
基于K-means聚类算法的学生表现数据分析及预测建模研究
2021-06-04 03:15:32吕丁
微型电脑应用 2021年5期
吕丁
(陕西警官职业学院 治安系, 陕西 西安 710021)
0 引言
本文通过对不同校园管理系统数据进行预处理,去除重复、缺失的脏数据,并基于传统K-means算法建立学生表现行为的预测模型,对学生表现行为分类,通过针对不同类型学生特征,实现对学生校园表现的针对性管理。
1 K-means的数据预处理
1.1 数据挖掘
数据挖掘在以海量数据分析的基础上,提取满足不同业务目标数据信息的过程,并将信息反馈给用户。为获得满足用户需求的潜在有效信息,就要求对表层信息进行充分挖掘,去除冗余数据,并将关键数据能可视化的展示到用户面前。预测和描述作为数据挖掘的两个目标,预测指的是利用数据库中某些信息字段和变量预测隐含的有用信息,描述指将数据描述成可理解模式[1-3]。
本文采用ETL工具来获得校园一卡通系统、学生管理系统、图书馆系统和教务系统的数据信息,在对各数据管理系统的基础上,选择“学号、贫困生等级、奖学金等级、德育成绩、体育成绩、智育成绩、竞赛等级”7个属性作为特征评价指标[4-6]。
1.2 数据的清理
数据的清理主要包括格式的标准化、异常数据和重复数据的清除和错误数据纠正。通过查询某一高校成绩管理系统,就能获得近40余万条信息,整个数据量极为庞大,因此有必要对一部分重复数据进行清除,并从其他系统中获取其他维度的数据来补充整个数据库。如成绩系统中包括了学生各科目成绩信息,而学生的奖学金、竞赛信息均处于空缺,同时部分学生的某些成绩表存在很多空缺数据,这主要是由于学生缺考、补考或一些未知原因造成。对于该类噪声数据,从学生状态重查出信息,将学生成绩信息予以删除操作。
针对学生成绩信息,按照学期准则进行聚类,即对各科成绩进行泛化处理,用高级层次值代替,获得各科成绩的泛化绩点,如式(1)。
(1)
式中,i为科目数;Si和Xi分别为第i科得分和学分;J为绩点数。Xi学分划分为优秀、良好、及格、不及格,相应的得分转化分别为90分、80分、60分和0分。
对困难级别的数据变化,将学生困难程度划分为特别困难生、一般困难生、非困难生,对应的级别表示分别为2、1、0。
在学生竞赛方面,学校教务管理系统采用文字形式描述,本文根据分析调查,采用以数字方式来表征竞赛级别,如表1所示。
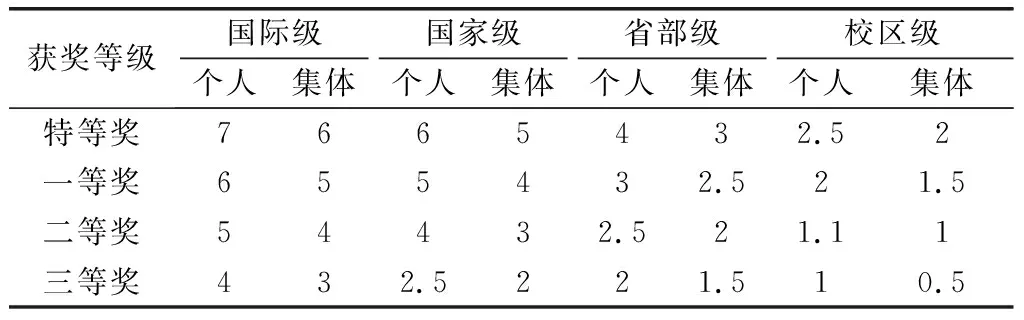
表1 学科竞赛等级分值转换
通过对竞赛等级进行数值转换,形成一个累积的加分制度。
奖学金在学生数据库中同样采用文字表达方式,由于系统中对应每个奖学金等级建立了对应的金额,基于此,本文对学生奖学金力度属性,将奖学金金额转化为相应的力度属性,如式(2)。
(2)
式中,i为奖学金数量;Xi为获得奖学金金额;V为奖学金力度。
在学生管理系统中,德育成绩和体育成绩均是以数据形式存储的,满分分别为20分和5分。
2 优化的K-Means聚类算法
K-Means作为经典的聚类算法,主要是通过迭代过程实现数据集类别的不同划分,该算法具有简单异性可扩展性强的优点[7-8]。K-Means算法首先从样本集S中任意选择K个样本作为初始聚类中心。然后根据规则算法进行数据对象间距离,通过获得的数据对象分组情况迭代计算直至中心无变化,得到K各聚类结果。算法的具体实现流程如下。
(1) 在K-Mean聚类算法中,设定算法输入样本集中包括n个数据对象和K个聚类个数;
(2) 根据聚类样本聚类,计算得到各样本与中心间距离,然后根据获得的最小计算距离重新划分对象。设两个p维数据点xi=(xi1,xi2,…,xip)和xj=(xj1,xj2,…,xjp)间的欧氏距离,如式(3)。
(3)
确定所有样本的平均距离为式(4)。
(4)
(3) 重新计算获得每个样本的均值后,返回步骤(2),直到目标函数值不变或小于指定阈值。确定目标函数的平方误差准则函数,为式(5)。
(5)
式中,ci为相同类别数据的质心点,定义ci计算公式为式(6)。
(6)
式中,|Ci|是类Ci数据对象数量;ci表示第i个簇中心。
(4) 结束,获得K个聚类。
对于K-means算法,算法简单,效率高。但算法聚类数K时和中心点的选取都缺乏明确标准定义,大部分都是随机给定的,这样容易对算法结果造成较大影响。基于此本文提出一种解决初始值K的选择方法。在K值选择中,根据实际情况限定聚类的范围,即假设聚类数K范围为(m,n),则进行n-m次K-means传统算法,并从多次聚类中选择最优聚类数作为最佳聚类树,设聚类各部各节点距离中心的欧氏距离为式(7)。
(7)
在初始点选取中,要求中心点互相距离最大化,初始中心周边点必须密集。对于中心点互相距离为式(8)。
(8)
d作为所有中心点距离和的均值,能较好地表现聚类中心相互距离整体情况。对于聚类中各元素点的密度,计算方法,如式(9)。
(9)
式中,pi点xi周围点密集程度,值越大,密度越大,则周围点越多。其中zi为样本点间距离,因此采用pi能较好地反应出i点周围密集程度,确定zi的计算,如式(10)。
(10)
通过优化的K-means算法的具体流程如图1所示。

图1 改进的K-means算法流
3 学生校园表现聚类分析
3.1 样本数据处理
通过对K-means算法改进,根据上节对数据预处理的基础上,选择“贫困生等级、奖学金等级、德育成绩、体育成绩、智育成绩、竞赛等级”数据作为六维评价输入变量,设定最大迭代次数为10,经过预处理后的数据格式如图2所示。

图2 整理的学生数据表
上述数据是基于不同量纲获得的整合数据,因此,需要对这些不同维度数据进行量纲统一,具体的计算为式(11)。
(11)
其中,xij为个体元素值。通过量纲统一后的待测数据能更真实的反映学生活动的数据聚类情况。
3.2 算法的核心代码优化
定义算法所用到的数据的类属性,如图3所示。

图3 初始化函数运行代码
其中,K为聚类数;logo为分类标识;center为数据旧中心;centernew为新中心;train为输入数据样本;dimension为数据维度。对算法数据进行初始化操作,每进行一次优化算法则执行一次初始化函数。图3为函数的运行代码。其中表示拥有30组测试数据,一组6个维度,并确定初始化数据中心和K值的大小[6]。
算法在Windows 8PRO操作系统运行,数据库采用SQLsever 2 000,navicat,给出改良后的K-means算法的部分核心代码,如图4所示。

图4 改进K-means算法的核心代码
3.3 优化分析结果
通过聚类分析,获得选取学生的分类信息和各方面的平均值结果,如表2所示。

表2 学生类别平均分析值
优化K-means算法将学生分为4个类别。其中第一类学生成绩中等,家庭较困难,并没有享受过奖学金或竞赛奖励;第二类学生成绩下游,家庭一般,未享受奖学金和竞赛奖励;第三类学生成绩良好,竞赛成绩优秀,享受奖学金较高,家庭一般;第四类学生成绩优秀、获得过奖学金和竞赛奖励,家庭困难。
学生管理系统中几位学生的分类情况,如图5所示。

图5 学生表现情况分析表
由图5可知,根据选择的类别属性,系统将每一位学生根据自己的学号得到了其在德育、体育、竞赛、智育、奖学金、贫困情况方面的分类级别。根据聚类算法后的学生分类结果,可以让高校辅导人员对学生的具体情况进行有针对性的管理,符合当前高校学生“德、智、体、美、劳”的综合发展需求。
4 总结
本文选择学生校园表现进行研究,通过对学生生活、学习、活动等行为特征数据分析挖掘,采聚类算法建立学生生活表现类别模型,实现对学生生活表现数据,将学生进行分类。文中以校园一卡通系统、教务管理系统、学生管理系统数据为基础,针对数据系统中“脏数据”进行预处理,通过数据清洗、集成和变换数据存储格式,得到满足K-mrans算法的维度输入数据。针对传统K-mrans算法聚类数K、中心点的选取容易造成算法结果偏差,根据实际情况限定聚类的范围,得到最佳聚类K值和中心点,并添加量纲矩阵系数对学生表现进行聚类,最后通过在学生管理系统中写入算法核心代码建立学生表现模型,分析出不同类型学生行为特征,并指导学生日常管理工作。
猜你喜欢
中等数学(2022年3期)2022-06-05 07:50:56
承德医学院学报(2022年2期)2022-05-23 13:01:44
华人时刊(2022年1期)2022-04-26 13:39:36
英语文摘(2019年5期)2019-07-13 05:50:30
中国交通信息化(2018年8期)2018-11-09 01:05:50
作文通讯·高中版(2017年11期)2017-12-20 08:09:36
中学生数理化·高一版(2017年3期)2017-07-08 08:25:39
中国船检(2017年3期)2017-05-18 11:33:08
大学生(2016年7期)2016-04-29 20:30:06
塔里木大学学报(2014年3期)2014-03-11 18:47:28
