
基于混合过滤编码的神经中文生成式摘要
2021-06-25 02:08蓝雯飞周伟枭许智明朱容波罗一凡
中南民族大学学报(自然科学版) 2021年3期
蓝雯飞,周伟枭*,许智明,朱容波,罗一凡
(1 中南民族大学 计算机科学学院,武汉 430074;2 福州大学 机械工程及自动化学院,福州 350108)
文本摘要是自然语言处理(NLP)的重要任务,其主要目的[1]是从文档中抽取或总结其中的重要信息、获取摘要并用以概括和展示文档的主要内容或段落大意.
以摘要方式作为分类依据,文摘技术主要分为抽取式摘要和生成式摘要.以摘要处理对象作为分类依据,文摘技术主要分为单文档摘要和多文档摘要.
本文主要关注生成式摘要,此类方法通过重新组织给定文档的重要信息并生成单词序列获得摘要,与人工撰写摘要的方式相似.最新研究表明,由于输入文档与参考摘要之间不存在显式对齐关系[2,3],导致出现以下问题:
(1)使用传统带注意力机制的序列到序列模型生成摘要时,存在重复注意的缺陷,进而出现重复生成相同单词的问题;
(2)对齐问题导致文档编码信息包含噪声,进而出现生成的摘要存在语义不相关以及准确性低等问题.
针对上述问题,部分研究人员通过过滤编码器的输出得到更好的文档编码信息.ZHOU等[2]提出了选择编码机制(Selective Encoding Mechanism, SEM),并将神经生成式摘要(Neural Abstractive Summarization)任务拆分为3个步骤:编码、选择与过滤、解码.LIN等[3]提出了全局编码机制(Global Encoding Mechanism, GEM),GEM根据文档上下文全局信息来过滤从编码器到解码器的信息流,并对文档上下文的表示进行细化,以提高单词表示与全局上下文之间的联系.
受文献[2]、文献[3]的启发,本文提出一种新的摘要模型更好地解决了上述问题,主要贡献如下:
(1)提出混合过滤编码网络(Hybrid Filter Encoding Network, HFEN),并在HFEN中集成混合过滤编码机制(Hybrid Filter Encoding Mechanism, HFEM)、注意力机制、指针生成器;
(2)提出两种混合过滤编码机制的混合方式:管道过滤编码机制(Pipeline Filter Encoding Mechanism, PFEM)和特征融合过滤编码机制(Feature Fusion Filter Encoding Mechanism, FFFEM);
(3)在FFFEM中添加特征融合层(Feature Fusion Layer),并使用两种特征融合方式:级联融合(Concatenation Fusion)、门控融合(Gated Fusion);
(4)在中文摘要数据集LCSTS测试集上的实验结果表明,HFEN相较于基线模型生成了更为准确、重复单词更少的摘要,ROUGE指标有较大提升.
1 相关工作
1.1 神经生成式摘要
大量研究人员关注将Seq2Seq模型应用于文摘任务的问题.RUSH[4]首次实现神经生成式摘要,同时集成了注意力机制[5].在此基础上,NALLAPATI[6]拓展了基于RNN的神经生成式摘要.
为解决集外词(Out of Vocabulary, OOV)问题,VINYALS[7]、GU[8]分别提出指针网络(Pointer Network)、CopyNet.针对对齐偏差产生的重复生成问题,ZHOU、LIN分别提出选择编码机制SEM、全局编码机制GEM[2-3].部分研究人员通过其他方式缓解重复生成问题,TU[9]引入覆盖度机制(Coverage Mechanism),该机制回顾当前时刻前的注意力机制从而避免重复注意相同的位置.SEE[10]集成文献[6,8,9]提出带覆盖度机制的指针生成器网络(Pointer Generator Network with Coverage Mechanism).本文提出的HFEN集成的指针生成器与之类似,区别在于HFEN没有引入覆盖度机制.
1.2 神经中文生成式摘要
部分国内研究人员同样关注神经中文生成式摘要的发展.HU[11]首次构建了大型中文摘要数据集LCSTS,并给出了部分基准模型的实验结果.
侯丽微等提出一种主题关键词信息融合的中文生成式自动摘要模型[12]. 吴仁守提出一种全局自匹配机制(Global Self-Matching Mechanism)的中文摘要生成方法GSM[13].
2 本文模型:HFEN
2.1 总体架构
如图1,HFEN总体架构包含5个模块:文档编码器(Document Encoder)、混合过滤编码机制(HFEM)、注意力机制(Attention Mechanism)、解码器(Decoder)、指针生成器(Pointer Generator).指针生成器的作用是让生成的单词选择性来源于输入文档或词汇表,一定程度上解决了集外词问题和重复生成相同单词的问题.
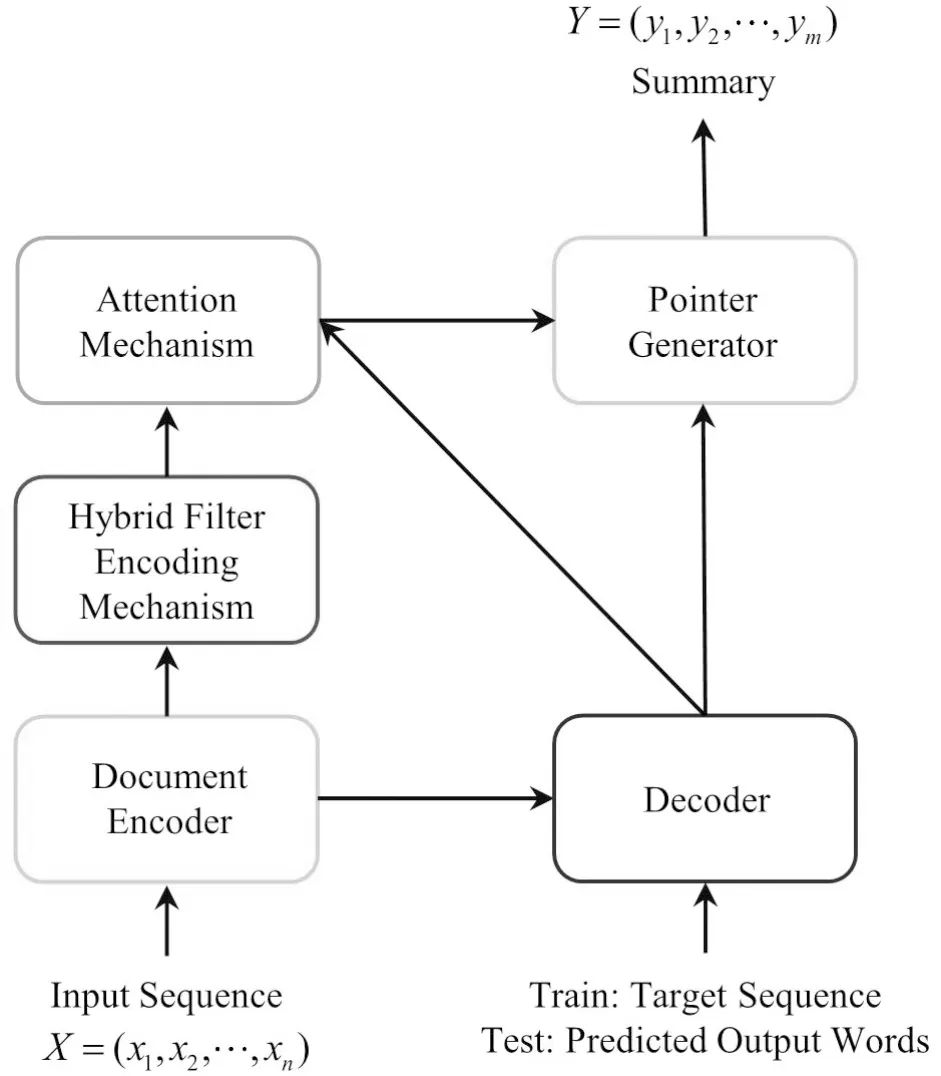
图1 HFEN总体架构Fig.1 The overall structure of HFEN
HFEN获取摘要时遵循如下步骤:
(1)使用文档编码器获取输入序列(输入文档)在每一时刻的隐藏状态(Hidden State);
(2)混合过滤编码机制HFEM对编码得到的隐藏状态进行过滤,并将过滤后得到的文档编码信息传递到注意力机制;
(3)解码器在每一时刻通过注意力机制计算词汇表概率分布Pvocab;
(4)指针生成器结合词汇表概率分布Pvocab与注意力分布计算最终的词汇表概率分布Pfinal,并获取该时刻生成的单词.
2.2 文档编码器
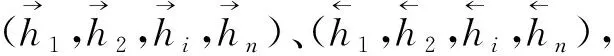
(1)
其中,t表示时刻,h为隐藏状态,c为细胞状态(Cell State).
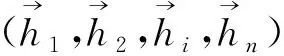
(2)
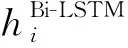
2.3 混合过滤编码机制
2.3.1 管道过滤编码机制(PFEM)
如图2所示,PFEM通过两阶段过滤的方式对SEM、GEM进行混合,编码器输出的文档编码信息hBi-LSTM先通过第一阶段SEM过滤获得文档二级编码信息hSEM,再通过第二阶段GEM过滤获得文档三级编码信息hPFEM将其传递到注意力机制模块.
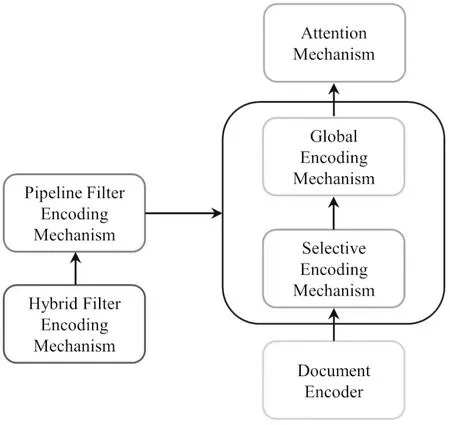
图2 PFEM架构Fig.2 Pipeline filter encoding mechanism architecture
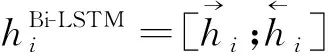
(3)
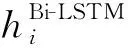
(4)
其中,Wh与Ws为可学习的参数,σ为Sigmoid激活函数.
文档二级编码信息hSEM计算公式如下:
(5)
其中⊙表示矩阵元素依次相乘.
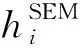
(6)
其中,Wconv和b为可学习的参数,ReLU为非线性激活函数.
在卷积块生成的新表示矩阵的基础上,继续对这些新表示矩阵实现自注意力机制(Self-Attention Mechanism)用于挖掘全局相关性,公式如下:
(7)
其中,Q和V表示卷积块生成的新表示矩阵,K=WattV,Watt为可学习的参数.
文档三级编码信息hPFEM计算公式为:
(8)
(9)
文档三级编码信息hPFEM为PFEM过滤得到的文档编码信息,该向量序列将会通过注意力机制模块计算上下文向量(Context Vector).
2.3.2 特征融合过滤编码机制(FFFEM)
如图3所示,FFFEM通过特征融合的方式对SEM、GEM进行混合,编码器输出的文档编码信息hBi-LSTM同时通过SEM、GEM进行过滤获得SEM文档二级编码信息hSEM、GEM文档二级编码信息hGEM,然后hSEM和hGEM通过特征融合层后得到文档三级编码信息hFFFEM并将其传递到注意力机制.
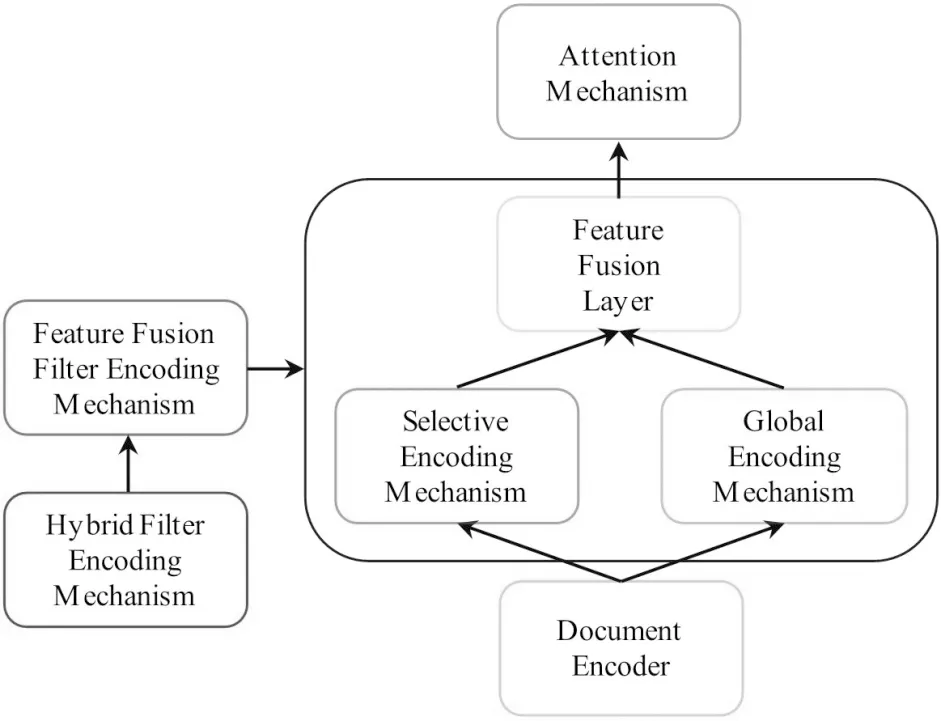
图3 FFFEM架构Fig.3 Feature fusion filter encoding mechanism architecture
SEM文档二级编码信息hSEM为:
hSEM=SEM(hBi-LSTM).
(10)
GEM文档二级编码信息hGEM为:
hGEM=GEM(hBi-LSTM).
(11)
本文在FFFEM中添加特征融合层,并使用两种特征融合方式:级联融合、门控融合.
级联融合简单地将hSEM、hGEM两个向量序列连接起来:
(12)
门控融合首先使用hSEM、hGEM两个向量序列计算融合门向量GFFFEM,然后通过门组合hSEM、hGEM两个向量序列:
(13)
(14)
文档三级编码信息hFFFEM为FFFEM过滤得到的文档编码信息,与hPFEM相同,该向量序列将会通过注意力机制模块计算上下文向量.
2.4 指针解码器
本文使用指针解码器(Pointer Decoder)作为摘要生成器,由图1中注意力机制、解码器、指针生成器组成.图4为指针解码器的结构图.
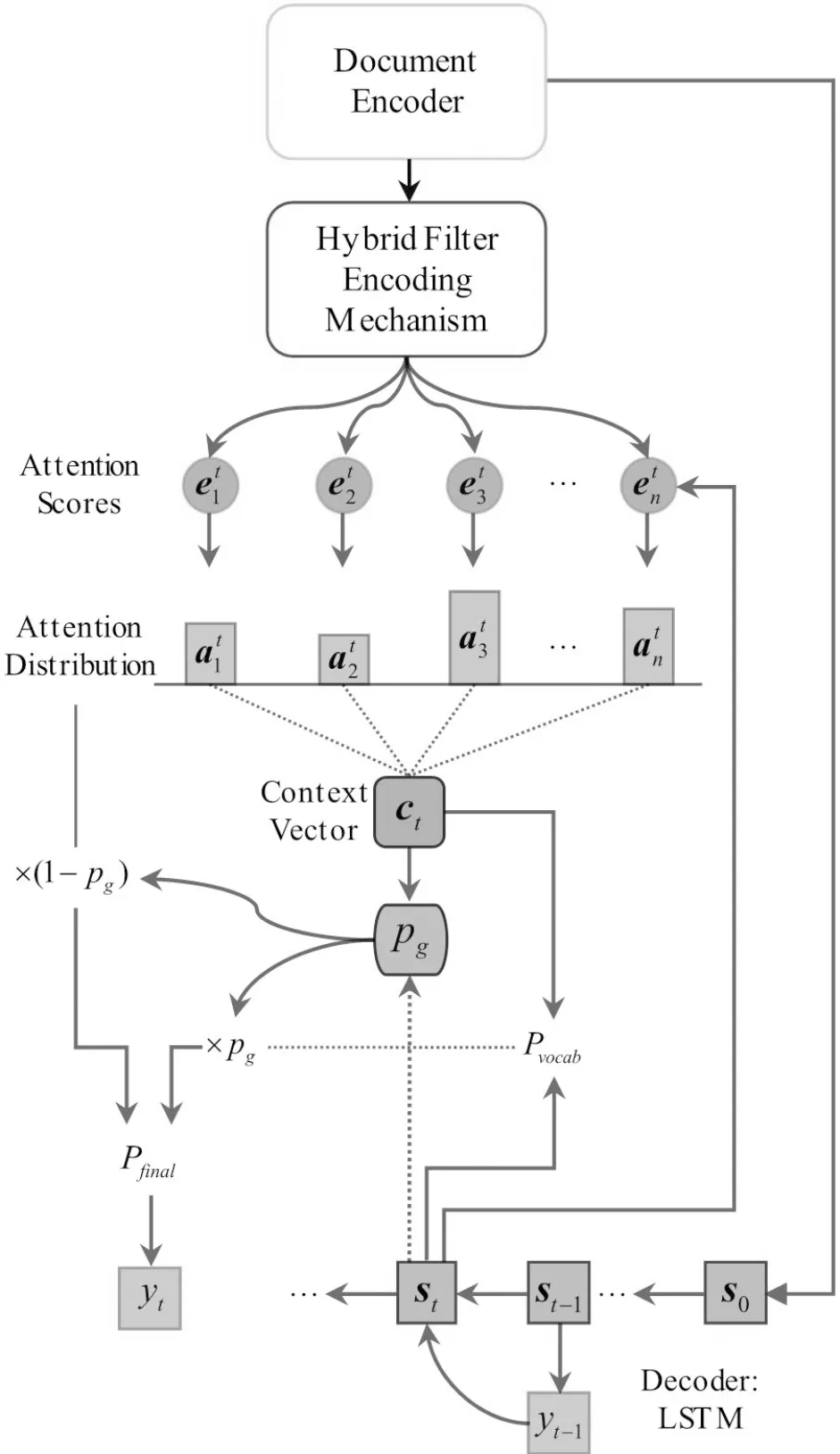
图4 指针解码器Fig.4 Pointer decoder
在解码时间步t,LSTM单元接收前一时刻预测输出的单词yt-1、前一时刻解码器状态st-1,得到t时刻解码器状态st.当t=0时,初始化解码器状态为:
(15)
其中,tanh为非线性激活函数,Winit为可学习的参数.
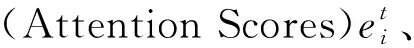
(16)
at=softmax(et).
(17)
(18)
经过注意力机制计算得到的词汇表概率分布Pvocab公式为:
Pvocab=softmax(Vlinear2(Vlinear1[st;ct]+blinear1)+blinear2),
(19)
其中,Vlinear1、Vlinear2、blinear1、blinear2为可学习的参数.
指针生成器定义选择开关pg控制生成的单词来源,pg由st、yt-1、ct共同决定:
(20)
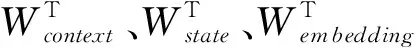
最终的词汇表概率分布为:
(21)
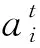
2.5 训练与推理
HFEN训练期间,给定输入序列与目标序列,使用导师驱动(Teacher Forcing)过程,通过最小化损失函数训练模型:
(22)
其中,θ*为HFEN各个模块的参数.
HFEN测试期间,解码器在t=0时刻接收起始符“
3 实验设置
3.1 数据集
LCSTS[11]源文档收集自中国著名社交媒体网站新浪微博,参考摘要来自人工撰写.本文遵循文献[3]、文献[11]、文献[13]的数据预处理过程,对LCSTS原始数据集进行拆分后得到训练数据2400591对、验证数据8685对、测试数据725对.
3.2 模型基本架构与组件
本文使用深度学习框架PyTorch实现3种新的摘要模型,各个模型基本架构及组件(CF、GF分别表示使用级联融合、门控融合)如表1所示.

表1 各个模型基本架构及组件表Tab.1 Basic architecture and components table of each model
3.3 HFEN参数设置
本文遵循文献[3]、文献[11]、文献[13]在LCSTS上进行实验时的参数设置,如表2所示.

表2 HFEN参数表Tab.2 HFEN parameters table
本文使用Adam优化器对HFEN的参数进行更新,Adam相关参数设定为:β1=0.9,β2=0.999,eps=1×10-8.所有训练文档按字分割.表1中3种HFEN均在GeForce GTX TITAN×12GB显存GPU上训练及测试.
4 结果分析
4.1 评价指标
ROUGE[14]是文本摘要领域的基准评价指标,通过计算待测摘要与参考摘要的单词重叠程度来判断模型生成摘要的质量,其中,ROUGE-N(包括ROUGE-1、ROUGE-2),ROUGE-L为重要指标.本文遵循文献[3]、文献[11]、文献[13]在测评时的设置,将生成的待测摘要按字级别进行切分.
4.2 主要结果
本文使用files2rouge包测评所有基线模型与HFEN生成的待测摘要在95%置信区间的ROUGE标准F1评分.表3为在LCSTS测试集上的主要结果.

表3 各个模型在LCSTS测试集上的ROUGE F1评分Tab.3 The ROUGE F1 score of each model on the LCSTS test set
结果显示,HFEN相较于其他基线模型均有较大的优势,其中,HFEN-FFFEM-GF达到了最佳的摘要性能,相较于GSM在ROUGE指标上分别提升1.0、0.7、0.4,相较于GEM(our implement)在ROUGE指标上分别提升1.9、2.6、2.0,证明了HFEN能够生成更准确、更能反映测试文档中心思想的摘要.
4.3 摘要重复率分析
本文对待测摘要的重复率进行分析以验证HFEN生成的摘要中包含更少的重复单词.为测评摘要重复率,定义如下评价指标:
(2)摘要层面重复率:
rep_summ_ratio=
其中,rep_wordsi为摘要summi中包含的重复单词集合.表4为重复率测试结果.

表4 重复率测试结果Tab.4 Repeat rate test results
结果显示,参考摘要在两个重复率指标上最低,因为人类在撰写摘要时会刻意避免使用相同的单词以便在摘要长度限制的情况下囊括更多的信息.HFEN在总体上相较于GEM重复率更低,其中,HFEN-FFFEM-GF生成的摘要重复率最低且与参考摘要的重复率最为接近,证明了引入FFFEM对降低重复率是有效的.
5 结束语
本文提出了一种混合过滤编码网络(HFEN),通过在HFEN中集成混合过滤编码机制(HFEM)解决了对齐关系导致的重复生成相同单词的问题以及生成的摘要与输入文档语义不相关、准确性低的问题,实验结果证明了所提HFEN的有效性.
猜你喜欢
客联(2022年3期)2022-05-31
小学生必读(低年级版)(2021年10期)2022-01-18
中国新闻周刊(2021年26期)2021-07-27
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
软件学报(2020年6期)2020-09-23
家庭影院技术(2019年8期)2019-12-04
广东第二课堂·小学(2017年9期)2017-09-28
电脑爱好者(2017年7期)2017-05-06
