及和互联网技术的发展,能够获取乘客每一次的刷卡信息以及車辆实时的定位信息,而这些数据无法直观反映公交线路站点客流情况,需通过计算机信息技术手段对数据进行挖掘,便能得到全面准确直观可靠的公交客流信息。《城市公共交通“十三五”发展纲要》提出:将信息技术与公交系统相结合,建设智能化的交通系统,广泛应用公交大数据,提高公交服务信息化水平。因此,针对公交刷卡数据进行深度挖掘,获取居民出行需求,优化城市公交,提供决策信息,具有重要的研究价值。
公交OD推算是获取公交客流信息的基础性数据,主要侧重于通过计算机的数据挖掘技术对海量公交刷卡数据以及车辆GPS信息进行分析处理,获得各站点的上下车人数与线路OD。目前国内外已有学者对基于公交刷卡数据的公交站点客流推算方法进行研究。戴霄[1]结合公交的调度信息,采用聚类分析对上车站点进行判断,提出基于单个乘客刷卡数据与基于站点吸引两种判断上车站点方法。王周全[2]通过乘客刷卡时间与公交车辆到达和离开站点时间相匹配,识别公交乘客刷卡的上车站点位置,以乘客出行距离和公交站点的吸引特征作为影响乘客下车概率的主要因素,建立乘客下车概率模型。涂一霜[3]基于公交到站数据与刷卡数据融合计算刷卡时间与公交到站时间差来匹配上车站点,基于出行链、规律出行和概率计算3种方法计算下车站点。梅珊[4]基于出行链的估计方法推算乘客的下车站点,并结合公交站点停靠时间得到下车时间。杨万波等[5]结合居民公交出行规律推算交通小区的公交OD矩阵。LI等[6]基于每个站点上下车人数估算每一站下车的概率及公交OD矩阵。窦慧丽等[7]基于站点上下车人数和线路客流量推算各站点乘客下车概率,提出单条公交线路客流OD矩阵推算方法。刘颖杰等[8]结合站点吸引率,提出了单条公交线路站点间OD反推的结构化算法。NAVICK等[9]运用小样本OD推算完整OD矩阵。崔紫薇等[10]基于历史出行记录扩充方法推算下车站点。NASSIR等[11]通过数据检测乘客出行链中的实际活动轨迹来确定下车站点。
这些方法各有适用范围和局限性,确定线路客流的影响因素较为单一,受单个因素影响较大,存在高数据敏感性的问题,不能全面反映线路客流情况。基于出行链的方法理论上能够准确推算公交客流数据,需要结合全市所有公交数据进行分析,但实际情况是公交换乘人数占公交出行总人数的比例很小,而时间与经济成本呈指数级增加,从经济效益来说并不适用。因此,本文从单条公交线路出发,考虑窦慧丽[7]和刘颖杰[8]等展望中提及的引入土地利用性质,综合站点上车人数来确定公交站点吸引强度,并结合乘客出行距离建立下车概率矩阵,推算线路OD矩阵,进行公交客流数据统计分析。
1 公交系统基础数据与预处理
1.1 公交系统基础数据
1.1.1 公交IC卡刷卡数据
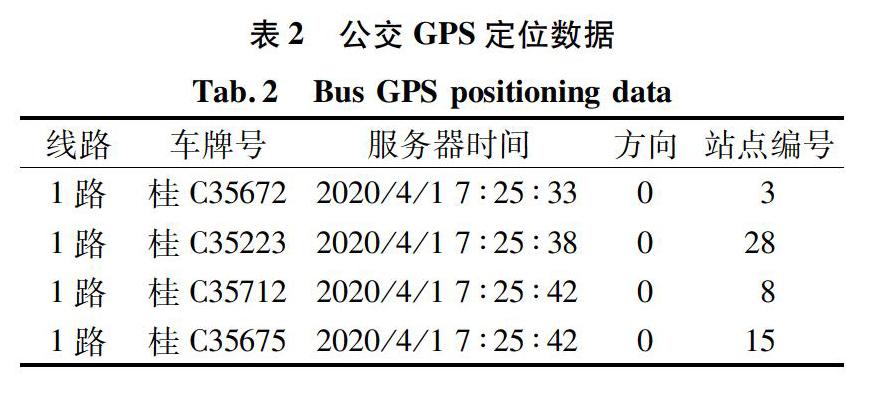
公交刷卡数据记录了每位乘客每次刷卡时的详细数据。不同城市的刷卡系统对应的刷卡记录数据结构可能不完全相同,对于上下车都需要刷卡的公交系统,刷卡数据结构中含有上车站点和下车站点字段,而目前桂林市公交采用单次刷卡形式,刷卡数据结构中不含有上下车站点字段。公交刷卡记录里包含线路、车牌号、卡号、交易时间等信息。部分数据如表1所示。
1.1.2 公交GPS定位数据
公交GPS定位系统记录了车辆的实时运行信息。对于车辆位置,主要利用经纬度坐标进行定位与站点相匹配,利用其他参考坐标点进行车辆位置信息的核查,得到公交实时位置附近所在的站点。公交GPS定位数据主要包括线路名、车牌号、服务器时间、方向、当前站点编号、当前站点名称等信息。部分数据如表2所示。
1.2 刷卡数据预处理
公交客流研究中需要用到的刷卡数据未必完全准确,存在部分问题数据,这些问题会在数据融合时使程序出错。因此需要对数据进行预处理,剔除错误数据,控制数据质量,保证研究数据的准确性[12]。
1)选择分析时段
公交都按照公交调度计划运行,乘客出行特点具有一定的周期性和时段性。一般来说,根据乘客出行特点,大部分乘客在一周工作日期间的出行特征有较大的相似性,可以日、周、月作为公交客流出行特征的基本分析单位。
2)选取数据字段
公交刷卡系统一天内记录了上万次乘客刷卡记录,而在进行公交客流出行特征分析的过程中,有大量字段对于分析没有实质的意义,因此在数据预处理阶段可以剔除这些对于分析没有实质意义的数据字段,这样可以减少计算机运行负荷,加快计算机处理速度,提高数据处理效率。主要选取的刷卡数据字段有线路、车牌号、交易时间。
3)剔除错误数据
在刷卡系统的工作过程中,可能会出现公交车辆收费机故障或系统网络传输中断等问题,因此原始刷卡数据中往往存在错误数据。刷卡数据中,缺失车牌号、线路、交易时间数据等部分字段是典型的错误数据。因此,剔除这些错误数据是保证公交客流出行特征分析质量的有效手段。
下面分析刷卡错误数据的特征及剔除方法。
公交刷卡数据主要存在以下几个方面问题:部分字段缺失、数据重复与数据串流。
1)部分字段缺失。例如部分数据为空(即NULL)。此类数据占总数据的比例约为1%。对于缺失字段数据,其占总数据比例最小,可直接删除缺失字段数据。
2)数据重复。例如刷卡数据中,存在部分完全重复的数据,为系统多次记录,此类数据占总数据的比例约为3%。对于重复数据,直接删除并保留每条唯一的刷卡记录即可。
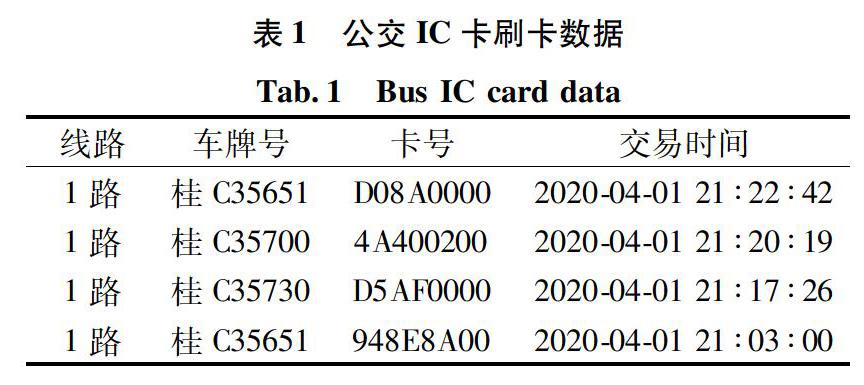
3)数据串流。例如刷卡数据中的某些车牌号出现次数较少,且在发车计划中并不存在。此类数据不为该线路数据,占总数据的比例小于0.1%。如图1所示,一天中刷卡数据数据串流车辆数约为3辆,且串流车辆刷卡数据不超过20次,非串流数据刷卡数据皆大于100次,并且发车计划中的车辆在刷卡数据中都能找到对应,因此可以通过以下几种方法删除:①删除刷卡数据中按车牌分组后刷卡数据不超过20组的数据;②通过与发车计划车辆数据关联,删除刷卡数据中车辆不在发车计划中的数据。在研究中发现,两种方法所得到的结果相同,而第一种方法算法较为简单通俗,能够减少处理时间,提高运行效率,故本研究采取第一种方法。
2 线路客流数据统计分析
2.1 站点上车人数匹配
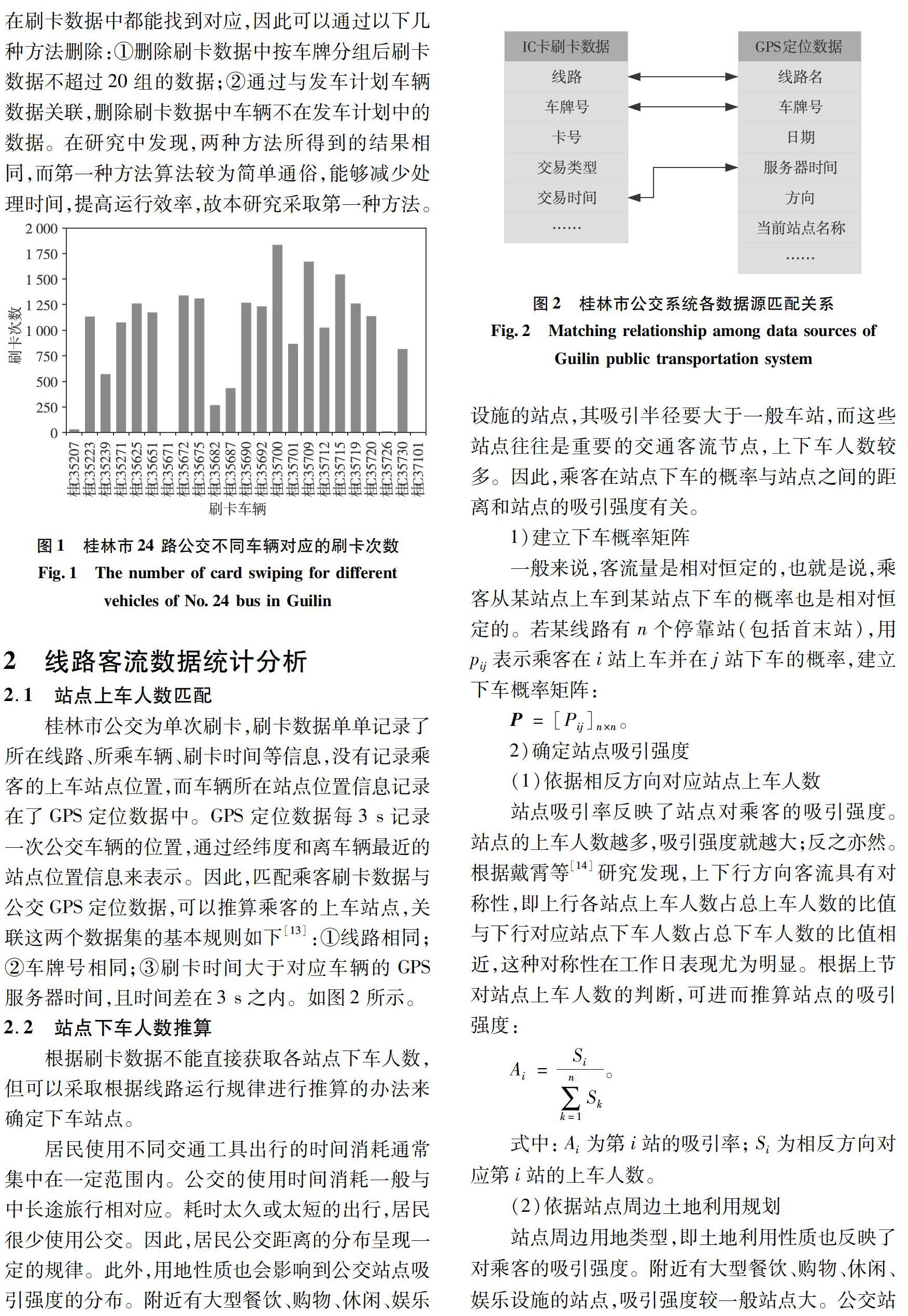
桂林市公交为单次刷卡,刷卡数据单单记录了所在线路、所乘车辆、刷卡时间等信息,没有记录乘客的上车站点位置,而车辆所在站点位置信息记录在了GPS定位数据中。GPS定位数据每3 s记录一次公交车辆的位置,通过经纬度和离车辆最近的站点位置信息来表示。因此,匹配乘客刷卡数据与公交GPS定位数据,可以推算乘客的上车站点,关联这两个数据集的基本规则如下[13]:①线路相同;②车牌号相同;③刷卡时间大于对应车辆的GPS服务器时间,且时间差在3 s之内。如图2所示。
2.2 站点下车人数推算
根据刷卡数据不能直接获取各站点下车人数,但可以采取根据线路运行规律进行推算的办法来确定下车站点。
居民使用不同交通工具出行的时间消耗通常集中在一定范围内。公交的使用时间消耗一般与中长途旅行相对应。耗时太久或太短的出行,居民很少使用公交。因此,居民公交距离的分布呈现一定的规律。此外,用地性质也会影响到公交站点吸引强度的分布。附近有大型餐饮、购物、休闲、娱乐设施的站点,其吸引半径要大于一般车站,而这些站点往往是重要的交通客流节点,上下车人数较多。因此,乘客在站点下车的概率与站点之间的距离和站点的吸引强度有关。
1)建立下车概率矩阵
一般来说,客流量是相对恒定的,也就是说,乘客从某站点上车到某站点下车的概率也是相对恒定的。若某线路有n个停靠站(包括首末站),用pij表示乘客在i站上车并在j站下车的概率,建立下车概率矩阵:
P=[Pij]n×n。
2)确定站点吸引强度
(1)依据相反方向对应站点上车人数
站点吸引率反映了站点对乘客的吸引强度。站点的上车人数越多,吸引强度就越大;反之亦然。根据戴霄等[14]研究发现,上下行方向客流具有对称性,即上行各站点上车人数占总上车人数的比值与下行对应站点下車人数占总下车人数的比值相近,这种对称性在工作日表现尤为明显。根据上节对站点上车人数的判断,可进而推算站点的吸引强度:
Ai=Si∑nk=1Sk。
式中:Ai为第i站的吸引率;Si为相反方向对应第i站的上车人数。
(2)依据站点周边土地利用规划
站点周边用地类型,即土地利用性质也反映了对乘客的吸引强度。附近有大型餐饮、购物、休闲、娱乐设施的站点,吸引强度较一般站点大。公交站点间距离一般在500~600 m之间,取上限值的一半,即300 m作为计算依据。根据各站点周边300 m的土地利用规划,基于不同性质用地的出行吸引率预测各站点的吸引率:
G*i=∑Likαik。
式中:G*i为第i站的吸引率; Lik为第i站周边300 m第k类用地的建筑面积占总面积比例; αik为第i站周边300 m第k类用地单位面积的出行吸引率。
再对线路各站点吸引率进行归一化处理:
Gi=G*i∑nk=1G*i。
式中:Gi为归一化处理后的第i站的吸引率。
结合相反方向对应站点上车人数确定的站点吸引率Ai,与站点周边不同土地性质吸引率Gi,计算出站点总吸引强度Li:
Li=β1Ai+β2Gi∑nk=1β1Ak+β2Gk。
式中:β1为根据站点上车人数确定的吸引强度所占权重;β2为根据站点周边300 m土地利用规划确定的吸引强度所占权重。其中,β1+β2=1,取β1=β2=0.5。
3)确定乘车站距分布
根据窦慧丽等[7]研究发现,乘客出行乘坐的公交站点数量主要集中在一定范围内。当乘坐的站点数量达到一定时,该站点的下车人数最多,即下车概率最大;当乘坐站点数量过多或过少时,下车概率相对较小,其通常遵循一定的分布规律。统计检验表明,在给定的行驶方向下,乘客乘坐的公交站点数量服从泊松分布:
P(k)=λke-λk!。
式中:P(k)为乘客乘坐k站的概率;λ为平均乘车站数。
乘客乘坐站数至少为1站,至多为首站至末站,即为n,需要对上述概率进行归一化处理:
P*(k)=λke-λk!/∑nk=1λke-λk!。
式中:P*(k)为归一化处理后的乘客乘坐k站的概率。
假设从i站上车并在j站下车为乘坐k站,即j-i=k,概率分布可表示为
Wij =λj-ie-λ(j-i)!/∑j-1i = 1λj-ie-λ(j-i)!。
式中:Wij为从i站上车并在j站下车的概率;λ为平均乘车站数,当i站以后的站点数目小于平均乘车站点数时,取λ=n-i。
4)确定下车概率
下车概率Pij与站点吸引强度和乘车站距分布有关,即Pij∝Li,Pij∝Wij,由此构成公交某一行驶方向,乘客从i站上车并在j站下车的概率为:
Pij=Li×Wij∑nk=i+1Lk×Wiki 0i≥j。 5)推算线路OD及下车人数 公交线路OD反映了某条线路站点至站点的OD量,对单条公交线路的站点优化、运营评价和运力配置有着关键作用[15]。 以特定的某一公交线路的数据分析为例,用Oi表示乘客在站点i的上车人数,用Dj表示乘客在站点j的下车人数。线路OD可表示为从i站上车人数与从i站上车并在j下车概率之积,具体公式如下: Nij=Oi×Pij。 式中:Nij为从i站上车并在j站下车的人数;Oi为第i站的上车人数。 上式计算得线路各站点OD量,累加后即能推导出各站点下车人数Dj,则: 起始站点没有下车乘客,因此,D1=0; 第2个站点下车人数来自起始站点上车人数,因此,D2=O1×P12; 第3个站点下车人数来自起始站点上车人数和第2个站点上车人数,D3=O1×P13+O2×P23; 以此类推,第j个站点下车人数来自于前j-1个站点上车人数,由数学归纳法可得任意一个站点下车人数为: Dj=∑j-1i=1(Oi×Pij)=∑j-1i=1Nij。 3 实例分析 以桂林市24路公交为例,该公交线路共有17个站点, 2020年4月1日共有1 022条公交刷卡数据,约20万条公交GPS定位数据,两者匹配得上下行方向各站点的上车人数如表3所示。 上下行平均站点客流为30左右,上行方向客流量较大的站点有航天工业学院南、航天工业学院北、电子科大东区、金鸡路口;下行方向客流量较大的站点有十字街解放东路、解放桥、七星公园、东环车场、金鸡路口。这些站点可为区间车以及大站快车等调度提供参考。 24路公交周边土地利用规划图如图3所示,不同用地性质交通吸发率如表4所示。 上行方向各站点吸引强度根据下行方向的站点上车人数以及站点周边土地利用规划来确定,上行方向各站点总吸引强度如表5所示。 根据2020年4月1日跟车调查结果,共获得485条上行方向数据,初步估计乘车站数分布概率服从泊松分布,对其进行拟合优度卡方检验,得到观测值与期望值如图4所示。 乘客的乘车站数集中在一定的区域内,乘坐站点数较少或较多的乘客所占比例低。通过分布概率计算,得乘客乘车站数的泊松均值为7.438,取泊松分布参数λ=7,计算得到归一化处理后的泊松分布矩阵。拟合优度检验计算得P值小于0.01,意味着接受原假设(原假设:数据泊松分布)。 根据站点吸引强度以及乘车站距,得到下车概率矩阵,即可得到线路OD矩阵及各站点下车人数,如表6所示。 由表6可得,前幾站的下车人数较少,后几站的上车人数较少,这使得前后几站的通过量较低,这主要是因为其上下行方向乘客的平均乘车站距为7站左右。解放桥、十字街解放东路等站点下车人数较多,因为其为较大规模的休闲活动区,可购物、吃饭、观景,附近住宅区较多,通勤需求较大,公交线路密集,公交需求大。对于站点上下车较多的站点,可增加区间车,保持供给平衡。 为评价公交线路OD算法的合理及有效性,将公交线路OD调查值与计算值相对比,采用的评价指标有最大可能相对误差、相对误差、相关系数和误差指数[15]。通过多种误差指标对比判断线路OD矩阵的准确性。线路OD调查值与计算值误差结果如表7所示。 从计算结果可看出,最大可能相对误差、相对误差均控制在10%以下,相较于未考虑土地利用性质的窦慧丽[7]和刘颖杰[8]等OD推算所得的相对误差,分别为7.61%和9.3%,有了一定程度的降低。相关系数为0.87,误差指数为0.85,该值表示计算值与实测值间的拟合度,位于0到1之间,越大表示拟合效果越好。总体而言,计算所得线路OD计算值较好地与线路OD实际值相拟合,所提出的方法具有适用性。 4 结语 本文分析了桂林市公交刷卡数据结构及异常数据特征,针对异常数据进行数据清理,为特征研究提供了良好的环境。在现有数据条件下,提出乘客上下车站点判断方法。匹配刷卡数据与定位数据得到各站点上车人数,通过站点上车人数和土地利用规划判断站点吸引强度,并结合乘客乘车分布规律推算各站点下车人数和公交线路OD矩阵。将计算所得线路OD矩阵与调查实际值对比,验证了假设和算法的合理性。 公交刷卡数据研究是一个非常复杂的问题,本文只是针对单条公交线路站点客流推算进行了研究,未来可进行多条线路融合,由线路OD分配至小区OD,为公交决策者提供更深层次的数据。参考文献: [1] 戴霄. 基于公交IC信息的公交数据分析方法研究[D].南京:东南大学,2006. [2] 王周全. 基于IC卡数据与GPS数据的公交客流时空分布研究[D].成都:西南交通大学,2016. [3] 涂一霜.基于IC和GPS数据的公交客流分析及预测算法研究[D].武汉:武汉理工大学,2017. [4] 梅珊.基于数据挖掘的城市公共交通客流分析及应用研究[D].武汉:武汉邮电科学研究院,2017. [5] 杨万波,王昊,叶晓飞,等.基于GPS和IC卡数据的公交出行OD推算方法[J].重庆交通大学学报(自然科学版),2015,34(3):117-121. [6] LI Y W, MICHAEL J C. A generalized and efficient algorithm for estimating transit route ODs from passenger counts[J]. Transportation Research Part B-Methodological, 2007,41(1):114-125. [7] 窦慧丽,刘好德,杨晓光.基于站点上下客人数的公交客流OD反推方法研究[J].交通与计算机,2007,25(2):79-82. [8] 刘颖杰,靳文舟,康凯.基于IC信息和概率理论的公交OD反推方法[J].公路与汽运,2010,28(3):31-33. [9] NAVICK D S, FURTH P G. Distance-based model for estimating a bus route origin-destination matrix[J]. Transportation Research Record, 1994(1433): 16-23. [10]崔紫薇,王成,陈德蕾,等.基于历史出行记录扩充的公交乘客下车站点推算方法[J].南京大学学报(自然科学),2020,56(2):227-235. [11]NASSIR N, HICKMAN M, MA Z L. Activity detection and transfer identification for public transit fare card data[J]. Transportation,2015,42(4):683-705. [12]刘德平. 北京公交车辆IC卡数据分析及应用[D].北京:北京理工大学,2016. [13]黄捷. 基于公交IC卡数据和GPS数据推断出行活动类型研究[D]. 成都:西南交通大学,2016. [14]戴霄,陈学武.单条公交线路的IC卡数據分析处理方法[J].城市交通,2005(4):77-80. [15]章玉. 基于数据挖掘的动态公交客流OD获取方法研究[D].北京:北京交通大学,2010. (责任编辑:曾 晶) Abstract: Bus passenger flow data is the basic data of bus organization and scheduling, line network optimization and station planning. With the development of information technology, comprehensive and accurate bus passenger flow data can be obtained by analyzing and processing bus card data. Taking the bus system data of Guilin as an example, the card data and bus positioning data structure is analyzed firstly. The IC card data is preprocessed to screen out the data needed for passenger flow calculation and the abnormal data is eliminated.Secondly, the card data and positioning data are combined to match the passenger boarding station.Then, the probability of alighting at each station is calculated according to the law of station attraction intensity and passenger travel station number, and the number of people alighting at each station and the line OD matrix are calculated. The attraction intensity is combined with the number of people boarding at the station and the use planning of land around the station. Finally, the error indexes of the calculated results and the actual survey values are analyzed, which shows that the research results are reasonable and accurate. Key words: bus passenger flow forecast; OD calculation; bus IC card; land use
猜你喜欢
大气科学学报(2022年3期)2022-07-22
环球人文地理·评论版(2016年5期)2017-01-03
南水北调与水利科技(2016年5期)2016-12-27
山东农业科学(2016年11期)2016-12-17
现代经济信息(2016年27期)2016-12-16
商(2016年33期)2016-11-24
中国集体经济(2016年27期)2016-11-19
商(2016年30期)2016-11-09
中国市场(2016年34期)2016-10-15
