
基于分组模型的引力搜索智能大数据聚类方法
2021-06-28 11:37:52胡晓东高嘉伟
计算机工程与设计 2021年6期
胡晓东,高嘉伟
(1.山西经济管理干部学院 电子信息工程系,山西 太原 030024; 2.山西大学 计算机学院,山西 太原 030024)
0 引 言
数据聚簇是目前最为流行也最为重要的一种数据分析手段[1],其目标是以数据对象集合分组的方式将其聚类成簇,使同一聚簇内的数据对象具有最大的相似性,即同质数据,而不同聚簇内的数据对象间具有最大的差异性,即异质数据[2]。数据聚簇广泛应用于诸多领域,如机器学习[3]、模式识别[4]、图像处理[5]、数据挖掘[6]等。
目前,受万有引力定理和物体运动规律的启发,一种基于随机种群的元启发式算法被提出,即引力搜索算法GSA[7]。GSA的设计初衷是求解连续最优化问题,与多数元启发式算法相似,该算法拥有较好灵活性,且在加强搜索和开发能力的均衡性上表现突出。GSA的搜索策略是利用万有引力定理将种群成员向着种群中最优的K个解移动。受该算法在变体最优化问题中的启发,本文提出一种基于分组的GSA算法GGSA实现大数据的聚簇求解。提出的GGSA算法与标准的GSA具有两个方面的不同。首先,算法设计一种分组编码策略,将数据聚簇问题的相关结构映射为解的部分;其次,对于给定的聚簇编码,适合于分组编码的解的位置更新与速度更新公式在GGSA算法中被重新定义。为了评估GGSA算法在数据聚簇上的性能,选取了13种经典的数据集进行了测试。对于给定的D个聚簇的数据集,GGSA试图通过随机选择的给定数据集的75%来寻找D个聚簇中心,这75%的数据集称为GGSA的训练数据集。而剩余的25%数据集则用于评估GGSA算法的性能,称之为测试集,而分类失误比率CEP则用于评估算法在测试集中的聚簇性能。
1 相关研究
数据聚簇方法已有很多研究,传统的数据聚簇算法的分类主要以分层和分割的方式进行区分[8]。分层的聚簇算法主要以凝聚式模式或群集式模式递归寻找数据聚簇。凝聚式方法以单个数据对象作为一个分离聚簇,然后连续地合并最具最似性的聚簇直到满足聚簇终止条件。群集式方法初始将所有数据对象视为一个聚簇,然后重复地分割每个聚簇为更小的聚簇,直到满足终止条件。另一方面,分割式聚簇算法试图在不构建分层结构的情况下同步寻找所有的聚簇。事实上,分割聚簇算法初始获得的是不相交的聚簇集合,然后逐步提炼使其满足最小化的预定义目标函数,其目标是在最小化聚簇间的联系的同时最大化聚簇内的联系性,从而实现最大化的数据紧密度,该方法也是本文的研究方法背景。
除了传统的数据聚类方法以外,基于算法聚类标准的不同还有几种聚类方法[9]。第一种是基于邻居共享相同聚类的聚类算法,这类方法主要有基于密度的算法[10]和最近邻邻居方法[11],前者根据对象密度进行聚类,后者则将近邻对象归属于相同聚类中。双聚类算法[12]同步通过行和列进行数据聚类,多目标聚类算法[13]则同步优化了数据集的不同特征进行聚类。重叠聚类算法[14]不同于多数的聚类算法,传统算法中每个对象仅属于一个聚类,而重叠聚类中每个对象可分属于不同的聚类中,最具代表性的重叠聚类即为模糊C均值聚类算法[15]。
近年来,元启发式方法广泛应用在数据聚类问题中。从优化角度上看,聚类问题可建立模型为一类NP难的群组划分问题[16]。这类算法需要搜索一个聚类的最优解,可以降低搜索过程陷入局部最优的风险。具体包括遗传算法GA[17]、模拟退火算法SA[18]、禁忌搜索算法Tabu[19]、智能蜂群算法ABC[20]、贪婪随机自适应搜索算法GRASP[21]、迭代局部搜索算法ILS[22]、可变邻居搜索算法VNS[23]、蚁群算法ACO[24]、粒子群优化算法PSO[25]等。
引力搜索算法GSA是受牛顿的万有引力定理的启发而提出的一种元启发式优化算法。算法中,搜索空间中的一个对象因为质量和重力的关系相互吸引,其吸引力与对象的质量成正比,而与距离的平方成反比。GSA已经被证明可应用于不同类型的优化方法中,包括数据聚类[26]、模糊系统识别[27]、分类问题[28]、排放负载分配[29]、风力涡轮控制[30]以及供电系统[31]中。然而,传统的引力搜索算法直接应用于数据聚类问题时,在问题解的编码机制和解的迭代更新机制上依然存在不足,会导致最优解的搜索过程过早收敛,本文将从这两个方面进行改进,并验证改进后的聚类算法性能。
2 数据聚簇问题

数据对象距离的度量是数据聚簇问题的关键,两个不同的数据对象Oi和Oj间的相似性与特征空间S中的距离是密切相关的,而空间S中的距离度量常用方式是Euclidean欧氏距离。衡量聚簇结果质量的常用目标函数为考虑聚簇内聚度的二次误差之和,可以评价一个给定数据分割的质量,定义为
(1)

(2)
式中:|Ci|代表聚簇Ci的基数,即聚簇i中数据对象的数目。
数据聚簇过程可以分为两类:无监督聚簇和监督聚簇。无监督聚簇即自动式的聚簇,训练数据集无需描述聚簇数目。而监督聚簇中训练数据集合需要描述训练目标和聚簇数目。本文所处理的数据集包括聚簇信息,因此,其优化目标是通过最小化目标函数寻找D个聚簇的中心,即最小化数据对象与其聚簇中心的距离之和。本文中,在训练集OTrain上的一个聚簇C={C1,C2,…,CD}的适应度定义为
(3)

3 引力算法GSA
标准的引力搜索算法GSA是受牛顿万有引力定理的启发发展而来的,这种群体优化技术提供了一种模拟对象在多维空间中由于万有引力影响带来的相互关连的迭代方法。GSA的基本模型中,其初始目标是解决连续优化问题,即一个对象(代理agent)被引入D维解空间中,需要寻找最优解。GSA中的每个代理的位置代表问题的一个候选解,因此,每个代理可表示为问题解空间中的矢量Xi。拥有越好性能的代理将拥有更大的质量,由于更重的代理拥有更大的吸引半径,因此拥有更大的吸引强度。在GSA的运行周期中,每个代理会连续调整其位置Xi,向着种群中最优的K个代理的位置移动。
为了详细描述GSA,考虑一个拥有s个搜索代理的D维空间,空间中第i个代理的位置可定义为
(4)

(5)
(6)
其中,Mi(t)和fiti(t)分别代表时间t时代理i的质量值和适应度值,worst(t)和best(t)分别定义为
(7)
(8)
利用运行定律计算代理i的加速度为
(9)
其中:randj代表区间[0,1]内的均匀分布的随机数;Rij(t)代表D维欧氏空间中两个代理i与j间的欧氏距离;ε代表一个极小值,避免公式中的分母为0,即两个代理i与j间的欧氏距离可能为0,但分母不能为0;Kbest代表拥有最优适应度值和最大质量值的最初的K个代理的集合,K代表时间的函数,算法开始时初始化为Kinitial,其值将随着时间递减;G(t)代表重力系数,拥有初始值Ginitial,其值也将随着时间递减至Gend,且
G(t)=G(Ginitial,Gend,t)
(10)
由此,代理i的速率更新可计算为当前速率的部分与其加速度之和,如式(11),而代理i的位置更新可计算为式(12)

(11)
(12)
其中,rand代表区域[0,1]间的均匀分布的随机值。
标准的GSA算法的过程如算法1所示。

算法1:GSA(1)generate the initial population(2)evaluate the fitness value for each agent(3)calculate the mass value for each agent(4)while stopping criteria is not satisfied do(5) update G, K and Kbest(6) calculate the acceleration of each agent(7) calculate the velocity of each agent(8) update the position of each agent(9) evaluate the fitness for each agent(10)calculate the mass value for each agent(11)end while(12)return best solution found
算法说明:步骤(1)进行种群初始化操作,生成约定数量部署于空间中的代理粒子,每个粒子代表求解问题的一个解;步骤(2)根据适应度函数(利用式(3)计算)对空间中的每个代理的适应度进行评估;步骤(3)利用式(6)计算每个代理的质量;步骤(4)~步骤(11)为算法的迭代求解过程,其中,步骤(5)利用式(10)更新相关参数,步骤(6)利用式(9)计算每个代理的加速度,步骤(7)利用式(11)计算每个代理的速率,步骤(8)利用式(12)更新每个代理在解空间中的位置,步骤(9)再次利用式(3)评估更新代理位置后代理的适应度,步骤(10)利用式(6)计算新的代理质量;最后,在经过约定次数的迭代操作后,在步骤(12)返回找到的最优代理,即问题的最优解。
在GSA中,参数K和G可以均衡算法在局部开发和全局搜索间的性能。为避免陷入局部最优,算法需要在初期迭代中利用搜索机制,而GSA算法可在初期利用较大的参数K值和G值完成搜索操作,即Kinitial和Ginitial必须较高。越大的参数K值可基于更多代理的位置加速代理在解空间中的移动,进而提升算法的搜索性能。同样地,越大的G值也可以增加代理在解空间的移动能力,增加其搜索性能。Kinitial和Ginitial值越高,解空间中更好的区域可在算法迭代中更可能被识别。因此,随着算法的迭代进行,GSA的搜索能力将减弱,开发能力将逐渐显现。而降低参数K和G值可以提升其开发能力。越小的K值可基于更少的代理位置使代理在解空间中移动,进而提升其开发能力。同样地,越小的G值则可以降低每个代理在解空间中的移动性能,增强其开发能力。因此,解空间中更好的区域在迭代中更有可能被开发出来。
4 基于分组模型的引力搜索算法GGSA
为求解大数据的聚簇问题,本文提出了一种基于分组的引力算法GGSA,算法考虑数据的聚簇结构设计了一种特定的聚簇编码方式。在给定的编码下,重新设计了代理的位置和速度更新公式。
4.1 解的编码
问题解的表达必须适合且与处理的优化问题具有很好的关联性,这样易于搜索操作符的控制,从而降低对解的搜索中的时间和空间复杂度。GGSA算法中解的编码利用一种分组表达方式,由两个不同的部分构成:物品item部分和分组group部分。item部分由大小为n的数组构成(n代表数据对象的数目),group部分由D个分组(聚簇)标签的排列构成。item部分中的每个成员可以对应D个分组标签中的任意一个,代表对应的物品可属于给定标签聚簇中。图1描述了GGSA中一种基于分组的解的编码示例,其中,数据聚簇问题O={O1,O2,O3,O4,O5}的一个解可表示为C={C1={O1,O3},C2={O2,O4,O5}}。

图1 5个数据对象聚簇中由两个聚簇构成的侯选解
利用标准的GSA优化一个连续函数时,通常每个解可表示为实值长度为D的矢量(D为空间中的搜索维度),而每个值则对应一个变量。类似地,利用GGSA算法解决数据聚簇问题,由D个聚簇构成的一个解也可以表示为长度为聚簇数目的结构。换言之,GGSA算法中的分组group即为标准GSA中的变量,在第d个维度上对象的位置即代表第d个参数的值,它决定了该数据对象属于第d个聚簇。本文中,在可行解X中聚簇数目以D表示。
分组编码的属性可以使解具有较低的冗余度。若问题的一个解拥有多个不同的编码,则认为该编码具有冗余度。在这种情况下,问题的解空间与算法的编码空间之间的映射关系是一对多的关系。算法编码冗余会扩大搜索空间,且无法适应搜索操作符的搜索过程,从而降低算法效率。
4.2 GGSA的公式更新
给定解的分组表达,本节的目标是重新定义式(9)、式(11)和式(12),使得算法可以数据聚簇方式替代标准GSA中的标量方式。重定义等式的主要特征是使其可以在连续空间内运行。
为识别GSA的主要搜索操作符,假设代理构成的种群被初始化在问题的解空间中。若应用GSA求解优化问题,则算法会试图在问题解空间中移动代理的位置,进而寻优。基于式(12),这种代理位置的移动是通过典型的加“+”操作符实现的,它需要两个输入参数,即代理i的当前位置和代理的移动长度。然后,返回解空间的新位置作为输出。代理i的移动长度即为其速度。基于式(11),代理i的移动长度由两类移动长度构成:独立移动长度IML和依赖移动长度DML。IML为代理对其它代理位置未知仅对自身位置已知的情况下得到的移动长度,该移动长度仅取决于它先前的移动长度(或先前的速度),本质上是先前移动长度的一部分。另外,DML是代理通过考虑Kbest集合中所有成员位置的情况下得到的移动长度。式(9)显示了代理的DML的计算方式。根据式(9),代理的DML取决于多个因素,包括:代理j的位置(j∈Kbest),代理i与j间在第d个维度上的线性距离,代理i与j间的欧氏距离,代理j的质量值以及引力系数值。为了重新定义式(9)、式(11)和式(12),使其可以分组的形式操作替代标量操作,需要重新定义3个操作符:线性距离操作符“-”、欧氏距离操作符以及移动操作符“+”。
标准GSA中,线性距离操作符量化的是两个标量间的线性距离,该操作符需要重新定义使其能够量化两个数据聚簇间的距离。聚簇距离度量方式有多种,一种是聚簇间的最小距离,即两个最邻近成员间的距离;另一种是聚簇间的最大距离,即两个相距最远的成员间的距离。而k均值距离度量方式则是以成员与聚簇中心的距离来度量。本文设计一种基于杰卡德距离(Jaccard distance)的聚簇间距度量方法。令C1和C2为基数为|C1|和|C2|的两个数据聚簇,聚簇C1和C2间的杰卡德距离定义为
(13)
式中:DistJ(C1,C2)代表两个分组C1和C2间的差异度,它决定了两个聚簇分离的远近。如果有C1=C2,则差异度为0;如果有C1∩C2=∅,则差异度为1。通常情况下,有0≤DistJ(C1,C2)≤1。
为重新定义欧氏距离操作符,GGSA算法将以聚簇操作代替标准GSA算法中的标量操作。换言之,类似于GSA,其代理在第d个维度上的位置代表d维变量的值,GGSA中代理的位置将决定数据属于第d个聚簇。令C={C1,C2,…,CD},C’={C’1,C’2,…,C’D},表示数据对象的两个候选聚簇,定义聚簇C和C’间的欧氏距离为
(14)
利用以上公式计算DistJ(.,.)时,距离计算之前需要适当对聚簇进行配对。为降低随机聚簇配对的负面影响,算法需要重新对C和C’聚簇进行索引分配,使得最为相似的聚簇总能完成配对。本文使用一种最大权重双向配对MWM方法进行聚簇的配对操作,MWM排序规则以一个拥有两种结点的完全双向相似图开始进行聚簇配对,一种为源结点,一种为目标结点。每个源结点对应于C中的一个聚簇,每个目标结点对应于C’中的一个聚簇。两个结点间的边以结点间的相似度赋予一个权重值,该相似度即为杰卡德系数,为(|C1∩C2|/|C1∪C2|)。令Gb表示一个加权完全双向相似图,Gb中的配对即寻找未入射至任一普通结点的边的子集。若属于匹配的结点是一条边的入射结点,则该匹配会覆盖该结点。通过这种方式,寻找Gb中的具有最大权重和的匹配(即最大权重匹配)以及对C’中的聚簇重新进行索引分配(重新排序),使得参与匹配的边的双方终止结点(聚簇)将拥有相同的索引,并且满足C和C’中具有最相似的聚簇进行配对的目标。

(15)
(16)
4.3 GGSA的新解生成方法
GGSA算法利用两阶段生成新的解。第一个阶段为继承阶段,即解Xi(t+1)可以继承解Xi(t)的部分基因,这使得解Xi(t+1)可能会丢失部分物品Item。第二个阶段为重新插入阶段,该阶段可以使得丢失的item可以重新插入已有的聚簇中。

(17)

算法2是GGSA中代理i在迭代t+1时生成新解的过程。
算法2:

(1)//MWM ordering rule (2)ford=1 to Ddo (3) pair cluster d of Xi(t) with the most similar cluster in Xj(t)(for all Xj(t)∈Kbest) by MWM pairing procedure (4)//Inheritance phase继承阶段 (5)calculate the value of EuclidianJ(Xi(t),Xj(t))(for all Xj(t) ∈Kbest) using Eq.(14) (6)for d=1 to Ddo (7) calculate the value of DistJ(xdj(t),xdi(t))(for all Xj(t)∈Kbest) using Eq.(13) (8) compute vdi(t+1) using Eq.(15) (9) calculate the value of ndi(t+1) by Eq.(17) (10) randomly select ndi(t+1) items fromcluster xdi(t) and allocate them to new cluster xdi(t+1) (11)end for (12)//Reinsertion phase重新插入阶段 (13)for each data Oj that have not been selected in the inheritance phase do (14) allocate data Oj to an existing cluster with the closest center (15)output: solution Xi(t+1)
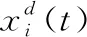
5 仿真实验
5.1 实验环境配置
本节利用UCI数据库[32]中13种实际的测试数据集对算法性能进行仿真测试,所选取的测试数据集涵盖了低、中和高维度的数据实例,后文中首先描述了所选的13种经典数据集的特征,然后同另外4种启发式数据聚簇算法进行仿真测试。
本文利用提出的算法求解了不同测试数据集的聚簇问题,算法利用C语言编程实现,硬件环境为2.2 GHz的Intel CPU。算法运行中的固定参数设置如下:数据对象数量s设置为20,K的初始值Kinitial设置为10,G的初始值Ginitial设置为1,G的终止值Gend设置为0.5,算法的最大迭代次数设置为200。同时,两种基于时间的线性函数用于降低参数G和K的值。
5.2 性能评价指标
对于每一个数据集,实验首先记录了算法聚簇后的分类失误比率指标CEP,该指标表示测试集中错误分类的数据比率,其计算方法如下:首先,对全部测试数据进行分类,并统计错误分类的数据量。由于对于特定的测试数据集,每个数据实例的实际分类标签是可以提前知道的。然后,错误分类的数据量与测试集中总的数据实例数量相除,并乘以100即可得到百分比,即计算方式为
除此之外,进一步引入聚类内的距离之和度量聚类算法的性能,该指标表示一个聚类内的数据矢量与聚类质心间的距离。聚类内距离之和越小,表明数据聚类结果的质量越高。定义为
其中,zj表示聚类j的质心质量,xp表示第p个数据矢量,d表示每个质心矢量的特征量,nj表示聚类j的数据矢量数量,Cj表示形成聚类j的数据矢量的子集。
5.3 数据集描述
本文所选取的13种测试数据集为机器学习领域最为常用的测试数据,表1显示了测试数据集的特征,包括数据实例数量、数据特征数量以及分类数量。每一个数据集中,随机选择75%的数据用于训练集的训练过程,剩余25%的数据用于算法的测试过程。表1同时给出了训练和测试集的数量。训练阶段后,可以获得聚簇中心作为从训练集中提炼出来的知识而用于分类测试集。

表1 13种测试数据集的特征
5.4 结果分析
算法在13种经典的测试数据集中进行了测试,其生成的计算结果与以下几种典型的元启发式算法进行了性能对比,包括:标准引力搜索算法GSA[33]、智能蜂群算法ABC[34]、粒子群算法PSO[35]以及萤火虫算法FA[36],对比结果见表2。

表2 算法的分类失误比率
表2表明,在所有测试数据集,本文算法GGSA优于PSO和标准GSA,在其中10个数据集,GGSA优于ABC,而在其它3种数据集中,ABC和GGSA几乎表现出相同的性能。对比FA算法,GGSA也得到了可接受的结果,仅在数据集Cancer、Heart和Thyriod中,FA要优于GGSA。而且,对于所有测试集,GGSA的平均CEP为8.9%,而FA为11.36%,标准GSA为11.41%,ABC为13.13%,PSO为15.99%。由表2的最后一行的平均值可以看到,本文的GGSA算法是5种元启发式算法中排序第一的算法。
表3为5种数据聚类算法在所有数据集中的聚类内距离测试结果。所记录的值为20次仿真实验测试得到的平均值。可以看到,本文基于分组模型的引力搜索机制下的数据聚类算法得到的聚类内距离的均值是小于其它4种算法的,且在不同的测试数据集中得到的结果均体现出了一定的优势,这说明算法在处理不同属性和不同分类量的数据集时具有很好的适应性和鲁棒性。其它4种算法之间,并没有体现出在不同测试数据集下的绝对性能优势,即在不同数据集上得到的聚类距离的差距是不一致的。如FA算法在Balance、Cancer-Int、Thyroid等数据集中是除了GGSA算法之外表现最好的一种算法,但它在其它数据集中得到的测试结果不是最优的,这说明算法在处理具有不同特征的数据时并不能保证性能的稳定性。

表3 算法的聚类内距离度量
6 结束语
为求解数据聚簇问题,提出一种基于分组的引力搜索算法GGSA。该算法在解决数据聚簇上的优势在于:首先,基于分组模型的解的编码方式最大限度降低的编码的冗余度,使数据聚簇问题的相关结构与引力搜索空间中解间映射关系得到了最好的表达;其次,算法中搜索代理的位置与速度更新机制与标准GSA是类似的,但利用了基于差异的分组因子替换了标准GSA中的算术操作符。聚簇差异性度量的使用允许算法以聚簇操作代替原始的标量操作。通过仿真实验的评估,验证了基于分组的GSA算法在分类失误比率指标上要优于同类型的几种数据聚簇算法。
猜你喜欢
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
趣味(数学)(2018年12期)2018-12-29 11:24:00
科学与财富(2018年30期)2018-12-28 20:41:40
现代营销(创富信息版)(2018年8期)2018-09-08 08:51:50
计算机应用(2016年9期)2016-11-01 17:57:12
学生天地(2016年23期)2016-05-17 05:47:15
体育科技(2016年2期)2016-02-28 17:06:21
电测与仪表(2015年15期)2015-04-12 00:43:48
河北科技大学学报(2015年5期)2015-03-11 16:16:37
中央民族大学学报(自然科学版)(2014年1期)2014-06-11 01:28:38
