
基于机器学习算法的信用风险预测模型研究
2021-06-15 17:55李丽赵陆亮陈军
企业科技与发展 2021年3期
关键词:机器学习
李丽 赵陆亮 陈军


【摘 要】为了解决西南财经大学“新网银行杯”竞赛数据中存在的高维稀疏数据、无标签数据、多产品客群来源及好坏样本不平衡等问题,采用机器学习方法,如Logistic回归、决策树、Adaboost、GradientBoosting和LGB模型对数据进行训练,得出LGB模型的性能评价指标AUC数值最大的结论。
【关键词】信用风险预测;机器学习;性能评价指标
【中图分类号】F830.589 【文献标识码】A 【文章编号】1674-0688(2021)03-0046-03
1 研究背景
银行信用风险评估一直是学术研究和商业银行管理领域重要的研究话题。信贷信用风险是银行所面临的信用风险中最重要的一个部分,又由于银行是整个金融系统的核心,银行的主要资产业务是银行对企业发放的贷款,若企业由于破产或资金流动性等原因无法按期偿还贷款甚至造成违约会给商业银行带来巨大的损失。此外,商业银行不良贷款率的不断提升也会导致整个金融市场风险的提升。因此,商业银行能否获得性能极好又切实可行的信用風险预测模型,对于银行金融机构乃至整个金融市场至关重要。
早期的预测模型大多使用传统计量和统计方法,例如多元判别分析方法、Logistic回归分析方法等。近年来,随着人工智能的兴起、机器学习和数据挖掘在世界范围内的推广,帮助商业银行风险预测获得了新的、更有效的预测方法,也预示着在商业银行信用风险预测领域,人工智能方法会逐渐取代传统统计方法,成为预测商业银行信用风险的首选方法。
2 文献回顾
Ekinci & Erdal(2011)[1]对土耳其的35家私人商业银行进行分析,比较了SVM方法和神经网络方法的预测精度。余晨曦等人(2008)[2]运用支持向量机技术(SVM),构建了基于支持向量机的我国商业银行信贷信用风险度量模型,将支持向量机的非线性分类器应用到贷款违约的判别中,研究发现SVM可以处理非线性分类问题,但不能很好地估计违约概率。李佳等人(2018)[3]将SVM、BP神经网络和PCA变量降维处理结合使用,对2015—2016年我国的144家沪深上市公司开展研究和预测,最后得出了良好的预测能力。
3 数据来源及解析
3.1 数据来源
本文数据是来自DC竞赛网中的西南财经大学“新网银行杯”数据科学竞赛,四川新网银行已经开发出了国内第一款全在线办理的银行大额云授信产品——“好人贷”。比赛提供真实业务场景下的脱敏数据,在“好人贷”的量化风控实践中,四川新网银行面临多个维度的挑战:高维数据、稀疏数据、无标签样本、多产品客群好坏样本不平衡等。其中,对于包含多产品(客群)的高维特征数据和表现数据(部分有标签,部分无标签),邀请参赛者对数据进行探索分析,综合利用监督和半监督机器学习算法、迁移学习算法等设计区分能力高、稳定性强的信用风险预测模型,对客户信用风险进行预测。
通过初步的数据分析,我们发现数据的特征缺失严重,可能会对模型的预测带来干扰,并且虽然特征维度仅有157维,但是由于是匿名特征,因此很难确定数据的具体含义。脱敏数据不能使用相关性分析方法,也不能构造新的特征,所以在数据清洗中对缺失值的处理与分析和模型的训练与评估都是需要我们解决的关键问题。
3.2 数据解析
此次竞赛提供的数据包括用户id,157项脱敏的属性/行为特征,以及是否属高风险用户的标签项。一共有3个文件,数据描述如下。
(1)train_xy.csv,带标签的训练集数据,共15 000条。
(2)train_x.csv,不带标签的训练集数据,除无标签字段‘y外,其余字段与train_xy.csv相同,共10 000条。
(3)test_all.csv,测试集数据,除无标签字段‘y外,其余字段与train_xy.csv相同,共10 000条。
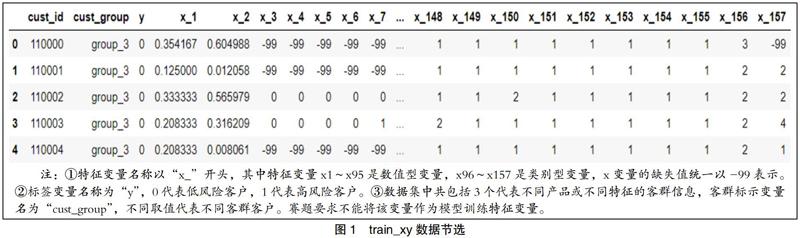
train_xy数据节选如图1所示。
那么,根据赛题任务与数据,可以将问题转化为“二分类”问题,0代表低风险客户,1代表高风险客户,赋值为0的个数有14 309,为1的个数为691,0和1的数量比值为21∶1,不同cust_group的样本分布也不平衡(见表1)。
评估指标为AUC=0.3×AUC1+0.3×AUC2+0.4×AUC3,并且提供有/无标签数据样本,可以使用监督与半监督方法综合预测用户的信用风险概率。
4 数据清洗与处理
4.1 缺失值分析
根据数据介绍,x变量的缺失值统一以-99表示,我们首先对每个x特征变量,在列方向上进行缺失值的个数统计,从而转化为缺失率。缺失率的大小可以表明某个特征缺失是否严重及严重程度。以train_set为例,从图2中可以更加直观地看出,有较多的特征缺失率高达100%,说明这些特征缺失严重,可能会对模型预测带来干扰。
4.2 缺失值处理
根据上面的分析,几乎所有数据都存在缺失值-99。一般处理缺失值的方法有中位数、平均数、众数填充等操作。在对变量进行填充之前,根据每个样本的缺失值的个数,对缺失值进行离散化并划分成7个区间引入虚拟变量。
在这里我们针对数值型的数据利用均值进行填充,对类别型的数据引入哑元变量,并对填充完的数据进行归一化处理。图3以x_81为例,可以看到均值填充后进行归一化的结果。
5 特征选取
一般而言,常见的特征选择方法有如下3种:一是过滤式选择,即通过相关系数、卡方检验、信息增益等筛选特征;二是包裹式选择,是通过迭代特征,利用学习器的性能评估进行选择;三是嵌入式选择,特点是利用学习器自动选择特征,包括正则化、基于树模型选择。
通过运用随机森林的方法对157个特征进行了重要性的排序,我们从中选取TOP25作为模型的特征,各个特征的重要性如图4所示。
6 模型选择与评估
6.1 降维与不降维结果比较分析
本文的数据建模方法主要有Logistic回归、决策树、Adaboost、GradientBoosting 4个模型。这两种方式的保留信息会有所不同,那么通过模型做出的预测结果肯定有区别。通过对两者的结果进行比较与分析,如图5所示,我们发现不降维的结果要优于降维之后的结果,所以我们最后决定不删除任何原始特征,而是使用模型自动选择。这样做有两个考虑,一是特征维度并不高(157维),而且是匿名特征,很难确定具体含义;二是模型自身具有选择特征的特性,可以更好地表现数据。
6.2 模型存在的问题
在上述模型中,会存在不同程度的过拟合现象(如圖5所示)。
6.3 解决方法
我们将采用5折分层交叉验证及将模型升级为LGB模型的方法减轻过拟合的现象,并且得到的结果AUC1=0.744 82、AUC2=0.765 77、AUC3=0.842 87、AUC=0.788 7。LGB训练的AUC值明显高于其他几个模型。所以,最终我们选取LGB作为我们的最终模型。
出现过拟合的原因:一是数据可能过小,容易产生过拟合;二是模型本身性能可能不理想,那么增加训练数据是没有效果的。但是相较这两种原因,我们认为前者的可能性更大。
7 结语
本文将数据集随机选取70%作为训练集,剩下的30%的数据作为验证集,并对缺失数据进行均值填充,运用多种机器学习方法,以AUC为模型的性能评价指标,由于决策树、逻辑斯蒂回归等模型出现过拟合现象,所以我们采取五折交叉验证,并改进模型引入LGB模型,得到的结果也是最优的,选取LGB模型作为我们最终的模型。
参 考 文 献
[1] Ekinci A,Erdal H I.An Application on Prediction of Bank Failure in Turkey[J].Iktisat Isletme ve Fi-nans Dergisi,2011,26(298):21-44.
[2]余晨曦,梁潇.基于支持向量机的商业银行信用风险度量模型[J].计算机与数字工程,2008,36(11):10-14.
[3] 李佳,黄之豪.银行信用风险预测——基于SVM和BP神经网络的比较研究[J].上海立信会计金融学院学报,2018(6):40-48.
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年10期)2016-06-02
科教导刊·电子版(2016年10期)2016-06-02
电脑知识与技术(2016年3期)2016-04-07
