
GF-4大气校正并行算法研究
2021-06-08 03:54:18王子翔李正强光洁佘璐
大气与环境光学学报 2021年3期
王子翔,李正强∗,光洁,佘璐
(1中国科学院空天信息创新研究院,国家环境保护卫星遥感重点实验室,北京 100101;2中国科学院大学,北京 100049;3宁夏大学资源环境学院,宁夏 银川 750021)
0 引言
高分辨率对地观测系统是国务院确定的中长期科学和技术发展规划重大专项之一[1],2013年4月,高分一号卫星成功发射,拉开了高分系列卫星发射的序幕[2]。高分四号卫星(GF-4)于2015年12月29日在西昌卫星发射中心成功发射,是我国第一颗地球同步轨道遥感卫星,搭载了一台可见光50 m、红外波段400 m分辨率、大于400 km幅宽的凝视相机,具备可见光和红外成像能力,通过指向控制实现对中国及周边地区的观测,在民用卫星遥感方面具有划时代的意义[3]。
GF-4数据应用的关键是快速、精确地进行大气校正,得到地表反射率(Surface reflection,SR)产品,保证数据产品及时应用于各个行业部门[4],产品生产效率与精度影响到数据应用水平和使用价值。GF-4卫星数据波段较少,空间分辨率与时间分辨率较高,可见光近红外通道单景影像数据量达到GB级别,整轨数据量有上百GB,随着GF-4数据广泛应用于局地精准天气预报、减灾救灾、森林与农作物监测等领域[5]。GF-4等卫星数据的串行处理算法无法满足在应急与应用领域的快速处理需求,考虑反演算法通常有较高的计算复杂性,遥感反演结合图形处理器(GPU)加速的并行处理方法已成为当前研究热点。
国内外已有较多关于GPU结合遥感计算的研究,周海芳等[6]选取GPU程序面向存储级的优化策略并结合遥感图像配准程序,提出并行设计模型与面向存储级的优化策略,适用于遥感图像配准领域,最大加速比达到了19.9倍;肖聆元等[7]基于CUDA架构的快速正射纠正算法,在GPU设备上并行运算并利用DOM和DEM对RPC模型进行精化处理;Song等[8]基于GPU实现从地形图的扫描彩色图像重新连接轮廓线的方法,具有更好的性能和更高的连接速率;王化喆等[9]为解决遥感图像前期处理算法计算时间较长的问题,开展了基于RPC模型实现遥感处理几何校正的并行加速与基于SIFT特征提取的并行加速研究,基于数据的并行划分实现了遥感图像的几何校正和SIFT特征提取算法的加速;汤媛媛等[10]构建CPU/GPU异构模式,对高光谱遥感影像MNF降维并行加速实现了异构模式在遥感高光谱领域的并行优化。以上结合GPU并行算法的遥感研究一定程度上提高了遥感计算的效率,但目前结合GF-4等国产高分辨率卫星的GPU并行加速应用研究较少。
大气校正方法主要包括基于图像特征模型、地表实测线性回归模型和辐射传输模型等。其中辐射传输模型反演地物反射率可描述大气散射、吸收等过程[11]。目前大气校正处理应用较广泛的6 S模型是美国马里兰大学地理系在5 S[12]模型基础上研发的,该模型在气体透过率、瑞利散射及气溶胶光学厚度的计算等方面进行了改进,在MODIS产品大气校正计算方面表现尤为突出[13]。2005年6SV较之前的模型主要增加了辐射极化的计算[14]。国内外相关研究中,Sever等[15]利用大气校正的多角度实现(MAIAC)是通过使用地表双向反射系数(BRF)的解析计算而使用格林函数的半解析算法;Wang等[16]使用MODIS日地表反射产品(MOD09GA)作为评估Landsat地表反射产品准确性的参考,证明MODIS SR(Surface reflectance)产品和Landsat SR产品具有很强的一致性;Eric等[17]提出MODIS表观反射率乘积计算出的OLI仪器的1/2通道和4通道的地表反射率的算法;简化的高分辨率MODIS气溶胶检索算法(SARA)[18]利用(AERONET)站的气溶胶特性以及MOD09GA level-2的每日地表反射率产品进行参数化,验证具有足够本地先验信息的高分辨率大气校正。
针对GF-4等国产卫星的大气校正产品快速生产需求,与国产高分辨率卫星结合GPU加速的应用研究较少的现状,本文基于GPU对GF-4大气校正进行并行算法设计,大气校正算法参考辐射传递方程参数化的先验知识,针对算法可并行步骤完成基于CUDA-C的内核设计与映射,对线程、寄存器等进行性能优化。GF-4大气校正算法原理:利用MODIS DT算法所使用的气溶胶类型[19],考虑辐射传递方程的参数化与地表类型参数化,基于MODIS地表反射率数据产品获得不同地表类型的GF-4可见光通道(0.47µm和0.67µm)与0.87µm瑞利校正大气层顶(TOA)反射率之间的统计关系,使用Levenberg-Marquardt算法进行迭代得到最佳气溶胶光学厚度(AOD)[20],基于AOD结果与构建的6SV模型LUT(查找表)计算地表反射率,并利用Landsat-8地表反射率产品对GF-4产品进行精度验证。
1 GF-4数据及大气校正算法简介
1.1 GF-4数据
GF-4数据包括可见光、近红外与中红外6个波段,其中可见光及近红外波段的空间分辨率为50 m,中红外波段空间分辨率400 m,波段信息如表1所示。考虑GF-4搭载全色多光谱传感器(PMS)与红外传感器(IRS)两个有效载荷,测试数据选择2016年6、7月份的GF-4 PMS数据,研究区域为中国长江中下游地区,如图1所示。表1也给出了MODIS的可见光及近红外波段的波段信息,包含250 m分辨率的近红外与红色波段,以及500 m分辨率的蓝绿波段。

图1 GF-4研究区域长江中下游地区Fig.1 GF-4 study area in the middle and lower reaches of the Yangtze River
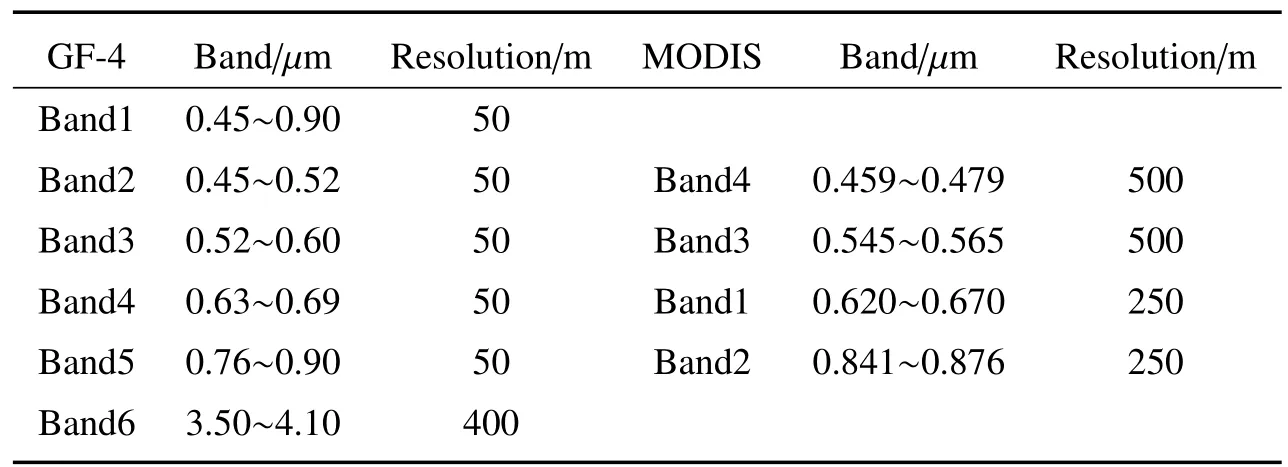
表1 GF-4数据波段与分辨率Table 1 Band and resolution of GF-4 data
1.2 大气校正算法
GF-4大气校正算法主要包括三个功能步骤,分别是估计地表反射率、反演AOD与计算地表反射率,大气校正算法的流程图如图2所示。
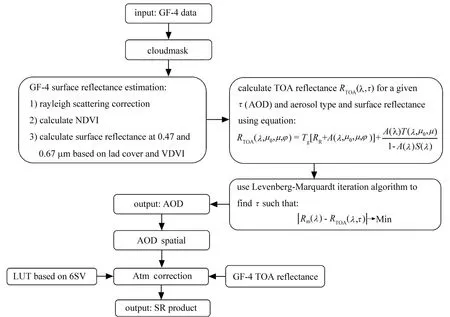
图2 GF-4大气校正算法流程图Fig.2 flowchart of GF-4 surface reflectance calculation
(1)估计地表反射率
TOA表观反射率的计算,需要输入估计的地表反射率,以及气溶胶类型等参数。已有研究基于MODIS DB的气溶胶反演算法[21],通过计算不同波长之间表观反射率的统计关系,准确估计地表反射率,证明MODIS数据产品进行地表参数化、气溶胶光学厚度反演与地表反射率计算的可行性[22]。考虑GF-4数据的可见光、近红外波段信息以及MODIS数据相近的可见光、近红外波段信息,基于MODIS数据作为先验知识进行地表反射率估算。先前研究验证了地表覆盖类型受归一化植被指数(Normalized difference vegetation index,NDVI)的影响,可见光波段(0.67µm和0.47µm)与近红外、红外波段(0.86、1.6、2.1、3.75µm)的地表反射率存在一定线性关系[18]。拓展考虑GF-4数据,归一化植被指数计算公式为

式中:C0.86和C0.67是近红外与可见光波段的瑞利散射校正TOA反射率。
R0.67和R0.47为估计的地表反射率,其分别为


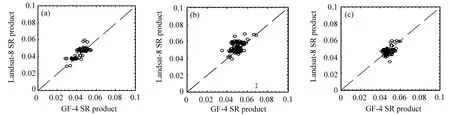
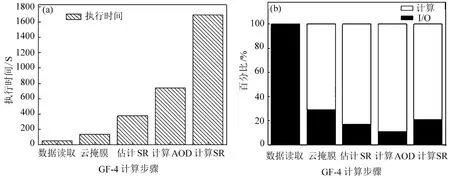
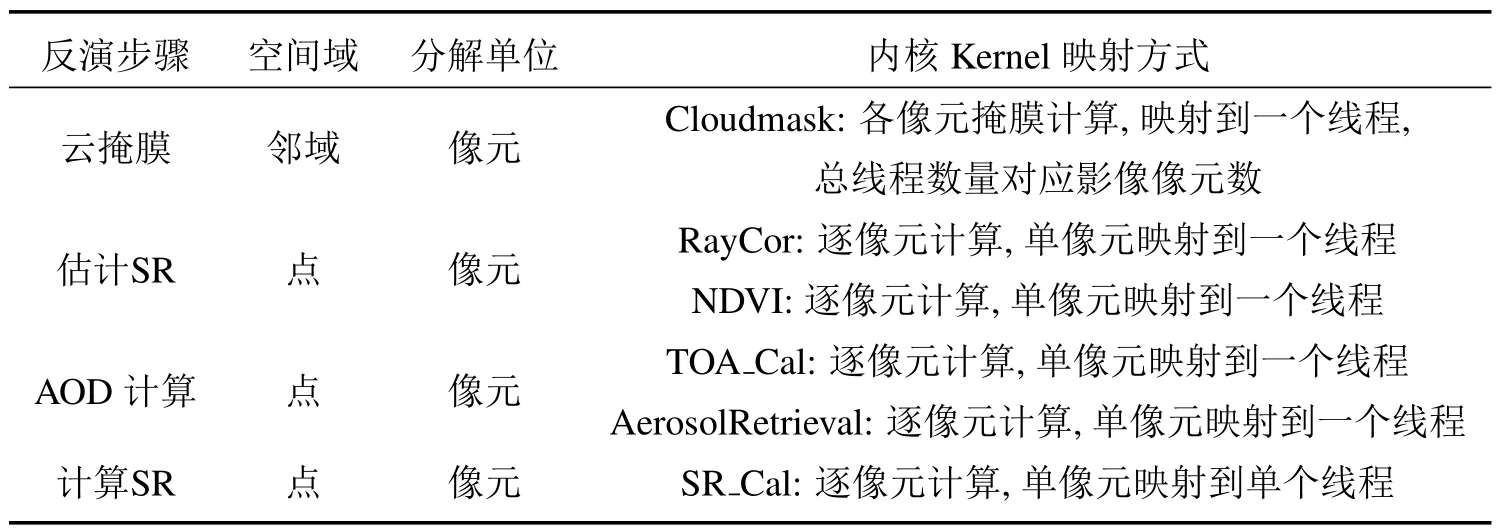
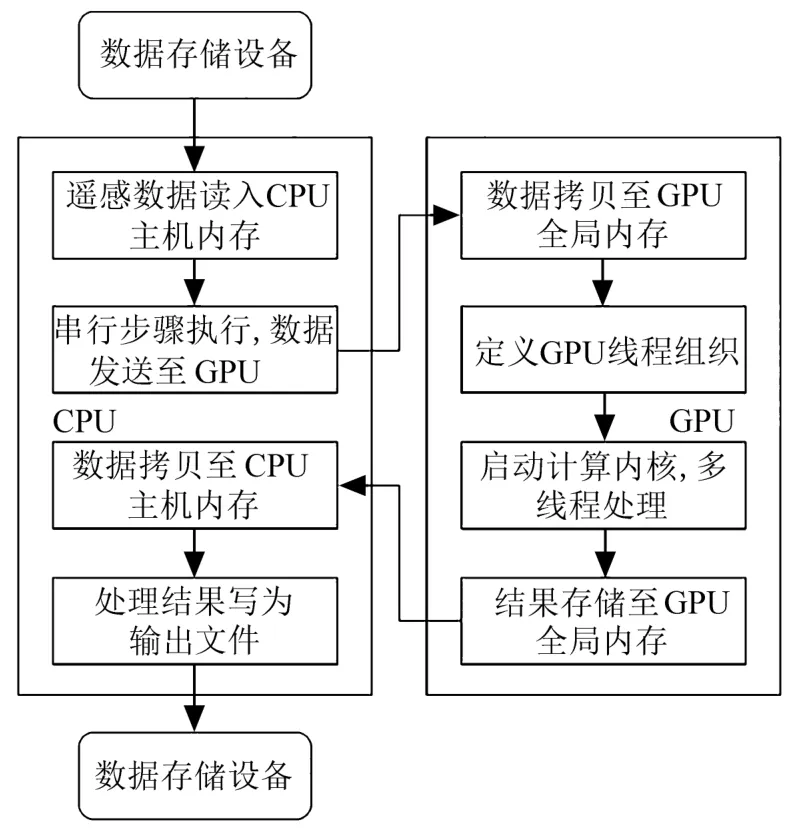
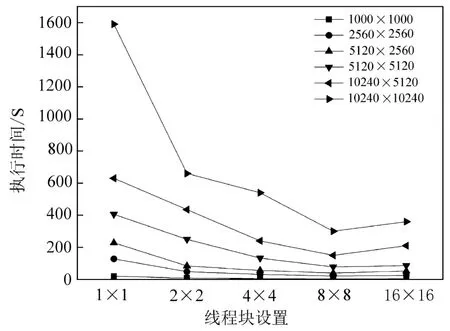
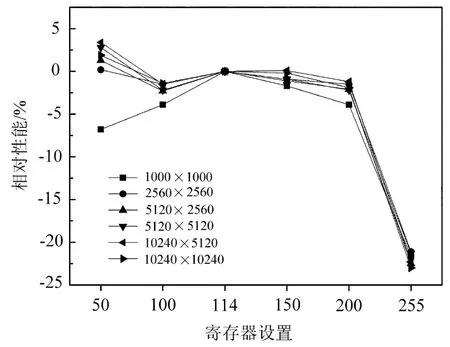
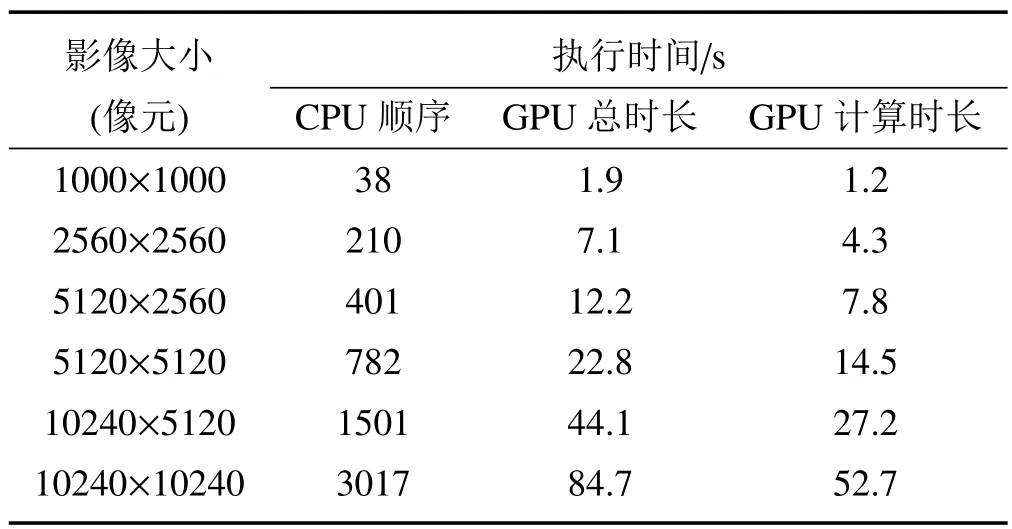
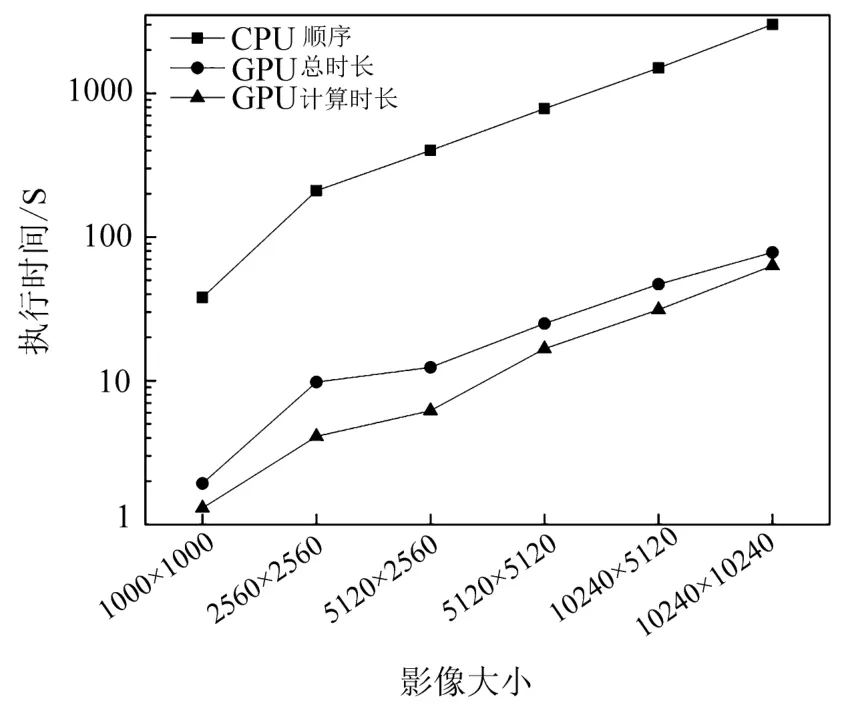
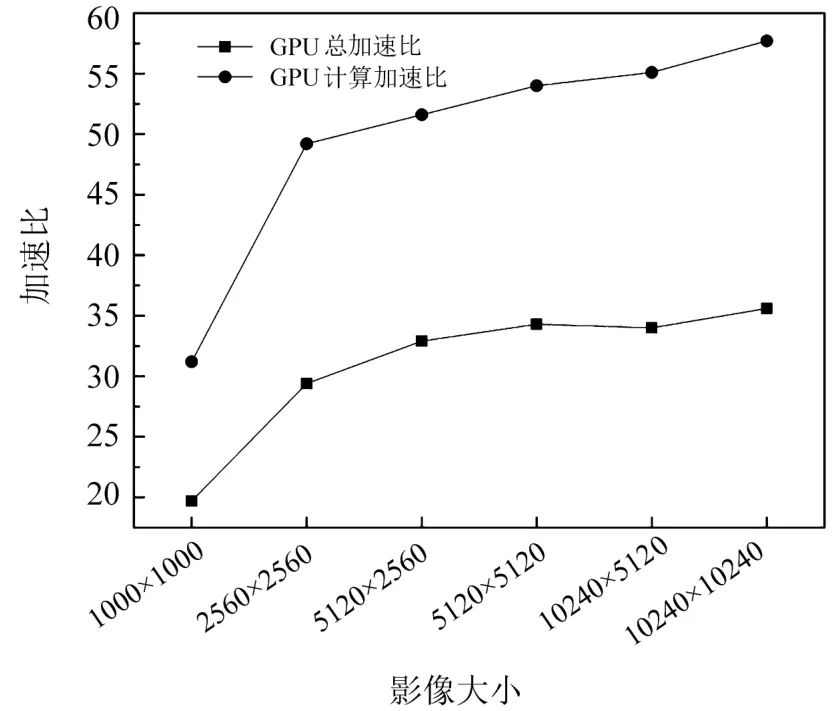
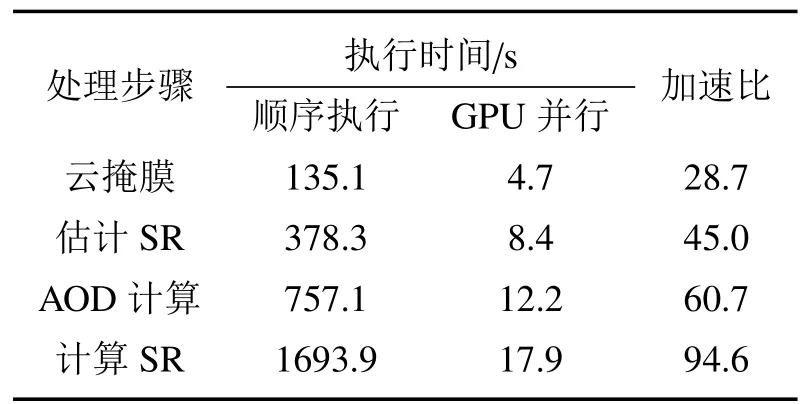
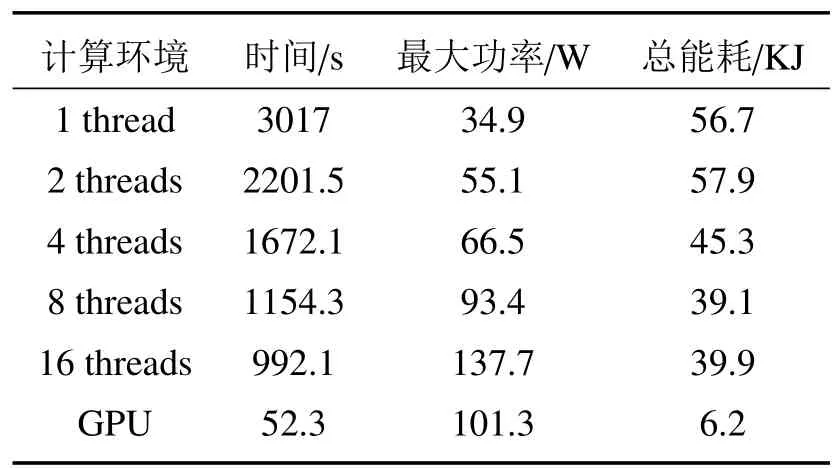
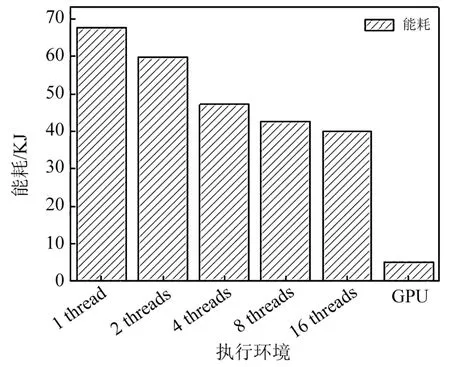
式中:s0.67/0.86和s0.47/0.86分别是0.67µm与0.86µm、0.47µm与0.86µm的回归方程斜率,y0.67/0.86与y0.47/0.86是回归方程偏移量,Ψ 是散射角,a0、a1、a2、b0、b1、c0、c1、c2、d0、d1等系数为最小二乘方法拟合真实地表反射率确定的回归系数,对于每种土地覆盖类型,在MODIS DB的算法基础上,将其分为三个NDVI组的四个季节的回归系数,分别为:0.10 针对TOA表观反射率计算的气溶胶类型输入部分,地表反射率与气溶胶的耦合关系使得在进行大气校正时,气溶胶的剥离存在一定难度,常用大气校正算法根据地理位置与时间选择一个限定纬度、地表的气溶胶模式,地表类型基于MODIS土地覆盖产品(MCD12C1)对70°E~130°E,15°N~55°N地区进行统计分析。气溶胶类型包含三个可见光波段的气溶胶模型,根据MODIS C6 Dark-Target气溶胶光学厚度反演算法设置,包括弱吸收、中吸收和强吸收三种,其中不对称因子g和单次散射反照率(SSA)被进一步参数化为不同的气溶胶类型,经过数值计算的多项式形式,通过0.55µm的AOD来设置g、SSA和Angstrom系数。 (2)气溶胶光学厚度反演算法 假设地表为均匀朗伯面,大气中分子与气溶胶散射及气体吸收水平一致,卫星传感器接收到的辐射由大气路径辐射、透过大气的目标地物直接反射辐射、经由大气散射的目标地物反射辐射、背景地物散射辐射以及背景地物多次地表散射辐射构成。 TOA表观反射率受到来自气溶胶的影响与地表反射率的影响。考虑GF-4大气校正算法,GF-4波段数据为可见光与近红外波段,通过瑞利反射率“ρRay”和气溶胶反射率“ρaer”计算大气路径反射率,考虑偏振效应时的瑞利散射,与散射角及入射方向有关,瑞利光学厚度(ROD)取决于入射波长和地表高程。在不考虑地表高程和压强影响时,Liang等[23]提出的瑞利光学厚度近似公式可满足精度需求。研究区域长江中下游地区高程较小,根据之前的研究基础,参考瑞利光学厚度求解的近似公式,气溶胶散射可参数化为气溶胶单次散射反照率、气溶胶相函数的函数,其中气溶胶相位函数使用了Henyey-Greenstein气溶胶相位函数。通过Levenberg-Marquardt迭代算法计算AOD,即 寻找使得卫星观测的TOA表观反射率与计算TOA表观反射率之间残差最小的AOD值,在0.47µm和0.67µm之间的价值函数最小化来获得最佳AOD,基于此计算AOD结果。 (3)计算地表反射率 基于AOD输出结果,将其作为地表反射率查找的已知输入数据,对AOD结果数据进行空间插值,结合GF-4 TOA反射率数据以及6SV查找表计算地表反射率。大气辐射传输模型计算速度较为缓慢,为提高反演速度,使用6SV矢量辐射传递模型建立查找表。6SV模型包含三个可见光波段(0.46,0.55,0.64µm)的气溶胶类型。GF-4是静止轨道卫星,卫星角度与成像区域经纬度相关,中国区域观测天顶角范围约0°~70°),方位角范围约70°~90°。查找表中设置15个太阳天顶角和观测天顶角(0°~84°,Δ=6°),16个相对方位角(0°~180°,Δ=12°),高程设置为0,气溶胶模式设置的类型选择取决于研究区域的地理位置,通过线性插值计算不存在的几何角度。 选择高空间分辨率、高精度的USGS Landsat-8 SR产品和GF-4 SR产品进行比较,两种SR产品具有绿、红和蓝三个可见光波段。为了地表反射率SR产品比较的精确性,纠正由不同的光谱响应函数引起的误差[24]。精准比较GF-4 PMS产品的反射率,考虑光谱差异并使用光谱匹配因子,光谱匹配因子的计算公式为 式中:fpms(λ)和fOLI(λ)分别是GF-4 PMS和Landsat-8 OLI的相对光谱响应函数。λ1~λ2是GF-4 PMS的光谱范围;λ3~λ4是Landsat-8 OLI的光谱范围。GF-4 PMS和Landsat-8 OLI之间的光谱匹配因子a如表2所示。 表2 可见光波段的光谱匹配因子Table 2 Spectral matching factor in the visible light band Landsat-8 SR数据日期为2016年7月30日,GF-4数据日期为2016年7月23日,通过裁剪得到相同经纬度范围的数据,选择的数据具有良好的时空匹配且受云影响较小,考虑Landsat-8 SR产品的空间分辨率为30 m,GF-4 SR产品的空间分辨率为50 m,对GF-4 SR产品和Landat-8 SR产品进行时空匹配,将数据重新采样到相同的分辨率,对数据进行定量分析和验证,分别对三个可见光波段(红、绿、蓝)的地表反射率结果逐次随机选择1000~10000个像元进行对比分析,如图3所示,图中每个圆圈代表一个像元点,对RMSE进行计算得到结果分别为0.02、0.01和0.02。与Landsat-8 SR产品相比,基于GF-4的地表反射率结果,在三个可见光波段的对比中RMSE均小于0.02,具有较好的精度。 图3 GF-4 SR产品与Landsat-8 SR产品在三个可见光波段红(a)、绿(b)、蓝(c)的对比结果Fig.3 Comparison of GF-4 SR product and Landsat-8 SR product in visible light bands of red(a),green(b)and blue(c) 遥感数据具有多波段的特性与几何特性,遥感数据处理流程一般包含原始数据读取、数据预处理、数据深加工处理及遥感专题信息提取等。基于GPU的遥感计算流程为:将遥感影像读入CPU主机内存;CPU端将数据拷贝至GPU全局内存;CPU端指令启动kernel内核函数,GPU端多线程并行处理;将GPU处理结果拷贝至CPU主机内存;CPU端将处理结果输出为影像。 遥感并行计算为基于遥感数据提取基本遥感参数,结合知识库信息等对一定空间、时间尺度的数据进行计算。以GF-4地表反射率计算作为遥感任务实例,结合遥感计算并行模型,探讨GF-4地表反射率计算的并行加速实现。 GF-4地表反射率计算的C++程序包含5个功能步骤,分别为数据读取、云掩膜、估计地表反射率、AOD计算、地表反射率计算,针对各步骤进行并行特征的执行时间与数据I/O分析。数据读取步骤为读取GF-4原始影响数据信息;云掩膜步骤中逐像元计算3×3窗口的绝对标准差,以识别是否是云像元;地表反射率估计步骤包括瑞利校正计算、NDVI计算、基于地表类型与NDVI值计算0.67µm和0.47µm波段的地表反射率等;AOD计算步骤实现TOA表观反射率计算、Levenberg-Marquardt最优估计等功能,得到空间分辨率为1 km的AOD结果产品;地表反射率计算步骤实现AOD结果插值、基于查找表计算等,得到空间分辨率为50 m的地表反射率产品。 计算环境为Intel(R)Xeon E5-1650 at 3.5GHz Workstation工作站系统,测试数据为2016年7月23日的GF-4 PMS数据“GF4PMSE111.3N28.820160723L1A0000122970”。统计5次测试数据执行时间的平均值,得到各步骤的执行时间与数据I/O分析分别如图4(a)、(b)所示。图4(a)中执行时间最长的是计算地表反射率步骤,其执行占比为56.4%,数据读取步骤执行时间占比为1.8%,云掩膜执行步骤的时间占比为4.5%,估计地表反射率的执行时间占比为12.6%,AOD计算步骤执行时间占比为24.7%。图4(b)中云掩膜、估计地表反射率(SR)步骤的计算占比高,对其进行并行优化;计算AOD、计算SR步骤的执行时间长且属于计算密集型步骤,需要进行算法并行设计及优化。对于数据读取步骤,其数据I/O占比极高,对其进行串行执行不做具体探讨。 图4 GF-4计算各步骤执行时间(a)及数据I/O情况(b)Fig.4 Runtime(a)and I/O(b)of GF-4 calculation steps 基于GF-4地表反射率计算流程各步骤执行时间、数据I/O的分析,其中云掩膜、估计SR、计算AOD、计算SR等步骤基于GPU进行并行优化。 考虑遥感计算的空间域并行分析的三个主要类别为基于点或像元的计算、局部计算以及非局部或不规则计算等,AOD反演的可并行步骤细粒度计算特征及其内核映射方式如表3所示。 表3 GF-4可并行步骤内核映射方式Table 3 GF-4 parallel step kernel mapping method 空间域分解依据反演各步骤的输入数据,选择基于单个像元、邻域或不规则区域的计算。其中云掩膜步骤,算法参考基于暗像元的方法,每个像元的3×3窗口进行绝对标准差计算,属于局部计算的方式且其计算单位为逐像元方式;估计SR步骤包括瑞利校正计算、NDVI计算、估计地表反射率等功能,属于逐像元计算的方式;AOD计算步骤为逐像元的计算TOA表观反射率并进行迭代计算得到AOD结果,属于点计算的方式;计算SR步骤为逐像元基于查找表进行计算等。基于GPU的并行计算设计和实现,将单个像元的所有计算分配到对应的一个GPU线程。 对于可并行步骤,影像数据采用一维数组存储,通过全局内存实现合并访问,所有线程访问连续对齐的内存块,对全局内存的连续对齐访问,能够基于线程束的方式将多个线程的访问地址合并,从而减少内存的获取次数,提高吞吐量。 针对估计SR、AOD计算等两个计算内核的步骤,在计算时会将部分结果存储于全局内存,后续内核计算的时候可以调用,从而减少了总线PCIe(Peripheral component interface express)的CPU-GPU数据传输。 对于云掩膜步骤的邻域计算,像元计算需要访问邻近像元值,全局内存的访问延迟为400~600 cycles,而共享内存同一线程块的所有线程都可对进行访问并读写操作,其访问速度快于全局内存,因此将重复访问的数据存储于共享内存中。云掩膜为逐像元基于3×3滑动窗口计算绝对标准差,当线程块包含M×N个线程时,其所需访问的数据包含(M+2)×(N+2)个像元,频繁的全局内存访问降低计算效率,采用数据复制策略,利用共享内存存储每个线程块所需的(M+2)×(N+2)像元。 基于GPU并行加速的地表反射率计算,计算环境包括CPU与GPU配置如表4所示。 表4 CPU-GPU计算环境Table 4 CPU-GPU computing environment 选择2016年7月23日的GF-4原始数据,其像元数为10240×10240个。对实验数据进行裁剪,分别获得 1000×1000、2560×2560、5120×2560、5120×5120、10240×5120、10240×10240 六组不同大小的遥感数据,基于六组数据对反演算法进行实验与分析。 考虑AOD反演流程中可并行处理步骤与串行处理步骤,基于GPU并行加速实现完整的AOD反演执行流程如图5所示。 图5 GPU-CPU执行步骤情况Fig.5 GPU-CPU performance steps 主要步骤包括从遥感影像数据存储设备读取MODIS数据至CPU主机内存;CPU端执行AOD反演串行步骤,同时初始化GPU变量,开辟GPU端内存;遥感数据从CPU内存拷贝至GPU端全局内存;定义GPU端的线程组织;GPU设备启动线程执行计算内核;将存储于GPU全局内存的计算结果拷贝至CPU端内存;CPU端结果数据写入输出文件并输出至存储设备。对于估计SR、计算AOD等包含多个计算内核的步骤,重复中间步骤,针对不同计算内核进行对应数据准备和拷贝,启动计算内核并完成计算过程;输入和输出图像步骤,数据存储在GPU全局内存。 基于GPU的AOD反演算法,从GPU线程、寄存器两个方面进行性能分析并优化。 (1)GPU线程 以计算SR步骤为例,研究GPU线程组织即线程块与线程网格的设置对计算性能的影响,选取最佳的线程设置,线程块设置与对应数据执行时间如图6所示。 图6 各组影像基于不同线程块设置的执行时间Fig.6 Each group of images is based on the runtime set by different thread blocks 计算环境的Tesla K40 GPU上每个线程块最大线程数为256(每个线程使用编译器默认的114个寄存器),将GPU线程块设置为2维,在1×1、2×2、4×4、8×8和16×16线程块上执行6组不同大小的影像数据计算时,线程块8×8时各组遥感影像获得最佳计算性能,8×8为最优线程设置。 (2)寄存器使用 设置最优线程块8×8,调用nvcc使得线程寄存器数量在50~255之间变动,得到相对性能如图7所示。 图7 各组影像基于不同寄存器设置的执行时间Fig.7 Each group of images is based on the runtime set by different register 编译器默认每个线程使用114个寄存器,当设置寄存器数量大于114时,各组遥感数据执行性能随寄存器数量的增加而呈现下降趋势;寄存器数量小于114时,除1000×1000大小的数据相对性能随寄存器增加而增加,其余大小数据相对性能随寄存器增加呈现先减后增的趋势。 减少每个线程的寄存器数量可允许更多并行执行的线程。如将每个线程使用的寄存器数量减少至57寄存器/线程,每个线程块可以设置为32×32线程,增加并行性但部分数据需要从比寄存器有更长延迟访问的存储器读取,相比最优8×8线程配置性能降低30%~40%,因此选择不手动设置每个线程的最大寄存器数目,使用编译器默认的114寄存器。 对6组不同大小影像数据进行了完整的地表反射率计算,其中串行执行的数据读取步骤在CPU端实现,使用GNU编译器gcc和编译优化选项“-O2”。基于GPU的并行算法通过CUDA-C实现。为保证遥感反演的精度,未使用“-use_fast_math”等编译选项。CPU串行执行和GPU并行加速执行的运行结果如表5所示。六组影像基于CPU串行执行与GPU加速执行的执行时间比较如图8所示。 表5 各组影像分别基于CPU与GPU的执行时间与加速比Table 5 Each group of images based on the runtime and speed-up ratio of CPU and GPU 图8 各组影像的基于CPU与GPU的执行时间Fig.8 Each group of images based on the runtime of CPU and GPU GPU总执行时间包括GPU驱动程序启动、数据输入、主机到设备的数据传输、GPU计算、从设备到主机的数据传输以及数据输出的总和。CPU顺序执行仅包括数据输入、计算以及数据输出,没有其他数据传输与驱动启动。由图8可知相比顺序执行,GPU端计算时长与总时长大幅缩短。 针对加速比(Speedup)对性能提升进行分析,其中加速比是同一个任务在单处理器系统和并行处理器系统中运行消耗的时间的比值,用来衡量并行系统或程序并行化的性能和效果,加速比计算公式为 式中:T1指顺序执行的时间,Tp为并行算法执行时间。GPU端的计算加速比为计算时长与顺序执行时长的比值,总加速比为基于GPU计算的总时长包括了CPU-GPU之间数据传输与顺序执行时长的比值。GPU端的总加速比与计算加速比结果如图9所示。 图9 各组影像的基于CPU与GPU的加速比Fig.9 Each group of images based on the speedup of GPU all and calculation 对于六组不同大小的遥感数据,随着影像数据的增大,基于GPU并行算法的计算加速比可达到49.8。考虑数据I/O时,总执行时间随影像像元数的增多而增大,影像的平均总加速比为31.0。总加速比随影像增大而增大,当影像计算规模增大时,GPU启动、CPU和GPU端的数据传输等时间开销在总执行时间中的占比降低,随着影像规模增大到一定程度,额外的时间开销可忽略,此时GPU遥感反演并行算法的总加速比趋于稳定。当影像范围较小如共有1000×1000像元数时,额外开销占比过大,此时GPU计算的加速比最低。 考虑遥感反演流程关键步骤的执行时间与加速比情况,对10240×10240像元数的GF-4数据进行如表6所示。 表6 各步骤分别基于CPU与GPU的执行时间与加速比Table 6 Each steps based on the runtime and speed-up ratio of CPU and GPU 分析GF-4大气校正算法可并行步骤的加速比,云掩膜、估计SR、AOD计算、计算SR等步骤分别获得了28.7、45.0、60.7、94.6的计算加速比,各步骤的平均加速比为57.3,均取得较高性能提升。 功耗是遥感数据反演计算时要重点考虑的指标,通常GPU具有极高的能耗而不适于遥感在轨处理和分析。采用功耗测量仪Christ CLM1000 Professional(Plus)对应用运行时的功率进行采样测量如表7所示,选择10240×10240的一景GF-4 PMS遥感影像进行地表反射率计算。 表7 不同计算环境能耗情况Table 7 Energy consumption of different computing environments 表7中,CPU多核执行在1、2、4、8、16个线程时的最大记录功率分别为34.9、55.1、66.5、93.4、137.7 W,当服务更多线程时,运行时间将大大减少。GPU的平均功耗约为101.3 W,其范围分别相当于CPU上的八个线程版本,并未达到其峰值功率220 W。对于所有测试,在统计信息中都排除了CPU主机端的功耗,多核与GPU加速的该部分功耗相等,而GPU闲置功耗仅存在于GPU节点中。GPU执行的平均功耗为80 W,接近于8线程多核的功耗开销。能耗基于功耗的运行时间积分,对功耗逐秒采样累加得到近似的执行能耗,如图10所示。 图10 不同计算环境能耗情况Fig.10 Energy consumption of different computing environments GPU并行执行的1、2、4、8、16线程时的能耗分别为67.7、59.9、47.2、41.4、39.1 kJ,而GPU并行执行的AOD反演模型计算因执行时间较短,总能耗仅为6.4 kJ,仅占能耗最低的8线程多核并行的15.5%。 针对GF-4卫星实现高效率大气校正、快速得到地表反射率产品的需求,对GF-4大气校正并行算法进行研究,大气校正算法基于辐射传输模型,在MODIS DT、DB算法基础上考虑地表参数化与气溶胶参数等,对最优AOD进行计算并作为6SV查找表输入得到地表反射率产品。针对反演流程的可并行步骤,基于CUDA-C完成内核的设计与实现,针对线程组织、寄存器使用等进行了分析与优化,详细分析了GPU并行加速的结果精度、计算性能、能耗等问题。结果表明基于GPU加速的地表反射率计算结果在可见光波段的典型地物类型对比中精度高,在执行性能与计算能耗上显示出优势,单景实验数据取得57.3的加速比,总体能耗仅占CPU多核并行的15.5%。GF-4地表反射率并行算法,产品取得较高精度,算法具有较好加速效果,后续工作还需进一步针对GF-4等国产卫星的其他专题产品应用进行相关并行优化。
1.3 GF-4地表反射率产品精度验证


2 并行计算分析与设计
2.1 GF-4计算流程并行特征
2.2 GF-4算法并行设计
3 算法实现与分析

3.1 AOD反演并行算法实现
3.2 性能分析与优化
3.3 性能比较

3.4 GPU功耗与能耗
4 结论
猜你喜欢
印制电路信息(2022年11期)2022-11-30 03:40:58
海洋通报(2022年4期)2022-10-10 07:40:26
光谱学与光谱分析(2022年4期)2022-04-06 03:44:38
家庭医学(下半月)(2020年7期)2020-08-24 07:47:04
四川环境(2019年6期)2019-03-04 09:48:50
电子器件(2017年2期)2017-04-25 08:58:37
环球市场(2017年36期)2017-03-09 15:48:21
高原山地气象研究(2016年2期)2016-11-10 06:06:27
沙漠与绿洲气象(2014年1期)2014-03-20 15:42:01
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
