
基于联合注意力生成对抗网络的自动文摘模型
2021-06-28 12:42:36董张慧雅
计算机工程与设计 2021年6期
董张慧雅,张 凡,王 莉
(1.太原理工大学 信息与计算机学院,山西 太原 030600; 2.太原理工大学 软件学院,山西 太原 030600;3.太原理工大学 大数据学院,山西 太原 030600)
0 引 言
关于自动文摘的研究方法主要两种方法:抽取式方法[1]和生成式方法。抽取式方法主要提取原文中的重要句子或段落组成摘要,需要考虑摘要内容的相关性和冗余性。而生成式方法是基于对文档的理解,然后归纳总结生成摘要,所以它更接近摘要的本质,然而,在抽象概括方面仍有很大的改进空间,这也是我们研究的主要方向。Rush等[2]提出基于注意力的端到端网络模型来生成摘要,在此基础上许多工作都得到了改进;See等[3]提出了一种指针生成器网络(pointer-generator network),该模型通过指针从文档中复制单词,解决了未登录单词(out-of-vocabulary,OOV)的问题,还增加了一种覆盖机制来解决输出重复的问题;Paulus等[4]提出一种目标函数,该函数结合了交叉熵损失与从策略梯度得到的奖励,减少了暴露偏差[5];Liu等[6]将生成对抗网络[7]与强化学习的策略梯度算法[8]结合起来并应用到自然语言处理领域,它采用对抗策略训练网络,并取得较高的ROUGE分数[9]。Hsu等[10]提出了提取式和抽象式结合的方法生成摘要,使得文档的上下文向量表示更准确地反映了文档主旨。
以上方法都是基于单词层注意力对文档进行表征,忽略了句子信息,这对于非频繁但重要的单词并不友好,很容易丢失文档中的重要信息。事实上,关键的句子往往反映了句子中的单词也非常重要。为此,本文提出一种基于联合注意力的生成对抗网络模型,将句子的信息融入对单词向量的表示中,减少对非重要句子中单词的关注度并提高重要句子中单词的注意力,从而提高了对文档上下文向量表示的合理性,使得最终生成的摘要质量更高。另外,为了更好的训练效果,提出一种联合损失函数训练生成器。
为了验证本文所提模型的有效性,在公共数据集CNN/Daily Mail 数据集上进行实验,并与相关主流模型进行对比,实验结果表明,该方法可有效提高自动文摘的质量。
1 基于分层注意力生成对抗网络的文摘生成
本文使用生成对抗网络机制[7]训练两个模型:生成器和判别器。生成器采用编码器-解码器结构,编码器通过双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)和联合注意力机制得到文档的上下文向量表示,解码器使用长短记忆神经网络(long short-term memory,LSTM)生成摘要,最后将生成的摘要和参考摘要(人工总结的摘要)共同输入到判别器中,迭代训练生成器和判别器。整体模型如图1所示。

图1 基于联合注意力的生成对抗网络训练模型
1.1 联合注意力机制

(1)
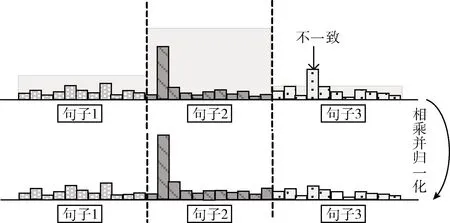
图2 联合单词层和句子层注意力

1.2 生成器生成摘要
生成器采用编码器-解码器结构,单词序列w输入Bi-LSTM转换成编码器隐藏状态h={h1,h2,…,hm,…},在第t步时,解码器(LSTM)接受参考摘要中的第t-1个单词嵌入生成解码器隐藏状态st,根据编码器和解码器的隐藏状态,得到在t时刻文本单词的注意力分布为
(2)
αt=softmax(et)
(3)

(4)
该上下文向量表示可以看作当前步对文档的表征,再经过与解码器隐藏状态连接和两个线性层,可以得到在固定词汇表上的单词分布,公式如下所示
(5)
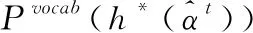
(6)

(7)
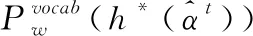
1.3 判别器判别摘要
判别器是一种二元分类器,其目的是区分输入的摘要是由人产生的还是由机器产生的。因为卷积神经网络在文本分类中显示了极大的有效性[12],本文使用卷积神经网络对输入序列进行编码。先使用不同大小的过滤器得到多种特征,然后对这些特征应用最大池化操作。这些合并的特征被传递给一个全连接的softmax层,最后输出为真或为假的概率。
1.4 生成对抗网络模块
生成对抗网络主要采用零和博弈的思想,生成器G与判别器D是博弈的两方,判别器尽可能地区分输入的摘要是由人生成的还是由机器生成的,而生成器尽可能地产生更真实的高质量摘要骗过判别器,这样在博弈过程中生成器被训练的越来越好,生成的摘要越来越真实,像人类写的一样,而判别器也被训练的更加“聪明”,有更强的区分能力。生成器与判别器的最大最小博弈函数为式(8)
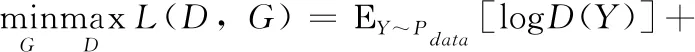
(8)
Y表示模型生成的摘要或者人工生成的参考摘要,D(Y)是判别器判别输入摘要为真的概率,或者说是奖励。越高的奖励说明生成的摘要越好,判别器与生成器相互对抗,最后训练的理想结果是判别器判别不出输入的摘要是由人类生成的还是由机器生成的,同时生成器生成的摘要质量也很高。
2 损失函数
按照图1所示的自动文摘生成模型,本文提出了由极大似然估计损失Lml、策略梯度损失Lpg、不一致注意力损失Linc以及句子层注意力损失Lsen构成的联合损失函数用于训练生成器。本节将依次介绍判别器、句子层注意力和生成器各自的损失函数。
2.1 判别器的损失函数
在生成器与判别器的对抗训练过程中,判别器作为生成器的奖励函数,它判别输入的文本是由人工生成的还是由机器生成的。通过对判别器的动态更新,迭代地改进生成器,使其生成质量更好的摘要。一旦生成器生成高质量和更加真实的摘要,就重新训练判别器,训练判别器公式
Ldis=minΦ-EY~Pdata[logDΦ(Y)]-EY~GΘ[log(1-DΦ(Y))]
(9)
DΦ(Y)是判别器给输入序列的奖励,它代表输入序列为真的概率,即判别输入序列为人工生成的概率。Φ和Θ分别代表了判别器和生成器的参数集。该公式的含义是判别器给参考摘要尽可能高的分数,给生成器生成的摘要尽量低的分数,这样损失函数的值才会小。
2.2 句子层注意力损失函数
为了鼓励单词层和句子层这两个层的注意力在训练过程中有一致的学习目标和一致性,即在该单词注意力很高时该单词所属的句子注意力也很高,本文采用不一致注意力损失函数
(10)
在计算某个单词的损失时,只选取其前k个单词,对它们的单词层注意力和所在句子的句子层注意力相乘并求和,依次计算T个单词的损失函数,进行相加取均值得到整篇摘要的不一致损失,T是摘要的单词总数。注意到如果采用两阶段的训练方式,式(1)是唯一句子层注意力参与到编码器的部分,不一致损失只有在端到端训练时才加入到生成器的损失函数中。
为了得到句子层的注意力分布,本文参考了Nallapati等[11]的方法,采用双层的循环神经网络结构,第一层得到句子的表征,第二层作为分类器得到每个句子的注意力大小。首先第一层输入句子中每个单词的单词嵌入,经过双向的GRU(gated recurrent unit)网络得到每个单词的隐藏状态,再经过向量求和得到每个句子的表征。第二层输入刚刚得到的每个句子的表征,经过双向GRU网络和一个sigmoid函数,最终得到每个句子的注意力β,该网络结构如图3所示。
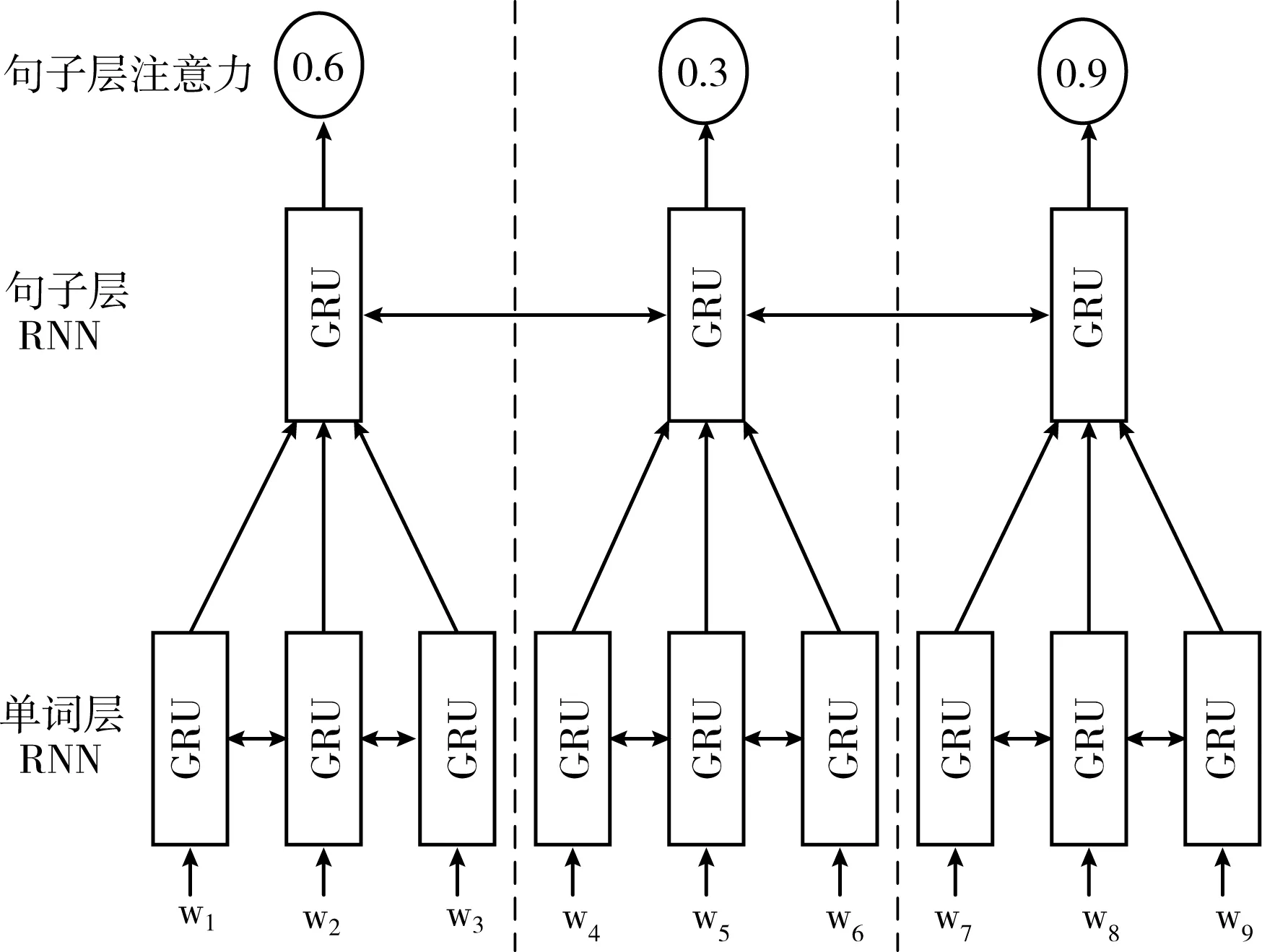
图3 句子层注意力结构
在训练句子层注意力网络时,由于在顶层采用了sigmoid激活函数,所以本文采用交叉熵损失函数训练网络,损失函数如下
(11)
式中:gn∈{0,1}是第n个句子的真实标签,N是参考摘要中的句子总数。当gn=1时,表示第n个句子含有的信息量高,若gn=0,则表示第n个句子含有的信息量少。而句子层注意力就是为了得到具有高信息量的句子,所以准确地为句子打标签至关重要。为了获得真实标签g={gn}n,首先,通过计算句子sn和参考摘要的ROUGE-L值获得文档中每个句子sn含有的信息量,然后我们根据ROUGE-L值对句子排序并从高到低选择信息含量丰富的句子。如果新句子可以提高已经选择的句子的信息量,则把该句子的标签gn置为1,并加入已经选择的句子集合中,最后通过式(11)训练句子层注意力网络。
2.3 生成器的损失函数
当判别器更新后,再训练生成器G,生成器的损失由极大似然估计损失Lml、策略梯度损失Lpg、不一致注意力损失Linc以及句子层注意力损失Lsen组成,分别赋予λ1,λ2,λ3,λ4权重,极大似然估计损失为式(12)
(12)
通过最小化极大似然估计损失,使得生成器生成的文本越来越接近参考摘要。由于极大似然估计存在两个重要问题。第一,评价指标为ROUGE评价指标,而损失函数为极大似然估计损失,评估指标和训练损失不同。第二,解码器在训练过程中每个时间步的输入往往是参考摘要中的单词表征,但在测试阶段解码器的输入是上一步的输出,一旦上一步出现错误,会影响下一步的输出结果,这样造成错误累计,形成暴露偏差。为了缓解上述问题,本文使用策略梯度算法对ROUGE-1进行了直接优化。生成器经过训练,使判别器给的最终奖励最大化,策略梯度损失如下
(13)

(14)
b(X,Y1∶t)是基线值以减少奖励的方差。由于生成器加入了句子层注意力来更新单词层注意力,需要再加上不一致注意力损失和句子层注意力损失,构成生成器的联合损失函数如下
LG(Θ)=λ1Lml+λ2Lpg+λ3Linc+λ4Lsen
(15)
需要注意的是在分阶段训练时生成器的损失不包含不一致注意力损失和句子层注意力损失。
3 实验结果与分析
3.1 数据集
本文实验使用CNN/Daily Mail数据集[3,11],它收录了大量美国有限新闻网(CNN)和每日邮报(Daily Mail)的新闻数据。每篇文章都有人工总结的参考摘要与之对应。本数据集有匿名版本和非匿名版本两种,前者把所有的命名实体替换成特殊的标记(例如@entity2),后者保留原始的新闻内容。我们使用非匿名版本,其中包含287个、226个训练对、13 368个验证对以及11 490个测试对。固定词汇表的大小是50k。
3.2 评估指标
实验采用ROUGE评估指标,将生成摘要与参考摘要相对比,其中ROUGE-1和ROUGE-2指标是分别是1元词(1-gram)和2元词(2-gram)的召回率,ROUGE-L指标计算的是最长公共子序列(longest common subsequence)的得分,具体计算方法参见文献[9]。
3.3 实验及结果分析
为了获得更好的实验结果,本文实验对获取句子注意力模型(图2)和整体模型进行了预训练,词嵌入均为128维,学习率设置为0.15,隐藏层大小分别为200和256。在预训练获取句子注意力模型时,限制原始文本的句子数和每个句子的长度为50。在预训练整体模型时,把信息量高的句子(gn=1)作为模型的输入,限制原始文本的长度为400,摘要的长度为100,批次大小为32。
为了探究句子层注意力对实验结果的影响,本文设置两种训练方式:①分阶段训练;②端到端训练。
实验1:分阶段训练
实验设置句子层注意力β为硬注意力,此时句子层注意力模型为一个二元分类器,把βn>0.5的句子作为整体模型的输入,而β是通过预训练得到的。实验参数设置见表1。

表1 本文模型参数
实验2:端到端训练
要最小化联合损失函数(式(15)),其中λ1=λ3=1,λ2=λ4=5,在计算Linc损失时设置k=3。学习率降到0.0001,这样可以保证训练的稳定性,神经网络模型采用Adagrad优化器进行优化。端到端训练时模型的输入为整篇文档。实验将本文提出的方法与主流方法进行对比,包括pointer-generator[3]、abstractive deep reinforce model(DeepRL)[5]、GAN[6]、unified model[10]。不同的方法进行实验得到的ROUGE-1、ROUGE-2和ROUGE-L值见表2。
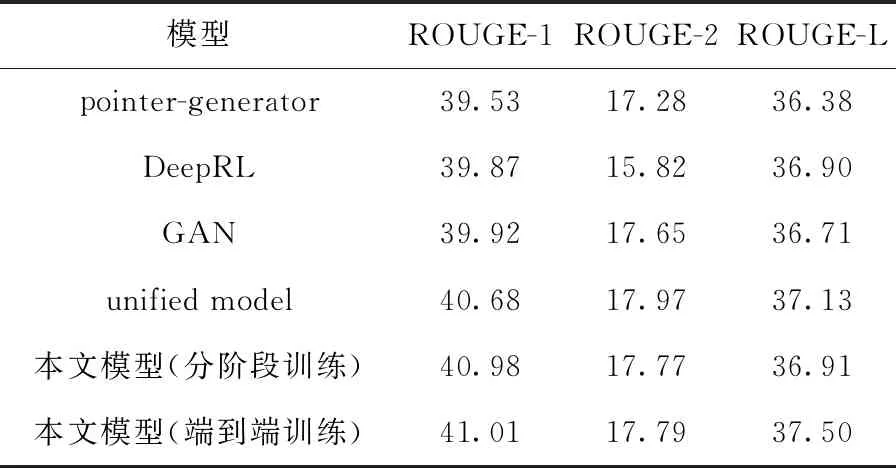
表2 不同算法的ROUGE值
每一行显示了一个算法的结果,可以看出,主流方法表现较好的是unified model,ROUGE-1和ROUGE-L值分别为40.68和37.13,而本文模型采用分阶段训练方式时ROUGE-1值有所提高,为40.98,采用端到端训练方式时ROUGE-1和ROUGE-L值均有所提高,分别为41.01和37.50,表明端到端的训练方式可以获得更好的训练结果。综上所述,本文提出的模型有效提高自动文摘的质量,同时由于结合了句子层注意力,从而可以准确捕捉重要单词,表达的中心思想更加准确。
下面对这几种模型和本文提出的模型生成的摘要进行比较,选取了其中一篇文档作为实验结果的展示,文档内容与其匹配的参考摘要如图4所示。对图4所示文本,几种不同模型生成的文摘如图5所示。

图4 样例文档和参考摘要
图5给出了几种不同模型的实验结果,本文用下划波浪线标示原文的重要信息,用粗体标示参考摘要与本文模型重合的部分,从结果可以看出,本文提出的模型可以生成更加准确的摘要,与参考摘要更加匹配,而其余几种模型存在重复问题或者缺乏重要信息的问题(如下划直线所示)。总体来看,本文提出的模型对自动文摘生成有改进作用。

图5 几种模型生成的文摘
4 结束语
本文根据越重要的句子包含越多的关键字,在生成对抗网络的基础上,加入句子层注意力,通过句子层注意力对单词层注意力的调节,使得获取的上下文向量表示更准确地表达了当前状态的文档信息,从而使得后续的文摘生成更加准确。另外本文在原有的生成对抗网络损失函数上加入单词层与句子层注意力的不一致性损失,反过来协调了句子层注意力。生成对抗网络生成的句子具有很好的连贯性,再加上句子层注意力帮助生成的主旨更加准确,最终使得生成的摘要具有更好的连贯性和可读性,实验结果表明,联合注意力对结果有了一定改进。本文提出的模型在自动文摘领域效果良好,能提升文摘的质量。在大规模文档理解、分析和总结方面有广泛用途。本文采用LSTM得到文档的上下文向量表示,未来可考虑更好的方法对文档进行表征,以使向量容纳更多的文本信息。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国新闻周刊(2021年26期)2021-07-27 04:02:12
环境影响评价(2020年2期)2020-12-02 01:23:50
传媒评论(2017年3期)2017-06-13 09:18:10
宝藏(2017年2期)2017-03-20 13:16:46
信息安全研究(2016年4期)2016-12-01 06:06:54
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
电脑迷(2012年4期)2012-04-29 06:12:13
祝您健康(1985年3期)1985-12-30 06:51:16
