
一种Hadoop海量电信数据云计算平台设计与实现
2021-06-04 03:09:20郭拴岐
微型电脑应用 2021年5期
郭拴岐
(陕西警官职业学院 信息技术系, 陕西 西安 710021)
0 引言
随着4G时代的到来,移动业务日渐增多,产生的电信数据更是以TB级速度上涨,这也为运营商的运营和管理造成了一定的压力。运营商只有快速处理每日产生的大批量电信数据,才能掌握电信用户的实际需求,设计出更具针对性的业务套餐供客户选择,提升自身竞争力。原有的关系型数据库已经难以满足当下海量电信数据的处理需求,若想提升数据处理速度,必须配以高性能机器,投入成本有所提升,为运营商带来了一定的压力,而Hadoop技术的发展和成熟很好地解决了这一问题。Hadoop作为一种开放式源代码架构,主要用于大型数据库,利用MapReduce编程软件划分数据,完成电信信息的兼并处理工作,效率高更加节省时间。Hadoop还具备优异的伸缩性、容错性,适配多款硬件,实际应用能力强。
1 应用技术简介
1.1 云计算
云计算是近年来新兴的计算机技术,是基于互联网服务人数增加、使用和交付创建出来的,是将并行计算和分布式计算整合起来的计算机技术,契合当前网络计算综合发展的需求。使用云计算后,系统会平均分配计算任务,各资源池上的任务数量相对统一,确保各资源池拥有充足的计算力来完成计算任务。信息存储空间和服务能力,并且具有安全性、共享性、扩展性和投入资金低等多项优点。以服务内容为划分依据,分为软件、平台、基础设备。以数据为中心点,在数据合并处理、编程和虚拟化等方面都发挥了非常大的作用[1]。
1.2 Hadoop平台技术介绍
Hadoop是由Apache基金会注资研发的,可应用在廉价PC机器上,作为分布式集群系统结构,拥有着安全、高效、可扩展和成本低等优势。由于其自身是不需要付费的开放性平台,用户在使用时拥有更多的灵活性,完成程序分布。Hadoop包含多个子项目,其具体分布如图1所示。

图1 Hadoop的项目结构
1.2.1 HDFS介绍
HDFS是一个分布式文件软件,自身拥有高容错性。该软件在调取数据时运用的是高吞吐技术,因此在性能一般的PC机上也能使用,不仅可以提升系统的工作性能,还能减少资金投入,适用于存有大批量电信数据的软件当中。HDFS应用的是主/从结构(master/slave),最早研发的版本中,架构体系包含一个控制模块和多个数据模块,控制节点负责存储和管理元数据信息,一般情况下一个集群系统中只配备一台机器,代替控制模块工作。数据节点则不同,可以同时配备多个机器,共同运转。作为普通软件,借助心跳机进行通信。
1.2.2 MapReduce介绍
在进行程序开发时,技术人员会将复杂的设计流程拆分为多个子任务,子任务之间存在着两种关系。一种是依赖关系,任务的前后顺序不能发生变化,此种情况下不能对任务进行并行处理。第二种则是独立关系,对前后顺序没有明确的要求,可以进行并行处理。因为所需要处理的数据数量极多,且在处理时间上也有硬性规定,因此需要大量的机器来完成这一工作,MapReduce编程模型的出现很好的解决了这些问题[2-3]。
MapReduce是于2004年研发出的一款分布式程序设计模型,可对大于1TB的海量数据集进行并行处理,因其使用方法简单,应用得相对广泛。在MapReduce研发成功之后,它取代了ad hoc程序,以新款谷歌索引的身份被应用,这也从侧面证明了MapReduce拥有良好的使用性能。应用MapReduce时,需要对输入文件进行切割,再将分割后的文件传输给Map函数,根据程序员便携的函数将接收到的文件映射成中间小文件。完成映射后在传送至Reduce,对其进行合并、缩减处理。因其具体操作流程都是一早由程序员设定好的,因此在使用时更具有灵活性。
2 基于Hadoop海量电信数据云计算平台的设计流程
电信运营商分析、处理大批量电信数据时,采用的仍是固有的关系型数据库,若想使用此种分析方法,必须借助高性能机器来完成,不仅耗时长,分析效率也不尽人意,影响业务决策的时效性。基于此种情况,本文提出了建新型云计算平台的构想,结合MapReduce编程软件,完成数据的整理工作,提升数据分析速率,从根本上解决电信运营商难以管理、分析海量电信数据的现状[4]。
2.1 平台设计的目标和原则
设计此款平台的目的是为了提升数据处理的时效性,在构建云计算平台的过程中,可以选用性能一般PC服务器,以此来完成海量电信数据的分析工作,提升数据分析的速率,不仅可以为电信运营商节省投资成本,还能为业务决策提供更具时效性和准确性的辅助参考信息。设计原则包含3个方面,分别为经济原则、高效原则和安全原则。经济原则,由于Hadoop对硬件要求并不高,因此在构建平台的过程中可以充分地调动现有资源,在搭建Hadoop云计算平台时可以使用低端PC服务器。高效原则,依靠精准测算力,快速处理数据,使其更具高效性。安全原则,在构建平台和应用时,应该将自身和信息安全考虑进去,通过必要措施规避使用风险。
2.2 平台框架结构
以海量电信数据自身具备的特点出发,云计算平台在框架结构上可以分成3部分,如图2所示。

图2 云计算平台框架结构
2.2.1 数据层
网络域数据囊括Gb,A和WLAN等多个端口的数据信息,业务支撑域包含的则是用户端的数据,设计自身信息、业务订购和消费数据等多个层面。这些数据通过Hadoop云计算平台上的HDFS模块来进行存储,用Hbase、Hive、Pig和ZooKeeper等软件对所存储的数据进行管理,利用SQL进行指标统计,经MapReduce整合完毕后存储于HDFS中,方便后续的导出和使用[5]。
2.2.2 模型层
模型层,对上一结构层面整理出的信息采取ETL处理,并将其汇总,以此为参数创建分析模型。以客户自身信息、业务订购和消费数据等多个层面入手,创建分析模型,包含用户位置、上网行为、短信行为等多种基础模型,并通过虚拟测试分析出用户位置、离网状态和交际圈等多种信息,可以更好地掌握用户的使用状态[6]。
2.2.3应用层
应用层的工作内容则是利用模型层所分析出的数据锁定目标客户,从用户所处地理位置,日常生活轨迹、套餐业务和增值业务的选择情况等方面入手,设计更能吸引目标客户的运营方案,并对实际推行情况进行总结。
2.3 平台功能模块
云计算平台包含四个功能模块,如图3所示。
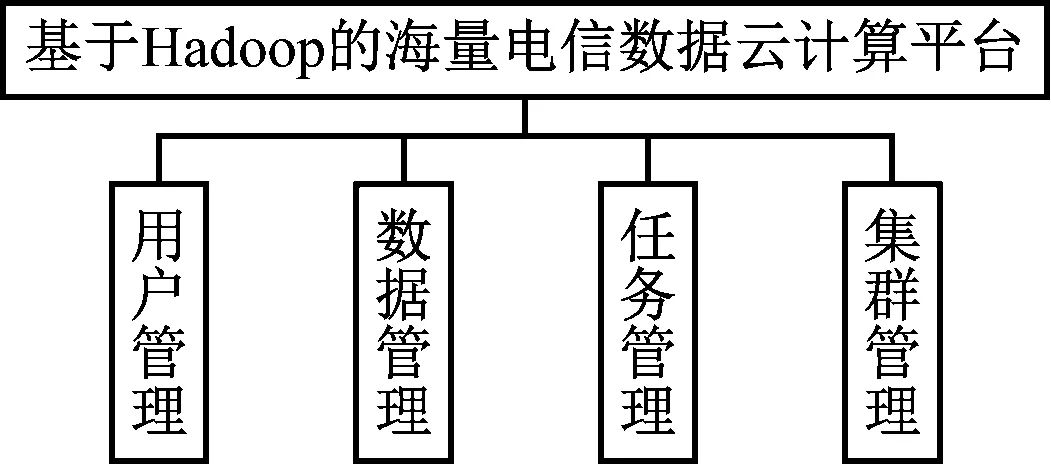
图3 功能模块具体划分
对图3中的4个模块进行了进一步划分。用户管理模块,包括开通账户、身份判定、权限分配和身份交互4个方面。数据管理模块,负责信息的上传、下载,发现无实际应用价值的信息时,及时将其删除。任务管理模块,及时申请自身承接任务,并对申请结果进行反馈。集群管理模块,对任务推进、节点管理进程进行监测[7]。
2.4 网络拓扑结构
云计算平台的网络拓扑包含两个功能分区:前端操作区、后端生产区,如图4所示。

图4 云计算平台网络拓扑结构图
后端生产区:Hadoop集群局域网由NameNode,Secondary NameNode和JobTrack三台服务器构成。NameNode服务器的工作内容是对海量电信数据进行分割和保存,并实时监测DateNode的运行状态。在平台运行时,系统最先完成的是信息读取工作,通过访问NameNode服务器,摸清数据文件所处位置,随后再与其进行通信。如果在运行过程中出现某一个DateNode宕机的情况,会自动启动副本以供应用程序访问,确保云计算平台可以正常运行。Secondary NameNode服务器的工作内容则是监控HDFS的工作状态,并完成和NameNode的通信工作,将HDFS原始数据的快照进行存储,当NameNode发生运行故障时,可将所存储的快照当做备用设备使用。JobTracker服务器的工作内容是对计算任务进行总体调控和监控各节点的工作状态,部分任务失败时,会自动重启,重新完成任务[8]。
3 云设计平台的部分实现和效果
3.1 底层Hadoop集群部署的实现
具体设备配置信息如表1所示。

表1 集群设备配置信息
3.2 实验结果
在提前部署好的虚拟云计算平台进行相关实验。实验一:利用分布式计算法,对单数据节点进行MapReduce计算,测试时长大约为63分钟[9]。计算过程如表2所示。

表2 实验一MapReduce计算过程
实验二:利用分布式计算法,对双数据节点进行MapReduce计算,测试时长大约为37分钟,计算过程如表3所示。

表3 实验二 MapReduce计算过程
通过实验数据我们可以得知,运用Hadoop分布式计算法可以大幅度提升计算速率,将测算时间缩短了3小时以上,且数据节点越多云计算平台的整体性能越好[10]。
4 总结
由于传统数据分析法无法满足大批量电信数据处理的需求,基于此种情况,提出了基于Hadoop海量电信数据云计算平台设计的构想,对其设计流程和功能模块进行了具体阐述,并通过虚拟实验证明了其具备可行性,可以帮助电信运营商提升海量数据的计算效率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
铁道通信信号(2019年9期)2019-11-25 01:44:58
当代陕西(2019年14期)2019-08-26 09:42:00
知识产权(2016年8期)2016-12-01 07:01:13
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
网络空间安全(2016年3期)2016-06-15 20:27:10
中国卫生(2015年12期)2015-11-10 05:13:34
