
基于动态语义网络分析的主题演化路径识别研究
2021-06-14 02:12倪兴兴刘家润曹晓丽王长天
情报学报 2021年5期
陈 翔,黄 璐,倪兴兴,刘家润,曹晓丽,王长天
(北京理工大学管理与经济学院,北京 100081)
1 引 言
主题演化路径识别是指通过对以词语为表征的研究主题在时间序列上的发展、变化趋势以及不同主题之间的交互作用进行跟踪分析,揭示技术领域发展脉络和演化规律的研究[1]。它可以帮助科研人员追溯具体学科领域的发展趋势,识别研究热点和可能的新知识增长点[2];也可以为政府和企业制定学科和领域发展规划提供重要的情报支持[3]。通常,主题的演化路径由“主题的前驱者—主题—主题的后继者”构成[4],主题间的演化关系可以用主题间的相似度来度量,当相似度大于一定的阈值则被认为存在演化关系,即不同主题在相邻时间段交界处存在新生、成长、衰减、合并、分裂以及衰亡六种演化方式[5]。
大量学者从网络分析和词频分析两方面入手开展主题演化路径识别研究,主要包括信息熵、引文分析、突发词分析和共词分析等方法[6]。近年来,基于关键词网络的主题演化路径识别方法被学者广泛使用[7]。例如,Katsurai等[8]构建了动态共词网络,对心理学领域的主题演化过程进行分析;侯剑华等[9]利用共词网络和聚类分析识别了我国哲学领域研究主题的演化过程。其中,如何准确识别关键主题是该类研究的核心[10],大量学者已开展相关研究。例如,Song等[11]学者使用马尔可夫随机场对关键词进行聚类进而识别主题;王曰芬等[12]使用LDA(Latent Dirichlet Allocation)模型识别出知识流领域的主题;张嶷等[13]采用主题词簇法通过词表清洗与合并、模糊语义处理等步骤对主题词表进行深度处理,解决了主题词表存在噪音和冗余的问题,实现了清洗、巩固主题词表的目的;有助于生成更有意义的核心聚类[14]。此外,社区发现算法逐渐兴起,展现出比传统聚类方法更大的优势[15],例如,Blondel等[16]提出的Fast Unfolding算法可在不事先确定主题数的情况下更准确地进行主题识别。
然而,当前研究还存在一些不足。首先,这些方法均假定关键词之间相互独立,未充分考虑关键词之间的语义关联关系[17],影响了关键词相似度分析的准确性。例如,关系密切的关键词对因没有共同出现在同一篇文献而被忽略。其次,传统主题演化路径识别研究往往凭经验或按照简单平均的方法对时间段进行划分,缺少科学依据。例如,时间段划分过长,大量主题在设定时间段内已完成演化;时间段划分过短,一个主题会被重复划分在多个时间段,导致主题割裂[9],均无法科学呈现主题间的演化关系。
为有效挖掘关键词之间的语义关系,准确识别领域中的热点主题及发展趋势,本文提出了基于动态网络分析的主题演化路径识别方法。首先,引入分段线性表示法(piecewiselinear representation,PLR)对时间段进行划分,并利用Word2Vec模型[18]构建动态关键词语义网络来体现关键词之间的语义联系;其次,利用Fast Unfolding社区发现算法识别动态网络中的社区,并基于Z-Score方法识别所有社区的主题标签以代表某领域的研究主题;最后,通过度量相邻时间段间的主题相似性来表现主题间的演化关系,进而识别主题的演化路径。本文以信息科学领域为例开展实证分析,并对方法的有效性进行了验证。
2 方法框架
本文的方法框架如图1所示,包括动态关键词语义网络构建、基于社区发现的主题识别、主题演化路径识别及可视化三大部分。
2.1 动态关键词语义网络构建
2.1.1 数据收集与预处理
本方法首先从WoS(Web of Science)中下载特定领域的文献数据,并利用文本挖掘软件Vantage‐Point①VantagePoint是面向文献计量数据(如科技论文、专利以及学术项目申请书等)的文本挖掘与可视化软件。更多详情请访问官网:https://www.thevantagepoint.com/抽取关键信息,包括关键词、标题、摘要以及年份;之后,对抽取的数据进行预处理,主要包括:去除标题及摘要中的乱码、去除带有乱码的关键词以及关键词中的XML标签等[5]。
2.1.2 基于分段线性表示法的时间段划分
本部分的目的是基于分段线性表示法对关键词序列进行时间段划分。首先,对关键词在等时间区间(月、季、年等)内的数量变化进行统计,得到一条有效的关键词数量序列,记为K={k1,k2,…,kt,…,kl},如图2a所示,其中,kt表示某研究领域在第t(1≤t≤l)时间区间内的关键词数量。在统计单位时间内的关键词数量时,为了清除噪声并使语义相同的关键词不被重复统计,本文利用主题词簇法[4]对关键词进行清洗(包括基于专家知识整合同义词、合并词干相同的词汇等)。

图1 基于动态网络分析的主题演化识别方法框架
其次,利用分段线性表示法将得到的关键词数量序列K拟合为首尾衔接的分段线性结构KPLR,如图2b中的折线所示。
这里,KPLR表示关键词数量统计序列K的分段线性结构,其表达式为

其中,Li(kti-1+1,kti-1+2,…,kti)表示KPLR中的第i(1≤i≤s)个线段,也是根据数据点kti-1+1,kti-1+2,…,kti拟合的线段(即趋势段),这条线段的起始时间为ti-1+1,终止时间为ti。
图2b中,折线的转折点便是本文要识别的趋势转折点,用TTP(trend turning points)表示,表达式为
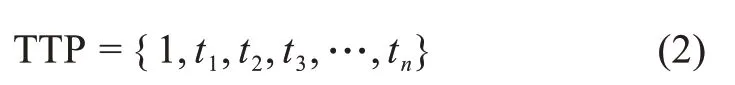

图2 分段线性表示法示意图
其中,t1表示第一个线段结束时的时间节点;t2表示第二个线段结束时的时间节点。这些时间节点标志着主题演化趋势开始发生转折,依据这些趋势转折点可以划分时间段,
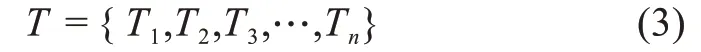
其中,T1表示起始时间点为1、终止时间点为t1的时间段;T2表示起始时间点为t1+1、终止时间点为t2的时间段;以此类推直到最后一个趋势转折点被划入时间段内。
在分段线性表示法中,表示分段数量的参数s的设置非常关键,s越小会忽略越多的局部波动数据,导致较大的整体拟合误差;而s越大保留的局部波动数据越多,引入的噪声也越多。本文参考了陈虹枢[19]的参数设置方法来平衡拟合的可靠性与趋势的可捕捉性。
首先,确定s的取值范围,求出每个s对应的均值根误差(root mean square error,RMSE)并存入均值根误差序列。在该序列中,随着s值的增大,均值根误差值不断减小。RMSE是用来衡量观测值与真值之间偏差的指标,可以更加直观地表现观测值对于真实值的拟合效果,本文用该指标来衡量分段线性拟合后的曲线与原曲线之间的误差,其计算公式为

其中,kt表示原曲线上t时刻的点;PLRt表示拟合后曲线上t时刻的点;N表示数据点的总个数。
其次,利用求导的方式,选取在RMSE不断减小过程中显著放缓的那一点,以其对应的s作为最优结果,即求出RMSE序列近似导数最大值所对应的s值。本文用sAD表示最优分段数,其计算公式为

2.1.3 基于Word2Vec的词向量获取
划分好时间段后,本文先对各时间段内的摘要和标题文本进行分句和分词处理,然后将分词后的语句序列作为语料库输入到待训练的Word2Vec模型中,并选用skip-gram模型对语料进行训练,最后,将得到的关键词通过训练好的Word2Vec模型映射为词向量。由于该词向量是基于关键词与上下文之间的关系得出的,既包含每个词从上位词继承来的公有属性,也包含自身的私有属性,可以体现关键词的多重语义信息[20]。Word2Vec模型训练过程如图3所示。
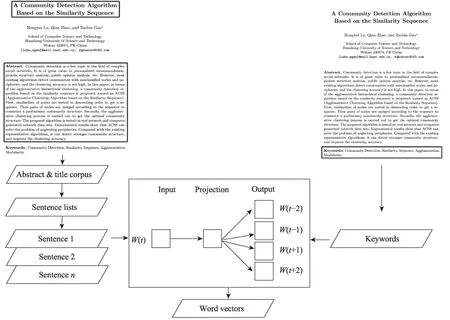
图3 Word2Vec模型训练示意图
2.1.4 构建动态关键词语义网络
本部分主要是构建动态关键词语义网络。首先,基于关键词的时间信息将抽取得到的关键词分到划分好的时间段内,并利用主题词簇法对每个时间段内的关键词进行清洗。
接下来,依次在各时间段内,利用清洗后的关键词与其对应的词向量构建关键词语义网络,构建过程阐述如下:
(1)定义某领域在时间段Ti内清洗后的关键词集为表示属于关键词集WTi的第i个关键词。
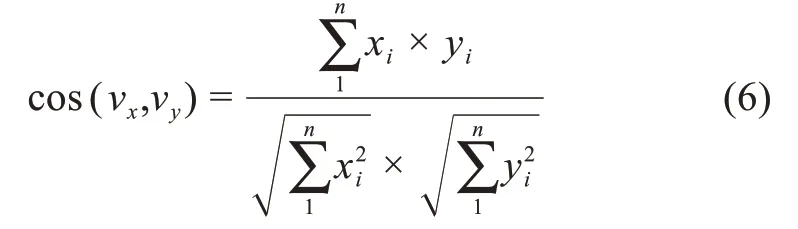
最后,所有时间段内的关键词语义网络组成了本文的动态语义网络G,计算公式为

其中,GTi为时间段Ti内的关键词语义网络。
2.2 基于社区发现的主题识别
本部分将识别动态关键词语义网络中的主题。首先,利用Fast Unfolding算法识别语义网络中的社区。Fast Unfolding是基于模块度最大化的社区发现算法,模块度是衡量社区划分效果的指标,可以度量社区内部连接的紧密度以及社区之间连接的稀疏度,模块度越大,社区划分的效果越好[21]。本文用R表示模块度,计算公式为

其中,A表示网络中所有连边的权重之和;Aij表示节点i和节点j之间的连边权重;Ni为节点i所有连边的权重之和,Nj为节点j所有连边的权重之和;δ(Mi,Mj)用来表示节点i和节点j是否在同一社区,如果在同一社区,取值为1,否则,取值为0。
为了避免弱关联和负关联(向量余弦值为负数)的关键词对在识别社区时引入噪声,本文参考曾庆田等[17]的研究对构建的关键词语义网络进行适当剪枝,去掉部分关系较弱关键词对之间的连边。本文将δ依次从0增至0.5(步长为0.05),利用Fast Unfolding算法识别δ对应剪枝后网络中的社区,并计算最后的模块度。这里,本文将模块度最大值对应的δ作为剪枝的阈值。识别出动态网络中的社区后,参考Wang等[4]的方法,利用Z-Score指标为每个社区的内部节点排序,选出Z-Score值最高的节点作为该社区的主题标签,计算公式为

其中,zi表示社区M中第i个节点的Z-Score值;N iM表示社区M的第i个节点与社区M其他节点连边的权重之和;M o表示社区M的节点数量;B表示社区M内所有节点与其他节点连边的权重和的总和;Q表示社区M中所有节点与其他节点连边的权重和的平方的总和。节点的Z-Score值越高,说明该节点与社区内其他节点的关系越紧密,越能代表整个社区。参考Guimerà等[22]的研究,Z-Score值大于等于2.5的节点可以作为社区的核心节点。
2.3 主题演化路径识别及可视化
本部分将识别主题的演化路径并进行可视化。首先,基于对应社区之间的相似度识别主题之间的演化关系。核心节点是社区内最具代表性的节点,也是社区发展变化的关键[4]。因此,本文利用核心节点度量社区之间的相似性,定义t+1时间段内的某个社区为Mt+1,t时间段内的某个社区为Mt,则Mt+1与Mt的相似度为HS(Mt,Mt+1),计算公式为
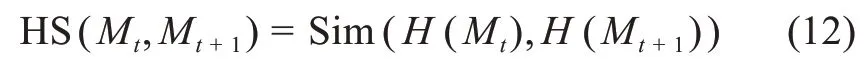
其中,H(Mt)表示Mt中核心关键词节点集,H(Mt+1)表示Mt+1中核心关键词节点集;Sim(H(Mt),H(Mt+1))表示H(Mt)与H(Mt+1)之间的相似度。
考虑到主题之间的相似度很大程度上依赖于主题之间的语义相似性,本文基于核心关键词节点的词向量,并利用关键词节点对应的Z-Score值赋予权重,采用向量余弦值加权平均的方法度量Sim(H(Mt),H(Mt+1))。为了统一量纲,本文对每个社区的Z-Score值进行标准化处理。以社区Mt为例,设该社区的核心关键词节点集H(Mt)中的某个关键词为Wt,则Wt对应的Z-Score值的标准化过程为
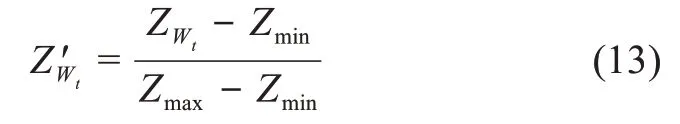
其中,Z'Wt表示关键词Wt对应的Z-Score标准化后的值,ZWt表示Wt对应的Z-Score值;Zmax表示标准化前H(M t)对应的Z-Score值中最大值,Zmin表示标准化前H(M t)对应的Z-Score值中最小值。
对Z-Score值标准化处理后,Sim(H(Mt),H(M t+1))的计算公式可以表示为

其中,Z't表示核心关键词节点集H(Mt)对应的Z-Score值标准化后的集合;表示H(Mt)对应标准化后的所有Z-Score值与H(Mt+1)对应标准化后的所有Z-Score值之间的两两乘积的总和;vWt表示Wt由Word2Vec模型映射后的词向量;cos(vWt,vWt+1)则表示向量v Wt与向量vWt+1之间的余弦值。
计算得到主题间的相似度后,可以剖析相邻时间段中两个主题之间的演化关系,即确定每个主题的前驱者与后继者,以及由“前驱者—主题—后继者”构成主题的演化路径。定义t+1时间段内的某个社区为Mt+1,它的前驱者为Pre(Mt+1),则Mt+1为Pre(Mt+1)的后继者,Pre(Mt+1)的表达式定义为

其中,Gt表示t时间段内的关键词语义网络;Mt表示Gt中的某个社区;δ为人工设定的阈值。
最后,对整个领域的主题演化路径进行可视化。本文以矩形代表主题,矩形上的文字代表主题标签,矩形的高度与主题对应社区的节点数量成正比,且同一时间段内的主题按照矩形的高度从大到小排成一列。再利用一条从前驱者指向主题的弧线表示主题间的演化关系,弧线上标出两个主题之间的相似度,不存在演化关系的主题将被描绘成浅灰色,演化路径示意图如图4所示。
具体来看,t-1时间段内的主题A与C是t时间段内主题D的前驱者,弧线上标了主题间的相似度,t+1时间段的主题F是t时间段内主题D的后继者。t+1时间段内的主题H与其他主题不存在演化关系。
根据学者Palla[23]的研究,社区的发展过程可以分为六种模式:新生、成长、合并、衰减、分裂以及衰亡。
(1)新生:在t时间段内不存在的社区,在t+1时间段内出现。
(2)成长:在t时间段内存在的社区,继续在t+1时间段内存在且社区节点增多。
(3)合并:两个或者多个存在于t时间段内的社区在t+1时间段内合并为一个社区。
(4)衰减:在t时间段内存在的社区,继续在t+1时间段内存在且社区节点减少。
(5)分裂:存在于t时间段内的社区在t+1时间段内分裂成两个或者多个社区。
(6)衰亡:存在于t时间段内的社区在t+1时间段内消失。

图4 主题演化路径示意图
2.4 方法验证
本文设计了定性与定量相结合的验证方法。在定性验证部分,我们将本文的分析结果与权威期刊文献的结果进行了对比;在定量验证部分,本文既对比了分段线性表示法与平均时间划分法的分析结果,又将本方法与K-means和LDA两大方法在主题识别中的效果进行了比较,并将准确率、召回率和F1值作为评价指标[24],用来验证本方法的有效性。相关指标计算公式为

3 实证分析
信息科学是一门典型的交叉学科,近年来该领域文献增长迅速,新的科学概念大量涌现[25],这使得该学科的主题演化过程更加复杂,其主题演化路径识别研究更有意义。本文选择信息科学领域作为实证分析对象,参考Hou等[25]学者的最新研究确定了信息科学领域的9种期刊,从WoS下载了2010—2019年10108条文献数据,如表1所示。

表1 信息科学领域期刊文献统计
通过Vantage Point软件提取得到31523个作者关键词,去除带有乱码的关键词和XML标签后,获得31276个有效关键词;之后,将有效关键词按月份划分为120个关键词子集,利用主题词簇法进行清洗,得到一个随时间变化的关键词数量序列。这里,本文以2018年11月的关键词子集为例来演示清洗过程,如表2所示。

表2 2018年11月的关键词清洗步骤(主题词簇法)
接下来,本文利用分段线性表示法中常用的三种方法(滑动窗口法、自上而下法以及自下而上法),对关键词数量序列进行分段线性拟合,并将参数s的取值范围设置为2到20[19]。遵循第2.1.2节的分析步骤,可以得到三种方法对应的最优分段数目s及其对应的均值根误差RMSE。最后,利用综合加权平均法对三种方法的拟合结果进行评估。为统一量纲,本文对s及RMSE两个指标进行标准化处理,使其均处于0到1之间,标准化的过程为

其中,as表示某指标标准化后的值;ai表示该指标标准化前的值;amin表示所有指标的最小值;amax表示所有指标的最大值。然后,对标准化后的s和RMSE指标加权求和(本文认为这两个指标同等重要,权值均为0.5),并用作评估指标。三种方法的拟合结果如表3所示。

表3 三种分段线性表示法的分段拟合结果
为了平衡趋势可捕捉性和拟合可靠性,本文倾向于分段较少以及均值根误差较小的拟合方法[19],故选择了加权平均值最小的滑动窗口法(取值0.2301),该方法的拟合结果如图5所示。
这里,信息科学领域被划分为6个时间段,各个时间段的起始点与终止点如表4所示。
本案例中的关键词集中有大量短语,如“Infor‐mation Retrieval”“Citation Analysis”等,而Word2Vec模型不能直接得出这些短语的向量,因此,我们将短语形式的关键词转换为相应的驼峰形式进行模型训练,如将短语“network analysis”转换为“Net‐workAnalysis”,并将关键词通过训练好的Word2Vec模型映射为相应的词向量。这里,我们参考Wang等[26]的工作,将向量设置为300维,窗口大小设置为7,最小词频设置为3。之后,在每个时间段内构建关键词语义网络。首先,将关键词集进一步划分为6个时间段内的关键词子集,删除词频小于3的关键词(去除噪声关键词)并使用主题词簇法进行清洗,清洗后的各时间段的关键词数量如表5所示。

图5 关键词数量序列的分段线性拟合结果

表4 关键词数量序列的时间段

表5 各时间段内的关键词数量
其次,依次在每个时间段内计算关键词对应词向量之间的余弦值,并以余弦值作为元素构建关键词关系矩阵。基于此可得到6个关键词关系矩阵,作为关键词语义网络。由于篇幅原因,这里只展示2010/01-2012/04时间段部分关键词关系矩阵,如表6所示。
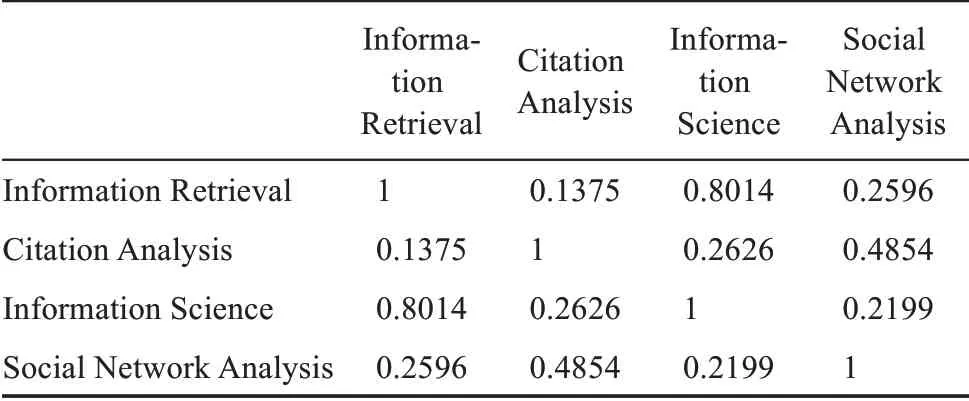
表6 2010/01-2012/04关键词关系矩阵(部分)
得到动态关键词语义网络后,利用Fast Unfold‐ing进行剪枝并识别网络中的社区,最终输出代表社区的关键词列表。整个动态网络共识别出154个社区,各时间段网络的剪枝阈值、社区数量以及对应的模块度如表7所示。
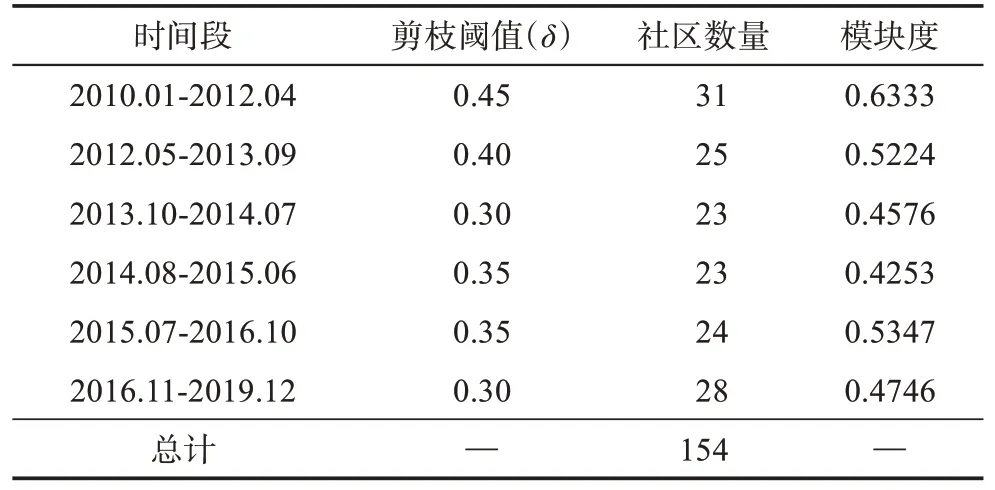
表7 各时间段内关键词语义网络的社区划分结果
这里需要为每个社区赋予主题标签。首先,利用Python语言为154个社区中的每个节点计算其相应的Z-Score值,选择社区中Z-Score值最大的节点作为该社区的主题标签,并以Z-Score值超过2.5的节点为该社区的核心节点。之后,基于社区的核心节点度量相邻时间段间的社区相似度,参考Schwartz等[27]的研究,将主题相似度阈值δ设为0.7,即相似度大于0.7的主题存在演化关系。图6显示了信息科学领域2010—2019年的主题演化路径图。
我们可以发现,近十年间信息科学领域存在明显的主题演化现象。例如,2013/10-2014/07时间段内的“Collaboration Analysis”(合作分析)、“Col‐laboration Network”(合作网络)、“Social Network Analysis”(社交网络分析)、“Co-authorship Net‐work”(合著网络)以及“Network Analysis”(网络分析)五个研究主题融合为2014/08-2015/06中的“Network Analysis”(网络分析),体现了主题合并;2013/10-2014/07时间段内的“Text Mining”(文本挖掘)主题分裂成2014/08-2015/06中的“Text Mining”与“Social Media Analysis”主题,体现了主题的分裂;又如,2016/11-2019/12时间段内产生了新的研究主题“Big Data”(大数据),2015/07-2016/10时间段内的“Epistemology”主题在2016/11-2019/12中消失,这体现了主题的新生与衰亡;同时,“Cita‐tion Analysis”(引文分析)贯穿了整个过程,其对应社区的大小也在不断发生改变,体现了主题的成长和衰减。

图6 信息科学领域主题演化路径图(2010—2019年)
基于图6所示结果,我们可将近十年信息科学领域的研究主题划分为计量、管理和技术三部分。①计量维度包括文献计量、信息计量、科学计量以及网络计量等定量化研究,如一直贯穿信息科学领域的“Citation Analysis”,以及演化过程中与其合并的“Academic Ranking”(学术排名)、“Author Ranking”(作者排名)等,它们是文献计量学中的常用方法,致力于对期刊、学者以及科学研究的影响性进行定量化评估。可以看出,定量化研究是信息科学领域的重要研究方向与必然趋势;②管理维度是管理学在信息科学领域进一步深化和拓展,如图中的“Knowledge Management”(知识管理)、“Document Management”(文档管理)及其演化出来的“Information Retrieval”(信息检索)等;③技术维度是指信息科学领域不断引入数学模型、计算机算法等工具展开新的研究,包括数学模型、深度学习等主题,如图中的“Text Mining”(文本挖掘)、“Text Clustering”(文本聚类)、“Machine Learning”(深度学习)以及“Scientific Model”(科学模型)等。该维度的主题是信息科学领域重要的新兴趋势,应当予以重视。
下面,我们以“Citation Analysis”研究主题相关演化路径(图7)为例进行重点探讨,并与权威期刊文献的分析结果进行对比验证。
从图7可以看出,2010/01-2012/04时间段中有“Citation Analysis”“Academic Ranking”“Journal Im‐pact Factor”(期刊影响因子)以及“Webometrics”(网络计量学)四个研究主题,在2012/05-2013/09时间段内融合为“Citation Analysis”,这说明越来越多的学术、期刊影响性以及网络计量学研究用到引文分析方法,使四个主题之间的关系越来越紧密,进而融合。我们的结论也与很多学者的研究相一致,例如,学者Vaio等[28]明确指出,引文分析是评估期刊和学术研究的重要工具,并用引文分析研究经济学相关期刊的排名;同时,2014/08-2015/06中的“Text Mining”主题融入2015/07-2016/10中的“Citation Analysis”,例如,学者Kralj等[29]明确提出通过结合文本挖掘技术与引文网络分析为研究问题带来了新视角,利用“Text Mining”构建新型的引文网络;此外,2014/08-2015/06时间段内的“Alt‐metrics”(替代计量学)和2015/07-2016/10的“So‐cial Media Analysis”(社交媒体分析)均融入了“Citation Analysis”,这表明基于网络媒体文本的新式计量学为“Citation Analysis”带来了“新鲜血液”,例如,学者Sud等[30]指出通过挖掘转发、评论等社交媒体关系可以准确地识别意见领袖。
接下来,本文采用传统的平均时间段划分法对主题演变的时间段进行划分,并对2010—2019年信息科学领域的主题演化路径进行描绘,结果如图8所示。可以明显看出,图8与图6相比丢失了很多主题,如图6中2012/05-2013/09时间段内的“Tech‐nological Transition”(技 术 转 型)、“Information Gain”(信息增益),2013/10-2014/07时间段内的“Citing Behavior”(引用行为)、“Concept Map”(概念图)以及2014/08-2015/06时间段内的“Technolo‐gy Policy”(技术政策)、“Knowledge Organization System”(知识组织系统)等主题均没有在图8中出现,这也进一步体现出本文提出的分段线性法的优越性。
我们还将本方法与K-means和LDA两类方法同时进行对比,以验证本文在主题识别上的有效性。参照林江豪等[24]的研究,我们首先依据信息科学领域专家意见建立一个标准“主题-关键词”集(标准集),作为各类方法分析结果的对照标准;其次,分别基于本文方法、K-means和LDA得出相应的关键词集,并把分析结果与标准集进行对比。由于篇幅原因,这里只展示部分结果,如表8所示。首先,我们邀请了5名信息科学领域专家从6个时间段内分别随机挑选2个主题,共得到12个研究主题(表8第2列);然后,由专家确定与主题对应的关键词集(表8的第3列);接下来,我们分别使用本文方法、K-means和LDA三种方法进行主题识别,结果如表8的第4~6列所示。
之后,我们以准确率、召回率和F1值作为评价指标将三种方法的分析结果与人工建立的标准集进行比较,对比结果如图9所示。
从图9可以看出,本文方法分析结果所在的值基本都在图的上部,这表明对于6个时间段内的12个主题,本文方法的3个验证指标值大多优于Kmeans和LDA方法,显示了本文提出的动态语义网络分析方法具有更好的主题识别效果。

图7 以“Citation Analysis”主题为主的演化路径图

图8 信息科学领域主题演化路径图(平均时间段划分法)

表8 主题词分析结果示例
4 结论与不足
本文提出了一种基于动态网路的主题演化路径识别方法,一方面,引入分段线性表示法对主题演变的时间段进行划分,解决了传统主题演化路径识别研究划分时间段不合理的问题;另一方面,基于Word2Vec模型构建动态网络,并利用社区发现算法在动态网络中识别主题,充分考虑了关键词之间的语义关系以使分析结果更加准确。
本研究也存在一些不足。首先,分段线性表示法仍可以继续改进,例如,最新的基于时序趋势的分段线性化算法,在数据集上展现了分段少、逼近性好等优点;其次,本文通过将短语形式的关键词转换为驼峰形式,对语料库中相应的关键词进行了替换处理,这样可能会因为改变语料库的文本结构而降低关键词向量识别的准确度,在未来的研究中可以考虑利用Phrase2Vec模型对关键词向量进行训练。

图9 主题识别的结果对比
猜你喜欢
山西大同大学学报(自然科学版)(2022年1期)2022-03-17
今日农业(2020年13期)2020-08-24
中学数学研究(江西)(2020年7期)2020-07-22
数学小灵通·3-4年级(2020年4期)2020-06-24
小学生学习指导(低年级)(2018年11期)2018-12-03
中学生数理化·高一版(2018年1期)2018-02-10
东方教育(2017年7期)2017-07-03
意林(2017年8期)2017-05-02
新东方英语(2016年11期)2016-11-11
太空探索(2016年9期)2016-07-12
