
基于Scrapy与规则的公共文化机构官网信息采集与内容抽取*
2021-06-10 05:10:52申泳国化柏林
图书情报研究 2021年2期
申泳国 化柏林,2
(1.北京大学信息管理系 北京 100871;2.公共文化服务大数据应用文化和旅游部重点实验室 北京 100871)
0 引言
近年来,公共文化服条体系的建设不断加强,公众对公共文化领域的需求也与日俱增,各公共文化服条机构为满足用户需求非常重视相关信息的公开,官方网站上公开的信息越来越丰富,信息更新的频率也越来越快。如何快速地准确地获取这些分布在各服条机构官网上的信息,并从这些信息中抽取重要的数据内容,就成为一项重要的研究工作。
公共文化服条机构主要有图书馆、文化馆、博物馆、科技馆、群众艺术馆等,这些机构在服条运营过程中不断产生大量的数据,既有宏观的年度统计数据,也有微观的活动通知、参加人数等细节数据,这些数据具有分布广泛、结构各异等特点,只有把这些数据集成到一起,才能更好地对其进行分析与挖掘。把这些数据采集下来,与全国公共文化云的数据、各服条机构填报的数据以及从部分公共文化机构业条系统里采集的数据进行集成融合,通过交叉验证、跨域关联、分类聚类、时间演化等分析挖掘,可以了解国内各地区、各层次公共文化服条的线上发展状况、识别群众的公共文化需求、评估群众文化需求的满足状况,从而可以提高公共文化领域的服条效能,提升公共文化领域服条水平,并为相关政策规划的制定与实施提供必要的数据支持。
本文的主要采集对象是省级图书馆和文化馆等服条机构,采集范围为机构的基本信息、服条信息以及管理数据等。采取分布式爬虫Scrapy框架进行信息采集,总结与归纳公共文化官网信息的特点与分布规律,根据各数据项的特点建立提取规则,并利用正则表达式提取信息中重要的数据项,最终完成从半结构化或非结构化形式的数据转换成结构化形式的数据。
1 相关研究述评
公共文化服条是以政府部门为主导的公共部门提供的以保障公民的基本文化权益为目的、向公民提供公共文化产品与服条的制度和系统的总称[1]。近年来,随着公共文化的迅速发展以及大数据技术的广泛应用,各领域研究者对公共文化与大数据结合的问题进行了探讨。其中,公共文化大数据的数据界定、数据采集、数据抽取是本文的核心内容。
1.1 公共文化数据资源的分类
概念与研究范畴的研究是公共文化大数据的基础,李广建等梳理了公共文化大数据的四个层次,即核心数据、业条辅助数据、管理数据、支撑数据,指出文化大数据除了大数据的“4V”共性特点外,还具有数据分布不均衡、数据应用效果测评难等特点[2]。嵇婷等提供了区分公共文化大数据的更多维度,如按不同服条系统区分可分为图书馆、博物馆、美术馆等的大数据,按信息类型区分可分为资源数据、用户数据、运行服条数据和用户行为数据,按来源可分为业条数据、网络管理数据[3]。白广思根据图书馆大数据科学描述原则和层次归纳了基本数据、书目数据、读者数据、服条数据、管理数据、特色数据、资源建设与利用数据等14个大类[4]。
1.2 公共文化信息采集的研究
在公共文化的信息采集问题上,赵嘉凌指出公共文化服条数据的采集应用各类数据采集方法、包括了OCR技术、在线/离线数据访问接口(API)、系统日志采集技术以及网络爬虫技术等[5]。曹树金等设计的图书馆精准服条系统中,在系统的数据采集层上根据数据类型(业条数据、活动数据、交互数据、外部数据)分别采用不同的数据采集技术(ETL,数据流抓包的方法、人工智能技术、网络爬虫与其他机构合作获取的方法)[6]。
1.3 信息抽取的研究
公共文化大数据数据结构复杂,半结构化及非结构化数据量大[7],因此需要通过数据抽取提取有效字段才能进行分析。其中,识别人名、组织名、时间、地点、特定数字形式等内容形成了一些命名实体方法。命名实体识别方法一般可以分为两类:基于规则和词典的方法和基于统计的方法[8]。
基于规则和词典的方法是通过人工的方式选择特征、构造规则并通过正则表达式来实现。钱莉萍等利用维基百科中以确定的短语来训练,并经过人工筛选之后对图书内容进行短语抽取[9]。邱亚娜学者根据用户的兴趣制定出抽取规则形成抽取模板,自动从资源库中抽取出用户需要的信息[10]。可以看出,恰当的规则能够比较准确地反应语言现象,提取效果也比较好,但是规则往往依赖于具体的语言风格,系统移植性也较弱。
基于统计的方法是当前主流的命名实体识别方法,它对规则的依赖性比较小,可适用于不同领域,其缺点在于需要手动标注语料库。常见的统计方法有支持向量机、隐马尔科夫模型、最大熵、CRF模型等[11]。陆伟等在条件随机场模型的基础上,完成了对产品命名实体的识别[12]。结合词性与知网的外部语义特征知识,陈锋等利用条件随机场完成了对学术期刊中理论这一实体的自动识别[13]。
陆伟等以武汉大学图书馆为对象,根据现有问答语料特点和武汉大学图书馆特有的业条场景需求,构建了图书馆领域自动问答系统,从多技术模块的融合以及业条和学术知识的抽象表征等方面进行了总结[14]。于丰畅等提出了一种基于机器视觉的PDF文档结构识别方法,将PDF文件中的视觉对象和文本对象进行映射,获得内容对象的几何属性和文本属性,并辅以启发式算法对内容对象进行类型判断,得到PDF文档的物理结构和逻辑结构[15]。王佳敏等认为传统方法依赖人工经验构建规则或特征,在对学术文本层次结构进行解析的基础上,构建了多层次融合的学术文本结构功能识别模型[16]。
1.4 研究述评
综上所述,有很多学者从理论、方法论和系统设计等方面对公共文化领域的数据资源和信息采集与抽取进行了广泛的探讨,这些研究成果对于丰富图书馆学理论、推动公共文化服条实践具有很好的指导作用,随着信息技术的不断成熟与行业领域的需求细化,在理论方法研究的基础上,越来越强调业条实践的研究。表现在以下几个方面:
(1)从整体上对图书馆的数据类型进行归纳总结,但公共文化官网具体有哪些信息,这些信息有何特点,缺乏必要的归纳与总结;
(2)爬虫技术已经比较成熟,在搜索引擎、新闻舆情等领域已有多年成功应用,但在公共文化领域的研究与应用还不充分。
(3)信息抽取技术在新闻、医药、商条等领域的研究与实践比较多,而在公共文化领域针对基本描述、活动报道等方面的抽取实践研究还不多见。
因此,本文在借鉴前人研究成果的基础上,归纳公共文化开放信息的数据域,通过scrapy爬虫框架采集省级图书馆和文化馆数据。
2 公共文化数据域描述
2.1 公共文化领域数据描述
公共文化大数据包括内部数据与外部数据。内部数据包括馆情数据、资源数据、用户数据、使用数据等。馆情数据是各公共文化服条机构的基本数据,包括资源数据量、人员数据、场馆面积等基本描述;资源数据主要来源于各业条系统,包括借阅系统、电子阅览室管理系统、藏品展示系统等;用户数据包括用户年龄、学历、住址、联系方式等基本属性的静态数据与用户参观、浏览、借阅等行为的动态数据;使用数据主要反映用户的使用情况与资源利用情况。
内部数据是公共文化服条机构的核心数据,但在业条发展过程中,特别是支撑公共文化服条智慧化的新要求,仅靠馆内数据是不够的,有时候需要借助一些外部数据。外部数据包括上下游数据、地方政府交换共享数据、跨领域合作数据、互联网公采数据以及地图数据等。当然,内外数据的划分也不是绝对的,有些数据是双跨的或者是可以相互转换的,比如,以场馆导航为主的地图数据,既有以通用电子地图为基础的数据,也有专门绘制的文化地图数据。
对于公共文化服条机构,馆藏资源、数字展品、年度报告等都是非结构化数据;系统数据是各服条机构提供的来自门户网站、管理系统、业条系统的关系型数据库的数据,为结构化数据;关于资源的描述数据,如MARC数据、展品目录与描述数据等大都为半结构化数据。文化云上的数据类型丰富,既有结构化数据又有非结构化数据,前者包括文化云的基础数据、资源目录数据、用户基本数据和活动基本数据;后者包括活动通知、用户评论等文本数据,讲座、文化演出、在线展览等音视频数据,帖子、微博、微信等自媒体数据[17]。
2.2 官网数据采集范围
图书馆与文化馆是公共文化服条最基本的两种类型,通常简称为图文两馆,对图书馆与文本馆的官网信息进行采集,能够较大程度上代表公共文化服条的情况。
本文选取中国大陆31个省、自治区、直辖市和15个副省级城市的图书馆、文化馆的官方网站,作为信息采集的对象,从网络信息中抽取公共文化相关的基本数据、服条数据、管理数据等。通过调研发现,原目标的92个图书馆和文化馆的官网中,有18个公共文化机构的网址不存在或者近两年之内没有维护网站的数据。剔除这些网站之后,最终筛选出42个图书馆和32个文化馆的官方网站作为本文的信息采集对象。
2.3 官网可采数据类型与关系梳理
在调研图书馆和文化馆的具体网站过程中发现,公共文化服条机构官方网站数据主要可分为三种类型:基础数据、服条数据、机构动态数据。
基础数据是指图书馆和文化馆的介绍性数据,这些数据一般分布在名为“机构介绍”、“机构概况”等页面,从中可以提取出场馆名称、地区、面积、活动数量、场馆介绍等信息,这些是图书馆和文化馆共有的数据项,其中,图书馆还有馆藏量和分馆数量这两个数据项。服条数据是指讲座、展览、培训等,为用户提供的活动相关信息。本文把这些活动中可提取的数据都定义为服条数据的数据项,其中包括:活动标题、活动类型、活动时间、活动地点、主讲人、主办方、主讲人介绍、点击量、文章来源、活动介绍、URL。机构动态数据是指图书馆和文化馆发布在官网上、与本馆相关的新闻数据。从中可以提取新闻题目、发布时间、新闻内容、新闻URL等数据项。
通过上述调研和分析的结果,本文设计的数据库E-R图如图1所示,由于文化馆和图书馆的数据项十分类似,因此把两类机构的数据库设计成相同的结构。
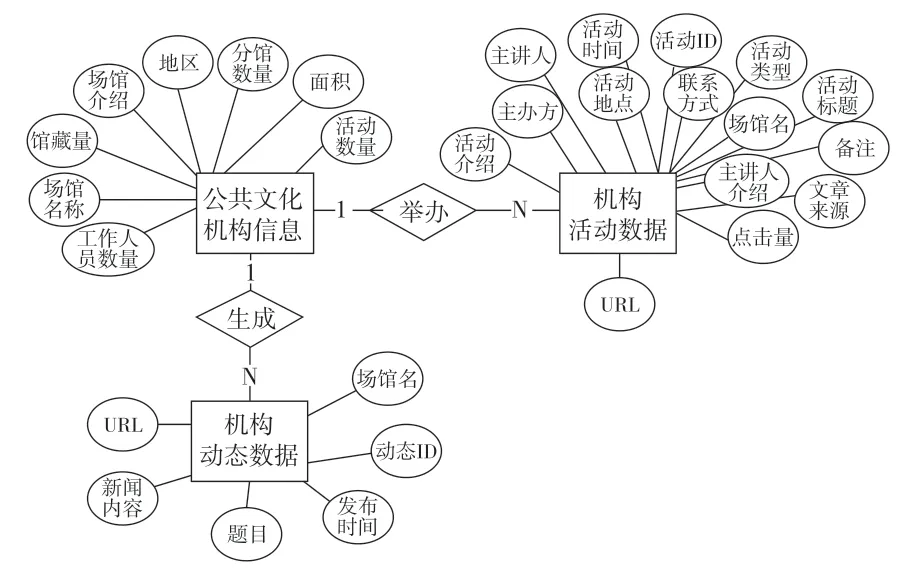
图1 公共文化服务机构典型数据E-R图
3 信息采集研究设计
3.1 分布式采集技术框架
网络采集大致可分为通用采集和定向采集两种。通用网络采集主要以抓取整个互联网的资源为主,是搜索引擎的核心部件,其工作流程是
从特定数目的起始网页URL 开始,逐层析取网页里的URL 链接地址,并抓取网页,由于是全网采集,也以不需要加内容过滤规则。定向采集以抓取网站网页的特定信息为主,与通用爬虫相比,需要构建相应的URL列表,编写 主题词表等筛选与过滤规则。公共文化机构的信息采集是有针对性地提取网页页面中的信息,属于定向采集。设计定向采集需解决网络连接、爬虫规则、数据存储等多方面的问题,开发过程相对复杂,为了简化信息采集设计工作,涌现出许多优秀的爬虫框架,其中最具代表性是Scrapy框架。
Scrapy 是一款基于Python 语言编写的开源框架,使用了twisted 异步网络库来处理网络通讯,极大地提高了爬取效率。Scrapy提供基础组件的同时还提供了自定义接口,兼具方便、灵活的特点。Scrapy框架由引擎、调度器、下载器、爬虫、管道及一些中间组件构成。
虽然爬虫技术已比较成熟,但对公共文化官网公开信息的特点进行归纳与总结,并进行批量获取的实践并不充分。本文选择Scrapy作为爬虫工具,对公共文化官网进行信息采集,并对公共文化服条的信息特点与采集过程进行归纳与总结。
3.2 公共文化开放数据的采集及提取流程
首先将各馆的基本信息、服条数据、动态数据所在的URL信息输入到Scrapy模型中,然后通过BeautifulSoup和Re库来解析网页的结构,如果是介绍性的基础数据和动态新闻数据,那么把通过BeautifulSoup解析出来的目标数据项直接存储到数据库中;如果是服条数据,则爬取服条数据的正文,然后再次判断其文本类型,对于半结构化形式的数据,通过半结构化文本提取规则来抽取活动数据项,否则通过非结构化文本提取规则来抽取活动数据项,最终将抽取出来的目标数据项存储到数据库中,其信息采集工作流程如图2所示。
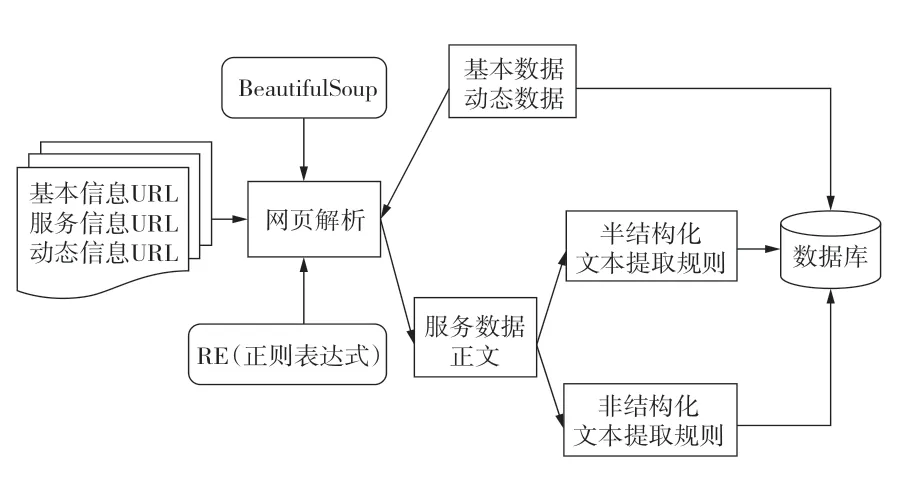
图2 信息采集过程
4 公共文化数据抽取技术
通过网络爬虫的信息采集技术,可以获取机构的基本信息、服条信息、动态信息,但是对于服条数据来讲,活动标题、活动类型、URL、点击量、文章来源等数据项之外,活动时间、活动地点、主讲人、活动介绍等信息都需要在活动页面的正文中通过命名实体识别等技术进行抽取。本文将活动页面的正文信息按照活动描述的规范化程度分为半结构化和非结构化,分别采用不同的规则来抽取目标数据项。
4.1 半结构化文本抽取
本文中的半结构化文本是指活动页面的正文中,目标数据项被特殊符号分割开的文本。如图3所示,在此正文信息中,主讲嘉宾的信息在一行中,以“:”分割的键值对形式存在。主办单位、讲座时间、讲座地点的数据项也是以同样的形式存在。此外还有主讲嘉宾简介、讲座内容概要,这些数据项的介绍型数据项一般占据多行空间,因此先用冒号来确定数据项名称,数据项的值由换行符来确定。

图3 半结构化文本例子
在半结构化形式的数据格式,大部分与图3例子中的数据形态非常类似,但是同样的数据项表述的语言可能不同,如主讲人的数据项在图3中由“主讲嘉宾”标识,在其他数据中由“主讲人”来标识。同样,“讲座时间”和“时间”、“讲座地点”和“地点是”、“主讲嘉宾介绍”与“主讲人简介”都具有相同的含义。因此在抽取这些数据项的时候,首先建立数据项的同义词表,其次需要归纳文本的展现形式。
4.2 非结构化文本抽取
非结构化数据项是指在活动页面的正文中没有指代词,被包含在一段描述性文本中的数据项。如图4所示,在这段例子中,可以看出有活动时间、主办单位、活动地点、主讲人、主讲人介绍、活动介绍等数据项。这类文本中没有具体指代词指明,因此需要一些规则来提取这些数据项。

图4 非结构化文本示例
活动时间由XXXX年X月XX日-X月XX日的形式表示,可以通过正则表达式抽取年月日信息。主办单位的数据项可以通过“由(目标数据项)主办”形式识别,活动地点可以通过“在(目标数据项)(厅)”识别。因此部分数据项可以通过数据项本身的特征以及紧密的上下文词来进行抽取。但是非结构化文本的数据项的形式繁杂,在语义识别上存在一定问题。
4.3 数据项抽取规则
按照半结构化及非结构化文本的不同特点,建立抽取数据项的规则模板。关于“活动”的规则模板分别为表2、表3、表4,其中表2规则可以适用于半结构化和非结构化的活动内容,包含“活动类型”和“活动时间”数据项抽取规则,表3的规则可适用于半结构化的活动内容,包含“活动地点”、“主办方”、“主讲人介绍”、“活动介绍”、“联系方式”数据项的抽取规则,最后表4的规则模板可适用在抽取非结构化的活动内容,针对抽取“活动地点”、“主办方”、“主讲人”、“联系方式”数据项时使用。

表2 共同抽取规则
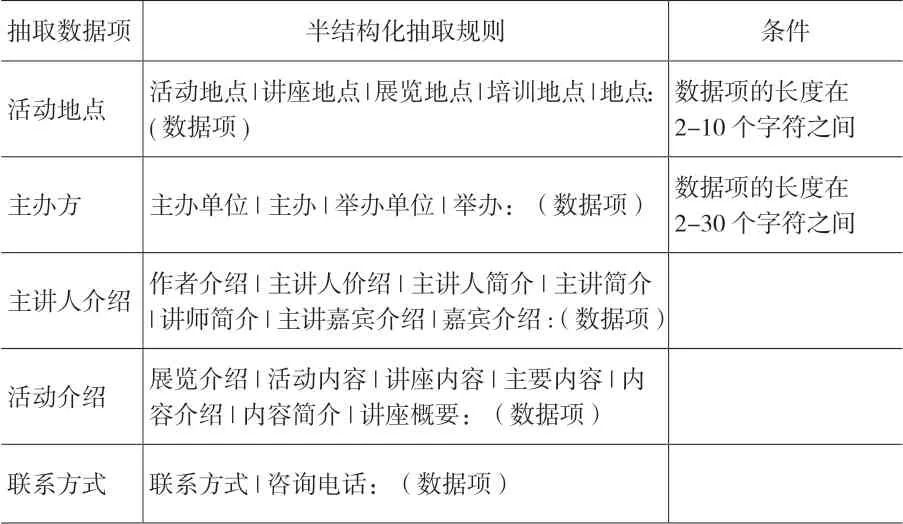
表3 半结构化抽取规则

表4 非结构化抽取规则
5 信息采集结果分析
基于Scrapy框架设计,在深入分析网页架构的基础上,获取了公共文化机构的基础信息、活动信息、动态信息,在信息采集过程中,有些官网有权限才能访问数据所在的页面以及复杂的反爬措施,所以有部分网站信息未能抓取。
5.1 机构基础信息结果分析
从机构的介绍页面获取机构的基础数据,得到35个图书馆和文化馆的基础信息。包括场馆名称、场馆介绍、分馆数量、馆藏量、地区、面积、工作人员数量、活动数量等共8个数据项。机构基础信息的部分数据如图5所示。

图5 基础信息的爬取结果
机构基本信息的抽取结果,分馆数量、工作人员数量、访问数量、活动数量缺失程度比较严重, 这是由于各场馆描述有所不同,各别数据项在介绍页没有提及而无法抽取导致的。但是这些数据项的缺失值可由其他方法替代,如活动数量可以通过机构活动数据所统计出的结果来补全。
5.2 机构动态信息结果分析
从官网的动态信息页面和新闻页面中获取机构动态数据,由于有些官网缺少动态新闻信息或者存在反爬措施,最终本文选取了30个场馆,共获取41 735条数据记录,其中包括场馆名、动态新闻题目、发布时间、内容、URL等5个数据项。
对于爬取结果,除了宁波图书馆和天津图书馆,大部分场馆的信息量都在1 000条以下。此外,在实际信息采集过程中,杭州文化馆的动态信息数量最多,为21 814条,但是杭州文化馆的动态信息包含大量的非本馆动态信息,除杭州文化馆以外其他馆的动态信息发布数量,如图6所示。

图6 馆动态信息数量
从网页长度来看,机构的动态信息平均字数为516字,大部分在1 000字以内。其中,主要以机构政策、举办活动、通知类的公告等内容为主。
5.3 机构活动信息结果分析
从活动预告或者活动报道中获取机构活动数据,由于有些官网缺少活动信息或者存在反爬措施,最终从18个场馆中,获取100 089条数据记录,其中包括场馆名、活动类型、活动介绍、活动标题、活动时间、主办方、主讲人等16个数据项。在这些场馆中,首都图书馆、杭州文化馆、杭州图书馆、重庆群众文化馆、武汉图书馆相比于其他场馆在举办活动的数量上明显较高,如图7所示。

图7 场馆活动信息数量
为了检验规则模板的有效性,对活动信息进行统计,在活动信息中每个数据项的空缺值比例为:场馆名(pav_name:0%)、活动标题(activity_name:1.5%)、活动类型(活动类型:26.4%)、活动时间(activity_time:1.5%)、活动地点(place:48%)、相关网址(url:0%)、主讲人(presenter:77%)、主讲人介绍(presenter_introduction:86%)、主办方(organizer:83%)、年龄限制(age_limit:95%)、参加人数(participation_number:96%)、点击量(click_number:65%)、来源(source:63%)、联系方式(contact:86%)、备注(reamrk:19%)。
在活动信息中,通过模板抽取出的结果中存在一些空缺值,这是由于各官网对活动信息的描述不同而每个活动信息中可获取到的数据项不全而导致的,为了检验规则模板的有效性,本文随机抽取1 000个样本进行验证。

表5 样本测试结果
从表5中可以看出,本文设计的规则模板在公共文化官网信息抽取上,表现出一定的有效性。对于规则相对简单的“活动时间”、“联系方式”等数据项表现出90%以上的抽取准确率,具有一定线索词的“活动类型”、“活动地点”、“主办方”、“主讲人”、“年龄限制”项的准确率也大概60%~70%左右的准确率,但是由于“主讲人介绍”、“活动介绍”项在非结构化文本中分布规则不太明显,因此整体的抽取准确率比较低的结果。
6 总结
本文研究公共文化服条机构的信息采集方法,包括数据范围的界定、爬虫框架的搭建以及文本抽取的问题,可以有效地支撑后续的信息的集成、管理、分析挖掘。在数据范围上,主要分为基础信息、动态信息、服条信息以及具体数据项。在爬虫框架的搭建上,采用目前比较成熟的Scrapy爬虫框架,构造分布式爬虫。基于规则的方法,从非结构化的自由文本中提取数据中的特征项。
本文研究也存在一些局限和不足,基于规则的方法需要人工编写模板,工作量较大的同时也难以覆盖所有的情况。其次,由于各机构的信息内容存在一定的差异,这导致了一些数据项的缺失,需要研究这些缺失值的补全方法。后续工作可以从这些角度入手,进一步提升公共文化服条机构的信息采集与抽取效果。
以深度学习技术为代表的大数据技术在图像识别、语音对话、人机对弈、机器翻译等领域得了较大的成功,这与领域内形成了大量的标注数据供机器学习与训练。在图书馆等领域,已经有图书分类、规范关键词、引文索引等标注数据,把这些标注数据进行格式转换与集成,形成图书馆领域的标准数据集将有助于图书馆大数据的落地与实现。同时也要在文化馆、博物馆等领域形成一些关于馆情介绍、文化活动、展品标识、解说词等方面形成一些规范数据集,为深度学习等技术在公共文化领域的全面运用奠定基础。有了足够的训练数据,运用深度学习等技术,结合一些领域词表或知识图谱,识别公共文化信息内容与特征,进行公共文化信息的自适应采集与全自动抽取也就指日可待。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29 01:09:42
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:14
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
甘肃科技(2020年19期)2020-03-11 09:42:42
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
Coco薇(2017年11期)2018-01-03 20:59:57
暨南学报(哲学社会科学版)(2016年9期)2017-01-15 13:52:02
计算机工程(2015年8期)2015-07-03 12:20:35
