
网络空间中情感扩散、信息级联与舆论偏差的内生影响效应研究
——基于2015—2020年突发事件面板数据动态分析
2021-06-14 02:12阳长征
情报学报 2021年5期
阳长征
(西安交通大学新闻与新媒体学院,西安 710049)
1 引 言
近年来,互联网的快速发展和广泛使用,在为公众提供广阔的话语空间以及自由表达的同时,也促使各类网络突发事件频发,形成难以遏制的社会舆论,并且已对社会造成了重大影响,如2020年新冠肺炎、2018年长春长生疫苗事件等。事件发生后,一方面,由于网络情感传播和信息级联,受众易于受到意见领袖、从众心理等因素的影响,从而产生认知偏差;另一方面,由于线上、线下实时互动,且把关人缺位,事件传播过程易于产生信息噪音。在上述因素叠加共振的作用下,突发事件网络舆论出现偏差,进而对公众心理及社会健康发展产生严重负面影响,因此,突发事件网络舆论已成为了人们高度关注的社会问题。
情感作为网络舆论演化的重要动力,其传播过程则是情绪载体通过所嵌入的社会网络进行传导和扩散,形成情感互动,并建立起特定情感关系的过程。当突发事件发生后,情感传播在公众中可形成大规模网络动员,并不断促进网民的情感共振与话语协同,影响着网民对事件本身的思考与解读,从而导致突发事件网络舆论偏差的形成和不断放大[1]。同时,信息级联理论指出,人们在某些情境下,倾向于认为他人所提供的信息比自身以其他方式获取的信息更具可信度和合理性,忽略自身所获得信息的可靠性,从而选择从众性地加入该类人群,并保持与多数群体成员相一致的看法、判断和行为,导致对事物的认知产生偏差[2]。而差序格局理论指出,差序格局作为社会关系结构现象,常发生于熟人关系、地缘关系中,在其中信息的传播以个体为中心,像水波纹一样推及开去。在差序格局中,每个人均以自我为中心结成网络,就像将一块石头扔至湖中,以这块“石头”(即个人)为中心点,在四周形成一圈圈波纹,波纹的远近可以标示社会关系的亲疏,并随自身所处时空的变化而产生不同的圈子[3]。传播学水纹效应模型也指出,信息传播过程就像在平静的湖水中扔下一颗石子,水纹会快速地向周围产生共振波,其扩散的范围和效果受到水质和水面地形的影响而有所不同。同样地,在网络空间中,信息的传播过程也具有该扩散效应。针对网络突发事件,人们由于无法获得危机事件的确切信息,容易产生从众效应,导致信息级联行为。由于网络社会人际关系的差序格局特征以及网络信息传播的波纹效应,在网络突发事件中,人们在对信息的认知和接受上容易形成信息差序级联效应,导致人们对事件形成舆论偏差,进而影响社会的稳定和健康发展。在此背景下,本文研究突发事件中网络空间情感扩散、信息差序级联与舆论偏差间的内生影响,并探索如下问题:①网络空间中情感扩散、信息差序级联与舆论偏差间的脉冲响应效应及边际影响力如何?②变量间的脉冲响应效应及边际影响力在不同用户细分群体间的差异性如何?
通过对上述问题的研究,可以发现网络空间中情感扩散、信息差序级联与舆论偏差之间相互影响的大小和方向,以及该影响效应在不同时间点的动态变化特征,并能够分离出各变量对其他变量波动的贡献率,各变量间影响效应在性别、年龄和学历群组上呈现的差异。根据研究发现,可挖掘出我国突发事件情感扩散、信息差序级联和网络舆论偏差的主要影响因素,制定有针对性的情感引导、级联监管和偏差纠正的具体措施,并根据不同细分群体而采用差异化监管策略,从而提高突发事件网络舆情的防控及治理效率和效果。
2 文献综述
为了深入了解网络舆情形成及演化过程的影响机理,国内外的学者们一直从不同视角对网络舆情进行探索和研究。
2.1 情感扩散与网络舆论
国内对情感扩散与舆论关系的研究:一部分学者从舆情传播过程的情感变化进行探索,如毛太田等[4]以“上海警察绊摔小孩事件”为例,收集新浪微博中的相关数据作为研究的数据支持。借助微博主题挖掘、关键词提取、网络信息生命周期等搜索技术和理论,通过情感分析,全面呈现了网络热点事件的特征。研究发现,新媒体时代的网络热点事件传播速度更快,信息更新周期更短,整个生命周期都没有经历明显的“成长期”。同时,热点事件信息本身可能是在公众的情感冲动中被误解和放大,还可能被恶意利用于散布虚假信息和有害信息。在信息不明确的情况下,公众很容易受到公众最主要观点的影响,并且在没有验证的情况下做出错误判断。因此,及时宣布事件的真相,并抓住信息“生态位”显得非常必要。陈显龙等[5]以2015年排名前十位的热点事件为研究对象,基于微博的情感特征和传播特性,构建了微博场能量模型。研究结果表明,根据微博情感效价的绝对值,传播特征的指数越高,则微博舆论的积极或消极能量越高,且微博会出现二次峰值。时间指数越大,微博舆论的耗散能量越大,微博客舆论能量值下降得越快。也有一部分学者从话题互动层面探讨舆情演化过程中的情感传播,如蒋晓丽等[6]基于互动仪式理论,认为网络话题是互动仪式的一种新形式。在网络互动中,情感是根本力量,事件的主题通过互动仪式获得情感能量,以分享情感内容。事件的展开,不仅是舆论建构的过程,也是情感激活和情感共鸣(即情感交流互动)的过程。
国外的相关研究,一部分学者从信息符合表征和信息系统的角度展开研究,如Buck等[7]将情感交流研究与麦克卢汉的媒体分析联系起来,指出麦克卢汉通过电子媒体识别出的整体认知过程,并非源于感官比例的模糊变化,而是源于符号传播的相对作用减少,以及电子媒体自发性情感交流的作用扩大。研究成果提供了一种替代机制,通过该机制可以理解比感官概念更能接受的“地球村”现象。同时,镜像神经元证据表明,通过视频和音频表示发送者的情感表现,听众可以直接理解发送者的感觉和愿望,电子媒体可促进亲社会、利他和同情的反应,以及促进仇恨和无情的反应。Nabi[8]研究了情感作为信息选择的动力,信息暴露的结果以及其他媒体效应机制,探讨了扩展媒体和情感影响的方式,并指出情感一直是面向媒体的传播重要部分,人们使用媒体来调节其情感状态。Rice等[9]研究了网络计算机传播形式,指出计算机介导的通信系统可以促进社交情感内容的适度交换,并可支持社会情感交流。系统之间的交流模式具有较强的连接性,且网络角色在社交情感内容上的比重通常没有差异。也有一部分学者从元认知和信息内容的角度展开研究,如Bartsch等[10]借助情感的评估理论,提出了一种元情感和情绪调节的过程模型,将元情感理解为一种监视和评估情感,并激活情感的反应过程,从而激发维持和产生情感以及控制或避免情感的动机。这种元情感过程在媒体用户选择或拒绝特定媒体产品方面,以及在邀请其体验情感方面起着重要作用。该框架可整合先前不相关的情绪,并在指导媒体选择使用中发挥重要作用。Stepanov等[11]发现,基于所确定的情感陈述,有助于确定用户的情绪状态的对话,以便推荐如电影、视频、数字书或其他媒体内容作为用户的选择内容。用户可基于由媒体内容引起的情绪来对媒体内容进行评级,这些内容包括表情符号、文本消息等,并可以使用这些表情或文本来传达由媒体内容引起的情绪。Derks等[12]指出,有人认为在计算机介导的交流(computer-mediated communication,CMC)过程中,情感交流比在面对面(face to face,F2F)交流中困难得多。但通过对离散情绪和情绪表达以及自我披露或情绪风格的研究,发现没有证据表明CMC中比F2F中的情绪传播较低或个人参与程度较低。相反地,CMC中的情感交流比F2F更频繁、更明确。
2.2 信息级联与网络舆论
关于信息级联与网络舆论关系的研究,国内关于信息级联的研究,主要集中于信息级联的影响因素和影响路径而展开,如刘启华等[13]对在线购物环境下的信息级联进行了实证研究,获得了信息级联和在线口碑对产品销售影响的混合结果。董健等[14]通过捕获社交网络数据,发现信息级联大小分布遵循胖尾分布,信息的吸引力和影响力对级联大小分布具有重要影响。蔡国永等[15]通过对新浪微博的分析,将信息传播的级联模型引入标记传播树(la‐beled propagation tree,LPT),构建了一种“标签级联传播树(labeled cascad propagation tree,CALPT)”的信息级联模型。邓卫华等[16]研究了一个新浪虚拟社区中负面信息的从众行为,研究结果表明,负面信息的扩散会受到用户在其中形成级联的深度和广度的影响。
国外相关研究,一部分学者对其影响因素进行探索,如Lin等[17]分析了什么可能导致股票市场中信息级联通常的原因,研究表明,信息级联可能更多地与投资者的内在搜索成本结构有关,而不是与信息相关的因素有关。Anderson等[18]通过级联实验检验了从个人接收不完全信息,并按顺序进行公共决策,会导致行为的一致性。也有学者从信息级联的过程进行研究,如Kaneko[19]在混沌网络中研究了信息级联的过程。研究结果表明,在部分有序的状态下,簇的分裂和级联是同步平衡的,并在分叉参数的间隔内保持了边际稳定性。Romero等[20]调查了民意测试差异是否归因于信息级联效应,即后来的受访者采用了先前受访者的决策,表明在事件安排期间会发生级联效应。Tinati等[21]根据作者的编辑活动,回答和识别了与使用Wikipedia文章信息级联有关的问题,发现可以通过使用编辑活动在Wikipedia文章之间构建信息级联。另外,有一些学者则对信息级联的形成机理和演化机制进行探索,如Kim等[22]探讨了中心性对社交网络决策的社会影响,以及中心性如何导致市场中信息级联的行为,发现特征向量中心性与行为者信息级联在统计上存在显著相关,并指出在扩散初期,中心性的错误决策会严重导致的信息级联。在级联过程中,中心性的桥梁作用比其在关键位置的作用更具影响力。Li等[23]指出,在网络中只有一小部分信息趋向于变得非常流行,而其余信息仍然未被注意或迅速消失。这种典型的“长尾”现象在社交媒体中非常普遍,该现象即受到信息级联的影响。Eftekhar等[24]针对基于组的问题建构了一种精细的信息传播模型,形成了一种在该模型下具有影响力的组的算法以及一个粗粒度模型。Tong等[25]讨论了两种用户在城市范围内活动的信息决策,分析了级联子图的规模和范围、级联子图的结构特征、扩展树的拓扑属性和级联子图的出现频率,并提出了一种新的信息传播模型。
综上所述,一方面,过去研究主要集中于情感传播、信息级联和网络舆论的两两变量之间关系的分析,尚未存在将三个变量置于同一理论框架下,作为系统结构进行模型建构和分析。然而,情感传播、信息级联和网络舆论作为密切关联且具有内生性的变量,若两两变量进行单独分析或与其他变量建立不同的系统结构模型,进行分析所获得的结果可能存在较大差异。同时,针对网络突发事件,人们由于无法获得危机事件的确切信息,容易产生从众效应,导致信息级联行为。而由于网络社会人际关系的差序格局特征和网络信息传播的波纹效应,在网络突发事件中,人们在对信息的认知和接受上容易形成差序级联效应,导致人们对事件形成舆论偏差。因此,本文创新性提出了“信息差序级联”概念,并用于分析其在舆论偏差中的影响效应。另一方面,过去虽有关于变量间影响效应大小的研究,但尚未涉及对变量间的边际影响力进行更细致的分析,而通过边际效应的分析可以寻找到情感引导、级联监控和偏差纠正的最佳“投入-产出”效率的监管策略。基于此,本文将情感传播、信息差序级联和网络舆论置于同一理论框架下,作为系统结构进行模型建构,采用向量自回归和状态空间方法,分析内生变量间的脉冲响应和边际影响力,并借助面板数据模型分析各变量间影响效应在不同人口统计学群体间的差异性。
3 变量说明与数据收集
3.1 变量说明
舆论偏差:是指人们在认知自我、他人或外部环境时,常因自身或情境的因素,使得认知结果与客观真实出现偏差的失真现象。基于“情感词典+语义规则+机器学习”模式,结合卷积神经网络CNN(convolutional neural networks)模型,对突发事件网络舆论中的情感及认知等字符和图像进行识别、提取、分类,采用Fisher判别准则进行降维,并标注生成舆论偏差序列。运用循环神经网络RNN(recurrent neural network)模型及贝叶斯神经网络,对网络舆论中的认知词汇进行扩展计算和深度学习,并对数据进行训练和测试,计算即时舆论客观度权重、事后舆论客观值和舆论偏差系数。对于某一时间节点i,采用ei=|p i-p|对舆论偏差进行测量,其中ei表示舆论偏差;p i代表即时舆论客观度权重;p代表事后舆论客观值。对于事件整体舆论偏差,采用标准差公式

对其进行计算,其中,N代表时间节点总数[26]。
情感扩散:是指情绪载体通过所嵌入的社会网络进行传导和扩散,形成情感互动,并建立起特定情感关系的过程。基于“情感词典+语义规则+机器学习”模式,结合卷积神经网络CNN模型突发事件网络舆论中的情感字符和图像进行识别、提取、分类,采用Fisher判别准则进行降维,并标注生成情感序列。运用循环神经网络RNN模型和贝叶斯神经网络,对网络舆论中的情感词汇和认知词汇进行扩展计算和深度学习,并对数据进行训练和测试,计算情感字符权重、情感粒度、中值价值率及舆论偏差系数。根据传染病SIRS(susceptible-infec‐tious-recovered-susceptible)模型,采用f(e)=测量总体概率密度函数的扩散概率,其中,μ(x)为定义在(-∞,+∞)上的一个波雷尔可测函数,即情感扩散函数,c为大于0的常数,即窗宽;e代表可能出现的任一观测值[27]。根据分子扩散思想[28],正态扩散函数为μ(x)=并将该扩散函数代入f(e)函数中,可得母体概率密度函数f(e)正态扩散估计,即
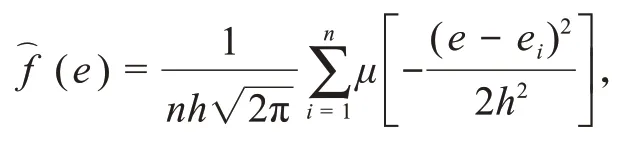
其中,h为经验窗宽,其值可根据择近原则导出。
差序级联:是指在网络差序格局中,用户认为他人所提供的信息比自身以其他方式获取的信息更具可信度和合理性,并忽略了自身所获得信息的可靠性,从而从众性地加入该类人群,并与所参照群体的认知保持一致[29]。差序级联的形成通常包括两步过程:首先,个人须处于决策性状态,且多为非此即彼的二维决策情境;其次,可通过观察他人行为或类似情景中的他人行为结果等外部因素来影响该决策。该过程的形成包括五个基本部分:①需做出决策;②存在非此即彼的有限决策空间;③人们按顺序做出决定,个体均可以观察早期行动者的选择;④个体均能获取自己所需的某些信息,有助于指导自身决策;⑤个体不能直接观察他人掌握的外部信息,但可从其所做的事情中推断出相关信息。在突发事件中,信息的转发与评论行为是用户在网络舆论中产生差序级联呈现的主要方式。针对某一时间节点,根据信息概率论理论,采用c=对差序级联进行计算,其中,p(A∪B)表示当评论或转发发生时的概率,当评论或转发时,取值为1;否则,为0。m为评论的次序级联概率;p为评论的内容级联概率;n为转发的次序级联概率;z为转发的内容级联概率。针对整个事件的差序级联系数,采用条件概率

其中,p(A|B)表示差序级联发生的情况下差序级联行为的概率[30]。
3.2 数据收集
3.2.1 样本选取
通过对我国于2015—2020年所发生的突发事件进行梳理和分析,以知名度、媒体报道程度、危机关注度、危机持续性、危机影响力以及危机破坏力6个维度作为选择标准[31],结合中央编办国家事业单位“舆情战略研究中心”历年发布的典型突发事件进行综合考量,最终确定选择11个具有代表性的突发事件,该样本涵盖了卫生、检法、汽车、交通、药品、幼儿、餐饮、医疗、酒店和教育等大多数领域。一方面,由于所选突发事件的综合影响力较大,且均为人们日常生活所接触,所涉及的领域均为公众所熟悉,并与公众具有较高关联性,因此,公众在事件舆论上的参与程度整体上相对较高,从而提高数据获取的效率及数据的有效性。另一方面,由于所选突发事件具有不同的性质,涉及教育、卫生和安全等不同主题,而不同主题的突发事件在舆论演化生命周期上存在一定差异。例如,有的突发事件舆论演化周期较短,有的突发事件舆论演化周期较长。为了保障数据获取时间长度的有效性,保证不同主题和不同性质的突发事件,在不同时间节点基本处于同一舆论阶段或同一生命周期,故在样本选取过程时,考虑了事件性质、事件重要性、涉及面等维度,并侧重于具有“特定”性质的突发事件,而不将具有“长期性”社会问题的事件纳入其中,其目的是保证事件舆情的发展、高潮和衰退周期长度的差异性较小,并降低数据有效时长出现严重差异化与舆情周期的严重不齐。其样本分布特征如表1所示。
3.2.2 数据获取
社交媒体的快速发展和应用,已使其成了人们进行信息获取和传播的重要途径,也成为了公众获取和扩散突发事件信息的重要方式和主要途径,因此,本文选取社交媒体作为突发事件网络舆论信息的获取平台。微博是当前主要的社交媒体平台,其数据的开放性和获取性相对其他社交媒体平台更为可行。国内较为成熟的微博平台主要有新浪微博、网易微博、搜狐微博以及腾讯微博。其中,新浪微博是当前运营最成功,使用规模、访问量、注册数和使用率均为最大的微博平台。中国互联网络信息中心(China Internet Network Information Center,CNNIC)发布的第44次《中国互联网络发展状况统计报告》(http://www.cac.gov.cn/2019-08/30/c_1124938750.htm)显示,自2013年开始,搜狐、网易、腾讯等公司对微博投入力度陆续减少,微博整体市场进入洗牌期。截至2015年6月,微博市场品牌竞争格局已经明朗,用户逐渐向新浪微博迁移和集中。其中,新浪微博用户占69.4%,一至五级城市的新浪微博使用率均在65%以上,全面超越其他微博运营商,新浪微博一家独大的格局已经基本确立和稳定。同时,根据2019年3月15日新浪微博数据中心发布的《2018微博用户发展报告》(https://data.weibo.com/re‐port/reportDetail?id=433),2018年第四季度财报显示,新浪微博月活跃用户4.62亿,连续3年增长超过7000万;微博垂直领域数量扩大至60个,月阅读量过百亿的领域达32个。因此,本研究选取新浪微博作为微博平台样本,能够较好地代表社交信息平台的特征和属性。
本研究采用网络爬虫技术对样本数据进行采集,在其数据抓取过程中,首先需要将站点中某一组需要访问的URL(uniform resource locator,统一资源定位符)设置为爬行起始地址,采用广度优先爬行策略对每个URL指向的页面信息进行抓取,并对页面中的内容进行解析,然后继续抽取下一个链接的URL进行页面爬取和解析,依次反复爬行,直至程序运行结束,从而实现对网络平台的相关页面信息进行抓取。
综合考虑各突发事件样本信息传播过程的有效时长,确定对各样本事件舆情的跟踪时间为21天,在数据搜集过程中,为了数据整理和表达的方便,对所获取的数据进行统一编号处理,对每一位用户及其转发的信息赋予唯一的ID编号。对数据进行清洗,包括对数据一致性、重复数据、无效数据、缺失值、错误数据等可识别的不符合要求的数据和文件进行审查、校验、纠正和处理。经过数据清洗后,共获得有效数据54793条,根据所爬取字节和内容进行识别、分析、提取和赋值,并计算形成包含情感扩散系数、信息差序级联系数以及舆论偏差系数三个变量的面板大数据。最后,形成两个数据集,即数据集1和数据集2。数据集1为所采集用户的具体资料信息,主要包含如下变量:用户ID、昵称、所在地、性别、创建时间、认证状态;数据集2为所采集用户的转发及内容、评论及内容、信息时间距离等数据资料,主要包含如下变量:YID(用户ID)、WID(微博ID)、ZF(是否转发)、PL(是否评论)、ZS(转发时间)、PS(评论时间)、SJ(信息时间距离)、PN(评论内容)、ZN(转发内容)、KS(情感扩散系数)、JL(差序级联系数)、PC(舆论偏差系数)。

表1 突发事件样本分布特征
4 模型构建
向量自回归模型(vector autoregression,VAR)是用于对多维时间序列中的一变量对另一变量动态影响分析的一种时滞性方法,是以每个变量的滞后项作为其他变量函数的自变量来建立模型,从而实现对变量间的相互扰动分析。在进行VAR模型构建前,需要进行Granger因果关系和稳定性的检验,以确定一组时间序列是否为另一组时间序列的原因,以及VAR模型在参数及结构设定上的正确性。
4.1 因果关系检验
对模型中的变量结构进行识别和检验,分析舆论偏差、情感扩散和信息差序级联之间是否存在显著性Granger因果关系,以确定VAR模型结构设定是否合理。对应的Granger因果检验结果如表2所示。

表2 Granger因果关系检验
由表2可见,在舆论偏差、情感扩散和信息差序级联的因果关系排除检验中,各变量及两两变量联合项的χ2检验对应的p值均小于0.05的显著水平,这表明可以拒绝不存在因果关系的原假设,即舆论偏差、情感扩散和信息差序级联间存在Grang‐er关系。因此,在VAR模型构建中将舆论偏差、情感扩散和信息差序级联作为内生变量的变量设置合理有效。
4.2 VAR模型构建
在Granger因果关系检验的基础上,为了进一步了解信息差序级联、情感扩散和舆论偏差之间影响的滞后时间长度,需对VAR模型进行统计分析和时滞长度判断。对应的统计结果如表3所示。

表3 时滞长度选择标准
根据LR(likelihood ratio)检验,以及FPE、AIC、SC、HQ信息准则最小化的标准,由表3可知,VAR模型的最佳时间滞后长度为2期。在上述因果关系检验和时滞特征分析基础上,对VAR模型进行设定和估计。其对应的模型形式为

其中,opinion为舆论偏差;emotion为情感扩散;infocascade为信息差序级联;k为内生变量滞后阶数;εi为随机误差项。
为了确定VAR模型构建和设定的正确性,需对构建的模型进行稳定性检验。该模型的单根稳定性检验结果显示,代表AR特征根倒数的模的点均落在单位圆内,这表明所构建的模型均满足稳定性条件,说明所设置的模型均正确,不需要重新构建。
以内生变量滞后2阶建构VAR模型,并对其进行模型估计,其结果如表4所示。

表4 VAR模型参数估计结果
由表4可知,VAR模型的3个方程中,各项系数显著性检验的|t|值均大于0.05显著水平对应的临界值1.96。同时,可决系数R2值均大于0.90,这表明所构建的VAR模型与样本数据拟合度良好,该估计结果可用于情感扩散、信息差序级联和舆论偏差之间动态影响的相关分析。
5 脉冲响应和波动分解
脉冲响应函数(impulse response function,IRF)是用来分析VAR模型的一种方法,也是VAR模型的重要组成部分,可分析VAR模型中各变量间受到外界冲击时,其他内生变量对该冲击所作出的响应情况,包括响应的大小、响应滞后长度、响应的动态过程等内容。
5.1 脉冲响应分析
为了揭示情感扩散、信息差序级联和舆论偏差之间的动态扰动特征,在VAR模型估计基础上,分别对情感扩散、信息差序级联和舆论偏差进行脉冲响应分析。此处采用残差协方差矩阵的Cholesky因子的逆来正交化进行估计,其函数形式为

其中,q=0,1,2,…;t=1,2,…,T;σvariable,jj=
由图1可知,在第一行脉冲图中,当情感扩散、信息差序级联与舆论偏差受到一个正向冲击时,该冲击迅速传导至舆论偏差,在三至四期后其响应值达到最大,且均为正值。情感扩散、信息差序级联和舆论偏差每次冲击带来的影响,在滞后第二期至第六期之间的影响效应较大,其后呈逐渐减弱趋势。在第二行脉冲图中,当情感扩散、信息差序级联和舆论偏差受到一个正向冲击时,信息差序级联和舆论偏差对情感扩散在滞后第二期及第十期内的影响效应较大,其后呈快速减弱。在第三行脉冲图中,当情感扩散、信息差序级联和舆论偏差受到一个正向冲击时,情感扩散的冲击和信息差序级联的自相关影响迅速对信息差序级联产生正向影响,且影响效应均较大。信息差序级联自相关滞后效应在滞后八期内的影响较大,其后快速减弱,并趋于零值。

图1 脉冲响应分析
5.2 波动贡献率分解
方差分解(variance decomposition)作为VAR模型中的重要组成部分,是用于分析VAR模型中某些相关内生变量的结构性冲击对特定内生变量变化贡献率的一种有效方法。为了比较情感扩散、信息差序级联和舆论偏差相互扰动效应的大小,从而识别出不同影响因素对情感扩散、信息差序级联和舆论偏差影响的重要程度,需在上述各影响因素动态扰动特征分析的基础上,分别对各因素的波动贡献率进行方差分解。情感扩散、信息差序级联和舆论偏差对应的相对方差贡献率(relative variance con‐tribution,RVC)算式为

由图2可知,在舆论偏差方差分解中,在前四期舆情偏差自相关的影响较大且快速下降,情感扩散和信息差序级联的影响相对较小且快速上升,各变量影响大小于滞后四期后均趋向平稳。情感扩散贡献率约为55%,信息差序级联贡献率约为38%,而舆论偏差自相关影响效应约为7%。在信息差序级联方差分解中,在前六期信息差序级联自相关的影响较大且快速下降,情感扩散和舆论偏差的影响相对较小且快速上升,各变量影响大小于滞后六期后均趋向平稳。情感扩散的贡献率约为62%,舆论偏差的贡献率约为22%,而信息差序级联自相关影响效应约为16%。在情感扩散方差分解中,在前五期情感扩散自相关的影响较大且快速下降,舆论偏差和信息差序级联的影响相对较小且快速上升,各变量影响大小于滞后五期后均趋向平稳。信息差序级联的贡献率约为53%,情感扩散自相关影响效应的贡献率约为28%,而舆论偏差约为19%。
6 影响力及群组分析
6.1 边际影响力
状态空间模型(state space model,SSM)是一类动态时域模型,是用于分析系统中各自变量每一单位数值对因变量影响效应的大小,即在某一时间内自变量对因变量产生的边际影响力的动态变化的过程,在数据分析层面和维度上则是对VAR模型的深化和补充,可实现变量间影响效应的单位性分解。在上述脉冲波动分析基础上,为了进一步了解情感扩散、信息差序级联和舆论偏差之间的边际影响力,使用状态空间模型对各变量之间边际影响力的变化过程进行分析,揭示情感扩散、信息差序级联和舆论偏差之间影响效应的波动过程特征。其对应的模型形式为

其中,测量方程中的解释变量为经协整检验后处于长期均衡关系的滞后第i阶的影响因子;ui1t为满足均值E(ui1t)=0和协方差矩阵var(ui1t)=Hi1t的连续不相关扰动项;εijt为满足均值E(εijt)=0和协方差矩阵var(εijt)=Hijt的连续不相关扰动项。其状态空间模型分析结果如图3~图5所示。

图2 方差分解分析

图3 舆论偏差边际影响分析

图4 信息差序级联边际影响分析

图5 情感扩散边际影响分析
图3结果显示,情感扩散对舆论偏差系数的边际影响力在事件发生的第一天约为0.3,当波动上升至第六期,边际影响力达到最大值约0.71,随后缓慢下降至第十四期边际影响力为0.2,接着持续缓慢下降并趋向于零值。信息差序级联对舆论偏差系数的边际影响力在事件发生的第一天约为0.17,当波动上升至第六期边际影响力达到最大值约0.38,随后缓慢下降至第十五期边际影响力为0.1,接着持续缓慢下降并趋向于零值。
图4结果显示,情感扩散对信息差序级联系数的边际影响力在事件发生的第一天约为0.28,当波动上升至第七期边际影响力达到最大值约0.57,随后缓慢下降至第十四期边际影响力为0.2,接着持续缓慢下降并趋向于零值。舆论偏差对信息差序级联系数的边际影响力在事件发生的第一天约为0.26,当波动上升至第三期边际影响力达到最大值约0.48,随后缓慢下降至第十四期边际影响力为0.1,接着持续缓慢下降并趋向于零值。
图5结果显示,舆论偏差对情感级联系数的边际影响力在事件发生的第一天约为0.13,当快速上升到第二期至第六期边际影响力达到最大值约0.49,随后缓慢下降至第十三期边际影响力为0.1,接着持续缓慢下降并趋向于零值。信息差序级联对情感扩散系数的边际影响力在事件发生的第一天约为0.4,当波动上升至第六期边际影响力达到最大值约0.6,随后缓慢下降至第十四期边际影响力为0.2,接着持续缓慢下降并趋向于零值。
6.2 群组分析
前文已对情感扩散、信息差序级联和舆论偏差间的脉冲响应与边际影响力进行分析,该分析主要从整体上探索各变量间的动态影响。然而,由于各类用户群体在社会角色与认知心理上的差异,导致不同性别、年龄和学历的群体在情感扩散、信息差序级联及舆论偏差之间的影响效应上存在差异。而面板数据模型分析作为时间序列与截面混合的数据分析方法,可进行时间维度差异及截面维度差异的详细分析,在数据分析维度上与VAR模型和SSM模型相互补充、相互深化,通过与VAR和SSM模型相结合对数据分析,可实现对数据在时间和截面维度上的全方位分析与比较。因此,为了探索不同用户群体间的差异性,采用面板数据模型对数据进行拟合和分析,对应模型为

统计值,并查阅F分布表,结果如表4所示。在opinion方程中,F2>F2临界值,且F1 使用Eviews 10.0计量软件对模型进行拟合,其拟合结果如表5所示。 从表5中的纵向结果数据来看,根据各变量系数大小,对于舆论偏差方程,情感扩散变量的系数β1值呈现出大于信息差序级联变量对应的系数γ1值。对于信息差序级联方程,情感扩散变量的系数β2值呈现出大于舆论偏差变量对应的系数γ2值。对于情感扩散方程,信息差序级联变量的系数β3值呈现出大于舆论偏差变量对应的系数γ3值。 从表5中的横向结果数据来看,对于舆论偏差方程,根据各变量系数大小,通过比较情感扩散变量的系数β1值及信息差序级联变量系数γ1值,结果显示:对于β1值及γ1值,在性别群组上,女性大于男性;在年龄群组上,29岁及以下群组最大,30~49岁群组较大,50岁及以上群组最小;在学历群组上,小学及以下群组最大,中学群组较大,大学及以上群组最小。 对于信息差序级联方程,对于情感扩散变量系数β2值,结果显示:在性别群组上,女性大于男性;在年龄群组上,29岁及以下群组最大,30~49岁群组较大,50岁及以上群组最小;在学历群组上,小学及以下群组最大,中学群组较大,大学及以上群组最小。但对于舆论偏差变量系数γ2值,在性别群组上,男性大于女性;在年龄群组上,50岁及以上群组最大,30~49岁群组较大,29岁及以下群组最小;在学历群组上,小学及以下群组最大,中学群组较大,大学及以上群组最小。 表5 群组面板模型拟合结果 为了保障群组差异分析结果的有效性,在上述群组分析基础上,需对各对应系数在不同群组间的差异性进行检验。其检验结果如表6所示。 表6 系数差异性检验 表6的系数差异性检验结果显示,舆论偏差、信息差序级联和情感扩散各方程在性别、年龄及学历群组上各对应系数的F检验结果在0.05水平下均显著,则拒绝“各组内相应系数相等”的原假设,表明舆论偏差、信息差序级联和情感扩散方程在性别、年龄及学历群组内各系数值不相等,即在群组内部的不同群体间存在显著性差异,表明上述相关群组分析结果有效。 本文从替换估计方法方面考虑模型估计结果的稳健性,在VAR模型脉冲响应分析时,前文采用了残差协方差矩阵的Cholesky因子的逆来正交化脉冲,该方法是通过给VAR模型的变量强加一个次序,并将所有影响变量的公共因素归结于VAR模型中第一次出现的变量上。现采用广义脉冲方法,即构建一个不依赖于VAR模型中变量次序的正交化的残差矩阵。在进行区域差异性分析时,采用工具变量的二阶段最小二乘法替代上述采用的最小二乘法对面板模型进行估计。 在状态空间模型中,其算法包括“Marquardt”和“BHHH(Brendt-Hall-Hall-Hausman)”估计方法。前文采用Marquardt进行估计,可以提供数值非线性最小化解决方案。该算法通过改变在执行过程中的参数,兼顾了Gauss-Newton和梯度下降法的优势,并改善了两者的缺点,如Gauss-Newton法的逆矩阵不存在或初始值与局部最小值相差太远。现采用BHHH算法,使用从上次迭代获得的参数拟合值来运算多元变量模型的残差项的方差与协方差矩阵,并运算新的搜索方向,以确定是否满足收敛的约束要求。若满足终止条件,则可获得参数的最佳估计;反之,则重新探寻步长λ和新的参数值β,并进行重新计算,以获得收敛的最佳算法。 采用上述替代方法进行模型拟合,考查模型拟合后各指标的显著性和各参数对应的拟合值,通过对比分析发现,采用替代方法估计后的各模型参数值在逻辑关系和逻辑结构上与初始所采用的指标建构的模型分析结果一致,表明上述建构的理论模型及分析结果具有良好的稳健性。 通过2015—2020年发生的具有代表性的11个突发事件面板大数据,探索了情感扩散、信息差序级联和舆论偏差之间动态影响,得出如下研究结论。 (1)当情感扩散、信息差序级联和舆论偏差受到一个正向冲击时,该冲击迅速传导至舆论偏差,舆论偏差的自相关滞后影响效应最大,情感扩散和信息差序级联对舆论偏差的冲击影响效应也较大,且情感扩散的影响大于信息差序级联的影响。情感扩散的自相关滞后效应和信息差序级联的冲击对情感扩散迅速产生影响,情感扩散的自相关滞后效应尤为明显。情感扩散的自相关滞后影响效应持续的时间较长,在事件舆论的整个演化过程中,其影响效应均较大。来自情感扩散和信息差序级联自相关效应的冲击会迅速对信息差序级联产生正向影响,且影响效应均较大,而舆论偏差冲击对信息差序级联的影响相对较弱,冲击效应不明显。其中,情感扩散冲击的影响尤为明显,且伴随着整个舆论演化过程。 关于信息差序级联对舆论偏差的影响,信息差序级联,发生于互联网时,在根据他人行为所提供的信息进行推断后,则认为他人行为释放的信息比自身以其他方式获取的信息觉得更可信和合理,进而选择从众性地加入该类群体行为。针对网络信息差序级联,其效应主要是人们易于忽略自身所获得信息的合理性,倾向于根据前人行为的推断而以此做出决策[32]。网络突发事件中,人们进行信息传播时,信息接收者通常难以直接观察到他人知道的外部信息,但可以从他人所做的事情中推断该类信息。仅通过对他人行为信息的推断而形成对事物的认知、判断和决策,易于受到事物表象的误导,从而产生认知偏差[33]。 关于情感扩散对信息差序级联和舆论偏差的影响,ELM(elaboration likelihood model)模型指出,人们态度的变化会受到信息论点的质量、外围线索及详尽可能性的影响,并将人们对信息的加工过程划分为中心路径和边缘路径。在边缘路径中,用户被说服程度与信息刺激中包含的正面或负面暗示线索相关联;在信息加工过程中,个人是对其所主张的立场信号进行简单推断[34],边缘路径加工则易于产生认知偏差。有限理性理论指出,大多数人只是部分理性,在这些人的其余行为中是非理性的,人们在制定和解决复杂问题以及处理信息方面(接收、存储、检索、传输)会受到多种因素限制。通常在个人做出决策时,其理性会受到决策问题的易处理性、思维的认知局限性和需做出决策的时间压力的限制和影响,从而行为主体寻求的是满意的决策,而非最佳解决方案[35]。其中,情感强度是人们认知中非理性差异的重要影响因素。因此,突发事件中,在有限理性作用下,人们的情感和情绪则促进了人们采用边缘路径对信息进行加工,从而对事物认知易于产生信息级联行为及偏差现象。 (2)情感扩散与信息差序级联对舆论偏差的边际影响力变化呈倒U形抛物线特征,在事件舆情的演化过程中,情感扩散对舆论偏差的边际影响效应显著大于信息差序级联的影响。情感扩散与舆论偏差对信息差序级联的边际影响力变化呈右偏分布抛物线特征,在事件舆情的演化过程中,情感扩散对信息差序级联的边际影响效应大于舆论偏差的影响。信息差序级联与舆论偏差对情感扩散的边际影响力变化呈右偏分布的抛物线特征,在事件舆情的演化过程中,信息差序级联对情感扩散的边际影响效应大于舆论偏差的影响。 关于情感扩散、信息差序级联和舆论偏差间的边际影响力均呈现抛物线特征,即当边际影响力达到一定数值后,呈递减特征。经济学的效应理论指出,事物给人们带来的效用是个体对事物消费行为的一种心理感受,消费某种物品可为主体带来一种心理刺激,使其获得某方面的满足感或能带来某种积极反应。边际效用递减规律强调,在消费初期,主体体验到的刺激较大,从而产生的满足感较强,并随着同一事物刺激的不断增加,个体在心理上的兴奋程度和满足感会随之逐渐增加,即随着消费数量的增加,其效用不断升高。但当该消费达到某一临界点时,随着消费数量的增加,其新增加的消费部分所带来的效用增长则呈逐渐减少趋势[36]。因此,在网络用户对突发事件信息的消费(即获取、认知及分享等行为)过程中,随着时间的推移,当该消费增长到某临界点时,其边际效用达到最大值;其后随着对信息消费的持续增加,用户获得的边际效用则会逐渐减小,即呈现倒U形抛物线特征。 (3)在整个舆论演化过程中,情感扩散对舆论偏差波动的贡献率最大,信息差序级联对舆论偏差波动的贡献率较大,而舆论偏差自相关影响效应最小。情感扩散对信息差序级联波动的贡献率最大,舆论偏差对信息差序级联波动的贡献率较大,而信息差序级联自相关影响效应最小。信息差序级联对情感扩散波动的贡献率最大,情感扩散自相关影响效应对情感扩散波动的贡献率较大,而舆论偏差对情感扩散的影响效应最小。在影响因素贡献率分解中,情感扩散对舆论偏差波动的贡献率大于信息差序级联的贡献率,情感扩散对信息差序级联波动的贡献率大于舆论偏差的贡献率,信息差序级联对情感扩散波动的贡献率大于舆论偏差的贡献率。情感扩散、信息差序级联和舆论偏差之间的相互影响效应在不同人口统计学群体间存在差异。 该研究结论对突发事件网络舆情治理具有启示意义:首先,在舆情治理和舆论偏差纠正过程中,应重点加强用户情感引导和情绪疏通的工作,尤其是在突发事件发生的初期,这是情绪引导和情感扩散控制的最佳时间。同时,降低因群体性集聚而引起的从众性信息差序级联,以及因客观信息披露不及时而导致的用户心理对未知不确定性而产生认知失调,引起小道消息的信息差序级联。通过情感疏导和信息差序级联管控,及时抢占网络舆论方向形成的主动权,降低舆论偏差的形成和放大。其次,通过对情感扩散的管控,既能降低舆论的偏差,也能减少信息差序级联形成的概率。通过对信息差序级联的管控,既能降低舆论的偏差,也能减小用户因情绪扩散而引起情感极化的风险。通过同时对突发事件中情感疏导和信息差序级联的管控,可较好的实现弱化情感传播、减少信息差序级联和降低舆论偏差三者间的良性循环,实现关键影响因素的源头性协同治理,大幅降低舆论偏差和舆情失控发生的风险和概率。最后,在舆情治理过程中,对舆情治理可采取受众细分策略,根据不同用户群体类型有针对性地采用不同的监控和管理措施。在进行情感引导、信息差序级联防控和舆论偏差监控过程中,在性别方面,加强对女性用户群体的重点监控,其次为男性群体;在年龄层面,重点加强对29岁及以下用户群体的引导和监管,其次为30~49岁的用户群体,最后为50岁及以上群体。

7 稳健性分析
8 结论与启示
猜你喜欢
心理学报(2022年7期)2022-07-09
核安全(2022年3期)2022-06-29
农业工程学报(2022年6期)2022-06-27
现代职业教育·高职高专(2022年16期)2022-05-05
——概念跨学科移用现象的分析与反思
西北农林科技大学学报(社会科学版)(2021年2期)2021-12-05
网络安全技术与应用(2019年5期)2019-06-05
汽车与新动力(2014年4期)2014-02-27
原子能科学技术(2011年10期)2011-07-30
电子设计应用(2004年9期)2004-09-17
