
感知特征增强学习的低分辨率人脸识别
2021-06-25 02:08熊承义邵奔高志荣柳霜李雪静
中南民族大学学报(自然科学版) 2021年3期
熊承义,邵奔,高志荣,柳霜,李雪静
(1 中南民族大学 电子信息工程学院&智能无线通信湖北省重点实验室,武汉430074;2 中南民族大学 计算机科学学院,武汉 430074)
人脸识别是一种对人脸图像身份信息进行识别的生物识别技术.近年来,随着深度学习技术的蓬勃发展,基于深度神经网络的人脸识别算法性能得到了显著提升,例如ArcFace[1]、MobileFaceNets[2]、SphereFace[3]等.其中最先进的人脸识别算法在开源人脸数据集LFW上的识别精度已经超过99%[4]. 然而,随着监控系统的普及,摄像头在实际监控环境中,受拍摄距离、角度、光照等因素的影响,采集到的图像往往都是低质量的人脸图像. 其中最常见的问题是由于距离影响,使得获取到的人脸图像尺寸较小,图像分辨率较低.研究表明,当人脸图像的分辨率小于32×24像素时,由于低分辨率人脸图像包含较少的面部信息,在主流的人脸识别模型上识别性能显著下降[5].因此,低分辨率(low-resolution,LR)人脸识别成为当前人脸识别领域关注的热点和难点问题.
目前的LR人脸识别方法主要分为两类:一种是基于公共特征子空间的方法,首先将高、低分辨率图像特征非线性映射到一个公共特征子空间,然后最小化相同身份图像特征在子空间中的距离后进行分类识别;第二种是称为基于图像超分辨率的方法,首先利用超分辨率技术对LR图像进行超分辨率重建,然后对获得的高分辨率(high-resolution, HR)人脸图像进行分类识别.基于子空间的方法主要存在对噪声扰动敏感,提取的面部特征鲁棒性较低等问题.基于图像超分辨率的方法因为可以有效缓解噪声扰动对人脸图像识别分类的影响,因此在近年得到了极大关注.比如,基于传统方法,HENNINGS等人[6]提出了SSRR(simultaneous super resolution and recognition)方法,将人脸超分辨率与人脸识别结合,显著提升了人脸识别性能;基于深度学习框架,YANG等人[7]提出了超分辨率与识别联合互补的端到端人脸识别深度网络,进一步增强了无约束低分辨率人脸识别性能.
受上述工作的启发,本文提出一种感知特征增强学习的低分辨率人脸识别网络结构.具体地,首先训练一个HR人脸识别辅助网络,用于初始化LR识别网络并对后续的学习过程进行监督;接下来通过HR通道对LR通道特征提取网络进行多级特征约束,以提高LR、HR图像特征在空间的相似程度,使得相同身份的特征距离更加紧凑;此外还反向利用识别网络监督超分辨率重构过程,以更好的得到身份信息保留的人脸图像.通过超分辨率和识别网络交替优化,从而实现对LR人脸识别性能的渐进提升.大量实验结果表明,提出的方法具有一定的可行性和有效性.
1 相关工作
基于超分辨率的方法十分有益于LR人脸识别任务,该方法包含两个过程:一是对LR人脸的超分辨率重建,二是对重建的HR人脸进行识别。假设输入LR图像为Il,HR标签图像为Ih,则人脸超分辨率重构优化过程可表示为:
(1)
其中,f为距离度量函数;R为人脸超分辨率模型;D为HR图像和超分辨率图像在特征空间中的距离,通过最小化距离D,获得最终人脸超分辨率模型.
完成上述重构过程后,得到重构出的超分辨率人脸图像. 接下来对超分辨率人脸图像进行识别,该识别过程与传统HR识别方法一致.识别过程通常使用Softmax函数及其变型形式将输出特征向量进行概率归一化,然后与标签向量做交叉熵损失,最小化交叉熵损失实现特征的识别.其中Softmax函数的使用可表示为:
L=Softmax(x).
(2)
为了探索基于超分辨率的方法如何提高LR人脸识别效果,各种算法相继被提出.例如,LI等人[8]提出特征幻化概念,该方法通过局部视觉基元特征表示法,将提取到的人脸特征进行类似超分辨率的处理后进行匹配识别.ZOU等人[9]设计了一个包含两个约束的线性回归模型来学习映射.SHUN等人[10]提出基于身份保留的人脸幻化的LR人脸识别方法.在基本的超分辨率方法基础上,提出一个全新的身份保留损失函数,结合图像像素损失联合训练超分辨率网络,确保恢复的图像保留身份识别信息.Jin等人[11]为了保证超分辨率网络有效地学习到对身份信息鲁棒的识别特征,提出将身份特征分解为两个正交分量,分别从两个方面来恢复LR图像的身份识别信息,确保了恢复的图像能够保留有效且鲁棒的身份信息.
2 提出的方法
如图1所示,本文提出的感知特征增强学习的低分辨率人脸识别网络,包含两个网络通道:高分辨率人脸识别通道、低分辨率人脸识别通道. 其中HR通道包含一个图像特征提取网络,负责提取HR人脸图像特征,用于辅助LR通道的特征学习.LR通道由一个超分辨率网络和一个图像特征提取网络组成. 首先由超分辨率网络重构恢复LR图像细节信息,接着提取超分辨率图像的特征进行人脸识别.

图1 网络整体结构框图Fig.1 Overall structure of the proposed network
其中IHR、ILR、ISR分别表示输入的HR、LR人脸图像以及超分辨率重构后的图像;vHR、vLR、vtarget分别为HR、LR特征提取网络的输出特征向量与身份标签向量.
2.1 人脸超分辨率
人脸图像超分辨率旨在恢复人脸图像缺失的细节信息,增强图像的感知特征. 为恢复LR人脸图像的细节信息,本文实验使用MSRN[12]网络作为人脸超分辨率模块.如图2所示,该网络通过多个多尺度残差块进行特征提取,最后将多个残差块的输出特征进行特征融合. 局部多尺度特征与全局特征相结合,为图像重构提供更丰富的特征信息,最终恢复出细节丰富的高分辨率人脸图像.

图2 超分辨率网络结构图Fig.2 Super-resolution network structure diagram
与传统超分辨率方法不同,本文为保证重构后的图像保留可识别的身份信息,结合使用像素损失与识别网络监督其整个恢复过程. 超分辨率过程可描述如式(3):
ISR=fSR(WSR;ILR),
(3)
其中ISR表示超分辨率后的人脸图像,fSR表示超分辨率网络模型,WSR为网络模型参数,ILR为输入LR图像.
2.2 特征提取网络
网络训练过程中,两个通道各自包含一个特征提取网络,且网络结构相同,实验中使用MobileFaceNets[2]完成特征提取任务.两个通道特征提取网络的结构如图3所示. 其中每个网络层上方参数为特征图通道数、下方为每层输出特征图尺寸大小. HR通道可提取到HR人脸图像在特征空间中的分布,该分布具有类内紧凑、类间分散的特点. 基于这一特点,为完成LR人脸识别任务,应引导其特征分布与HR特征分布趋于一致. 要实现HR通道引导LR通道学习,预先将HR特征提取网络训练并固定其参数不变. 由于两个通道特征提取网络结构相同,为了更充分的利用HR特征,在两个通道特征提取网络中间层设置多个特征损失函数. 特征损失通过在不同中间层特征空间最小化HR、LR特征距离,使得LR特征与HR特征趋近,最终实现LR人脸识别性能的提高. 考虑到特征图降维过程中特征变化明显,本文将特征图尺寸大小发生变化的卷积层作为特征损失接入节点(最后一个特征损失函数除外),约束该层降维后的特征分布. 由于不同网络存在多个符合条件节点层,多次实验验证特征损失函数在网络中接近均匀分布时效果最佳,最优的损失函数数量也与具体网络结构相关(图3中网络实验得出最优损失函数数量为3).

图3 双通道特征提取网络结构图Fig.3 Double channel feature extraction network structure diagram
HR和LR通道特征提取过程可表示如下式(4):
(4)

2.3 网络训练与损失函数
网络的训练过程包含3个阶段:首先在高分辨率图像数据集上训练HR通道,并用HR通道特征提取网络参数初始化LR通道特征提取网络. 后续训练过程中保持HR通道参数不变;接着,固定HR、LR通道特征提取部分参数,质量损失与身份损失联合约束超分辨率网络训练;最后,在HR通道的特征约束下,交替微调超分辨率网络与LR特征提取网络,提高整体LR通道的低分辨率人脸识别性能.
本文一共使用3种损失函数:特征损失、像素损失、识别损失.引入特征损失的目的在于最小化特征空间中HR特征与LR特征的距离. 余弦距离在分类任务中广泛使用且效果优异,使用余弦损失函数作为特征损失函数,可有效地提高网络识别性能,具体表示为:
(5)

像素损失旨在恢复图像细节信息与提高视觉效果.LI损失函数简单且可有效恢复图像,该函数定义为:
(6)
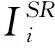
识别损失使用Softmax函数的改进形式ArcFace Loss[1]损失函数.在余弦空间对特征进行多次特征约束的基础上,ArcFace Loss通过增加角度余量进一步提高分类性能. ArcFace Loss具体表示如式(7):
(7)
θj表示权重向量与输出特征之间的夹角,θyi为标签向量与输出特征夹角,m为加性角度余量,s代表超球面特征空间半径.
损失函数使用:每一阶段训练损失由上述三项损失函数组成,其中,当训练超分辨率网络时使用的损失函数如式(8):
(8)
其中βi代表每个特征损失函数的权重(实验中βi设置为0.2、0.3、0.5),所有权重相加和为1,n为特征损失函数数量,该值由具体实验使用网络结构确定.当训练LR特征提取网络时,使用的损失函数可表示为:
(9)
3 实验
3.1 实验设置和数据处理
硬件条件包含Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz x 48,内存128GB,NVIDIA GeForce GTX 1080 Ti,单卡显存11GB.基于Ubuntu 16.04 LTS系统,PyTorch 1.0.2深度学习框架.
训练集采用CASIA WebFace Dataset人脸数据集,包含10575个身份的494414张人脸图像.测试集为LFW人脸数据集,包含13000张人脸图像.训练集与测试集相互独立,不包含相同身份人脸图像. 训练集样本如图4所示,在实验中,原始图像为112×96分辨率图像,将图像分别下采样到28×24、14×12、7×6分辨率用于训练和测试.

图4 训练集样本示例Fig.4 Sample training set
3.2 实验结果
为验证所提方法的有效性,本文在MSRN[12]、EDSR[13]两种超分辨率算法和SphereFace[3]、MobileFaceNets[2]两种人脸识别算法上进行验证实验.实验中,本文方法预先训练一个HR特征提取网络,且在LR网络最后一层使用一个特征损失函数LD.表1给出了4种不同超分辨率网络与人脸识别网络的组合的实验结果.根据表1结果可见,本文方法在仅仅使用一个特征损失函数时,在各分辨率条件下效果都有所提高,证明HR特征约束策略的有效性.相比之下,MSRN和MobileFaceNets的组合虽然识别率不是最佳,相对于其他几组效果略差,但是其网络参数最小,且训练过程更加高效和简单.考虑到时间和成本,在本文接下来讨论中,选用该组合完成后续实验.
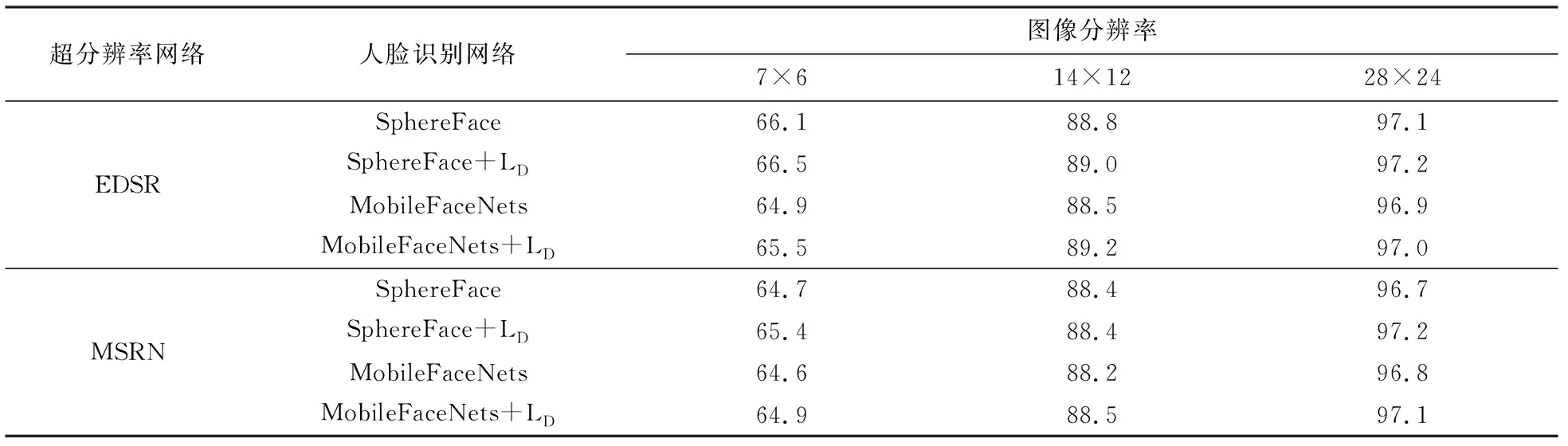
表1 HR特征约束在不同网络上的有效性验证Tab.1 Validation of HR feature constraints on different networks
为了比较特征提取网络使用特征损失函数数量对LR人脸识别性能的影响,本文在不同分辨率情况下,对特征损失函数的个数与识别率之间的关系做了一系列实验.实验结果如图5所示,其中n为实验中使用的特征损失函数个数. 从图中可以看出当n=1时效果最差,当n增加至3过程中,图像分辨率越低,识别效果提高更明显;当n大于3后,效果开始趋于下降.

图5 特征损失函数数量对识别性能的影响Fig.5 The influence of the number of feature loss functions on the recognition performance
分析图5实验数据,适当数量的特征损失约束可以提高LR识别网络的识别率,且分辨率越低效果提升越明显;当特征损失函数数目超过最佳点时,身份约束过强,使得类边缘的样本不能正确识别,导致识别率降低,具体如图6示意图所示.特征损失数量和选择的网络、训练数据等都有一定的关系,本文选择n=3作为最佳特征损失函数的数量.

图6 余弦空间同一身份人脸特征分布示意图Fig.6 Cosine space features of the same identity face distribution diagram
本文方法在不同分辨率下与LightCNN[14]、ResNet[15]、VGGFace[16]、SphereFace等算法进行对比.对比方法为复现论文代码得到结果,参数设置与原论文一致,训练集与测试集均与本文相同.为适应对比实验网络的输入尺寸,将测试集通过双三次插值将图像变换到112×96大小.从表2中可知,不同分辨率下,本文算法与对比实验中最优的ResNet相比识别率分别提高8.1%、1.5%、0.2%,特别是在分辨率为7×6时,本文算法的识别效果提升更加明显.

表2 不同算法在LFW数据集上识别率的比较Tab.2 Comparison of recognition rate between different algorithms on LFW dataset/%
4 结语
针对低分辨率人脸特征信息丢失严重,导致识别性能急剧下降的问题,提出了一种高分辨率图像辅助感知特征增强学习的低分辨率人脸识别方法.利用深度神经网络分别提取高分辨率人脸与低分辨率人脸的多层特征,并将特征损失用于监督低分辨率人脸识别网络的训练优化,更好地恢复了超分辨率人脸的身份信息,有效提高了低分辨率网络的特征表示能力.实验结果验证了本文算法对改进低分辨率人脸识别性能的有效性.
猜你喜欢
红外技术(2022年11期)2022-11-25
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机应用(2020年7期)2020-08-06
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
艺术科技(2018年2期)2018-07-23
