
先心病心音CNN分类算法的硬件加速
2021-06-28 12:41奎皓然杨宏波王威廉
计算机工程与设计 2021年6期
粟 炜,宗 容,张 强,奎皓然,杨宏波,王威廉+
(1.云南大学 信息学院,云南 昆明 650500;2.云南省阜外心血管病医院 心血管内科,云南 昆明 650102)
0 引 言
如今,先心病已经成为严重危害青少年健康成长的疾病,早预防、早发现、早诊断、早治疗是减少先心病危害的4种重要途径[1],早发现、早诊断是4个途径中难以实现的。对先心病的早发现、早诊段,仅能通过医务人员的下乡筛查、定点检查等方式,带来难度大、成本高等缺陷。随着信息时代的发展,可以利用深度学习对心音进行分类,然后将网络模型移植进低成本、高实时性的嵌入式端,进行离线的辅助诊断,以此来缓解先心病筛查的压力。
卷积神经网络(convolutional neural network,CNN)是目前在图像处理领域应用成熟,同时也被广泛应用在语音语义识别、生物医学信号分类等方面的深度学习模型中[2-4]。CNN也被应用在心音分类[5],有些研究者将心音数据变换得到声谱图、频谱图的形式,再利用卷积结构提取图像特征,这类方法的平均准确率也达到0.8[6-8]。但此类研究也有局限:隐层中参数过多造成计算量大、实时性不高;该研究的架构需依赖高功耗、高成本的硬件环境,难以移植进低功耗、低成本嵌入式平台。因此,针对这些问题,本文对先心病心音CNN分类算法和其并行执行能力进行了研究:首先,对心音信号进行预处理;其次,设计CNN的网络结构;最后,通过对卷积层中的循环进行流水线的设计,实现了先心病心音分类算法的硬件加速。本文在硬件加速的过程中,保证算法达到平均准确率的前提下,损失部分计算精度以换取算法在硬件中执行效率的提升。本文在多种嵌入式平台上选用了ZYNQ系列片上系统,本文采用的了Zynq-7020芯片(Zedboard)并在VIVADO HLS进行综合仿真。
1 先心病心音分类CNN模型设计
1.1 CNN模型设计
CNN是一种深度前馈神经网络,由输入层、隐层、全连接层和输出层组成。考虑到卷积神经网络具有高度并行性的特点,十分契合FPGA的运行机制,CNN也被证实了在心音分类上具有一定的优势。本文设计了一种适于先心病心音分类的CNN结构,该结构由两个卷积层、两个池化层和一个全连接层所组成,如图1所示。
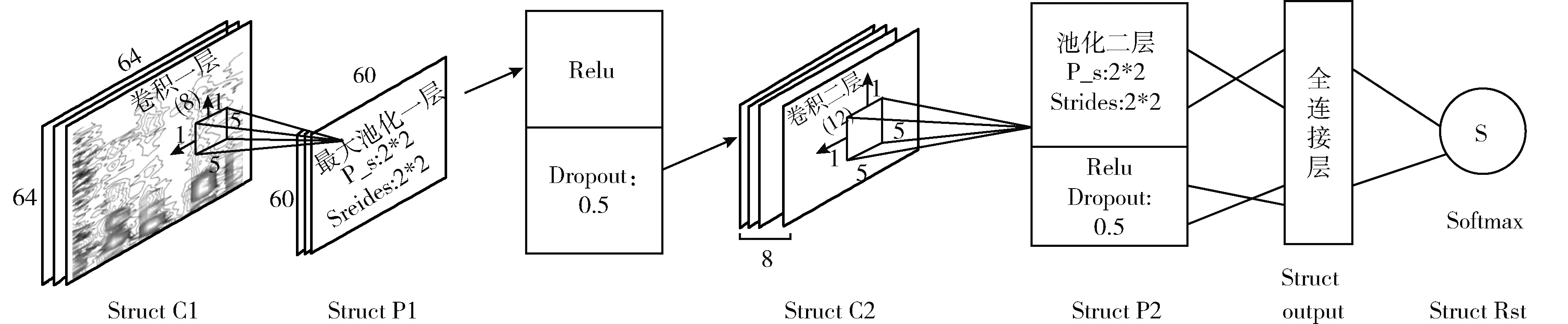
图1 先心病分类算法的CNN网络结构
其中模型的隐层由卷积层和池化层交替连接组成,通过卷积操作提取局部特征,通过池化操作对卷积层产生的特征向量进行降维,并将其输入到一个或多个全连接层。全连接层在整个CNN中起到分类器的作用,其将隐层中学习到的分布式特征映射到样本标记空间,最终经过Softmax获得输出结果。Softmax函数公式如式(1)所示
(1)
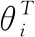
卷积层与池化层之间都需要通过激活函数实现非线性变化,激活函数负责将上一层的输出结果映射成非线性函数,作为下一层网络的输入向量。相比于Sigmoid/tanH函数,ReLU只需要一个门限值,即可得到激活值,计算速度更快。本文采用的ReLU做层间的激活函数, ReLU函数可以很好地克服梯度的消失,ReLU函数公式如式(2)所示,式(2)中x为卷积后输出的参数

(2)
从图1中,可看出本文所用CNN网络结构简单和隐层的参数不多。因为预处理已经显化了数据的特征,因此不需要复杂的网络结构来处理数据。在对算法进行硬件移植的过程中,隐层的参数带来的计算量决定了算法在硬件上的执行效率和硬件资源的使用率。因此,在保证分类准确率的前提下,减少隐层的参数,可以留有大量的硬件资源方便后期的在硬件上的优化操作。在上述模型中,各层的权重值、偏置值、特征图的个数及变量见表1。实验采用基于快速特征嵌入的卷积结构(convolutional architecture for fast feature embedding,CAFFE)框架的CNN模型作为先心病分类算法的分类器。在图1中,在卷积层、池化层、全连接层下面留有结构体名称,会在2.2节对其做解释。

表1 各层权重值、偏置值、特征图个数及变量
1.2 先心病数据集准备
1.2.1 数据说明
本文中1020例心音数据样本,用于训练和测试CNN模型,均为课题组从临床(1岁到20岁)先心病患者,以及在先心病筛查中6岁到20岁志愿者实际采集所得。数据采样率为5000 Hz,每个样本长度为20 s,病例样本均为超声心动图确诊,即采用“金标准”[10]确认过的数据。此数据集中包括:训练集900例,其中正常心音样本450例,异常心音样本450例;测试集为120例,其中正常心音样本60例,异常心音样本60例。研究样本标注为:正常心音标签为0,异常心音标签为1。
1.2.2 数据预处理
借鉴CNN在语音信号处理的研究,本文将一维心音信号[11]进行短时傅里叶变换(short-time Fourier transform,STFT)[12],采用时频分析的方法对心音信号进行分析。在此研究中,将每例样本平均截断成10个片段,每段时长为2 s,含2-3个完整心动周期,如图2所示。随机对每例心音数据选出1个片段,在MATLAB上使用SPECGRAM函数对单个片段进行短时傅里叶变换,用于显化心动周期的特征。考虑到心音信号的病理杂音通常发生在心脏的收缩期,时长约为0.20 s-0.25 s,实施短时傅里叶变换的参数如下选择,窗长0.256 s(1280样点)可以包含一个S1至S2的时间片段;步进128点(0.025 s),可最大限度捕获病理特征,得到如图3所示的时频图,该时频图像素大小为560*420,其反映了心音信号经时域、频域变换后,在相位、频率和能量方面的特征。通过Linux下的BASH脚本中RESIZE函数对其进行归一化,归一化后的特征图像像素大小为64*64。心音数据采用上述方法预处理后,作为后期分类器的输入样本。
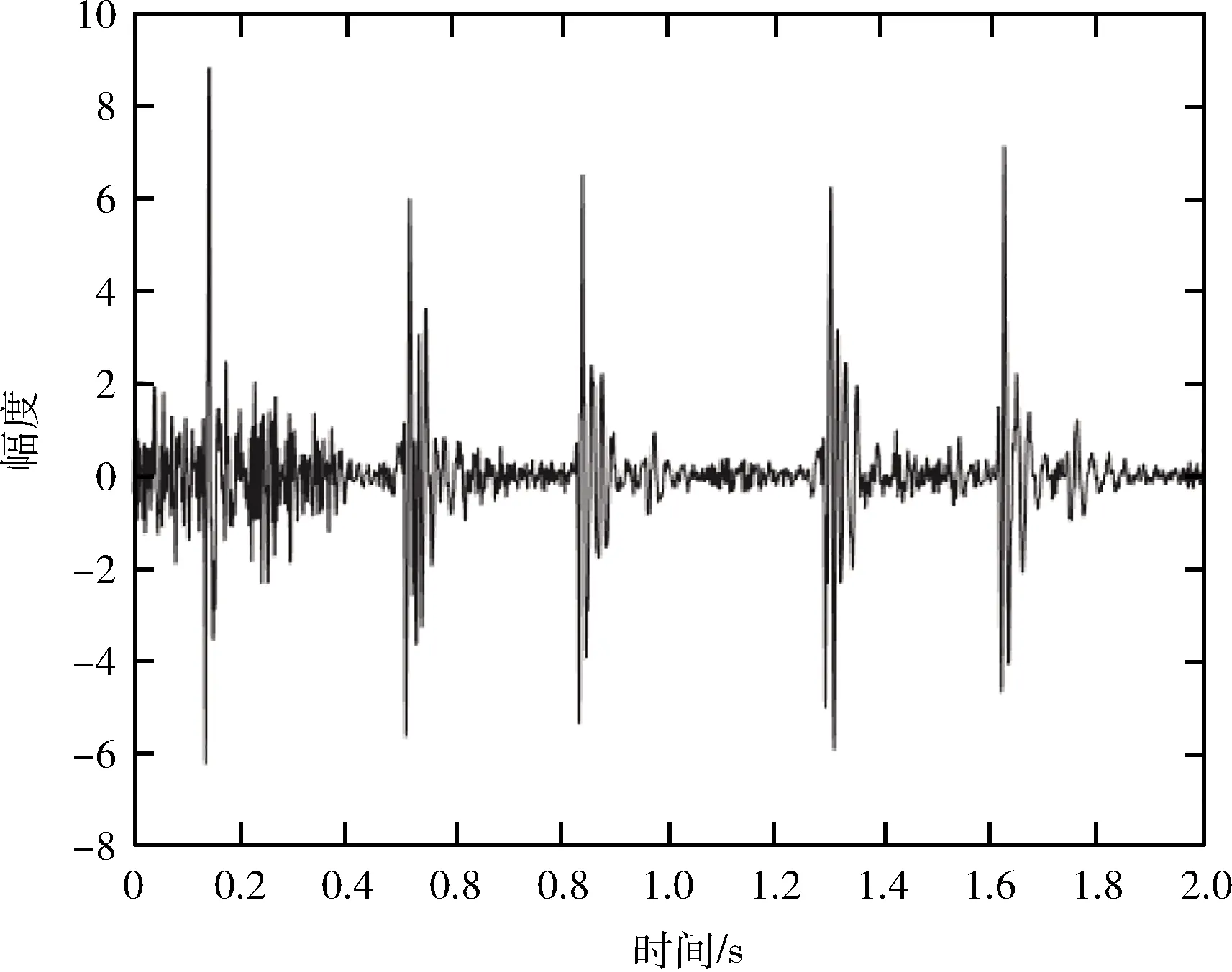
图2 一个心音片段的心音原信号
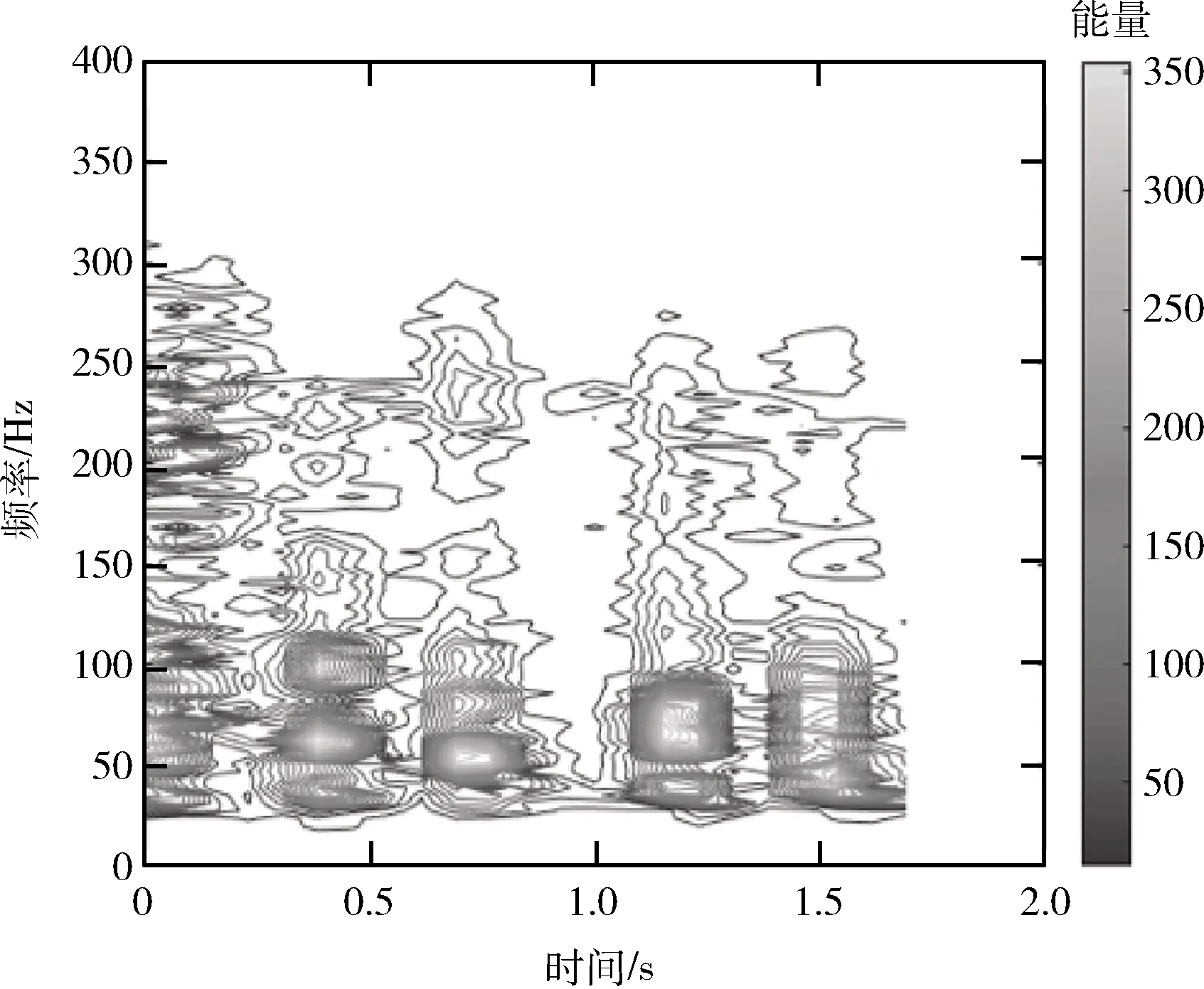
图3 一个心音片段的时频图
1.2.3 数据集制作
为对应本文所设计的CNN模型结构,心音数据需做预处理才能放入CNN模型中进行训练。原始的心音数据是一维信号,而CAFFE框架中使用的数据类型为内存映射数据库(lightning memory-mapped database,LMDB),LMDB并不支持音频信号数据,因此需要将心音数据经过预处理成图像形式,再进行归一化,并生成数据集和均值文件,如图4所示。
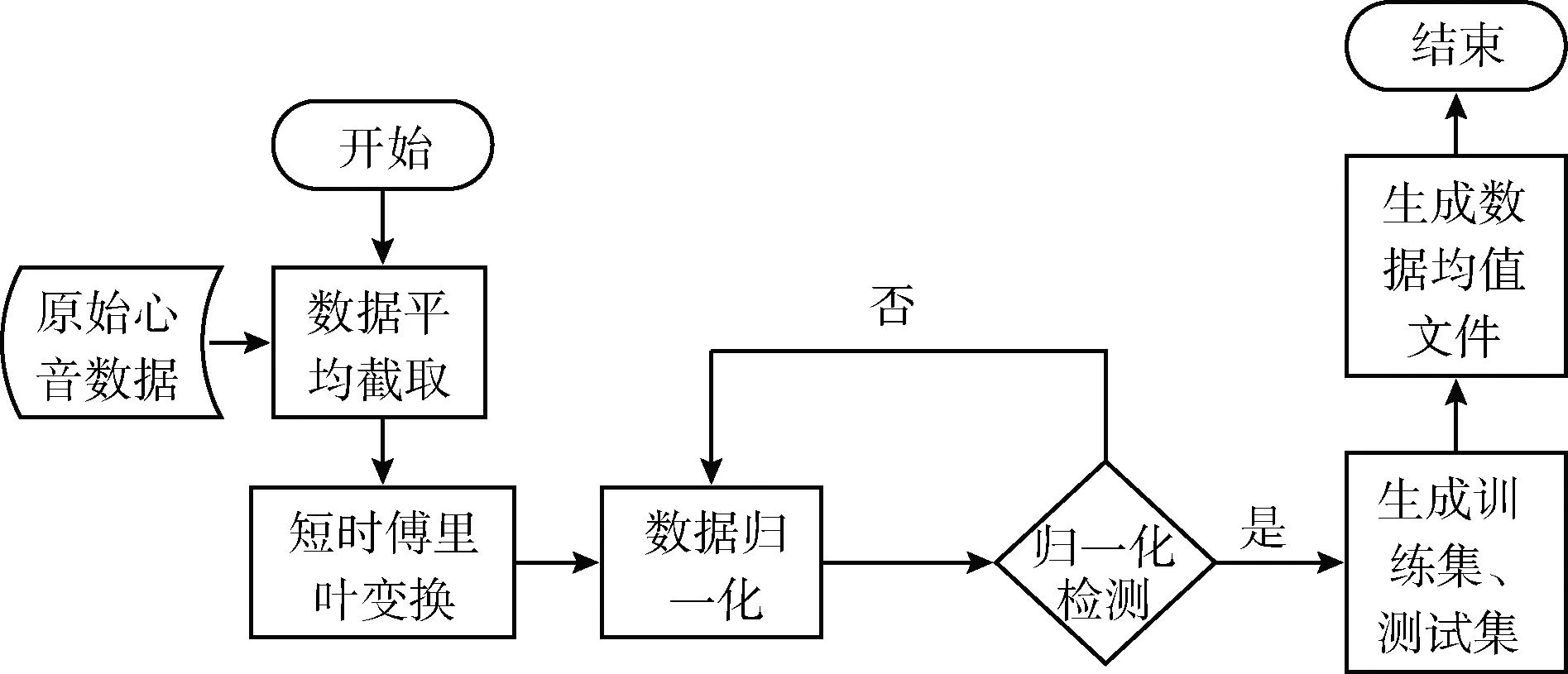
图4 数据集制作流程
1.3 对CNN模型分类训练
经上述的方法,将时频图制作成训练集、测试集后,放入设计好的CNN模型,在PC上进行训练和测试。数据样本共有1020张时频图,其中训练集900张,正常和异常样本各450张;测试集为120张,正常样本有60张,异常样本有60张;实验中在PC上训练900张时频图获得了0.8222的准确度,对120张时频图的分类获得了0.8667的准确度。PC端训练集结果见表2,其中训练集的准确度、损失函数直接从终端显示得知,测试集准确度需要根据式(2)计算得出,PC上对测试集的结果见表3。

表2 PC训练和测试结果
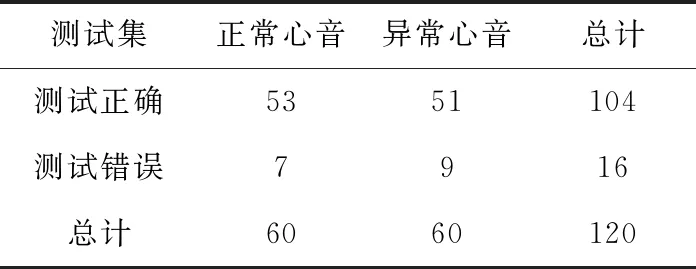
表3 PC测试结果
其中损失函数采用的二分类中常见的对数损失,也称为交叉熵损失,如式(3)所示
(3)

准确度定义为式(4)所示
(4)
式中:TP为正确识别的正常心音,FP为错误识别的正常心音,TN表示为正确识别的异常心音,FN表示为错误识别的异常心音。
2 CNN模型的硬件加速
高层次综合将硬件领域和软件领域相结合,为软件设计人员提供了高效的系统设计,使得软件开发者可以在FPGA上加速算法的密集型计算部分。本文通过以下3个步骤来保证算法在硬件上的适用性、高效性。首先是对模型进行量化,降低计算精度,以应对无浮点硬核的FPGA。然后,利用VIVAOD HLS中提供的编译指令来提高算法在硬件上的工作效率。最后,在FPGA上,通过流水线约束的方法,去控制数据流在硬件中的运行效率,来获得更低的计算延时。
2.1 模型量化
在对算法进行硬件移植的过程中,研究发现大多数的FPGA上并没有浮点硬核[13],因此保持如此高的计算精度并不明智。同时也考虑到今后的算法需要对不同版本的FPGA进行移植,本文采用RISTRETTO固定点浮点数量化工具,对CNN模型的参数进行量化,牺牲了算法部分精度。模型量化的目的是将32位浮点运算转换为16位定点运算,用于适配大多数的FPGA,方便之后的移植。本文在Ubuntu OS下,完成对CNN模型的量化后,编写python脚本用于提取模型参数的权重值和偏置值,并与卷积核数、输入通道和卷积核尺寸保持对应一致;然后将模型提取得到的参数保存为文本格式,使用CC++语言读取文本格式中的内容,用于算法在对数据集进行处理、分类过程中的调用。
需要注意的是,在VIVADO HLS编程中,HLS提供了一种定点数据类型用于将数据建模为整数和小数位。在使用这种类型前,需要先导入AP_FIXED.H头文件,才能使用ap_fixed.h
2.2 HLS中的编译指令使用
在VIVAOD HLS编程中,编译指令(pragma)也是非常重要的一项,因为使用CC++高级综合转换到硬件电路是需要通过添加编译指令来告诉编译器一些额外的操作,这些操作将作为实现各种优化设计的前提。
本文中使用了如下3类pragma编译指令:
(1)接口类指令
代码示例:#pragma HLS INTERFACE
其中
代码示例:#pragma HLS INTERFACE register register_mode =
其中register_mode=
(2)数组类指令
代码示例:#pragma HLS array_partition variable =
其中variable=
(3)数据流类指令
代码示例:#pragma HLS stream variable =
其中variable=
2.3 算法的硬件加速
本文在VIVADO HLS下采用CC++语言对已经训练好的CNN前向过程进行编程,使用CC++语言中的STRCUT类型(其中包含可以调用模型参数的函数)存储隐层参数,通过求地址运算符的方式调用参数。在图1下方展示了模型各层结构对应的结构体名称。其中Strcut C1中存储了卷积一层中的参数,包含权重值的个数为600个(8*5*5*3),其中8为卷积核个数,5*5为卷积核尺寸,3为输入数据的通道数,偏置值的个数为8个。Strcut P1用于存储从经池化一层池化后的结果,Strcut C2中存储了卷积二层中的参数,其包含的权重值的个数为2400个(8*12*5*5),其中12为卷积核个数,5*5为卷积核尺寸,8为输入数据的通道数,偏置值的个数为12个。Strcut P2用于存储经池化二层池化后的结果;Strcut output中存储了全连接层的参数,Strcut Rst用于输出分类结果。预处理后的数据导入进HLS中,需要经过以下的操作来获取结果。
首先将64*64*3的时频图通过调用结构体C1进行卷积,经过ReLU函数处理,得到大于0的数据,再通过第一层的池化处理,将结果保存到结构体P1中。同理,再次调用P1的地址,将参数输入至卷积二层中进行卷积,再进行激活函数ReLU处理及第二层的池化处理,得到的结果数据存到结构体P2中;通过调用P2的地址,将P2中保存的参数输入到全连接层结构体output进行全局变量提取,再经过结构体Rst即可得到对心音数据的识别效果。在VIVADO高层次综合中, FPGA加速CNN的测试文件遵从VIVADO高层次综合的格式规范编写[14],具体测试程序如图5所示,运行完成后在VIVADO HLS的仿真串口中查看运行结果。

图5 高层次综合的TESTBENCH编写流程
本文使用的CNN模型在1.1节中已经介绍,在每一个卷积层内采用6个for循环进行相互嵌套循环。按照顺序依次遍历卷积核数量、通道数量、卷积图像高度、卷积图像宽度、卷积核行数、卷积核列数。为了便于讨论,本文将卷积一层C1中部分代码列出,其中for循环代码如图6所示,代码对应的约束方法如图7所示。本文设定最内层,即卷积核宽度作为第一层,自内向外的层数依次递增,用于说明在不同循环层进行约束后与其所生成IP核的性能的关系。

图6 卷积层for循环代码示例
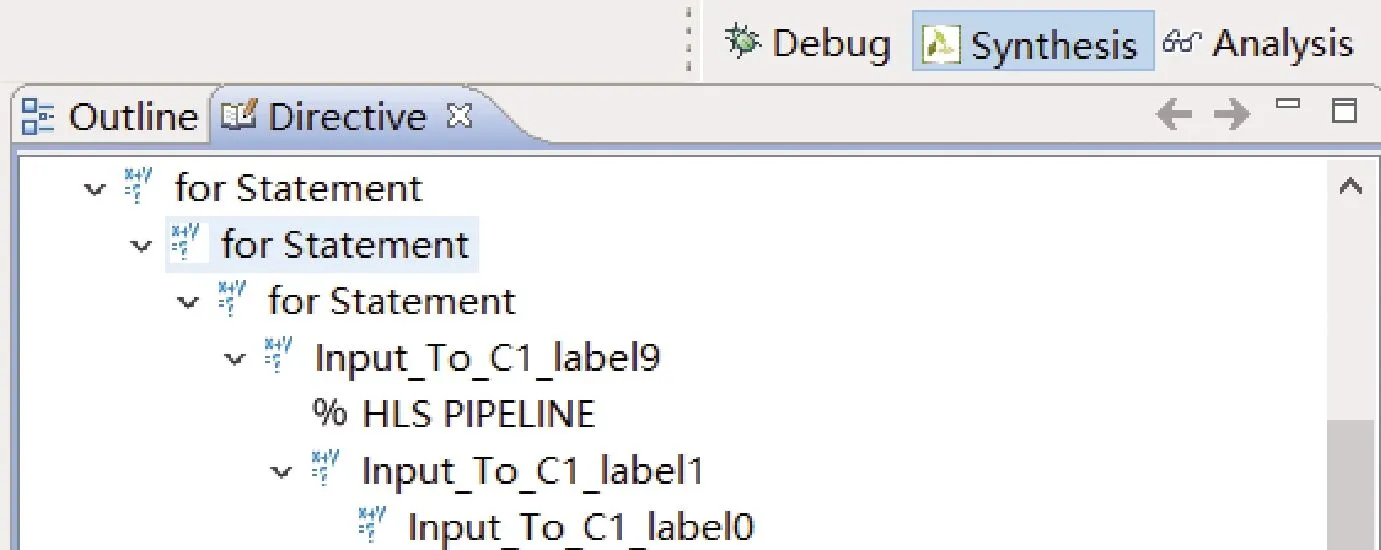
图7 HLS中Directive配置
在FPGA上实现硬件加速算法,通常对卷积中的for循环层采用流水线(Pipeline)约束或者展开(Unroll)约束这类方法来提升算法的执行能力[15]。相对于不采用任何约束的执行方式,Pipeline约束可以减少整个数据的操作时间,且只增加少量的逻辑资源。Unroll约束是将循环完全展开,让多个计算单元同时运行,因此硬件资源消耗比Pipeline约束带来的硬件资源消耗更大,效率也要比Pipeline约束更高。
在目前的研究中,平衡CNN_IP核的资源消耗和计算性能最优的方法是对最内层的循环采用Pipeline约束,使用Pipeline约束的特点是当前层循环下的子循环都会执行Unroll约束[16]。而只对最内层的循环采用Pipeline约束时,由于没有子循环,便不会执行Unroll约束。在这种情况下,CNN_IP核的资源消耗将会是最小的,同时,也可以为大多数应用程序提供可接受的吞吐量。Pipeline约束的层数循环越高,其子循环执行Unroll约束越多,消耗的计算和存储资源将会越多,带来吞吐量的增加和计算延时上的缩减。这就使得IP核的性能得到提高。首先,将卷积一层中的for循环从最内层逐步向外层依次展开,通过HLS生成的综合报告可以看到IP核的各方面的资源消耗;其次,确定好卷积一层的优化后,再开始进行对卷积二层的优化;最后,根据资源消耗报告确定最终优化方案。
3 实验结果与分析
3.1 实验环境
在本文研究中,研发环境为Xilinx公司的VIVADO HLS v2019.1开发工具以及Zedboard开发板(主芯片是XCZ7020),芯片的PS部分的时钟频率为33.333 MHz,芯片的PL部分的时钟频率为100 MHz。PC端的操作系统为Ubnutu16.04 OS,其使用的中央处理器型号为Intel core i5-8300H CPU 2.30 GHz,分别对进行预处理后的单张和多张心音数据样本进行测试,对获得的结果进行了分析。
3.2 实验结果
本实验在VIVADO HLS中编程实现IP核。在卷积一层中,对不同的for循环层采用流水线约束综合后对应的计算延时和硬件资源消耗,见表4。在对卷积一层优化的基础上,对卷积二层优化后IP核的计算延时和硬件资源消耗见表5。最终优化目标的时钟频率、时钟不确定性、估计可达到的最快时钟频率的报告见表6。

表4 C1优化后IP核的延时和资源消耗

表5 C2优化后IP核的延时和资源消耗

表6 IP核的时钟频率报告
表4、表5中的DSP48E表示PL中的数字信号处理逻辑单元,共计220个;LUT表示PL中的一种用于实现组合逻辑和时序逻辑的存储资源,共计53 200个;随着并行度的增加,对数字信号处理器模块(DSP)和LUT的资源消耗的使用会大大增加;从表5中可以看出,在卷积二层中,流水线处理第三层循环时,综合的IP具有最低的计算延时,但是LUT消耗资源已经达到饱和状态。因此最终确定的优化方法是同时对卷积一层中的第三层for循环和卷积二层中的第三层for循环采用流水线约束,计算延时周期数为3 168 322个(每个周期10 ns),单个周期计算延时预计可达8.621 ns,总体计算延时通过计算延时的周期数与单个周期计算延时相乘获得,约为0.03 s。
在卷积一层和卷积二层中,约束不同的for循环层,对单张时频图进行识别所消耗的时间见表7。结合表4,当对卷积一层中的第一层for循环(最内层循环)做流水线约束后,DSP48E的资源消耗量增加约0.5%和LUT的资源消耗量增加约1%,将IP核的计算延时缩短了1.3倍;越往外层约束,资源利用率越高,得到效率也越高,在第三层时IP核的计算延时缩短了1.7倍;再结合表5,对第二层卷积中的第一层for循环进行流水线约束后,DSP48E和LUT的资源消耗量增加约0.5%。在对卷积一层优化后的时间基础上,将IP核的计算延时缩短了1.73倍;对卷积二层中的第三层for循环优化后,LUT的资源消耗达到饱和。对比于表4中,未对IP核作优化产生计算延时,优化后的计算延时缩短了约7.4倍。

表7 PC与嵌入式设备实现算法对数据集测试的效率对比
在上述的基础上,对模型实现流水线约束前后运行效率对比PC上运行效率进行分析,见表7,其Zynq-7020(*)表示未采用任何约束,Zynq-7020表示采用流水线的约束。本文对两个卷积层中的第三层for循环同时采用流水线约束,相比于PC提升了约2.38倍的识别速度。虽然识别率降低了,但是可以增加算法在FPGA中的普适性。
4 结束语
本文在已有研究的基础上进行了新的探索,对心音信号进了预处理,设计了一种结构简单、隐层参数少的先心病心音CNN分类算法。结合CNN内部运算特点,在VIVADO HLS上将算法映射到FPGA中的并行硬件,仿真实现了对算法的硬件加速。解决了先心病心音分类算法需要依赖高成本、高功耗的硬件设备,实时性不高等问题,虽然过程中损失部分精度,但准确率也达到这类方法的平均准确度。本文适用于先心病下乡筛查、定点筛查等场合,这类先心病筛查需要设备具有高效率、低成本等特点。此外,在硬件综合的测试完成之后,可以把硬件加速先心病的分类识别的CC++程序,封装为可供片上系统使用的IP核,这便于今后将先心病心音CNN分类算法向ZYNQ片上系统的移植。
猜你喜欢
广西医学(2022年14期)2022-09-18
天津医科大学学报(2021年3期)2021-07-21
自动化仪表(2020年10期)2020-11-13
中国临床医学影像杂志(2019年1期)2019-04-25
计算机技术与发展(2018年5期)2018-05-28
计算机技术与发展(2017年12期)2017-12-20
无线互联科技(2017年6期)2017-04-26
船舶力学(2015年6期)2015-12-12
中国继续医学教育(2015年14期)2015-01-31
图学学报(2014年2期)2014-03-06
