
基于分布式数据库的大数据平台动态页面数据生成技术
2021-06-24 07:24:50苏莉娜
微型电脑应用 2021年6期
苏莉娜
(江苏省第二中医院, 江苏 南京 210019)
0 引言
随着网络技术和计算机科学的发展,我国的计算机网络用户数量不断攀升,根据2019年《中国互联网络发展状况统计报告》显示,截止到2019年底,我国互联网用户数量达到了9.87亿,比2018年同期增长约9.4%[1-3]。互联网用户数量增长的背后是网络数据爆发式增长,如何使网络用户在海量数据中集中筛选有用信息,节省时间提高上网查询效率是一个突出问题,其次,现有的数据结构由传统的嵌入式HTML 网页静态数据变成了以语音、视频等为载体的动态数据,相比于静态数据,其筛选难度更大[4-5]。因此,本文结合动态页面特点,建立了动态页面脚本提取系统,在分布式数据提取基础上对动态页面的脚本信息进行提取,最后对系统的功能进行了测试分析。
1 分布式数据处理
MapReduce是一种建立在分布式数据存储基础上的数据云计算方法[6-7],它是将分布式数据库中的大量数据进行分解,将数据库逐渐分解成需要的目标节点,之后从整合的目标节点中寻找需要的数据并将数据汇总。MapReduce数据处理流程如图1所示。

图1 MapReduce数据处理流程
由图1可知,首先在数据输入端将分布式数据库中的数据分解为几个splite集合,之后根据map函数对splite集合中的数据进行匹配计算,匹配后的数据经过middle result数据整合后以函数形式输出结果,最后数据经过函数反解,以规定的表现形式输出结果。
数据处理的前提是数据的安全性问题,为此本文专门开发了符合数据库特点的数据安全访问流程,如图2所示。
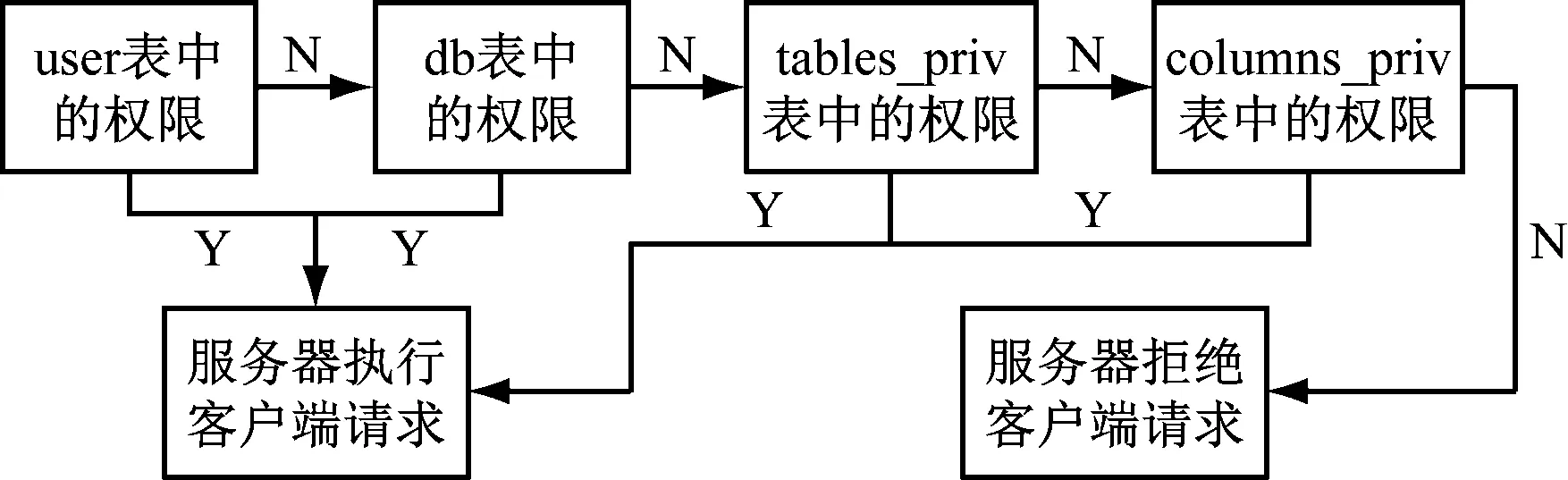
图2 数据访问流程
由图2可知,用户依次进行user权限、db权限、tables-prive权限、columns-prive权限认证,根据安全等级的不同,采取不同层级的认证访问权限。
2 脚本提取子系统
为了对动态页面实现信息采集,需要在动态页面和系统数据库间增设脚本提取系统,以处理提取数据的临时存储和数据筛选交换。
脚本解析系统的工作流程如图3所示。

图3 脚本解析流程
由图3可知,首先在HTML网页文件中构建DOM树,根据JavaScript中目标信息与DOM树的关系,采取二元化的信息处理方式,解析环境初始化后提取HTML网页文件中的脚本信息,脚本提取完成后运行脚本,若脚本是一个open()类函数,则保存URL,否则重构DOM树,重复上述流程。脚本解析的难点是DOM 解析,它的原理是将对象按照模型树的方式,在HTML网页文件中将网页信息用结构化的方式展现。
根据目前计算机软硬件的发展特点,需要采用有针对性的数据调动方式和程序以克服不同软件条件下作业命令和数据格式不兼容的弊端[8-9]。本文开发了适用于动态信息提取和MySQL数据库特点的MapReduce 调度算法。算法架构如图4所示。
由图4可知,作业池是将所有的工作任务按照任务间的逻辑关系进行分类,在同一个工作任务下可按照时间顺序、优先顺序等进行任务细化分解。实时资源列表是为了提高调度效率设置的具有列表黑名单功能的信息筛选功能,它是根据作业池向资源池发送的Task Scheduling信息,采用两次发送两次接收的模式,若资源池只收到一次Task Scheduling请求,则表明该节点是非法的,将其列入黑名单。
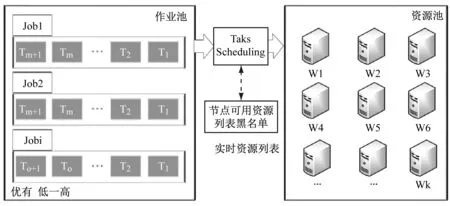
图4 算法架构
按照以上算法架构,建立了调度算法流程,如图5所示。
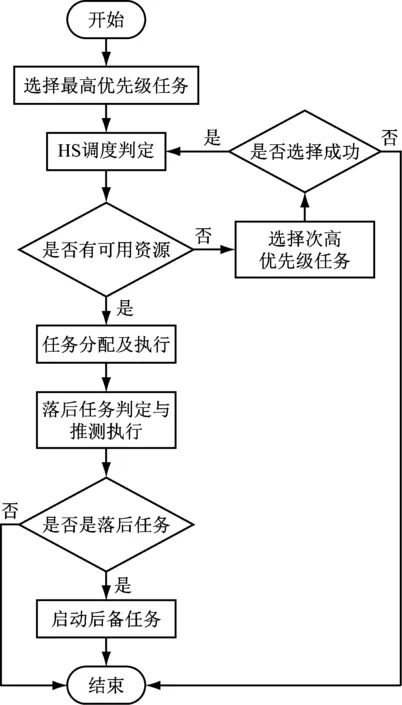
图5 调度算法流程
由图5可知,算法的第一步是选择最优任务,算法按照预定的规则将作业池中的任务进行优先级别排序,同时根据任务特点从资源池匹配与之对应的节点。HS调度判定是作业任务和资源节点间的匹配调度过程,若资源池中节点无法匹配任务,则HS调度判定命令会选择下一个紧邻的任务进行资源池中节点的匹配。落后任务判定与推测执行是对于级别有所调整的执行任务进行优先级别的调整,并利用资源池节点进行匹配。
脚本提取系统数据文件存储结构,如图6所示。
由图6可知,crawldb是系统连接的爬行数据库,是对网页的数据采集记录进行跟踪;jscrawldb数据库包含两个子系统,是对页面中JavaScript文件进行存储;Segments数据库是对每一个完成访问的页面进行信息存储,将每一个页面存储生成一个单独的文件;Linkdb是一种网页链接数据库是对所有访问的网页地址进行存储。
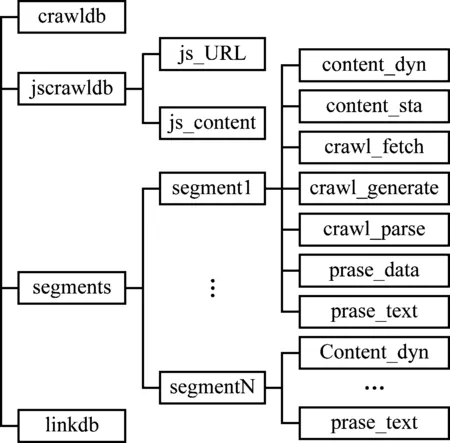
图6 数据存储结构
根据以上脚本提取方式,建立了动态页面信息采集系统架构,如图7所示。

图7 动态页面信息采集系统架构
由图7可知,首先系统根据筛选种子从系统白名单中对数据进行抓取,对于抓取的网页,利用脚本提取系统对网页脚本进行提取,按照页面脚本信息对页面数据进行解析处理并筛选,最后根据筛选结果对筛选数据进行翻转,以数据及网页信息的形式将筛选结果进行保存。
3 系统测试分析
动态页面数据生成系统是针对音视频等动态数据进行提取的以对象为目标的信息捕捉系统,根据系统数据处理流程和脚本提取方式对系统的性能进行了测试分析,测试中选择某市科技局网站为对象,对网站中的动态信息进行采集,并与其他采集方式对比。
3.1 测试环境
系统集成模拟系统由4台并联的计算机组成。系统测试软硬件的组成如表1所示。

表1 测试软硬件
3.2 测试结果
系统完成测试后对科技局网站进行了静态数据提取,提取结果如图8所示。
由图8可知,相比较于动态网页数据,静态数据提取技术能有效提取页面的有效信息。
本文以对比的方式分析了系统在脚本加入前后系统抽取有效信息数量和提取效率,测试结果如表2所示。
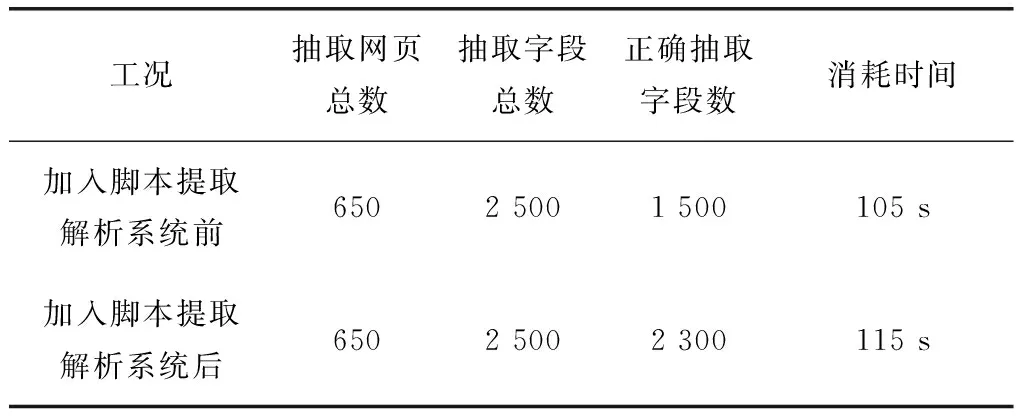
表2 数据提取效果
由表2可知,在抽取网页总数和字段总数相同的前提下,加入脚本提取解析系统后其提取的准确率上升了32%,而系统消耗的时间与原来相比只增加9.5%,因此该脚本提取解析系统达到了预定功能需求。
4 总结
随着动态网页信息的丰富,网页中的数据类型也有所丰富,用户的上网体验效果更佳,与此同时,动态网页中的信息采集难度也随之增加。本文以从分布式数据库为基础,开发了适用于动态网页的脚本解析系统和数据调度方式,在分析了分布式数据库类型基础上对动态页面信息采集系统进行了架构分析,最后对系统的应用效果进行了测试,结果表明加入脚本提取解析系统后其提取的准确率上升了32%,而系统消耗的时间与原来相比只增加9.5%。
猜你喜欢
大灰狼画报·益智版(2024年3期)2024-12-09 00:00:00
作文小学中年级(2022年11期)2022-11-25 09:52:08
保健医苑(2022年1期)2022-08-30 08:39:14
课堂内外(小学版)(2020年11期)2020-12-04 06:38:44
电子测试(2018年14期)2018-09-26 06:04:24
电子制作(2018年10期)2018-08-04 03:24:38
中学生(2017年19期)2017-09-03 10:39:07
电子制作(2017年2期)2017-05-17 03:54:56
电子测试(2015年18期)2016-01-14 01:22:58
计算机与网络(2014年7期)2014-03-25 10:57:07
