
弱监督对抗数据增强的细粒度视觉分类算法
2021-06-11 03:53司学飞张起贵
电子设计工程 2021年11期
司学飞,张起贵
(太原理工大学信息与计算机学院,山西晋中 030600)
细粒度视觉分类(FGVC)任务着重于将对象的子类别与同一类别区分开,例如鸟类、汽车和飞机模型。由于高级图像识别、智能农业技术、智能零售和智能交通等的广泛应用,近来FGVC 引起了广泛的关注。与传统的图像分类任务不同,FGVC 极具挑战性,仅靠最新的粗粒度卷积神经网络(CNN),例如VGG、ResNet 和Inception,很难获得准确的分类结果。正如最近的研究表明,FGVC 的关键步骤是在多个对象部位中提取更具区分性的局部特征。但是,很难定义对象的各个部分,并且各个对象之间的差异也很大。此外,标记这些对象的零件需要额外的人工费用。在这项工作中,文中利用弱监督学习,仅通过图像级注释来定位对象的区别性部位。文中不是关注区域边界框,而是通过卷积生成的注意力图来表示对象的部分或视觉模式。文中还提出利用双线性注意力模型和以对抗数据扩充为导向的数据增强方法来增强注意力集中过程。与其他本地化模型相比,该模型可以更轻松地定位大量对象部位(超过20 个),从而获得更好的性能。此外,还提出联合优化方法解决因自然图像的长尾分布[1]而导致的训练问题。
1 相关工作
1.1 细粒度视觉分类
细粒度视觉分类一直是计算机视觉领域研究的热门话题之一。为了解决大规模图像分类问题,提出了卷积神经网络(CNN)。但是经过研究发现,这些基本模型只能实现中等性能,如果没有特殊设计,其很难集中精力于目标部位的细微差别。
为了更多关注局部特征,许多方法都依赖于部位位置或属性的注释。Part R-CNN[2]扩展了R-CNN[3]来检测对象,并在几何先验条件下定位它们的部位,然后从姿势归一化表示中预测出细粒度的类别。文献[4]提出了一个反馈控制框架Deep LAC,以反向传播比对和分类错误进行本地化。为了减少大量的位置标注成本,仅通过图像级注释的方法引起人们的关注。文献[5-6]提出了双线性池化[5]和改进的双线性池化[6],其中使用外部乘积在每个位置组合了两个特征,并考虑了它们成对的相互作用。MPN-COV[7]通过矩阵平方改善了二阶合并,并实现了最新的准确性。
空间转换网络(ST-CNN)[8]旨在通过几何变换和图像对齐来实现准确的分类。该方法还可以同时定位目标的多个部位。文献[9]提出的递归注意卷积神经网络(RA-CNN)递归地预测一个关注区域的位置并提取相应的特征,而该方法仅关注一个局部部分,因此将3 个尺度特征(即目标的3 个部位)组合在一起,预测最终类别。文献[10]提出了MultiAttention CNN(MA-CNN),同时定位多个部位。但是,对象部位的数量有限(2或4),限制其准确性。文中提出了将注意力层与特征层结合起来的双线性注意力池,其注意力区域的数量更容易增加,并提高了分类准确性。
此外,在FGVC任务中引入了度量学习。文献[11]提出的多注意多类别(MAMC)损失将正特征拉近锚点,同时将负特征推开。文献[12]提出的PC 结合成对的混淆损失和交叉熵损失来学习具有更泛化的特征,从而防止过拟合。在该模型中,提出了注意力正则化损失来规则化注意力区域和相应的局部特征,从而提高了目标部分的定位和分类准确性。
1.2 数据增强
文中的数据增强方法专注于图像的空间增强。在此之前,已经提出了随机空间图像增强方法,例如图像裁剪和图像丢弃,并被证明可以有效地提高深度模型的鲁棒性。Maxdrop[13]的目的是删除最大激活的功能,以鼓励网络考虑不太突出的功能。缺点是Maxdrop 只能删除每个图像的一个区分区域,从而限制了性能。Hide-and-Seek[14]通过从训练图像中随机遮掩若干正方形区域来提高CNN 的鲁棒性。但是,很多擦除区域都是不相关的背景,否则可能会擦除整个对象,特别是对于较小的目标。为了克服这些问题,文中考虑了数据分配策略,提出对抗性数据增强,引用弱监督学习领域强有力的网络模型,生成对抗网络(Generative Adversarial Nets,GAN)以共同优化数据增强和深度模型训练,在线生成部位数据以提高深度模型的鲁棒性。
2 算法原理及联合优化
文中详述了该细粒度视觉分类算法的原理,包括弱监督的注意力学习,基于对抗性的数据增强和联合优化。该方法原理结构如图1 所示。
2.1 弱监督注意力学习
该模型的第一部分采用双线性注意力网络[15]。将特征图F与注意力图A进行逐元素相乘,生成M个部位特征图Fk,如图2 所示。
文中主干网络采用Inception v3,首先,分别生成特征图集和注意力图集。通过将每个注意力图与特征图逐元素相乘来生成部位特征图。然后,通过卷积提取特征,最终特征矩阵包含所有这些部位特征。

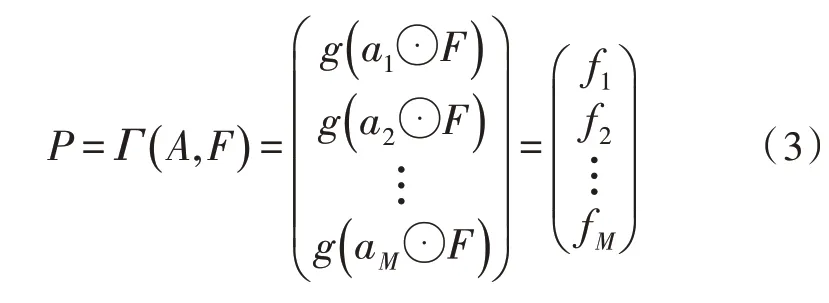
其中,⊙表示两个张量逐元素相乘。然后,通过特征提取函数g(·)进一步提取判别性局部特征,例如全局平均池化(GAP),全局最大池化(GMP)或卷积,以获取关注特征fk∈R1×N。
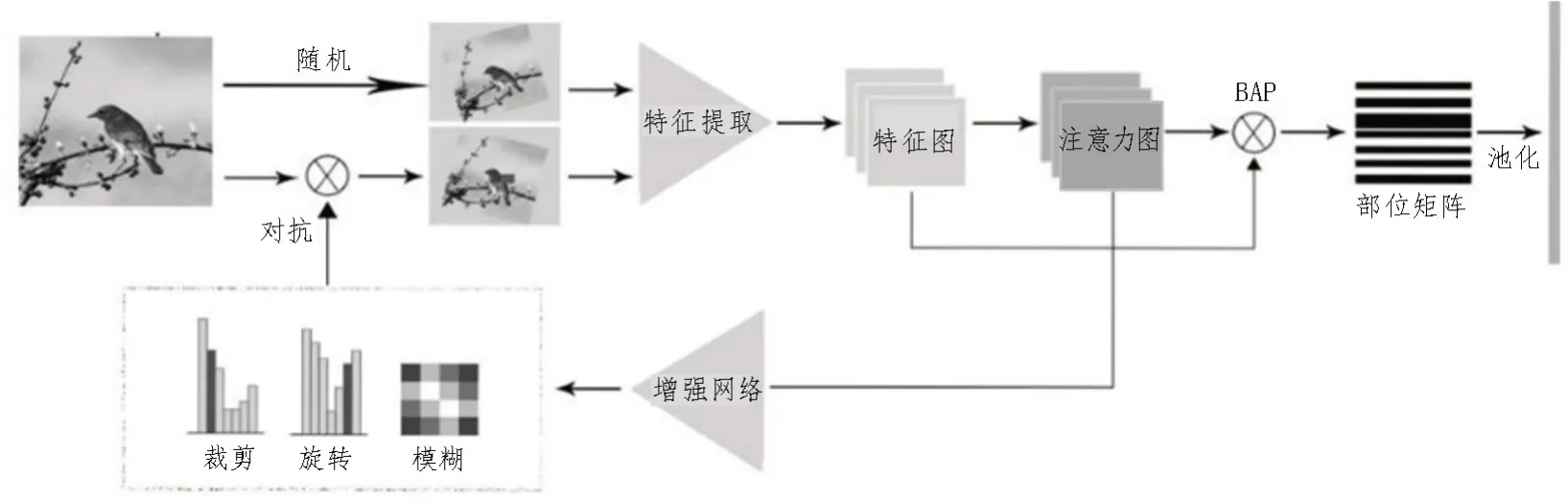
图1 整体原理图

图2 双线性注意力模型

目标的特征由部位特征矩阵P∈RM×N表示,它们是由部位特征fk堆叠而来。用Γ(A,F)表示注意力图A和特征图之间的双线性池化,其可用式(3)表示为:
2.2 对抗数据增强
从静态分布中采样的随机数据增强几乎不能遵循动态训练状态,可能会产生许多无效的变化,文中建议利用对抗学习共同优化数据扩充和网络培训。主要思想是学习一个生成“硬”增强的增强网络G(·|θG),可能会增加分类网络的损失。同时分类网络D(·|θG) 尝试从对抗性增强中学习,同时评估质量。生成器充当增强网络,输出一组扩充操作。在数学上,增强网络G通过最大化期望,输出对抗性增强τa(·)与随机对抗τr(·)相比可能增加D的损失。
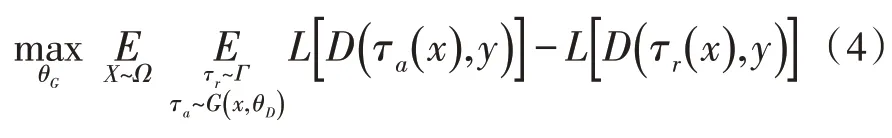
其中,Ω是训练图像集,Γ是随机增强空间,L(·,·)是预定义的损失函数,y是图像注释,G的生成要同时满足输入图像X和目标网络D的当前状态。
分类器充当鉴别器有两个作用:1)评估生成质量;2)通过最小化期望试图向对抗数据学习。
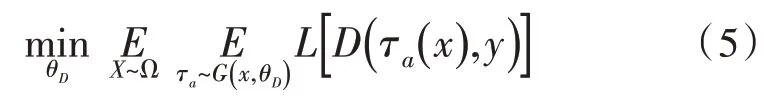
对抗性增强τa(·)可以比随机增强τr(·)更好地反映D的弱点,从而可以更高效地训练网络。
G和D的联合训练是一项艰巨的任务。增强操作通常是不可区分的,这会阻止梯度在反向传播中从D流动到G。为解决此问题,提出了奖励和惩罚策略来创建G的基本信息。因此,可以随时更新G以遵循D的训练状态。
2.2.1 对抗策略
预训练增强网络非常关键,这样它才能在联合训练之前获得增强分布感。对于每个训练图像,总共采样m×n个增强,每个增强都来自一对高斯。然后,将增强转发到目标网络以计算损失,该损失表示增强的“难度”。将m×n的损失累积到相应的缩放和旋转箱中。通过将bin 的总和标准化为1,生成两个概率向量:Pm∈Rm和Pr∈Rn,分别逼近缩放比例和旋转分布的真值。
除了缩放和旋转外,增强网络更重要的是生成遮挡操作,细粒度识别目标部位的位置彼此高度相关。通过遮挡图像的某些部分,可以激励特征提取网络学习可见部分和不可见部位更牢固的关系。与旋转和缩放不同,要遮挡深层特征而不是图像像素。具体地,增强网络生成指示,要遮挡特征的哪一部分的掩码,从而使主干网络具有更多的估计误差。遮挡块以最低分辨率生成,然后按比例放大,以应用于主干网络的特征提取层。
2.2.2 奖惩策略
奖励和惩罚策略的核心思想是,根据目标网络的当前状态来更新增强网络的预测,同时通过对比参考评估其质量。为每个图像采样了一对增强:对抗增强τa和随机增强τr。如果对抗增强比随机增强难,将通过增加采样bin 或旋转缩放的概率来奖励增强网络。否则,将通过相应地降低概率来惩罚它。用公式表现出来,令表示增强网络的预测分布,P∈Rk表示要寻找的真实分布。k是旋转或裁剪的数量,i是采样数量。如果对抗性增强τa与参考值τr相比造成更高的目标网络损失,通过奖励更新P:

相反,如果τa比τr导致更低的目标网络损失将通过惩罚更新P:

其中,0<α,β≤1 是控制奖励和惩罚量的超参数。增强网络不断在线更新,而不受奖励或惩罚,从而产生旨在增强目标网络的对抗性增强。
联合训练流程如算法1、2 所示。
算法1:小批量训练方案
输入:小批量X,增强网络G,判别网络D
输出:G,D
1)将X随机等分为X1、X2、X3;
2)使用X1训练D;
从格拉斯哥到盎散克之旅显然是虚无的,从象征意义上来说,所谓的空间转换根本不存在,盎散克就是格拉斯哥,或者说是格拉斯哥的反乌托邦版本。贫困、失业、疾病、压迫和衰落,这些困扰格拉斯哥的社会问题在盎散克同样存在,甚至被加以夸大变形,正如科林·曼罗夫所说的那样,“它关注的都是大城市的问题:政治、社会、艺术和权力机构。”(Manlove 1994:198)
3)根据算法2 使用X2对G和D进行对抗性缩放和旋转训练;
4)根据算法2 使用X3对G和D进行对抗性分层遮挡训练。
算法2:单个图像训练方案
输入:图像X,增强网络G,判别网络D
输出:G,D
1)前向学习D获得网桥特征f;
2)根据f前向学习G得到分布P;
3)从P中采样一个对抗性增强
5)随机增强x得到
8)更新D。
2.3 网络结构
传统意义上,通过输入层即前馈网络的第一层如图3(a)所示,将潜在分布提供给生成器。文中完全省略了输入层,而是从一个学习到的常量开始,从而偏离了这种设计如图3(b)所示。给定一个在潜在输入空间Z中的潜在分布z,一个非线性映射网络f:Z→W首先产生w∈W(图1(b),左)。为了简单起见,设置了两者的维数在512 之内,并且映射f是使用8层MLP 实现的。综合网络g由18 层组成,每种分辨率为两层(42-1 0242)。使用单独的1×1 卷积将最后一层的输出转换为RGB。
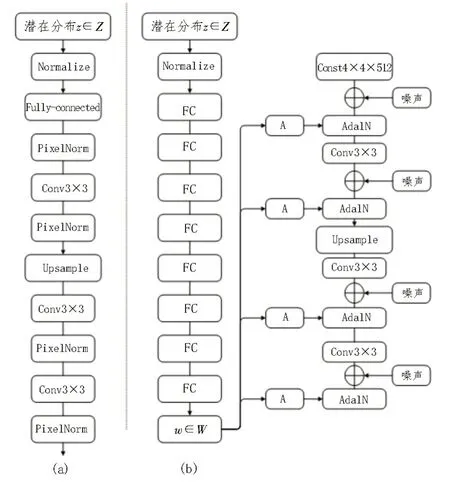
图3 增强网络结构图
3 实 验
3.1 数据集及实验设置
文中在CUB-200-2011、Stanford Cars 和FGVC Aircraft 数据集上全面评估了算法性能,表1 中显示了3 个数据集的统计信息。
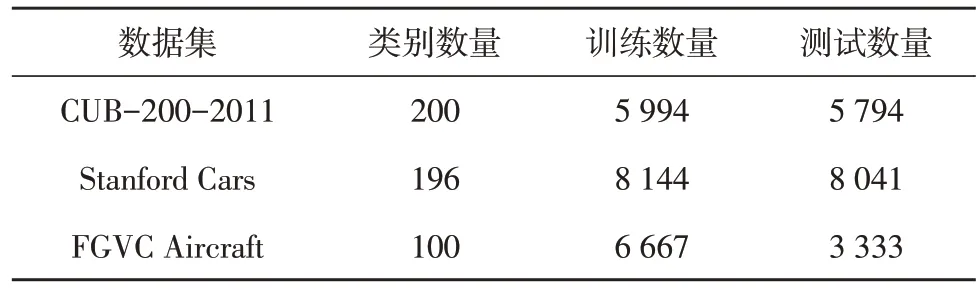
表1 数据集参数设置
使用PyTorch 框架进行实验,GPU 型号为GTX1080Ti。选择Mix6e 图层作为特征图。注意,图是通过1×1 卷积核获得的。采用GAP 作为特征池函数g(·)。RMSProp[16-18]用于优化网络。对图像进行预处理,将注意力图的聚焦点M初设为3。对抗训练包括3 个阶段。首先,训练鉴别器的几个纪元,学习速率为0.000 25。然后,冻结鉴别器,并使用它训练学习率为0.000 25的裁剪旋转网络和遮挡网络。一旦对它们进行了预训练,就将这两个网络的学习率降低到0.000 05,并共同训练这3 个网络。验证精度达到稳定水平后,主干网络的学习率下降到0.000 05。
在CUB-200-2011 数据集上对去掉增强网络的主干网络进行单独训练。主干网络以Inception v3 为骨干,使用随机梯度下降(SGD)训练模型,其动量为0.9,迭代次数为80,重量衰减为0.000 01,最小批量为16。初始学习率设置为0.001,每两个周期后指数衰减为0.9。
3.2 对比实验及分析
首先,对比具有增强网络的完备模型和原始模型在3 个数据集上的训练过程中,不同时期对测试集图像产生的平均注意力图数量M的变化,并进行了实验。如图4 所示,随着训练时长的增加,原始模型可在图像上学习到的平均最多聚焦点为15个,完备模型在增强网络的激励下可将平均最大聚焦点个数提升至32个,甚至更高。说明该模型可以挖掘更多图像的区别特征。然后,在Stanford Cars 数据集上进行了关于注意图数量M有效性的实验,表2 显示随着M的增加,分类准确率也会提高。当M达到32时,性能逐渐趋于稳定,准确率达93.2%。特征池模型使得设置任意数量的对象部分变得很容易。可以通过增加注意力图的数量来获得更准确的结果。再对比了文中方法与现有一些方法的准确性,并分析衡量了该模型的性能。

图4 两种模型生成注意力图数量对比

表2 注意力图数量的影响评估
如表3 所示,通过对比可知,文中方法在CUB-200-2011 和FGVC-Aircraft 这两个数据集上的表现优于现有方法,在Stanford Cars 上的表现接近现有最先进方法的精度。总体而言,文中的方法在细粒度视觉分类任务中表现良好,具有较高的性能。同时,通过对实验流程的监控,发现在增强网络的鼓励下,主干网络注意力图的聚焦点M由初始值3 最大可增加至32。说明该方法可以使网络关注更多的图像部位特征。由于鉴别器是通过随机数据增强进行预训练的。然而,随着训练的继续,分布变得更平坦,这意味着增强网络可以跟踪目标网络的训练状态,并生成有效的数据增强。
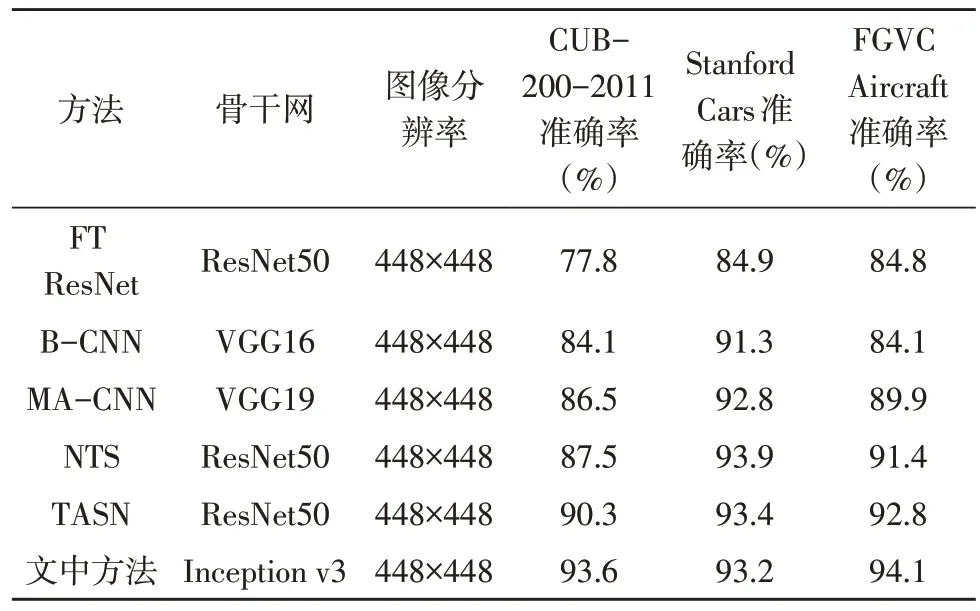
表3 文中方法与已有方法准确率对比
3.3 数据增强可视化
如图5 所示,在CUB-200-2011 和Stanford Cars数据集中通过随机数据增强和注意力引导数据增强来可视化增强的图像。直观地说,随机数据扩充在训练数据中引入了很多背景。注意引导的数据增强由于对象部件位置的引导而在裁剪或删除时更有效。
图5(a)中随机裁剪将包含比例较高的背景作为输入图像,注意裁剪能准确地定位物体的位置。图5(b)中注意力下降与随机下降比较。随机遮挡可能会从图像中擦除整个对象,或者只是擦除背景。注意遮挡对于擦除有区别的对象部分和促进多重注意更为有效。

图5 注意引导数据增强与随机数据增强实验结果对比
4 结论
文中提出了弱监督对抗数据增强网络。将弱监督学习与生成对抗网络(GAN)相结合。弱监督学习提供对象的空间分布,增强网络提供对抗数据扩充、鼓励主干网络的注意力学习过程。促进模型挖掘更多的具有图像区别性的部位特征,以此保证其优良的性能。在细粒度视觉分类方面达到了较高的准确率,但是联合训练的稳定性也是有待解决的问题。
猜你喜欢
红外技术(2022年11期)2022-11-25
红蜻蜓·低年级(2022年5期)2022-05-25
红蜻蜓·低年级(2022年5期)2022-05-11
小雪花·成长指南(2022年1期)2022-04-09
中华养生保健(2020年2期)2020-11-16
安阳工学院学报(2020年2期)2020-06-05
华人时刊(2018年23期)2018-03-21
电脑知识与技术(2017年26期)2017-11-20
传媒评论(2017年3期)2017-06-13
信息安全研究(2016年3期)2016-12-01
