
一种改进LSTM 训练的语音分离技术
2021-06-11 03:53郭佳敏李鸿燕
电子设计工程 2021年11期
郭佳敏,李鸿燕
(太原理工大学信息与计算机学院,山西太原 030024)
人耳可以轻易地将感兴趣的语音从背景噪声中分辨出来,为了使机器学会这一能力,文中将目标语音从背景噪声中有效地区分出来,即“鸡尾酒会问题”[1]。语音分离的主要任务是解决鸡尾酒会问题,并将其应用到实际场景中。随着人工智能、深度学习等相关知识的迅速发展,很多算法相继被提出。文献[2]将深度神经网络(Deep Neural Network,DNN)运用到语音分离的研究中,在大规模训练的基础上,使语音分离性能实现了显著的提升。文献[3]将深度神经网络的语音分离系统进一步优化,并取得了显著的效果。文献[4]将长短时记忆网络(Long Short-Term Memory,LSTM)运用到语音分离任务中,通过其记忆功能,能有效获取信号的上下文信息,提升语音分离的性能,相较于DNN,可以有效提升分离语音的短时可懂度指标,但在语音质量等其他方面表现欠佳。同时,由于其结构复杂,参数众多,计算复杂度较高,导致训练时间成本较大。文中通过简化长短时记忆网络模型结构和参数,使用门控循环单元(Gated Recurrent Unit,GRU)[5]缩短训练时间,降低了计算复杂度。
为实现系统语音分离性能的综合提升,根据人耳的掩蔽效应,针对信号的时频(Time Frequency,T-F)单元,结合注意力机制进行建模,并提出将噪声和语音主导T-F 单元分类方法与回归任务中常用的均方误差(Mean-Square Error,MSE)[6]相结合的方法,构建新的损失函数,对模型的训练过程进行优化,以获得性能更好的语音分离模型。
1 算法结构
图1 所示是语音分离算法结构框图。系统分为训练和测试两个阶段,根据算法各部分功能,各模块可归为数据处理和模型优化两个部分。其中,数据处理部分包括时频分解、目标计算和特征抽取。在训练阶段,数据由干净语音和噪声在固定信噪比下混合得到,通过时频分解后,提取混合语音特征作为输入,计算干净语音作为输出,通过大量的“特征-目标对”训练模型得到二者之间的映射关系,获得分离模型。在测试阶段,运用训练好的分离模型,将带噪语音通过时频分解、抽取特征值输入模型,获得估计的目标语音,进行性能测试。针对传统LSTM 语音分离系统中存在的问题,文中从分离模型的结构简化、输入优化和损失函数改进3 个方面出发,通过对原有算法的改进,最终达到提升语音分离性能的目的。
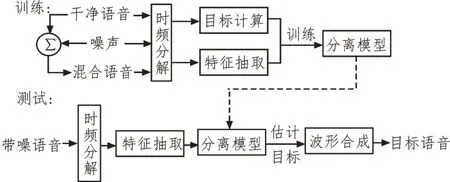
图1 语音分离系统结构框图
1.1 数据处理
1.1.1 时频分解
系统的时频分解部分采用短时傅里叶变换算法[7],将输入时间域的干净语音信号、噪声信号以及混合得到的带噪语音信号通过分帧、加窗、快速傅里叶变化转化为二维的时域信号:
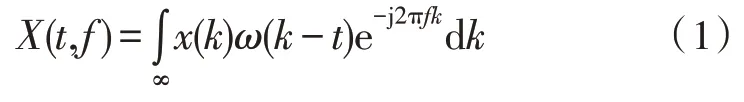
其中,ω(t)=ω(-t)是一个长度为N的实对称窗函数,每次移动N/2,X(t,f)是一维时域信号x(t)在第t个时间帧,f个频段的短时傅里叶变换系数。
1.1.2 目标计算
使用时频掩蔽可以很好地保留语音的共振峰特性,有效提高分离语音的可懂度,通过傅里叶逆变换可以直接合成目标语音分波形[8-9]。文中以理想二值掩蔽(Ideal Binary Mask,IBM)作为计算目标,信号在短时谱中语音能量大于噪声能量时值为1,否则为0:
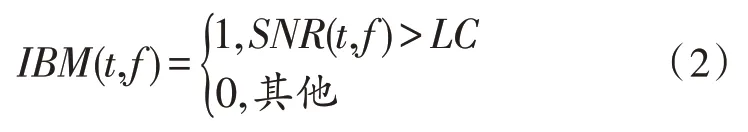
其中,LC是设定的局部阈值,SNR(t,f)是混合信号的信噪比。为更好地获得目标语音的能量谱,将LC设置为小于SNR(t,f)。
1.1.3 特征抽取
根据人耳的特性,提取混合语音信号的梅尔倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)[10],可以更好地展现语音感知特性的相对谱变换-感知 线性预测(Relative Spectral Transform-Perceptual Linear Prediction)[11]特征。提取的特征组合中包含了许多与目标语音无关的噪声信息,对语音分离的效果造成一定影响。
1.2 模型优化
1.2.1 模型结构优化
LSTM 作为一种时序模型,比起深度神经网络,在其隐层间增加了反馈连接,对时序信号的短时动态信息进行建模,使网络具备记忆功能。其输入门it用于控制当前时态输入xt是否融入当前细胞状态ct;输出门ot用于判断隐层向量ht对上一时间细胞状态ct-1部分的保留与否;遗忘门ft用于控制上一时间细胞状态ct-1是否影响当前细胞状态ct。细胞状态ct综合了每个时刻的当前输入xt和上一时刻细胞的状态ct-1。
如图2 所示,为简化LSTM 计算,保留了其核心功能,采用两个门结构的GRU,将细胞状态ct融入隐层向量ht中,输入门it和遗忘门ft合并,为更新门zt选择控制xt输入,重置门rt替换输出门ot。其前向计算原理如下:

图2 LSTM单元结构简化
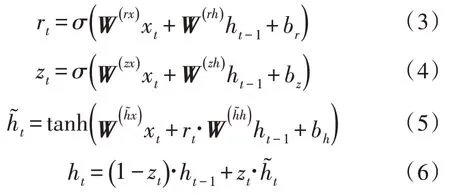
其中,σ(·)表示sigmoid 函数,W表示连接不同门的权重矩阵,表示隐层向量当前时刻的记忆候选向量。使用简化后的LSTM 单元构建网络,循环层沿时间反向传播,保留上下文信息,其循环的单元数随输入数据的时间长度变化,在每个时间点上将信息分别输出到下一个隐层。模型采用单循环层的结构,并通过两个全连接层调整数据的输出维度。循环层采用dropout 算法,各层间采用Batch Normalization 算法对网络训练过程进行优化。
1.2.2 模型输入的优化
针对抽取特征值无法避免噪声影响的问题,结合注意力机制原理以及人耳的掩蔽效应,对获得的语音特征进行筛选。根据人耳的掩蔽效应,弱的声音会被较强的声音覆盖,输入特征序列的T-F 单元可以被区分为由噪声或目标语音分别主导。对模型输入施加注意力机制,使模型输入更关注于目标语音主导的T-F 单元,使用Transformer 模型中的自注意力机制[12],计算T-F 单元之间的相似性,得到对应的注意力权重,从而获得可以弱化噪声影响的特征序列。
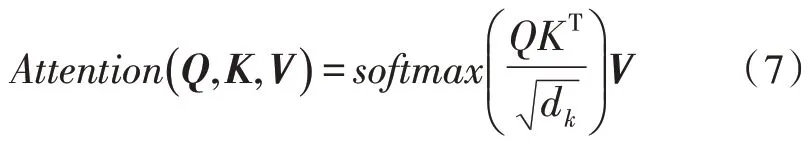
其中,Attention(·)表示一次注意力的计算过程,Q、K、V分别对应注意力机制计算中的元素内容矩阵、寻址矩阵和对应的值矩阵,dk表示矩阵K的维度。仅通过一次Attention计算无法很好地区分噪声和目标语音主导的时频单元,需要经过多次计算,获得叠加的权值系数。将输入矩阵映射到不同子空间,并采用缩放点积的形式对数据进行编码,即多头自注意力计算,从而实现对输入T-F 单元之间相似度的反复计算和权重叠加。
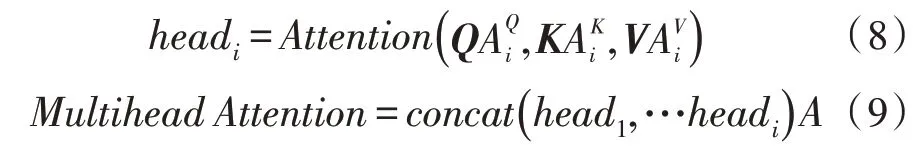
其中,headi对应输入的不同子空间,concat(·)表示对每个head的拼接计算,A表示注意力模型的权重参数。由于目标语音主导的单元数量在整个特征序列中占大多数,因此经过多头自注意力编码后的特征序列,可以加强目标语音在输入中的重要程度,对噪声实现有效的抑制,最终作为优化后的训练数据输入分离模型。
1.2.3 训练准则——损失函数的优化
使用IBM 作为目标时,语音分离任务可以自然地看作是0-1分类的问题,命中率减误报率(HIT-FA)可以直接作为语音性能评价指标,该指标与分离语音效果呈现正相关关系,可以客观地反映语音分离系统的性能[13]。通过直接比较干净语音理想二值掩蔽和模型估计的目标语音理想二值掩蔽,可得到命中率-误报率。
根据表1 所示的计算方式,并通过模型估计的二值掩蔽和理想二值掩蔽表示,HIT-FA可表示为:

表1 二值掩蔽评价指标计算表示方式
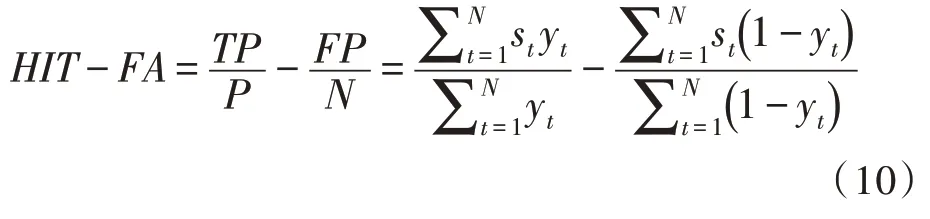
其中,st和yt分别对应当前时刻t混合语音经过模型估计得到的二值掩蔽和干净语音的理想二值掩蔽。HIT表示预测结果中,分类正确的目标语音主导T-F 单元在所有目标语音主导T-F 单元中所占的比例,HIT越大,对应的语音分离结果越好。FA计算的是预测结果中被错误分类为目标语音主导的噪声T-F 单元在全部噪声主导T-F 单元中所占的比重,FA越小,对应的语音分离结果越好。
在模型训练时,损失函数计算为模型估计值与理想输出之间的距离,为网络中每一个需要更新的权重找到对应的梯度,寻找最优解。MSE作为模型训练中最为常见的损失函数,在短时可懂度等方面具有较好的表现,但不能很好地匹配其他语音分离的评价指标。优化模型结构可以有效提高语音的可懂度,但在语音质量等方面表现出不平衡现象。以IBM 作为语音分离目标,可以自然地将语音分离任务转化为分类问题。通过对比几种不同损失函数对语音分离结果的影响,并根据HIT-FA的计算原理,将错误估计的噪声T-F 单元数量作为分子即FP,实际语音主导的T-F 单元数量作为分母即P,构成损失函数LH-F:
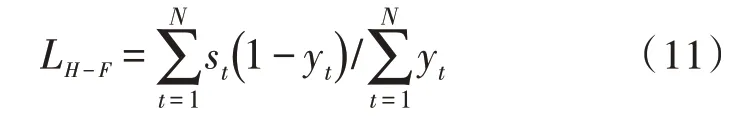
LH-F对估计为目标语音主导的T-F 单元进行判断,错误估计的单元数量越多,LH-F越大,通过训练使LH-F最小,从而抑制被噪声主导的时频单元对语音分离效果的影响。最小化LH-F可实现语音评价指标HIT-FA的最大化,但无法刻画预测值与真实值之间的差距。结合在STOI 等方面表现较好的MSE,其损失函数为:
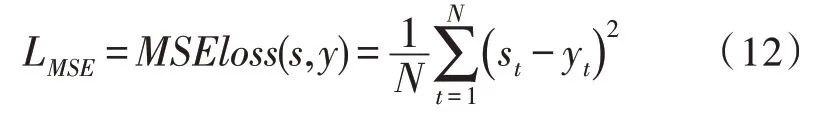
综合LH-F和LMSE的性能,在缩小预测值与真实值之间距离的同时,抑制噪声T-F 单元错误分类对结果的影响,提出一种新的损失函数L:
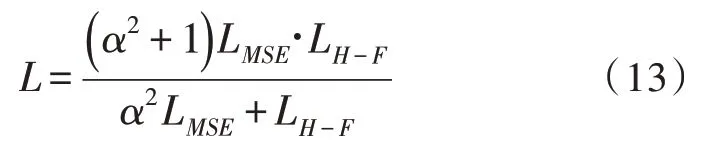
这里采用加权调和平均将二者融合构成新的损失函数,α大小反映函数LH-F在计算中的重要程度,α=1 时,表示两个函数同等重要,α设置越大,对应LH-F在计算中越重要。通过训练获取一个阈值,使二者同时实现最小化,以获得分离语音性能在HIT-FA和STOI方面的最佳表现,实现对模型训练过程的改进。
根据计算,自定义的损失函数L是可导可微的,满足自定义函数的条件。配合优化后的LSTM 网络,沿时间反向传播,通过适当的学习率lr实现梯度的下降迭代对模型参数进行更新,网络权值和偏差最终通过时间展开后积累得到。
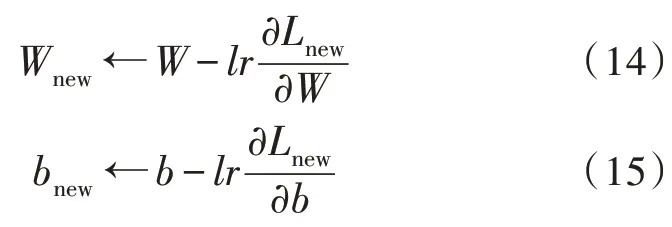
新的损失函数、学习率等参数的设置以及梯度下降优化算法的选择也影响着整个系统的性能。基于模型结构特点、训练速度等多方面因素,使用配合历史信息动量加速的随机梯度下降法(Stochastic Gradient Descent,SGD)、自适应学习率的RMSProp(Root Mean Square Prop)算法和Adam 算法3 种算法分别对训练过程进行优化。
在优化结构后的网络中,分别运用3 种不同的优化器算法对训练过程中的自定义损失函数进行可视化[14-20],如图3 所示,纵轴为损失函数值,横轴为迭代次数。同时观察训练过程,可验证该函数是否可以实现有效收敛。根据结果,自定的损失函数L在模型训练中可以实现有效的收敛。根据训练过程的损失函数值变化曲线的收敛速度和收敛效果来看,使用RMSProp 和Adam 算法进行优化的表现相当,对比训练过程中损失函数的最小值,最终选择RMSProp 算法对模型进行优化。
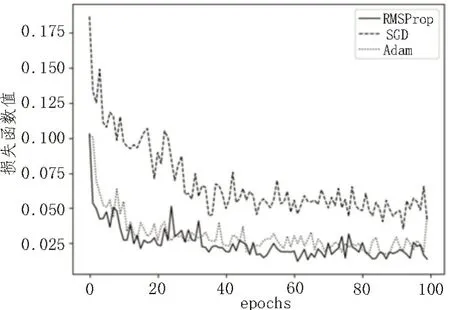
图3 SGD、RMSProp、Adam算法对比
2 实 验
2.1 实验配置
实验基于深度学习原理构建LSTM 的语音分离系统,并进一步优化。从语料库中抽取720 条干净语音及一种工厂噪声作为数据来源,分别在-2 dB、0 dB、2 dB 和5 dB 信噪比下生成600 条混合语音信号,用于模型训练,另生成120 条混合语音信号用于测试训练好的模型。为证明算法性能的提升,在相同实验环境下,使用传统的LSTM 语音分离系统同优化后的LSTM 语音分离系统进行对比。数据处理部分采用Matlab2016a 实现,包括对原始语音数据的混合处理以及时频分解,计算干净语音的IBM 和混合语音的特征值组合构成训练集和测试集。模型搭建、优化和损失函数的自定义通过Python 和Pytorch平台实现,同时利用TensorboardX 对整个训练过程进行监控。
测试中,为了可视化地对比语音分离的效果,计算处理后语音的短时包络相关性,使用短时客观可懂度指标(Short-Time Objective Intelligibility,STOI)作为客观语音清晰度指标,该指标取值范围在[0,1]之间,且值越大性能越好。同时,采用与语音主观评价MOS 值相关的语音质量感知评价指标(Perceptual Evaluation of Speech Quality,PESQ)对测试合成语音的质量性能进行评估测试,该指标取值范围在[-0.5,4.5]之间,值越大对应性能越好。同时,针对分类问题,使用模型分类精确度(Accuracy)和HIT-FA 对系统性能进行评估。此外,为缩短训练时间,实验训练过程使用GPU 进行加速。
2.2 实验结果
首先,为验证优化模型结构后性能的变化,分别使用优化前后的模型在-2 dB 信噪比条件下进行测试,并记录测试结果,如表2 所示。

表2 优化后的LSTM模型性能测试结果
分析表2 数据可以得出,相较于传统的LSTM 模型,优化结构后的LSTM 模型在简化计算后,各项性能指标均获得了一定的提升,并且在完成100 次迭代训练时,耗时缩短了约21%。可以得出,LSTM 经过优化后,仍然可以很好地保留语音的时序信息,使其在STOI 方面获得较明显的提升,且计算复杂度降低,训练速度更快,但在语音质量PESQ 方面表现仍有待提升。
为验证结合注意力机制在模型输入的改进是否有效,在不同信噪比条件下分别使用结合注意力机制改进前后的模型进行训练和测试,记录测试结果,并取平均值,如表3 所示。
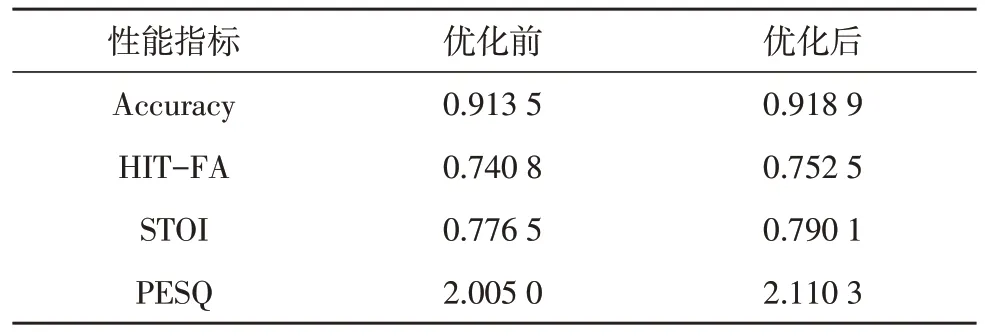
表3 结合注意力机制优化前后的模型性能测试结果
实验结果表明,优化模型输入后,各性能指标都得到了一定的提升。结合注意力机制对模型输入进行优化,通过计算T-F 单元之间的相似性,可以将训练的注意力集中在语音主导的T-F 单元上,有效抑制噪声在模型计算过程中的影响,实现各个语音分离性能的综合提升。
最后,使用提出的损失函数对分离性能提升的有效性进行验证。首先,确定L中α的取值,在2 dB信噪比条件下,分别取α=0.5、α=1 和α=2 进行训练,结果如表4 所示。
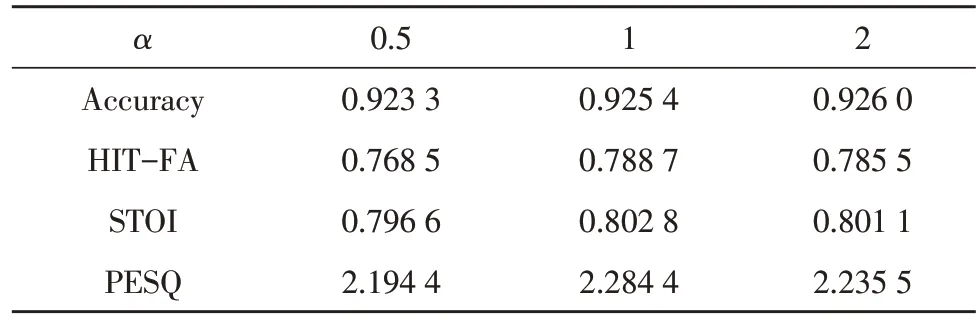
表4 不同α取值的测试结果
结果表明,取α=1 时,在训练中将L中的LH-F和LMSE计算视为同等重要,分离结果在Accuracy、HIT-FA、STOI 和PESQ 性能方面的表现较α=0.5 和α=2 时好。
令α=1,同时考虑其泛化性能,分别在-2 dB、0 dB、2 dB和5 dB信噪比条件下,使用式(12)与式(11)以及式(13)作为对比,在优化结构和输入后的模型中进行训练,测试分离语音性能,并记录实验结果,如图4 所示。
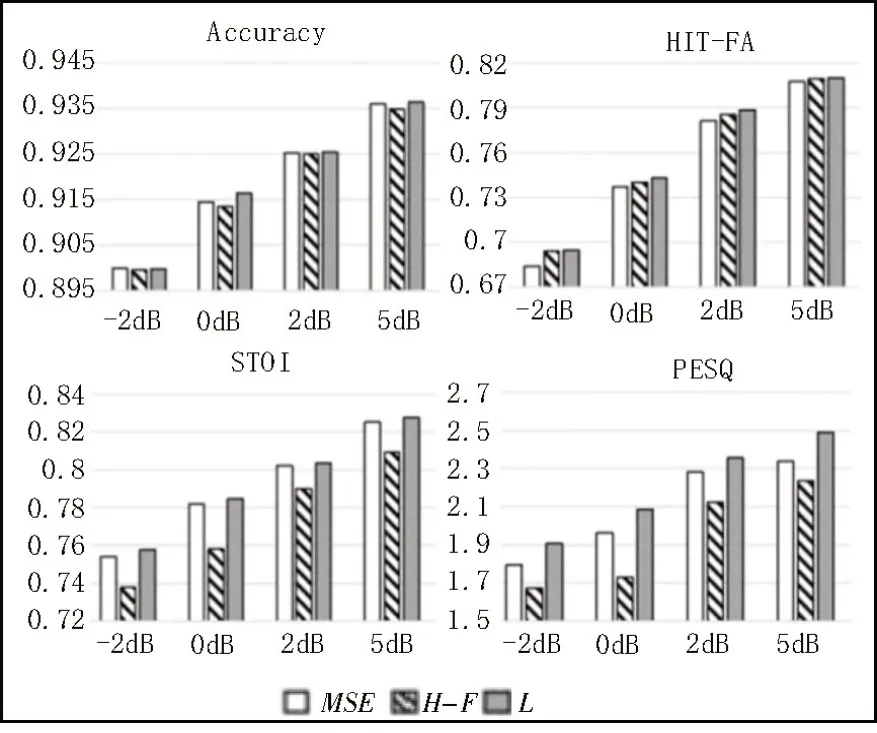
图4 损失函数对比测试结果
如图4 所示,根据训练提出的损失函数L,在Accuracy 方面的表现与单独训练LMSE损失和LH-F损失时大致相当。通过对HIT-FA 原理改进后,训练L得到的HIT-FA 指标性能相较于训练LMSE时获得较明显的提升。而且,由于HIT-FA 指标与主观听音测试存在正相关关系,因此通过其原理改进损失函数后,相较于两种损失函数单独训练时,在STOI 和PESQ 方面都表现出较好的性能。实验结果表明,提出的结合语音分离指标HIT-FA 改进均方误差构成的损失函数L不仅可以在训练中有效收敛,同时可以实现语音分离系统HIT-FA、STOI 和PESQ 性能方面的提升。
将优化后的语音分离系统算法与传统的LSTM语音分离系统作对比,取不同信噪比条件下分离语音结果的平均值,如图5 所示,文中构建的语音分离系统算法在Accuracy、HIT-FA、STOI 和PESQ 方面都获得了较好的表现,实现了对系统优化的目的。

图5 算法性能测试对比结果
3 结束语
文中将IBM 作为目标,采用LSTM 网络构建语音分离模型并进行优化,为实现训练时间的缩短,简化其单元结构,结合注意力机制对抽取的语音MFCC及RASTA-PLP 特征组合进一步优化,对输入特征中的噪声予以抑制,优化数据在训练过程中的计算,减少噪声对最终结果的影响。由于通过模型结构的优化无法实现系统综合性能的全面提升,提出一种新的损失函数对模型训练过程进行改进,将与语音评价指标HIT-FA 直接相关的函数与传统的MSE损失函数相结合运用到模型训练中,从而更好地匹配语音分离性能指标。为验证算法的泛化性,在不同信噪比条件下,将干净语音和噪声进行混合分别进行训练和测试。实验证明,从模型的单元结构和输入对传统LSTM 系统进行优化,实现了训练时间的缩短,同时结合注意力机制对模型输入进行优化,使训练过程中的计算更集中在目标语音上,系统各性能实现提升。最后,将提出的损失函数运用到训练中,可以更好地与语音分离各性能相匹配,实现系统性能的综合提升。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
数学年刊A辑(中文版)(2020年3期)2020-10-27
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
今日农业(2019年15期)2019-01-03
小说界(2018年5期)2018-11-26
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
