
多尺度定位信息增强的图像全景分割方法
2021-06-17 00:37:58薛程叶少珍
福州大学学报(自然科学版) 2021年3期
薛程, 叶少珍, 2
(1. 福州大学数学与计算机科学学院, 福建 福州 350108; 2. 福州大学智能制造仿真研究院, 福建 福州 350108)
0 引言
图像理解是图像分割中重要处理环节, 将有助于促进自动驾驶、 机器人和增强现实等技术的实际应用. 在深度学习技术应用之前, 图像解析、 场景解析和全图像理解等已经得到一定的发展, 随着深度学习在语义分割和实例分割的应用, 文献[1]将其命名为全景分割(panoptic segmentation, PS), 将图像内容分为Stuff不可数语义类(例如草地、 天空、 道路)和Things可数实例类(例如人、 交通工具), 任务的目的是为图像中每一个像素分配语义分类标签和实例ID. 在Things实例类中, 实例ID用于区分每一个目标, 因此其对于Stuff语义类来说是非必需的, 但是分类标签对于Stuff语义类和Things实例类是必需的. 所以, 对于同一个实例的像素拥有相同的实例ID. 目前, 主流研究方法为: 选取一个主干网络进行特征提取, 然后将特征图分别输入到语义分割分支和实例分割分支中, 实现共享特征, 最后经过一个启发式策略将两者的输出进行合并. 但其仍存在两大问题, 一是语义分割结果和实例分割结果的重叠冲突, 二是实例分割中出现的重叠冲突. 全景分割任务包含了传统的两大任务: 语义分割和实例分割. 其中语义分割是全图像每一个像素的分类, 包括了Stuff语义类和Things实例类, 无法分割出具体的实例. 实例分割, 关注于Things实例类的检测和分割, 并没有对Stuff语义类进行检测和分割. 本研究在原有全景分割网络的基础上通过改动卷积结构以及增添新的卷积模块分别提高了AP评价指标和mIoU评价指标.
1 图像全景分割方法比较
在常用的Cityscapes数据集上, 人工对一张图片进行像素级的标签注释需要较长的时间, 如何在全景分割标注数据不够的情况下完成全景分割任务, 文献[2]提出使用弱监督的方法, 利用弱边框和图像级别的分类标签来减少标注数据少引起的问题. 针对实现全景分割落地, 埃因霍芬理工大学团队尝试了端到端的方法[3], 提出了JSISNet, 将语义分支和实例分支的损失函数合并, 从而达到联合训练, 实现端到端的方法. TASCNet采用从共享的骨干网提取特征图, 在实例分支使用基于候选区域的方法Mask R-CNN[4]完成Things类的分割并生成Things类的二进制掩码, 语义分支使用一系列的卷积和上采样操作完成Stuff类的分割, 以及生成Things类的二进制掩码, 通过与实例分支的Things二进制掩码和语义分支的Things二进制掩码的互补, 最终将实例分支的输出、 二进制掩码的输出及语义分支的输出进行融合, 输出最终的全景分割结果, 实现了Things和Stuff类的一致性. 文献[5]根据语义分割和实例分割存在上下文信息联系, 提出了AUNet, 利用前景上下文信息来提高背景Stuff分割的效果. 由于之前的一些全景分割的工作使用单独和不同的网络进行实例和语义分割, 而没有进行任何共享计算, PanopticFPN[6]致力于为全景分割任务提供一个良好的基线, 认为全景分割旨在架构级别上统一这些方法, 应该为语义分割和实例分割设计一个单一完整的网络. 通过使用共享的特征金字塔网络获取特征图, 为实例分支Mask R-CNN赋予语义分割分支FCN[7]来完成分割. UPSNet[8]遵循以往的做法, 使用ResNet[9]的FPN[10]作为共享骨干网来提取特征图, 实例分支基本使用Mask R-CNN, 使用可变形网络的子网络输出语义分支的结果, 根据PQ的计算方式, 创新地引入一个未知类, 当对某一个像素预测冲突时, 将其置为未知类, 既解决了语义分割结果和实例分割结果的冲突, 也提高了PQ评价, 在全景头中, 通过使用实例分割结果修正语义分割结果的方式来融合两个分支结果进行全景预测. UPSNet算法比之前的算法在PQ评价指标和推理速度上都有进一步的提高, 使用的语义分支更加轻量, 但是UPSNet算法对细长物体的分割效果较差(例如电线杆), 未知类的引入虽然解决了冲突, 但是对于冲突像素点的分类预测有一定的失误.
综上所述, 对于解决全景分割任务, 主要在于建立一个统一完整的网络架构, 直接实现对每一个像素点的分类标签和实例类的实例ID的预测, 在现有大多数框架中, 采用方法主要是提取一个共享特征, 分别对语义分割和实例分割进行预测, 最后将两者的预测结果进行融合, 虽然这类方法不同于PS中提出的实现一种统一完整的网络框架, 但是在一定程度上能够解决全景分割任务.
2 图像全景分割改进模型
从UPSNet结构改进出发, 针对实例分支定位和语义分支分割存在的两个问题, 首先提出在特征金字塔残差网络中添加一条自底向上的定位信息增强路径, 其次在语义分支中添加一个并行的四个克罗内克卷积, 实现对语义和实例分支效果的提升.
2.1 改进算法框架模型
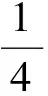

图1 本研究改进算法框架模型Fig.1 The algorithm framework model of the paper
2.2 定位信息增强特征金字塔网络
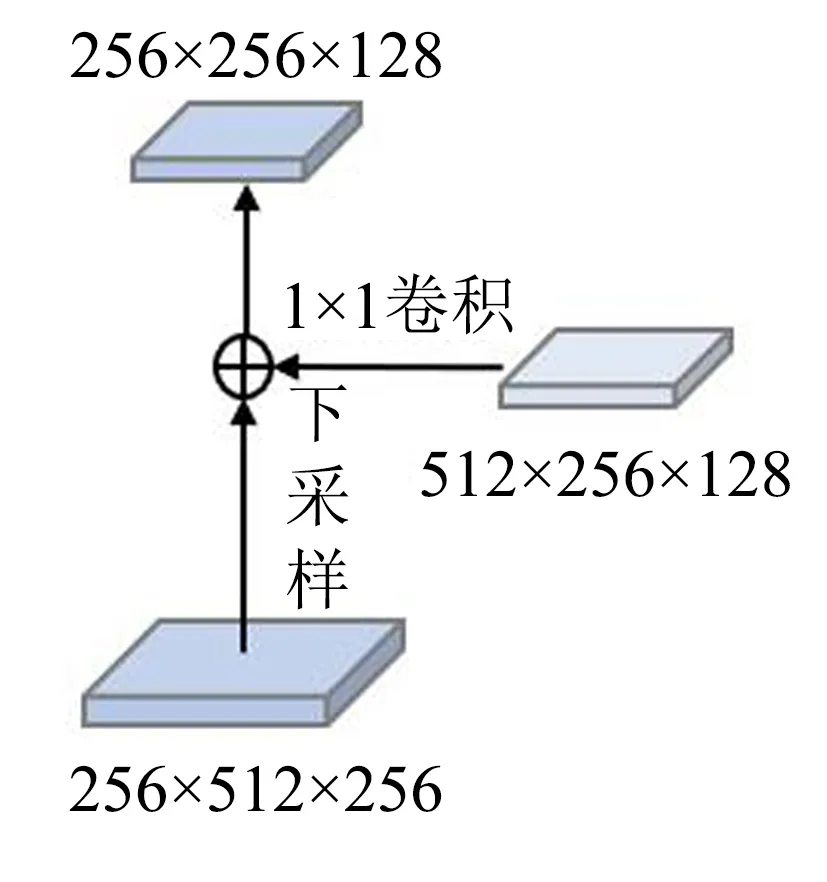
图2 自底向上和横向连接的结合Fig.2 Combination of bottom-up and lateral connections
本研究提出了如图2所示的自底向上的操作. 在图像分割以及目标检测领域使用多尺度特征表示往往有更好的效果, 传统特征金字塔网络是一种通用的多尺度信息特征提取器, 因为高层神经元对整个物体有强烈的反应, 而其他神经元更容易被局部纹理和模式激活, 所以需要添加一条自顶向下的路径来传播语义上强大的特征. 通过在所有尺度上构建高层语义特征图, 使用一种通用的用于图像分类的模型, 例如ResNet, 在分类模型中, 通过自顶向下和横向连接, 将特征层次中的两个相邻层依次组合, 建立特征金字塔. 对语义强但分辨率低的高层次特征自顶向下进行上采样, 并与高分辨率低层特征相结合, 生成高分辨率和语义强的特征表示. 但是语义强的高层特征缺少更多的低层的物理特征, 而信息在神经网络中传播的方式是重要的, 低层物理特征能够促进实例物体定位到更准确的位置. 在此方面, 用于实例分割的PANet[11]在自顶向下后的特征图后面添加一条自底向上的路径增强模块, 其模仿了传统特征金字塔的横向连接, 通过和自底向上的特征进行结合, 输出最终特征图, 这样在较低层次上用精确的定位信号增强整个特征层次, 缩短了低层和高层的信息路径.
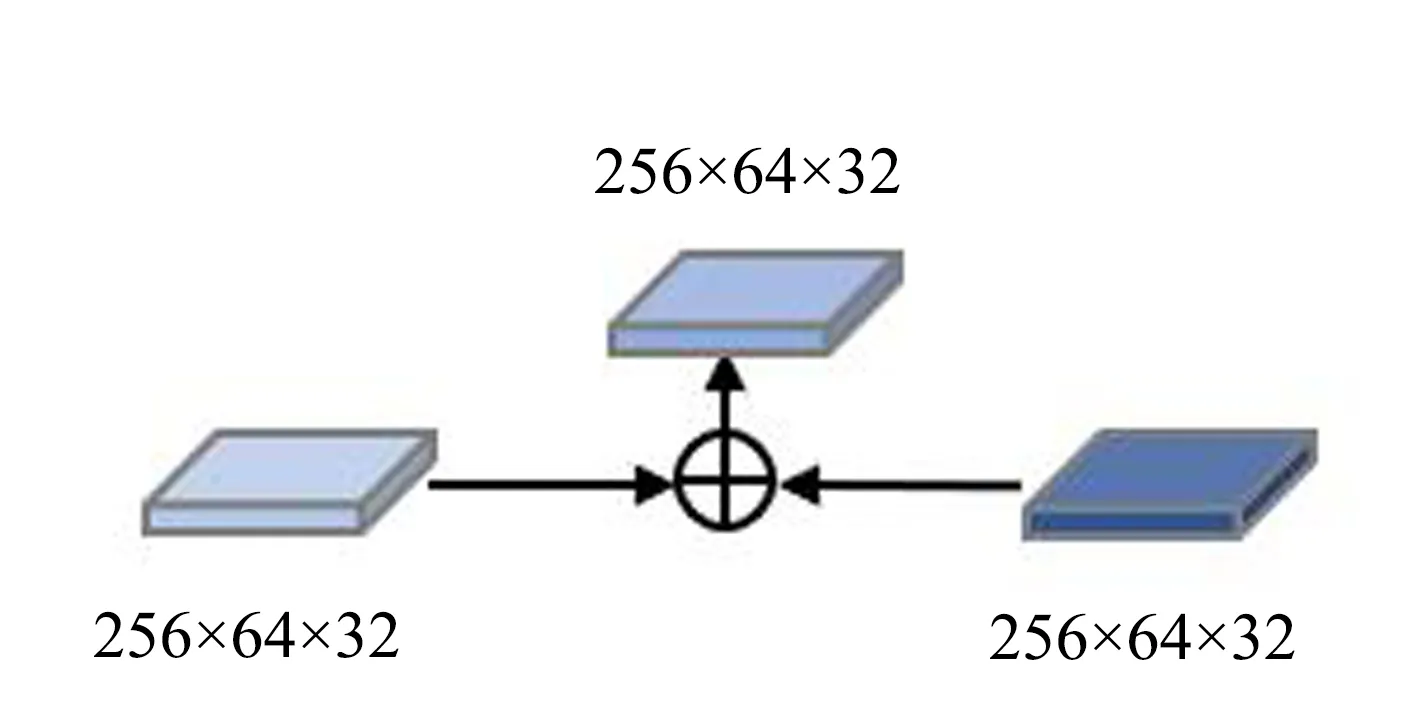
图3 自底向上和自顶向下的结合Fig.3 A combination of bottom-up and top-down
鉴于低层定位信息对于实例分支中实例定位的重要性, 结合传统特征金字塔网络, 使用ResNet分类模型, 在ResNet的卷积过程中, 额外添加一条自底向上的路径, 对每一层先进行下采样, 再与原来的特征图横向连接进行相加结合, 一层层将低层信息传播到最高层, 产生了{PL2,PL3,PL4,PL5}特征图; 然后, 再与传统特征金字塔的自顶向下的{PR2,PR3,PR4,PR5}特征图结合, 结合方法如图3所示; 最后再通过一个3×3卷积输出最后的{P2,P3,P4,P5}多尺度特征图, 从而实现将低层定位信息传播到高层语义信息强的特征图中, 弥补了高层特征表示缺乏低层定位信息的缺点, 使共享主干网的特征输出更适合之后的实例分支.
2.3 克罗内克卷积和扩张卷积对比
本研究提出了如图2所示的自底向上的操作. 而在图像分割领域中, 感受野对于图像分割精度的好坏是一个重要的因素, 而通常情况下是使用标准卷积再加上池化操作来增大感受野, 但是减小了特征图尺寸. 由于图像分割是逐像素预测, 所以在进行预测时, 需要在尺寸较小的特征图上采样至原始大小尺寸, 这个过程经历了将图片尺寸缩小再放大, 会导致丢失信息. 扩张卷积实现了在增大感受野的同时, 不会缩小图像尺寸, 并且设置不同的扩张率的扩张卷积一起使用, 可以捕获多尺度上下文信息, 但会受到棋盘问题的影响, 导致丢失了局部信息. 因此在设置不同扩张卷积时, 可以满足两个特性, 一是叠加扩张卷积的扩张率不能有大于1的公约数, 二是将扩张率设计成锯齿状结构.
由于扩张卷积会导致局部信息的丢失, 所以引入了克罗内克卷积[12], 使得在卷积的过程中能够捕获局部信息, 并且不会增加参数, 网络不会更加复杂, 克罗内克卷积通过两个因子来调节大小, 分别是内部膨胀因子和内部共享因子. 内部膨胀因子控制克罗内克卷积扩张率, 而内部共享因子控制用于捕获局部信息子区域的大小. 也就是说, 克罗内克卷积不仅继承了扩张卷积的优点, 而且还克服了扩张卷积会丢失局部信息的缺点. 通过一个有效特征比(valid feature ratio, VFR)来对比克罗内克卷积和扩张卷积, 从而验证克罗内克卷积可以捕获局部信息, 发现克罗内克卷积的有效特征比较高. VFR用来计算所涉及的特征向量数与卷积块中所有特征向量数之比.
克罗内克卷积的数学理论基础是克罗内克积, 使用一个内部膨胀因子大小r1×r1的方阵与原始核进行克罗内克积, 使得原始核大小可以扩展到原来的r1倍.为了避免额外带来参数, 可以将r1×r1的方阵设计为一个全1矩阵和零矩阵的结合, 而全1矩阵的大小可以设置为内部共享因子的大小为r2的方阵.
克罗内克积公式如下:
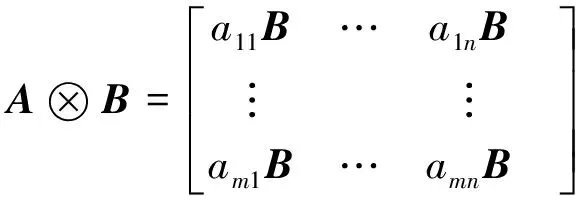
(1)
其中,A是一个m×n的矩阵;B是一个r×s的矩阵.则克罗内克卷积公式可以表述为:
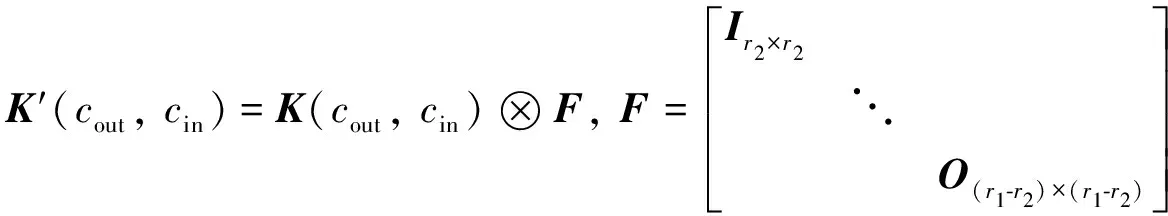
(2)
这里,cout∈[1,coutput]∩Z,cin∈[1,cinput]∩Z;K′是经过克罗内克积后的克罗内克卷积核;K是原始卷积核.令每一个通道上的特征矩阵定义为M, 克罗内克卷积核K′映射到M中的中心坐标是(p,q), 则可以定义特征矩阵M中参与计算的区域矩阵为S.以上可以推出参与计算的坐标为: (p+ir1+u,q+jr1+v), 其中i,j∈[-k,k]∩Z,u,v∈[0,r2-1]∩Z, 那么在每一个通道上的克罗内克卷积操作可以表示为:

(3)
由上述公式可知, 当r1≥1,r2=1时, 克罗内克卷积退化为扩张卷积, 当r1=r2=1时, 克罗内克卷积退化为标准卷积.
本研究使用四个克罗内克卷积, 将多尺度特征分别输入到克罗内克卷积网络中, 得到的输出与可变形卷积网络的输出进行融合, 接着上采样拼接, 输入到1×1卷积中进行语义类别预测.
3 实验与结果分析
3.1 实验数据集
Cityscapes城市街道场景数据集, 主要提供无人驾驶环境下的图像分割数据, 用于评估算法在城区场景语义理解方面的性能: 像素级、 实例级和全景语义标注. 该数据集中所有图片来自于50个不同城市春、 夏、 秋的街道场景, 每一张图片的分辨率都是1 024 px×2 048 px, 并且还包含了5 000个精细标注的图片和20 000个粗糙标注的图片, 图像中物的类别来自于30种语义类, 其中19个常用类用于语义分割的基准评估. 这些图像分为8大类: 平面、 人、 交通工具、 建筑、 小物体、 自然、 天空、 空类. 5 000个精细标注的图片分为了三个文件, 分别是包含2 975张图片的训练集文件、 包含1 525张图片的测试集文件和包含500张图片的验证集文件. 部分示例图像如图4所示:

(a) 示例1 (b) 示例2 (c) 示例3图4 Cityscapes数据集示例Fig.4 Cityscapes dataset example
3.2 实验定量分析
实验使用ResNet-50作为共享主干网低层信息增强特征金字塔网络的图像分类模型, 学习率为0.005, 动量为0.9, 优化器为SGD, 归一化方法使用组归一化, 训练轮数为48 000, GPU使用NVIDIA GeForce GTX 1080Ti.
为了对全景分割方法性能进行客观评价, 采用PQ、 AP和mIoU作为本研究提出的全景分割方法效果的衡量指标. 其中, PQ是由RQ和SQ的乘积而来; RQ是在检测中应用广泛的F1 score, 用来计算全景分割中每一个实例物体识别的准确性; SQ表示匹配后的预测分割和标注分割的mIoU, 当预测分割和标注分割的IoU严格大于0.5, 则表示预测的分割和标注的分割匹配. PQ的计算式如下所示:
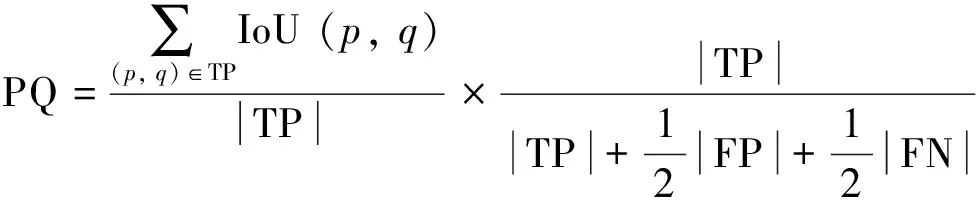
(4)
AP指标是实例分割常用的评价指标, 指的是实例的平均精度, 是PR曲线和坐标所围成的面积:
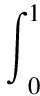
(5)
mIoU指标是语义分割广泛使用的评价指标, 指的是每一个类的预测分割和标注分割的交并比再取平均. mIoU 表示分割结果与原始图像真值的重合程度.

(6)
从表1的对比结果可以看出, 在评估实例分支的AP指标和语义分支的mIoU指标相对于UPSNet有了更进一步的提升, 但是反而降低了PQ指标, 说明UPSNet的全景头融合方法还存在一定的缺陷, 需要更好地解决两个分支在融合时产生的冲突问题.

表1 在Cityscapes 验证集上的对比结果
3.3 实验定性分析
从图5的UPSNet方法的全景分割结果图片中看出, 在远处的语义类和实例类颜色相近的实例类像素点会被分配为语义类, 从而有的实例会直接消失, 并且在细节的刻画上, 会导致很多的凹凸不平, 使得分割出来的物体不够有线条性. 在第一行图片中, 本研究方法的草地分割更加准确并且更加平滑; 第二行图片中, UPSNet方法中右边墙面没有分割出来, 而本研究方法分割出了一部分; 第三行图片中, 在UPSNet方法中中间拿着包的人的手臂出现了断续, 本研究方法完好地分割出来; 第四行图片中, 本研究方法对于UPSNet方法在分割道路时更接近于标注图片.
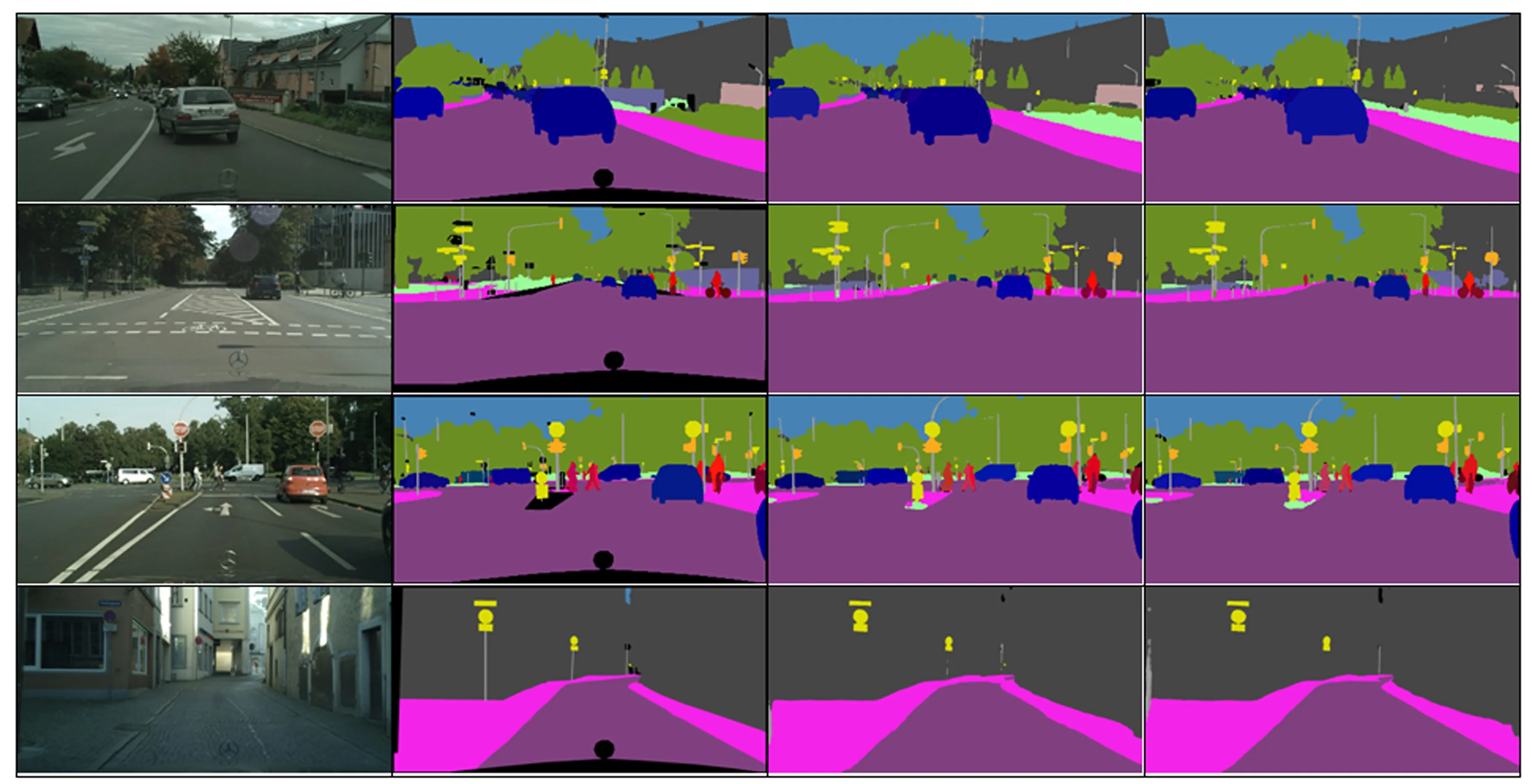
(a) 原图 (b) GroundTruth (c) UPSNet方法 (d) 本研究方法图5 本研究方法与UPSNet在Cityscapes上的全景分割效果对比Fig.5 Comparison of panoramic segmentation effect between UPSNet and our method on Cityscapes
4 结语
为了提高语义分支和实例分支的分割能力, 设计了一个新型的基于多尺度定位信息增强的全景分割模型, 其能够有效增强分割能力主要源于两方面.
1) 多尺度定位信息增强特征. 根据传统特征金字塔网络的高层特征缺乏低层物理特征的缺点, 在传统特征金字塔网络的另一边添加一条自底向上的路径, 增强了高层特征的定位信息.
2) 克罗内克卷积组. 在语义分支中添加四个克罗内克卷积分别对应四个多尺度特征, 增大了此时的多尺度特征的感受野, 并且防止了特征的局部信息丢失.
针对UPSNet的不足进行了改进, 在Cityscapes公开数据集上进行了多组多种方法的对比实验, 实验结果表明了本研究方法相对于UPSNet在语义分支和实例分支中的效果更好. 此外, 未来的工作将进一步研究全景头中语义分支结果和实例分支结果的融合方法以及语义分支和实例分支之间的相关性, 探索出更好的融合方法以提高整体的分割能力.
猜你喜欢
家庭影院技术(2020年11期)2020-12-28 01:22:36
学生天地(2019年28期)2019-08-25 08:50:54
英美文学研究论丛(2018年1期)2018-08-16 03:00:54
数学物理学报(2018年1期)2018-03-26 08:16:36
家庭影院技术(2017年12期)2017-02-06 02:32:12
特别文摘(2016年21期)2016-12-05 17:53:36
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
疯狂英语·口语版(2013年1期)2013-01-31 09:23:26
