
基于情感词典和SVM的微博网民情感分析
2021-06-07 00:15王文韬张士豹
现代信息科技 2021年24期
王文韬 张士豹

摘 要:近年来网络社交平台兴起,大众倾向于在网上发表日常生活的感受,通过对这些文本的分析可以挖掘出人们的情感信息。文章基于新冠疫情暴发初期新浪微博有关新冠话题的评论数据,通过结合情感词典和支持向量机的方法构建情感分类模型,接着通过情感时序分析和LDA主题模型综合探讨疫情期间微博网民的情感走勢与特征。经实验分析,网民在新冠疫情期间的情感以积极情感为主,体现了大众对于战胜疫情有着相当充足的信心。
关键词:新冠疫情;情感词典;支持向量机;情感时序分析;LDA
中图分类号:TP391.1;TP181 文献标识码:A文章编号:2096-4706(2021)24-0024-05
Abstract: In recent years, with the rise of network social platforms, the public tends to publish their feelings in daily life on the Internet. Through the analysis of these texts, peoples emotional information can be mined. Based on the data of comments on the topic of COVID-19 on Sina micro-blog in the early stage of COVID-19 epidemic outbreak, this paper constructs an emotion classification model by combining emotion dictionary and Supports Vector Machine. Then, the emotion temporal sequence analysis and LDA (Latent Dirichlet Allocation) theme model are used to comprehensively explore the emotional trend and characteristics of micro-blog netizens during the epidemic period. According to the experimental analysis, the emotions of netizens during the COVID-19 epidemic period are mainly positive emotions, which shows that the public has sufficient confidence in overcoming the epidemic.
Keywords: COVID-19 epidemic; emotion dictionary; Support Vector Machine; emotion temporal sequence analysis; LDA
0 引 言
近些年来,社交媒体如微博、知乎等凭借着实时互动,多元化的特点已然成了传播时事,网民表达自己情感的重要渠道[1]。微博的开放环境为网络舆论的自由化提供了便利,人们随时随地便能在微博发表自己的想法。文本是用于情感分析的典型数据集,通过使用数据挖掘技术我们能够得到文本中所蕴含的情感倾向,而通过对微博文本数据的挖掘,我们更能从中了解整个社会群体的情感,分析影响这些群体情感起伏的因素。
新冠疫情在这两年断断续续,始终是网民讨论的重要话题。尤其在2020年1月1日至2月18日这段时间,新冠疫情初步席卷全球,全球社交平台的讨论此起彼伏,让其成了2020年最具影响力的一次热点事件[2]。通过对疫情期间的网民评论数据进行分析,能够挖掘出这期间网民的情感变化趋势及主要影响他们情感的相应因素。总的来说,通过对互联网热点事件的实时分析,我们能够即时掌控和把握网民的情感倾向,从而能够为有关部门促进社会和谐稳定提供应对方向。
本文首先通过情感词典标注微博文本数据的情感倾向,接着以支持向量机(SVM)构建情感分类模型,并以情感时序分析的方法探究网民情感发展趋势,最后通过LDA(Latent Dirichlet Allocation)主题模型分析了不同情感态度下的特征,为舆情治理提供一定参考。
1 情感分析方法
网民的情感分析是一种对文本的情感倾向分析方法,通过对语句的提炼,可以分析出语句背后人们的主观态度和情感倾向。现如今情感分析方法被广泛应用在社交平台和电商平台的评论数据当中,大多是为了对这些评论进行挖掘,分析出这些评论的观点信息和情感极性。目前在相关研究领域当中,情感分析主要使用机器学习,深度学习或者情感词典的方法。
1.1 基于机器学习的情感分析
Pang[3]等运用多种机器学习方法,如朴素贝叶斯,支持向量机等,对电影评论数据进行了情感分类,证明了机器学习作为文本情感分析的可行性。Liu L[4]等通过SVM(Support Vector Machine),朴素贝叶斯和随机森林对微博用户的评论立场作出了识别。Xue[5]等用LDA主题模型来实现了对2 200万条Twitter信息中新冠肺炎相关的突出主题及情感的识别。
1.2 基于深度学习的情感分析
Milagros[6]等提出了一种新的深度学习算法,该算法结合了依存语句,且对文本的情感分析效果较好。梁军[7]等使用递归神经网络实现了对COAE2014微博数据集的情感分析,且准确率接近于许多手工标注特征的传统算法。梁斌[8]等提出了基于多注意力机制的卷积神经网络,且其分类效果比传统的卷积神经网络效果好。
1.3 基于情感词典的情感分析
情感词典是对现有各种文本语言中各种情感词的归纳,通过对情感词典与待分析的文本进行比对,找出其中重叠的情感词,从而可以确定该文本表露的情感。Cynthia[9]对情感词典的研究较早,其通过对情感词典不断完善,使其将现有语言和情感词典相匹配。栗雨晴[10]等提出了一种基于中英文双语的情感词典,通过双语情感词典的构建解决了当微博评论英文字符比重增加,导致分类效果下降的问题。Mohammed[11]等通过结合当前可用的英语词汇和来自目标语言的未标注语料库构建非英语情感词典,且证实了能够显著提升非英语情感分类性能。
2 研究方法
2.1 基于情感词典的文本情感分类
2.2 基于SVM的文本情感分类
情感词典文本分类方法对情感词典的依赖性极高,不同情感词典对同一文本的分类效果也不同,甚至可能极性相反,因此需要选取较为准确的情感词典。首先通过对待分类文本分词去停用词等预处理后,再对处理后的语句中的词与所选择的情感词典的情感词一一比对,根据比对后的正向情感词与负向情感词作差后的结果正负判断该文本是属于积极文本还是消极文本,是0则是中性文本,其中具体的步骤如下:
(1)选取情感词典;
(2)对待分类文本预处理,包括分词,去停用词等;
(3)将预处理后的文本与情感词典比对,计算文本的情感极性,如果为正数,为积极文本,如果为负数为消极文本,如果为0,则是中性文本;
(4)采用评估指标对文本的情感分类极性结果进行评估。
支持向量机目前在文本情感分类上运用较多,该方法采用监督学习方式对二分类问题进行建模。主要解决线性可分和线性不可分的情况,当线性可分时,则通过寻找一个最优超平面把样本分隔开,线性不可分时,则使用核函数将其转化为线性可分,通常使用多项式核,径向基函数核,拉普拉斯核和Sigmoid核。而以上的最优超平面则称作最大间隔超平面,这个平面到两边最近数据点的距离都是最大的,此时SVM问题转化为一个凸二次规划问题的求解。其原理图如图1所示。
支持向量机模型的基本思想即求两类样本的最大几何间隔,即H1到H和H2到H的距离,而H就是通过不断地训练计算而求出用于分类的超平面(在二维空间中即一条直线),位于H1和H2上的圆形和正方形即支持向量集。最大化几何间隔可以使算法的误差上界最小,从而提高分类器的效果和泛化能力。
2.3 基于情感词典和SVM的文本情感分类
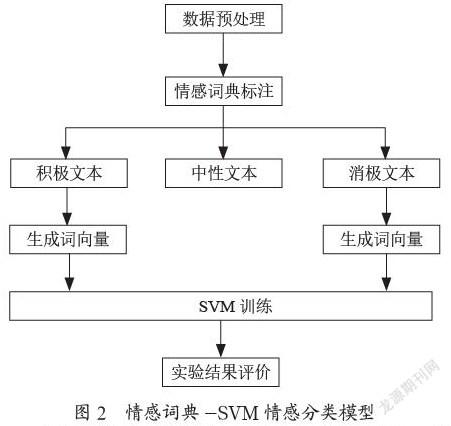
本文通过采用情感词典的方法标注微博文本数据来使得SVM模型训练更加准确,从而提高整体的情感词典-SVM分类模型的精度。首先对数据进行预处理,具体包括数据清洗,并对清洗后的数据分词,去停用词。再通过情感词典的方法得出各个句子的情感得分,对以上得出的结果中,令情感得分正的为积极文本,情感得分负的为消极文本,情感得分为0的为中性文本。选取其中正负得分较为高的积极和消极文本作为数据集进一步进行分类模型训练,通过机器学习SVM算法对此模型做验证分析,具体流程图如图2所示。
而在得到情感分类模型后,本文通过情感时序分析和LDA主题模型分别分析了网民情感变化趋势和特征。通过对情感词典得到的每日微博评论的情感得分做日平均,画出情感得分随时间变化的曲线,并与每日新增感染人数作对比,以此分析新冠疫情期间网民的情感变化趋势。而对选取的积极和消极文本进行LDA主题模型分析,可以得到不同态度的网民群体的情感特征。
3 实验与结果分析
3.1 数据获取
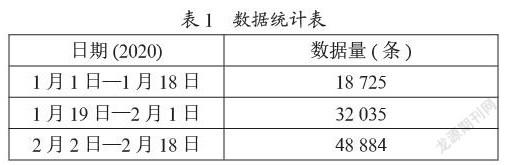
本实验选取了在2020年举办的疫情期间网民情绪识别比赛的10万条数据,此次比赛数据集是依据于“新冠肺炎”相关的230个主题关键词进行数据采集,抓取从2020年1月1日到2020年2月18日期间的微博评论数据,这段时间是新冠疫情从被网民开始关注到疫情逐步得到缓解,大部分地区开始复工,能够代表公众在此期间的情感倾向和观点态度,具有较高的舆论研究价值。表1为数据统计表。
3.2 基于情感词典和SVM的情感分类模型构建
在通过情感词典对微博评论初步标注计算情感得分之后,我们选取正负极性较高的积极的和消极的评论数据各1万条。在本次实验中,将对这些已經通过情感词典筛选的数据集的80%随机抽取作为训练集,剩下的20%作为测试集,确定模型的精确度和误差。再通过Word2Vec词向量模型将文本语料转换为词向量,取词向量维度为100维,再通过调用sklearn 中svm 包,采用RBF核函数( kernel=‘rbf,惩罚系数C=2,gamma=0. 1),训练降维后数据,作出ROC曲线如图3所示,得到此分类模型准确率达到0.96,可知该分类模型结果较好可以用于微博评论数据的情感分类。
3.3 情感时序分析
在得到了每条微博评论的情感得分后,对每日微博评论的情感得分做日平均,画出情感得分随时间变化的曲线,并与每日新增感染人数作对比,图像如图4所示。
从上述时序图可以看出,在1月1日至1月18日,即使随着确诊人数的增加,大众对于新冠的情感大多也是乐观的积极的,相信这次疫情不会持续很久,会很快地得到控制,同时对感染的患者也是持祝福的情感,所以这段时间微博的评论大多都是积极的。在1月19日至2月1日,感染人数在这段时间内不断地增长,死亡人数也在增多,大众对新冠疫情也从一开始的乐观变为恐惧和惊慌,微博评论的情感得分也在这一段时间内呈下降趋势。在1月31日时,微博评论的情感得分达到了负值,表示了这段时间大众的情感偏向消极。但是同时,这段时间大众情感得分虽然呈下降趋势,但是大部分还是为正,这就表明了大众对于国家能够走出这段疫情还是保有着坚定的信心的。在2月2日到2月18日这段时间里,随着疫情逐渐得到控制,各省逐渐开始复工,大家之前那种恐慌消极的心情在政府各项行之有效的措施中也得以慢慢缓解。因此,微博评论的情感得分也有上升的趋势。
我们根据上述的发展阶段将时间分为3个部分,并对以下三个时间段作出相对应的词云图如图5所示。在1月1日到1月18日可以发现微博主流的词汇主要是“志愿者”“新冠病毒”“咳嗽”等词汇,还有“绿色地球”等时事话题,说明疫情还在开始阶段,人们开始关注但重视程度还不够。1月19日到2月1日是疫情暴发时期,人们开始重视,高频词汇全部为与新冠病毒相关的词语,如“感染”“病例”等,整体情绪较之前悲观。2月2日到2月18日是舆论开始稳定的阶段,除了上个阶段的高频词之外还有“中国加油”“武汉加油”“抗疫”“战疫”等积极的有正能量的词汇,整体情绪开始好转。还出现了“中医药”“双黄连”等与当时“双黄连可抑制新冠病毒”等新闻相关的词汇,说明网民仍有一定恐慌情绪。
3.4 LDA主题模型
通过使用Gensim模块对积极评论数据和消极评论数据分别构建LDA主题模型,设置主题数为3,每个主题下生成10个最有可能出现的词语,如表2和表3所示。
表2反映了新冠疫情期间积极评论文本中的潜在主题。主题1中的关注点主要是中国,医护人员、加油、致敬,主要反映了疫情期间网民对于国家以及医护人员的加油和支持。主题2的关注点则是感染、病例、出院,主要反映了在疫情期间经过救治之后,出院的患者。主题3则主要关注读书、口罩、体现了网民在疫情缓解,开始逐步复工复产的趋势下,开始注重于生活的重新开始。
表3反映了新冠疫情期间消极评论文本中的潜在主题。主题1中的关注点主要是感染、确诊、疫情,反映了疫情期间人们对于每天确诊人数的增多所带来的担忧与害怕。主题2中的关注点则是野味、蝙蝠,反映了人们对于疫情源头的痛恨。主题3中的关注点则是金银花、医院、出院、希望,体现了人们对新冠病毒所产生的恐慌,世界上各方力量都在寻求有助于缓解疫情的方法。
4 结 论
微博网民情感分析的主要任务是为了掌握网络舆情动态,明确互联网热点事件的民众态度及情感特征,为政府维护社会稳定作出一定参考。本文通过结合情感词典与SVM构建了微博网民情感分类模型,取得了较好的分类效果,同时通过情感时序分析和LDA主题模型对此次疫情民众情绪变化和特征进行了可视化分析,通过分析发现,民众在新冠疫情期间的情感虽有对于新冠病毒的恐慌,但仍以积极情感为主,相互鼓励,共同渡过这个难关,回归正常生活。由于新冠疫情引起的舆论此消彼长,可以进一步扩大数据量,更加全面的探讨新冠舆情的相关问题。
参考文献:
[1] 王艳东,李昊,王腾,等.基于社交媒体的突发事件应急信息挖掘与分析 [J].武汉大学学报(信息科学版),2016,41(3):290-297.
[2] 韩珂珂,邢子瑶,刘哲,等.重大公共卫生事件中的舆情分析方法研究——以新冠肺炎疫情为例 [J].地球信息科学学报,2021,23(2):331-340.
[3] PANG B,LEE L,VAITHYANATHAN S. Thumbs up? Sentiment Classification using Machine Learning Techniques [J/OL].arXiv:cs/0205070 [cs.CL].[2021-11-03].https://arxiv.org/abs/cs/0205070v1.
[4] LIU L R,FENG S,WANG D L,et al. An Empirical Study on Chinese Microblog Stance Detection Using Supervised and Semi-supervised Machine Learning Methods [C]//Natural Language Understanding and Intelligent Applications.Kunming:Springer,2016:753-765.
[5] XUE J,CHEN J X,HU R,et al. Twitter discussions and concerns about COVID-19 pandemic:Twitter data analysis using a machine learning approach [J/OL].arXiv:2005.12830 [cs.SI].[2012.11.16].2020.https://arxiv.org/abs/2005.12830v2.
[6] FERN?NDEZ-GAVILANES M,?LVAREZ-L?PEZ T,JUNCAL-MART?NEZ J,et al. Unsupervised method for sentiment analysis in online texts [J].Expert Systems with Applications:An International Journal,2016,58(C):57-75.
[7] 梁軍,柴玉梅,原慧斌,等.基于深度学习的微博情感分析 [J].中文信息学报,2014,28(5):155-161.
[8] 梁斌,刘全,徐进,等.基于多注意力卷积神经网络的特定目标情感分析 [J].计算机研究与发展,2017,54(8):1724-1735.
[9] WHISSELL C. Objective Analysis of Text:II.Using an Emotional Compass to Describe the Emotional Tone of Situation Comedies [J].Psychological Reports,1998,82(2):643-646.
[10] 栗雨晴,礼欣,韩煦,等.基于双语词典的微博多类情感分析方法 [J].电子学报,2016,44(9):2068-2073.
[11] KAITY M,BALAKRISHNAN V. An automatic non-English sentiment lexicon builder using unannotated corpus [J].The Journal of Supercomputing,2019,75(4):2243-2268.
作者简介:王文韬(1997—),男,汉族,江苏苏州人,硕士在读,研究方向:大数据分析;张士豹(1996—),男,汉族,安徽滁州人,硕士在读,研究方向:图像处理。
猜你喜欢
大经贸(2020年2期)2020-05-08
现代商贸工业(2020年14期)2020-05-07
新丝路(下旬)(2020年4期)2020-04-23
中小学心理健康教育(2020年10期)2020-04-13
大经贸(2020年1期)2020-04-07
大经贸(2020年1期)2020-04-07
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
