
基于Fcn-Attention的硬盘故障预测方法
2021-06-07 01:37:56张佳惠
现代信息科技 2021年24期

摘 要:保证大型数据中心服务的可靠性越来越重要,硬盘是大型数据中心中故障率最高的组件。如果能够预测硬盘的故障情况就可以提前对数据进行保护和隔离,避免造成重大损失。然而当前的预测器不能同时有效地提取时间序列的长短期依赖关系,学习样本的有效特征。文章提出了基于注意机制的全卷积注意力模型,该模型能够解决长短期依赖问题,有效识别故障模式。最后在采集的SMART日志的数据集中证明了模型的有效性。
关键词:硬盘故障预测;异常检测;注意力机制;全卷积网络
中图分类号:TP391;TP18 文献标识码:A文章编号:2096-4706(2021)24-0048-03
Abstract: Ensuring the reliability of services in large data centers is becoming more and more important. Hard disks are the component with the highest failure rate in large data centers. If the failure of the hard disk can be predicted, the data can be protected and isolated in advance to avoid major losses. However, current predictors cannot effectively extract the long and short term dependency of the time series at the same time, and learn the effective features of the samples. This paper proposes a fully convolutional attention model based on the attention mechanism, which can solve the problem of long and short term dependency and effectively identify failure modes. Finally, the validity of the model is proved in the data set of the collected SMART log.
Keywords: hard disk failure prediction; anomaly detection; attention mechanism; fully convolutional network
0 引 言
随着大数据以及云平台的普及,每天都有大量的数据需要存储。而目前最主要的存储设备就是硬盘。海量数据以及云平台的在线部署都使硬盘的稳定性面临着巨大的挑战,据统计硬盘故障是IT设备故障中最常见的组件。硬盘故障会导致服务中断,数据丢失等问题,严重是会造成巨大的经济损失。根据Backblaze的2021年第三季度的报告,硬盘在该季度的平均故障率为1.01%。这意味着在一个拥有300 000块硬盘的数据中心,几乎每天都会出现硬盘故障。对于不同的硬盘来说,不同的厂商会内置一个记录硬盘内部状态的日志(SMART自我健康监控报告),该日志能记录这硬盘生命周期内的重要安全指标。然而只利用这样的日志进行硬盘故障检测的检测的故障率为3%~10%[1]。所以需要结合相关模型进行预测研究。在机器学习中,硬盘故障预测问题通常被抽象成一个二分类问题:给定某硬盘过去的数据,预测它在未来一段时间后是否会发生故障。对于预测为故障的硬盘采取更换措施并对部署的服务进行及时的迁移,可以把避免更大的经济损失。本文提出全卷积注意力(Fcn-Attention)模型用来捕获硬盘故障前数据的长期短期依赖关系,并通过全卷积来识别故障模式,提高硬盘故障预测的精确率。
1 相关工作
对于硬盘故障预测问题在很早之前就有学者开展了相关的工作,相关的研究方法主要分为两种:基于傳统机器学习的方法和基于深度学习的方法。基于传统的机器学习方法可以通过使用分类器来解决这个问题,比如支持向量机[2]和树模型[3]。但是硬盘的故障从本质上来讲是一个时间序列的问题,硬盘是逐渐发生故障的,而不是突然发生故障的。然而,传统的机器学习是很难抓取时间上的信息的。LI Qing [4]等人利用集成学习中的XGBoost方法对硬盘故障进行预测,利用手动创造特征的方式来提取数据中的时间信息。WANG Haifeng等人利用集成学习中的Stacking框架将不同方法的结果进行串联。但是这些方法的弊端就是需要额外点的方法或者是人力对时间序列信息进行提取。需要大量的预处理过程。
与传统机器学习相比,基于深度学习的方法利用神经网络的特性对时间信息进行提取,例如利用循环神经网络(RNN)、长短期记忆网络(LSTM)、一维卷积网络(CNN)。这些方法在效果上都能得到提升。但是由于循环神经网络不能进行并行训练,所以在性能上略有欠缺。一维卷积的方法一定程度上依赖窗口的大小。受到注意力机制在自然语言处理领域的相关工作的影响。注意力机制可以对进行词嵌入后的句子中的词进行上下文的融合,而得到更加能够代表词意的词嵌入向量。那么将注意力机制引入多维时间序列中也可以融合长期短期值之间的依赖关系。
2 Fcn-Attention模型
2.1 问题描述
本文提出的基于深度学习的方法,该方法根据硬盘的状态数据来预测硬盘是否会出现故障。因为不能提前预知故障情况,也不能在故障发生后再进行数据采集。所以这里的采集需要全采集。即在每一个时间戳(例如:每天或者每小时)记录硬盘的m个属性的特征向量。对于某一块硬盘x,x的状态数据是由该硬盘的h个连续特征向量组成的集合。这些特征向量从时间戳ti(开始记录的时间戳)记录当时间戳ti+h+1(停止记录的时间戳)。这里的故障数据指的是硬盘在t时刻后k天内出现故障,则该硬盘为故障样本。否则为正常样本。
假设一个包括n个样本的时序数据集D={(x1,y1),(x2,y2),…,(xn,yn)},xi∈Rh*m,h表示时间序列的长度,m表示状态数据的维度。yi∈{0,1},是样本的标签信息,y=0表示健康硬盘样本(负样本),y=1表示硬盘在不久之后会发生故障(正样本)。因此该问题被抽象成一个二分类问题,此时的损失函数为二进制交叉熵损失。公式为:
为样本被预测为1的概率即发生故障的概率。
2.2 模型结构
该模型的结构如图1所示,分别包括:全卷积(fully convolution networks)网络模块、时间序列的注意力模块、全局池化模块。全卷积网络首次在图像语义分割任务中被提出,与传统的卷积网络不同,全卷积网络在输出前利用全局池化层来代替全连接层,同时在每个卷层后不再接入池化层。而是使用BatchNorm层和ReLU激活函数来优化中间层的输出分布,提高学习效率。这里使用一维卷积在卷积层来进行特征组合,并增加卷积核的个数来学习更多组合特征;时间序列注意力模块用来捕获时间序列历史值的相关性。对于某块硬盘某一时间步数据,利用公式(1)来映射到三个不同的特征空间。
Q(X)=X·WQ,K(X)=X·WK,V(X)=X·WV(1)
注意力机制通过Q(X)与K(X)之间的映射关系来决定分配哪两个时间步更大的权重,通过公式(2)来计算注意力矩阵。但是对于当前时间步的查询向量q,它只能与当前时间步之前的键向量进行映射,否则就会出现数据穿越现象。所以将S矩阵的右上角设置为了零。通过公式(3)即softmax来对权重进行归一化。
将权重矩阵与值向量进行加权计算,并将结果利用公式(4)与输出权重WO进行矩阵相乘。以上注意力机制使用矩阵运算,相比于RNN不能并行训练来说可以提高学习速度,全局池化层来代替全连接层可以有效地减少参数数量。
3 实验与分析
3.1 数据集
实验选择使用Backblaze[5]中2020-1-1至2021-7-1年记录的真实硬盘数据。Backblaze自2013年就开始发布基于数据中心硬盘的统计数据。该数据由SMART日志以及一些静态信息构成,包括日期、序列号、型号、容量和故障情况。由于数据集中的硬盘厂商以及硬盘的型号众多,所以这里直选取保有量较高并且故障率也较高的希捷厂商的两种型号的硬盘进行实验。分别为ST8000DM002、ST8000NM0055。由于健康硬盘的数量远远大于故障硬盘的数量,传统解决数据不平衡的方法包括对正样本进行过采样、对负样本进行欠采样。但是为了能够保留更多原始数据所包含的信息。这里我们对故障数据进行尽可能多的采样,即对于预测问题的前置时间k(即我们应该在真正发生故障前的k天内预测出来),可以针对k天的每一天构造负样本。这样的采样方式不仅可以生成更多的故障样本,也有利于捕获更多的故障模式。根据工业实例的需求,这里的前置时间k设置为10,时间长度h设置为30,即利用某块硬盘之前30天的采集数据来预测该硬盘是否会在10天内发生故障。最终共采集117 439个样本,其中有4 632个异常样本。共采集32个原始SMART日志属性。
3.2 实验设置
将实验数据集按照8∶2的比例划分成训练集和测试集,划分时保证数据集中的正负样本比例以及不同型号样本比例近似。在实验过程中,为了保证实验结果的真实有效,所有实验将在TensorFlow2.0框架、同一设备下完成。实验使用Adam优化器,学习率设置为0.000 01,卷积模块中选择使用三层的卷积层,分别包含7*m、5*m、3*m尺寸的卷积核,对应卷积核的个数为128、256、128。注意力模块向量长度设置为100,其他一维卷积的尺寸均为7。
3.3 实验结果对比
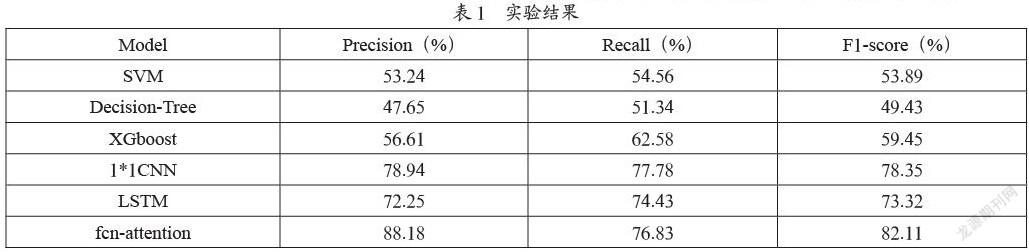
实验将相关工作中提到的机器学习方法,包括支持向量机(SVM)、决策树模型(Decision-Tree)、XGboost模型以及最近提出的一维卷積网络(1*1CNN)、长短期记忆网络(LSTM)模型来进行对比实验,以保证该模型的有效性。实验中使用的评估指标为精确度(precision)和召回率(recall)。同时均衡分数(F1-score)也作为一个综合点的评价指标来衡量模型的有效性。最终结果如表1所示。
表1中加粗部分为针对采集数据集的最好结果。针对机器学习方法来说总体的预测效果是最差的,这是由于异常模式的复杂性,以及有效特征构建的问题。SVM很难选择一个合适的分离超平面将正负样本完全分开,而且选择一个合适的核函数也是很困难的事情。决策树是针对特征进行节点分裂的,这更依赖有效特征的构造了。一维卷积和LSTM相比于传统机器学习效果有明显提升。一维卷积具有平移不变性,能够识别在不同时间段上的故障模式,但是这样的识别依赖于卷积核的长度限制,对于某些长期的影响才造成故障的情况识别率较低。LSTM当序列长度超过一定限度会存在梯度消失问题所以对于较长的影响的故障也是识别率降低,并且由于不能并行计算所以训练时间较长。本文模型先利用卷积来提取局部时间的相关性,并利用多个卷积核来构造有效特征,同时注意力机制将之前时刻进行加权求和,所以无论是长期影响还是短期影响都能对影响时刻提高权重来保证预测的准确率。而对于硬盘故障问题,误报即精确率降低会投入更多的人力,而漏报即召回率较低可以配合其他方法继续解决。所以精确率高是更合理的。
4 结 论
本文针对硬盘故障预测问题提出了新的全卷积注意力模型,能够捕获时间序列中值的长期和短期的依赖关系,全卷积网络可以提取样本特征更多的有效特征而且卷积的平移不变性还可以提取故障模式。在采集的Backblaze公开数据集上与其他模型进行比较也有更好的表现。后期工作中,会考虑解决不同厂商以及在大量不同型号中如何进行预测。
参考文献:
[1] MURRAYJ F,HUGHES G F,KREUTZ-DELGADO K. Machine Learning Methods for Predicting Failures in Hard Drives:a Multiple-instance Application [J].Journal of Machine Learning Research,2005,6(1):783-816.
[2] ZHANG J,WANG J,HE L,et al. Layerwise Perturbation-Based Adversarial Training for Hard Drive Health Degree Prediction [J].IEEE,2018:1428-1433.
[3] SHEN J,WAN J,LIM S J,et al. Random-forest-based failure prediction for hard disk drives [J].International Journal of Distributed Sensor Networks,2018,14(11),pages 15501477188,November.
[4] LI Q,LI H,ZHANG K. Prediction of HDD Failures by Ensemble Learning [C]//2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS). Beijing:IEEE,2019.
[5] Backblaze. Backblaze Drive Stats for Q3 2021. [DS/OL].[2021-11-05].https://www.backblaze.com/blog/backblaze-drive-stats-for-q3-2021/.
作者簡介:张佳惠(1997.07—),女,汉族,黑龙江伊春人,硕士研究生在读,研究方向:人工智能、智能运维、数据挖掘。
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
教育教学论坛(2017年1期)2017-02-08 21:21:32
软件导刊(2016年11期)2016-12-22 21:59:46
科教导刊·电子版(2016年27期)2016-11-18 09:48:25
科教导刊·电子版(2016年25期)2016-11-16 22:09:46
