
基于内存计算的图书馆文献服务模式构建研究
2021-06-04 03:09:08于芳
微型电脑应用 2021年5期
于芳
(哈尔滨工业大学(威海) 图书馆, 山东 威海 264209)
0 引言
在当前的大数据时代背景下,现代图书馆的文献逐渐增多,数据处理越来越复杂。文献服务涵盖类数据检索、文献标准等方面内容,具有总量大、种类多、高价值低密度特性,因此为读者提供高效精准的文献服务成为现代图书馆面临的主要任务[1-2]。采用先进的“计算”收到来实现数据价值的深层次挖掘,成为一种必要的方式[3-5]。目前,人们通过提高单个CPU处理速度在一定程度解决了数据处理问题,但数据的I/O速度成为制约瓶颈[6]。而共享内存试图通过增加数据库缓冲池来实现数据处理提升的目的,但受限于数据库技术和操作系统,难以满足实际需求[7]。内存计算通过将处理数据一次性存取,避免了对数据的频繁操作造成的处理时间延长,但在海量数据量下,如何高效、精确查找到所需要的文献资料,成为目前资料查阅迫切解决的需求[8-10]。目前比较典型内存计算主流框架有Apache 的Hadoop+Spark系统,应用较多的的内存计算产品如SAP HANA等[11]。本文基于图书馆数据信息特征,利用内存计算中Spark系统框架高的容错机制和实时运算优势,提出一种基于短句“字符串匹配”和文档的“相似度匹配”下的混合关联算法,实现图书馆文献查阅过程中的准确推荐需求。
1 图书馆推荐服务内存算法
对于图书馆而言,推荐是通过科学合理化建议来帮助读者选择满足需求的图书、论文、专利文献。推荐算法作为图书馆个性化服务系统设计的核心模块,推荐质量直接影响到服务效率和质量[12]。传统的图书数据推荐难以满足不同客户需求的个性化、精准化推荐,因而导致用户节约转化率低。在大数据环节下,利用大数据挖掘算法,来提升推荐算法的精准性、新颖性等性能,成为迫切解决的问题[13]。目前,主流的推荐算法包括内容推荐算法、协调过滤推荐算法以及混合推荐算法[14-16]。
关联规则作为数据挖掘领域的重要技术,用来发现用户使用文献间的关系。基于关联规则推荐算法首先根据用户使用文献构成关联规则,并通过浏览、查阅行为进行推荐,但用户使用文献数据较大时,则需要通过信道数据挖掘获得用户使用文献的关联规则。基于内容的推荐算法根据不同文献间存在的相似度进行推荐,通过数据挖掘对用户文献内容进行评分,建立档案模型,根据评分筛选推荐给用户。
协同过滤算法中,根据不同的对象分为基于用户、物品和模型的协同过滤。基于用户协调算法相当于一类聚类算法,即根据用户对文献的评价日志进行用户间相似度计算,根据相同评分层次的邻居用户来推荐相应的文献;基于物品的协同则通过物品间相似度进行,即对文献进行聚类,推送给特定用户;基于模型的协同通过对用户历史借阅信息来构建模型,采用概率模型、人工神经网络等数据挖掘技术进行图书评价预测,通过数据挖掘算法获得的历史数据向用户推荐图书文献。
混合推荐算法则是综合了多种推荐技术获得的推荐结果,最终形成一个推荐列表。混合推荐算法有效避免了单一推荐算法的弱点,模型级联融合和加权融合作为两种方式,将人工神经网络、大数据回归算法和概率模型、回归算法等线性和非线性技术融合起来,提高推荐结果精确度。
本文针对图书馆文献数据格式多、类型复杂的特点,为避免文献查找缺陷、文献浏览迷航、文献分析效率低的特点,基于大数据环境下,提出一种新的混合推荐算法,针对文献间相似度较大的情况,采用“字符串匹配”和“相似性度量”的文献关联,利用参数优化提升推荐性能,避免“文献缺失”,通过构建文献列表来概述“浏览迷航”的问题,同时,基于Spark框架构建内存算法结构,提升大数据系统性能,提升文献推荐算法的分析效率。
2 图书馆文献推荐的混合算法
2.1 文献推荐的混合推荐算法
当用户根据自身需求登录图书馆信息系统,查阅感兴趣的文献链接时,系统通过用户浏览文献的特征度来查找相似的文献。基于此,本文提出的混合推荐算法即根据浏览的文件相似度特征来进行匹配度排名后,推荐给客户。因此,基于用户兴趣和文献数据来构建混合关联模型,具体以用户感兴趣的文献特征建立用户偏好模型,同时根据文献特征和用户匹配度来建立海量文献的数据建模。根据用户兴趣模型从数据库中选定相似匹配度高的文献进行排序,并推荐给用户。基于用户兴趣的文献数据模型的混合推荐算法,如图1所示。
从图1中可以看出,利用Sparik RDD来支撑“字符串匹配”,利用Spark MLlib支撑“相似性度量”。采用混合推荐算法主要是根据用户需求推荐不同类型的的文献,如“图书到图书”或“图书到文献”间不同类型的推荐。为提高推荐性能,其中建立了“字符串匹配”和“相似性度量”关联方法。“字符串匹配”主要将“作者”“关键词”等文献数据库中规划化的元数据进行比较,确定不同文献间的字符串是否关联。“相似性度量”主要将文献“摘要”“篇名”等内容较长切标书灵活的文档类型进行相似度计算,并整合成混合权重进行排名推荐。
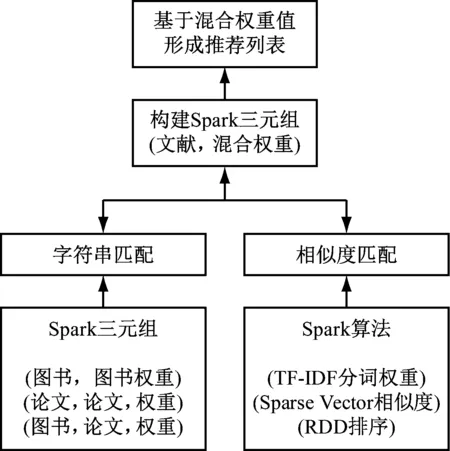
图1 图书文献混合推荐算法
2.2 混合关联算法的流程
根据上节中算法的结构框架,建立“混合关联”推荐算法。具体流程如图2所示。
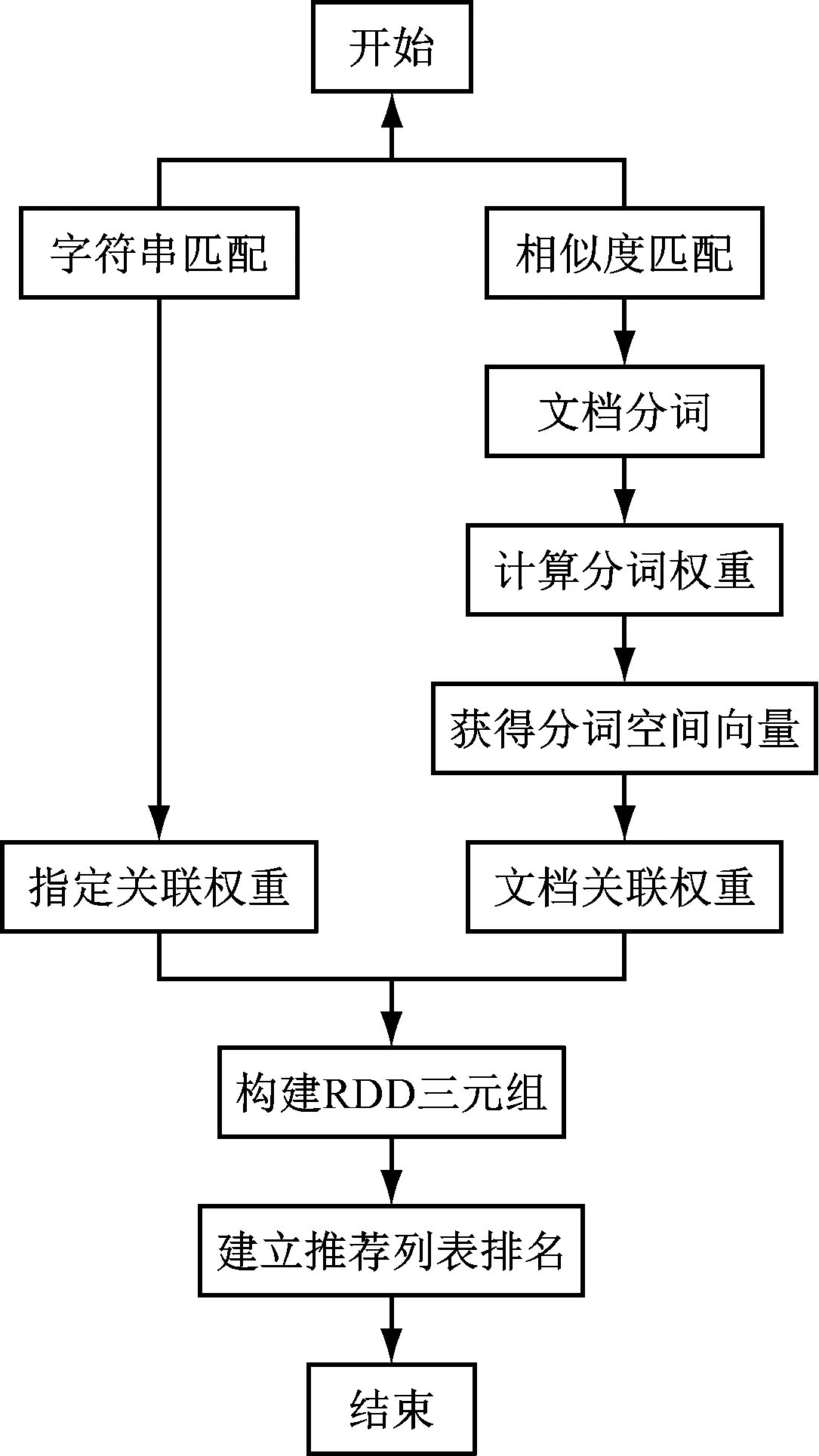
图2 推荐列表实现流程
图中包括了“字符串匹配”“相似性度量”“混合关联权重计算”“推荐列表”排名四个具体步骤。
字符串匹配中,抽取图书数据库中的“作者”“关键词”信息与论文数据库进行关联。如图书数据库和论文数据值相同,则建立两个文献的关联Spark RDD三元组(id1,id2,Wchar),其中id1和id2分别为两个文献id;Wchar为字符关联度权重,反映关联的重要程度。
相似性度量中,通过抽取图书数据库中的“书名”“内容介绍”与论文数据库中的“篇名”和“摘要”进行关联。由于文档内容较长,因此,采用文档相似度关联时,首先利用分词软件对文本进行预处理,去除停用词,保留分词,通过TF-IDF()算法获得分词的TF/IDF值作为权重值。这里的TF为某一文档个中该分词出现的频数,如式(1)。
TF=T/M
(1)
其中,T为文档中词语总数;M为该分词出现次数。
IDF为反文档频率,用于鉴定某一分词在文档中的区分能力,如式(2)。
IDF=log(D/(Dw+1))
(2)
式中,D为数据库中文档总数;Dw为出现该分词的数量,通常Dw越小,IDF越大,则表明该分词越重要。
将计算获得的分词TD-IDF值生成新的文档向量模型,其中w=TF*IDF作为该分词的权重,计算文档D1和D2的余弦相似度Sim(D1,D2)作为“相似性度量”权重WSim,建立基于(id1,id2,WSim),如式(3)。
(3)
式中,s为模型分词列表长度;wi1、wi2为文档对应分词权重。
再进行“混合关联”权重计算,得到“字符串匹配”权重和“相似性度量”权重,并将结果作为文献id1和id2的最终关联权重Whybrid,建立格式为(id1,id2,Whybrid)的RDD三元组,如式(4)。
(4)
式中,a为调和参数,确定两个关联比重[17];m,n为两类关联关联此次;k为关联种类求和变量。
根据获得的Whybrid大小排名,获得推荐列表,利用Spark中的RDD函数包中的rdd.sortBy()进行函数排表,将文献相关度高的文献排名靠前。
3 实证研究分析
3.1 运行平台
为验证本文提出的混合文献推荐算法的可行性,本文以某大学图书馆馆藏书名数据库为对象进行实例分析。其中实证数据来源包括该校图书馆藏书数据库共1 243 557条数据,同时,通过爬虫软件从互联网中收集共472 536条文献数据,其中期刊论文373 327条,硕博论文125 646条构成研究论文库。
系统运行在3个节点的Spark集群上。考虑到数据计算量较大,将系统分为Spark离线计算部分以及Web界面部分。离线计算用于在Hadoop+Spark平台计算文献间关联权重,建立RDD三元组;Web界面能直接调取数据库结果,并实时推荐和显示。
3.2 推荐性能评价
目前针对文献推荐性能的指标评价有多种类型[18]。本文在相关研究的基础上,采用准确率来评价算法的推荐性能[19]。即在推荐列表中用户真正感兴趣的类型所占的比重,建立起准确率计算公式,如式(5)。
Pre=N/L
(5)
式中,L为文献推荐列表长度;N为感兴趣文献数量。
根据研究,为保证算法的准确率,确定该“混合关联”调和参数a取值范围在0.5-0.7。本文中根据算法特点,确定a=0.6[20]。
3.3 结果和讨论
全数据集调价下,不同长度推荐列表的准确率。如图3所示。
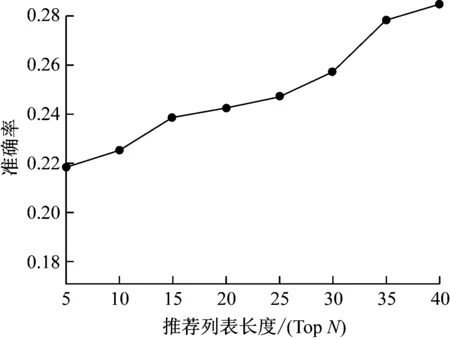
图3 不同推荐列表长度下的算法准确率
通常准确率指标表征了符合用户兴趣的文献占比。从图3中可以看出,随着TOPN长度的增加,与用户偏好具有高相似度论文进入列表的概率逐渐上升,由于采用本文算法是融合论文不同特征构建的空间向量模型,因此能够有效提取文档特征,从而当文献列长度更大,则相应的关联相似度更大,则表现出更高的准确率。
TopN=10条件下,不同论文库规模下的算法准确率测试结果,如图4所示。
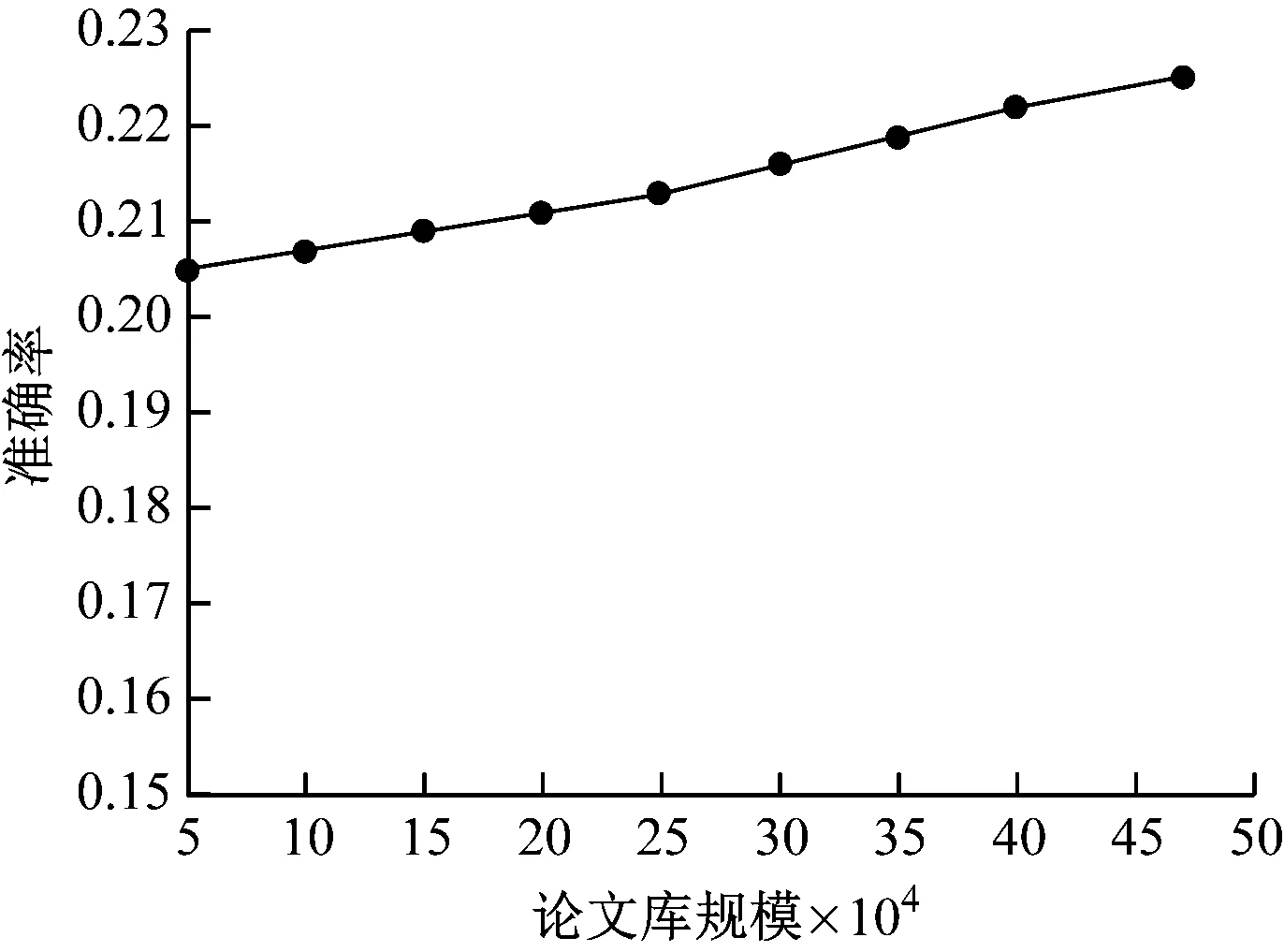
图4 不同论文库规模下的算法准确率
可以看出,随着论文库规模不断增加,数据更为丰富,算法的准确率稳步提升。采用RDD关联三元组算法是基于“先计算后检索”方案进行,能够根据所需文献形成的两两相似度数值进行检索排序,因而论文库越大,则相似度数值越精确,准确率越高。
4 总结
本文在大数据背景下,提出了一种“混合关联”的图书馆文献推荐内存算法。通过将短文本“字符串匹配”和长文档“相似性度量”进行匹配,引入调和参数实现不同分词相似度的融合,提高文献的相互关联性。并通过构建文献、权重间的Spark RDD三元组实现文献的交叉推荐,根据不同的混合权重排名获得不同长度推荐列表。在引入准确率进行算法的评价中表明,该算法在较大图书资料系统中依然具备了非常高的准确率,并能够满足用户对感兴趣资料文献的查找需求。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
当代陕西(2019年15期)2019-09-02 01:52:00
智富时代(2019年6期)2019-07-24 10:33:16
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
信息安全研究(2016年4期)2016-12-01 06:06:54
高中生·天天向上(2016年9期)2016-11-22 09:10:34
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
电脑迷(2012年4期)2012-04-29 06:12:13
