
融合模糊评价与极限学习机的配电线路台风灾损预测
2021-06-17 00:38:34吴莉林珍江灏陈静庄胜斌
福州大学学报(自然科学版) 2021年3期
吴莉, 林珍, 江灏, 陈静, 庄胜斌
(福州大学电气工程与自动化学院, 福建 福州 350108)
0 引言
随着全球极端天气恶化加剧, 台风的规模和破坏力不断增大, 由台风及其引发的次生灾害对公共基础设施造成了严重影响[1]. 与用户生活紧密联系的电力基础设施一旦遭受台风重创, 将产生不可逆的损害[2]. 其中, 配电网架空线路因其覆盖范围广、 线路走廊环境复杂、 早期设计抗风等级低等问题成为了电力系统中的重灾区[3]. 在应对台风灾害方面, 对配电网本身进行深入分析和挖掘, 明确台风登陆的规律, 可以更加有效地支持灾害预测关键技术的研发, 从而最大限度地提高灾害应急处理能力和灾后重建工作的效率[4]. 因此, 实现智能化电力灾损评估技术对台风天气下配电线路灾损预测具有重要意义.
在台风天气影响下, 如何有效地对配电线路进行防灾、 减灾已成为国内外专家高度重视的问题[5]. 陈国建等[6]对有关输电塔线动力特征的力学模型作了研究, 为后续配电线路灾损的评估分析提供了技术基础[7]. 吴海彬等[8-9]基于塔线力学的特点, 模拟台风仿真环境, 综合考虑不同影响因素对灾损系数进行修正, 从而建立评估模型. 江思杰等[10]从台风灾损机理入手, 利用短期和短时双时间尺度台风的基本信息和杆塔地理位置[11], 以更详实的实验数据构建了台风影响下配电线路的损伤模型, 为灾损预测提供了一定的理论基础. 王永明等[12]提出一种台风灾害下考虑运行状态的配电网风险评估方法. 综合考虑台风登陆时风速特征与电杆运行状态, 建立了台风灾害条件下配电网电杆故障修正模型. 但是, 由于台风本身复杂的结构和形成条件, 搭建仿真环境需要耗费高额的成本, 影响台风灾损预测的研究进程. 随着人工智能的发展, 神经网络算法逐渐被应用在回归预测领域. 国内外专家考虑使用反向传播神经网络[13]、 广义神经网络[14]和支持向量机[15]等算法, 从机器学习角度对台风灾损进行快速预测. 王维军等[16]结合数学模型, 建立了一种基于重力搜索算法优化的极限学习机(IGSA-ELM), 通过预测台风对配电线路的损害, 不断提高预测精度. 在此基础上, 考虑破坏配电线路的多种因素, 对其进行关联分析, 从而增加预测结果的精度. 然而, 配电网台风灾损问题属于小样本问题, 可用的信息极为有限. 在考虑不同因素的影响时, 仅利用有限的台风固有属性对其灾损进行分析往往会造成较大的误差, 使风灾影响下配电线路灾损预测的准确性无法得到很好的保障, 最终导致灾后应急抢救工作存在一定困难.
因此, 本研究深入分析配电网台风灾损机理, 通过提取台风属性中的登陆点因素, 探究登陆位置对灾损的影响, 构造模糊评价函数, 并结合台风风级、 风速以及风圈半径, 作为预测模型的输入特征. 在此基础上, 利用我国东南沿海某地区的台风灾损样本配合历年台风的属性数据, 建立台风影响下的极限学习机灾损预测模型, 以实现对配电线路灾损的准确预测. 本算法在灾损预测上摒弃了较为盲目的关联分析过程, 有助于解决台风灾害过后应急抢修的恢复问题.
1 配电线路台风灾损分析
在台风灾害风险评估系统中, 风险的大小主要从台风的时空分布、 台风强度及易灾区经济水平等几个方面进行评估. 依据该原则, 选取台风风速、 台风风级、 台风登陆点和风圈半径作为模型训练的输入特征. 其中, 台风的空间特点决定了未来成灾的位置地点、 移动方向和范围等信息. 由此形成的台风路径通常是由多个路径点构成, 每个路径点又具有各自的属性, 成为了风险评估的关键内容. 在众多参数中, 确定台风登陆点需要根据气压、 风速与大气环流等多种相关数据进行综合分析, 其要素繁多且复杂. 为了科学和准确地对台风灾损进行预测, 将台风登陆点转换成与目标地区的直线距离. 考虑到台风登陆距离与目标地区的灾损影响并不是简单的线性关系, 而是需要结合地理地形等因素. 因此, 提出利用模糊评价方法对其影响程度进行衡量, 从模糊量的角度来评估台风登陆点对配电线路的灾损预测影响.
对电力系统而言, 台风的致灾能力主要体现在台风、 降雨以及雨水冲击导致的地质灾害三个方面. 配电网受损主要体现在配电设备的故障频发, 大范围的配电线路跳闸、 杆塔倒塌、 断线等, 对整个电网线路造成严重的破坏. 台风导致配电线路有不同程度的损伤, 线路跳闸是台风对配电线路损毁影响的主要表现之一. 杆塔主要以杆塔倾斜、 倒杆与断杆为主; 导线以断线为主, 即当承受的荷载超过其设计极限时会造成断股或断线的现象. 因此, 主要以跳闸、 断线、 倒杆和断杆作为灾损评估对象.
2 基于模糊评价的登陆距离关联度分析
1) 模糊集与模糊隶属度. 模糊是用来描述难以明确界限的客观事物的一种方法. 模糊集则包含了所有模糊对象的集合. 假设U是非空集合, 称为论域.在U中任意给定一个元素x, 则有属于模糊集合A存在.U上的模糊集合X是U到 [0, 1] 的一个映射,μA称为A的隶属函数,μA(x)叫做x对模糊集A的隶属度, 记为
A={(x,μA(x))|x∈X}
(1)
其中: 使隶属度为0.5的点x0称为模糊集A的过渡点, 此点最具有模糊性.
2) 台风灾损影响的隶属函数. 隶属度是模糊数学的基本思想. 应用模糊数学方法建立数学模型的关键是建立符合实际的隶属函数. 针对定义在数据集上, 同时具备特殊分级特点的台风登陆点信息, 采用模糊分布来确定台风登陆距离与受灾程度的模糊关系. 按照电力系统灾损的评价标准, 将配电线路损害的严重程度划分为4种: 轻微影响、 中度影响、 严重影响和极端影响. 同时根据文献查询和先验知识的积累, 制定了灾损影响程度所对应的登陆点与受灾地区的直线距离, 如表1所示.

表1 配电线路灾损影响等级
对此选用四个等级的梯形模糊隶属函数, 分别表述如下.
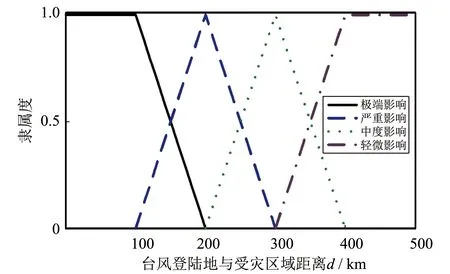
图1 配电线路灾损分级示意图Fig.1 Distribution line damage classification diagram
式中:μ1(l)、μ2(l)、μ3(l)、μ4(l)分别表示台风登录距离对配电线路极端、 严重、 中度以及轻度影响的隶属度函数,l为登陆点距离目标受灾地区的距离值;a,b,c,d,e分别对应该配电线路灾损指数所对应灾损的距离标准值: 100, 200, 300, 400, 500.相应的隶属度函数图像如图1所示.
由于设置隶属函数分级指标时采用不同区域的位置作为计算标准, 导致隶属度的大小无法直接进行比较. 因此, 为了有效地开展台风灾损的预测工作, 需要对不同影响等级的隶属度进行统一. 采用无量纲化公式将隶属度进一步归一化, 具体公式为

(3)
式中:μ(l)′代表归一化后的隶属度, 函数值越接近1说明该距离对配电线路破坏的影响越严重, 数值越小说明该距离对配电线路影响越微弱;lP、lL代表距离的上限和下限;li代表该配电线路灾损指数所对应灾损分级指标的标准值.
经过处理后的隶属度, 能够使用统一的参量来定量地表示各距离隶属于灾损样本的程度. 将模糊集理论引入模糊现象区域可使模糊问题清晰化, 能更深刻地反映出事物的属性. 同时, 也为下文极限学习机预测配电灾损的实验提供更加科学和有利的数据.
3 基于ELM的配电线路灾损预测原理
3.1 配电线路灾损预测模型
台风影响下配电线路灾害的预测一般是利用历史台风灾损数据进行模型训练, 进而预测未来灾损情况, 是典型的回归预测问题. 但由于台风的不确定性和复杂性, 以及配电线路相关的灾损数据量稀缺, 有限的台风属性特征难以挖掘其与灾损影响的关联性, 导致预测问题的精度不高. 针对以上问题, 结合模糊处理后的距离隶属度, 运用极限学习机算法对台风影响下的配电线路灾损进行预测. 选取历史重要台风期间引起的线路跳闸、 断线、 倒杆以及断杆作为模型训练的样本数据. 其中以台风风级、 风速、 登录距离模糊值和风圈半径作为模型输入特征, 以配电线路跳闸、 断线、 倒杆和断杆作为模型的输出特征, 构建台风影响下的配电线路灾损预测模型. 其原理图如图2所示.
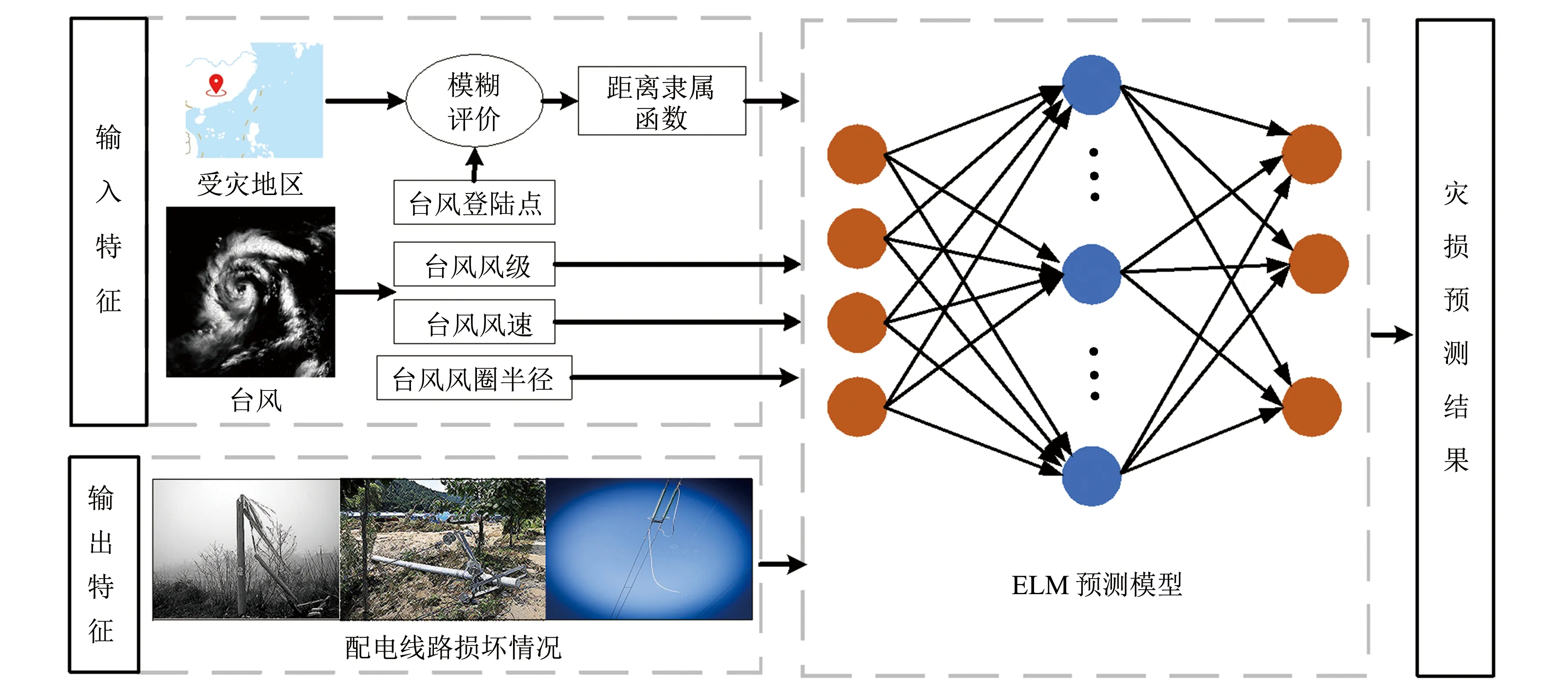
图2 配电线路灾损原理图Fig.2 Schematic diagram of distribution lines damage
3.2 ELM算法原理

图3 ELM原理图Fig.3 Principle diagram of the ELM
极限学习机(extreme learning machine, ELM)是一类基于前馈神经网络的机器学习算法[15], 其主要优势在于隐含层节点数可以任意设置或人为给定且不需要调整, 训练仅需计算输出权重. ELM具有学习速度快、 泛化能力强的优点, 被广泛应用于回归分类等问题中. 工作原理图如图3.
依据ELM算法的网络特征, 台风影响下的配电线路灾损预测模型可以表示为:
Model=ELM(w,b,β,g(x),L)
(4)
基于ELM算法进行灾损预测, 具体步骤如下:
步骤1参数初始化, 选取隐层节点数L, 激活函数g(x), 随机权重系数w, 误差阈值b.
步骤2样本数据预处理, 将原始数据进行统计, 以消除不同指标间量纲影响. 其表达式为:
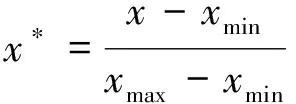
(5)
步骤3随机划分数据样本的训练集与测试集, 载入训练集数据.
步骤4由输入层与隐层连接权重、 隐层神经元偏置及选定的激励函数计算隐层节点输出矩阵. 通过训练集训练样本得到模型并保存.
步骤5使用测试集数据验证模型精度.
4 实验结果与分析
实验采用的台风资料主要来自中国气象局编写的《热带气旋年鉴》[17], 以及国网某供电公司提供的2015—2018年某地区台风影响下电网的灾损数据, 该数据来源可靠、 信息真实. 然而, 该地区每年遭遇的台风个数有限, 灾后人工统计历时长、 效率低, 系统中有关台风影响的数据极为匮乏. 对近几年8个台风样本展开研究和分析, 建立适合小样本的配电线路灾损预测模型.
样本数据经过标准化后, 提取台风风级, 台风风速, 模糊处理后的登陆距离以及风圈半径作为ELM模型的输入, 10 kV跳闸次数, 断线、 倒杆和断杆数据作为输出. 将台风登陆地到该地区的直线距离作为本次模糊集的论域, 即U={171.52, 455.17, 171.52, 198.34, 236.39, 272.62, 122.31, 51.92}(单位: km), 分别表示8个台风登陆点距受灾地区的距离, 根据其影响程度进行模糊评价, 获得各样本的隶属度值, 如表2所示.

表2 8个台风登陆地距离归一隶属度
为了研究模型性能参数的影响以及与其它方法预测结果的比较, 这里选用均方根误差(the root-mean-square error, RMSE)作为模型精度的评价指标, 计算公式为:
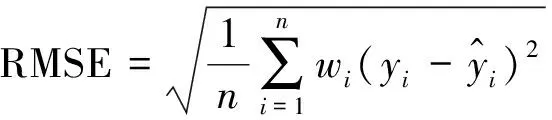
(6)

4.1 台风影响下配电线路模型的预测结果
综合考虑模型的训练误差、 隐含层神经元个数之间的关系, 选择Hardlim函数作为实验的激励函数, 隐含层节点个数为45进行实验. 通过ELM对台风所选的数据进行模型训练, 并使用测试集数据进行测试, 最终检测结果如图4所示.
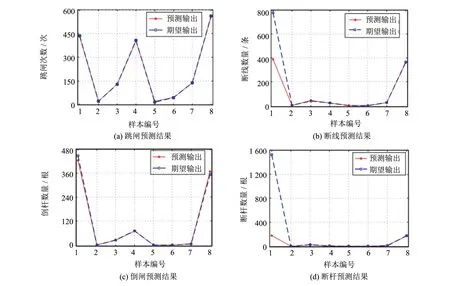
图4 基于ELM算法的灾损预测结果Fig.4 Damage loss prediction results based on ELM algorithm
图4分别表示台风影响下, 跳闸次数、 断线次数、 倒杆数量以及断杆数量的结果预测, 整体预测结果基本吻合. 而断线和断杆除了样本1的结果出入过大以外, 其余7个数据的测试结果都非常接近. 造成这种现象的原因主要是样本1的数据收集于2015年, 防风措施尚未完善, 加上配电线路本身的脆弱性, 造成的灾害尤为严重, 导致台风数据与灾损的差距过大, 无法拟合.
4.2 隐含层激活函数对预测模型精度的影响
为了分析不同激活函数对实验精度的影响, 以RMSE作为评估标准, 分别以Sigmoid函数、 Sine函数、 Hardlim函数、 Tribas函数以及Radbas函数作为激励函数进行实验. 当模型选用不同的激励函数时, 得到的预测结果如表3所示.

表3 不同激活函数测试结果
表中平均误差表示8个样本测试结果的均方根误差平均值. 5种激活函数的测试结果显示, Hardlim函数、 Tribas函数在训练集上的表现更胜一筹. 测试集均方根误差以Sigmoid、 Sine、 Hardlim函数表现更优. 此外, Hardlim函数获得的均方根误差平均值最小. 3个指标结果说明Hardlim函数在本实验中的性能更加优秀和稳定, 因此更适合作为台风灾损的预测实验的激活函数.
4.3 隐含层节点个数对预测模型精度的影响
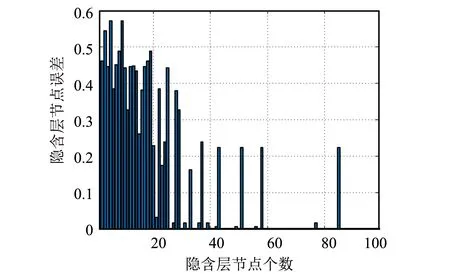
图5 隐含层节点预测结果Fig.5 Prediction results of hidden layer nodes
隐含节点数是ELM模型的关键参数, 默认其他参数不变的情况下, 分析了不同隐含层节点数对台风影响下的灾损预测精度, 设置1到100个隐含层节点数, 其得到的预测结果如图5所示.
从比较结果来看, 随着隐含层节点个数的增加, 模型的预测精度开始不断减小. 当节点个数超过25时, 预测误差低于0.1, 部分隐含层节点引起误差波动, 但不影响整体实验结果. 考虑到节点个数的增加将导致模型训练的时间越来越长, 影响预测效率. 因此, 选择隐含层节点个数为45个, 以保证实验的最佳结果.
4.4 不同算法对预测模型精度的对比
将所提出的基于模糊评价的ELM算法与传统ELM算法、 BP算法以及最小二乘支持向量机进行对比. 跳闸是配电线路灾害中发生次数最多, 最典型的故障类型, 因此采用跳闸样本作为对比实验样本数据. 在同样实验条件下, 用不同方法分别做了跳闸组的实验, 最终计算每组实验的均方根误差. 实验结果如表4所示.

表4 不同算法与所提出算法的预测误差对比
模糊处理后的ELM测试集与训练集误差优于其他现有算法. 同时, 8个样本产生的RMSE中, 带模糊处理的ELM算法误差值低至0.009 8. 由此说明利用经过模糊处理后的数据建立ELM灾损预测模型具有一定的性能优势, 可以获得20倍以上的精度提升. 因此, 基于模糊评价的ELM算法能够很好地实现台风影响下的配电线路灾损预测.
5 结语
针对台风危害下的配电线路受损问题, 提出一种基于模糊评价特征的ELM灾损预测模型. 摒弃考虑多因素关联的台风影响做法, 通过对台风登陆点与受灾区域的直线距离进行模糊评价, 取得明确灾害分类级别的隶属度值. 以此结合台风其他属性, 建立ELM灾损预测模型. 实验结果表明, 加入对登陆点距离进行模糊特征后的极限学习机预测模型, 不仅取得了准确的灾损预测结果, 还能够适用于小样本数据预测问题. 对于不同种类的配电线路灾损类型, 获得了较高的预测精度. 因此, 所提出的基于距离模糊处理的极限学习机灾损预测模型, 对台风灾后应急处理能力和灾后重建工作具有重要的参考价值.
猜你喜欢
环球时报(2022-09-07)2022-09-07 17:16:40
小读者(2020年4期)2020-06-16 03:33:46
经济技术协作信息(2018年7期)2019-01-14 03:05:40
小哥白尼(趣味科学)(2018年12期)2018-12-18 02:13:54
小学生导刊(2018年34期)2018-12-18 01:53:14
电子制作(2018年18期)2018-11-14 01:48:20
通信电源技术(2018年5期)2018-08-23 01:16:20
小星星·阅读100分(低年级)(2017年8期)2017-08-08 21:58:30
山东青年(2016年3期)2016-02-28 14:25:55
母子健康(2015年1期)2015-02-28 11:21:33
