
耦合PCM的随机森林算法研究
2021-06-04 09:23钟雯静张伟劲何雪梅常睿春
科技经济导刊 2021年14期
钟雯静 ,张伟劲 ,何雪梅 ,常睿春
(1.成都理工大学 数学地质四川省重点实验室,四川 成都 610059;2.成都理工大学 成都理工大学数字胡焕庸线研究院,四川成都 610059;3.成都理工大学 信息科学与技术学院(网络安全学院),四川 成都 610059)
随机森林算法具有较好的分类性能,一直是广大研究者们的热门研究对象,被广泛应用于数据挖掘、数据分析领域。随机森林的改进主要体现在以下几个方面:(1)数据的预处理;(2)对RF中生成的决策树改进;(3)对投票方式的改进。但是由于数据集的复杂性,尽管随机森林具备较好的性能,仍然容易陷入过拟合或局部最优的情况。基于此,本文提出了一种耦合可能性C-means聚类的RF算法,先用AUC值对传统RF的决策树进行评估,选出AUC值高的树,再进行可能性C-means(pCM)聚类,选取每一类中AUC值最大的决策树组成新的子森林。这种改进方法既能够舍弃分类性能差的决策树,又能改善相似性高的决策树出现分类错误的情况,在分类精度和分类时间上皆优于经典SVM和传统RF算法。
1. 算法改进
1.1 可能性C-means聚类(PCM)
本文采用的聚类方法是pCM聚类算法,是基于模糊C-means聚类(FCM)的一个改进。以下是有关pCM算法的介绍:
pCM目标函数:

N为样本个数,C为聚类中心个数(2≤C≤N);m为加权指数且m∈[1,∞),关于m的最佳取值目前还没有充分的理论研究作为支撑,一般情况下取m=1.5;为每个聚类的中心,表示样本到聚类中心的距离;η是由FCM算法得出U,C后直接计算作为定值,通常取K=1:表示各个样本到每个聚类中心距离的加权平方和。越小表示聚类效果越好。

1.2 评估指标
本文将AUC值作为随机森林算法里单棵CART决策树分类精度的评估指标,AUC值越高,模型的分类性能越好。
AUC值的计算公式:

其中表示第条样本的序号,M、N分别表示正、负样本的个数,表示只加正样本的序号。
1.3 PCM-RF模型
传统的随机森林算法具有泛化能力强、拟合效果好、对部分缺失值不敏感等优点。为提升分类精度,可适量增加RF中的决策树数量,但此种方法也有弊端:如分类时间会增加且易陷入过拟合。生成的决策树分类性能也有优劣之分,若某棵树分类错误,则其他与之相似度高的树也会获得错误的分类。基于此,本文提出了pCM-RF算法:计算传统RF中每棵CART树的AUC值及AUC值的中位数Me,筛选出q棵AUC值高的决策树,对选出的树进行pCM聚类,从每一类中选取分类精度最高的树构建新的随机森林。将中位数Me作为选取标准可使得子森林中树的数量不会超过原始森林的1/2,达到简化决策树数量目的,pCM-RF算法不仅能获得更高的分类精度且能节约分类时间。
2. 实验设计
2.1 数据集
UCI数据库是由University of CaliforniaIrvine提出的标准数据库,本文实验用到的数据集皆来自于此,它们分别是Winequality-red,Abalone,Haberman’s Survival.Winequality-red包含4898个样本,12个特征,共11类;Abalone包含4177个样本,8个特征,共29类;Haberman’s Survival包含306个样本,2个特征,共3类。
2.2 实验过程
由于经典SVM算法具有良好的学习能力且分类性能好,是机器学习里占据主导地位的算法之一,因此本文在把pCMRF算法与传统RF算法分类性能作对比的同时,也与经典SVM算法作了对比分析。本文实验以分类精度作为算法分类效果的评估指标,采用10折交叉验证的办法,将数据均分为10份,轮流将9份数据作训练集,1份数据作测试集,让所有的数据都有同等的机会作为训练集和测试集,最后取10次实验之后的结果均值作为模型性能的评估。实验流程如下:
输入样本数Y,聚类中心数C,权重指数m,最大迭代次数Max_iter,迭代阈值ε;
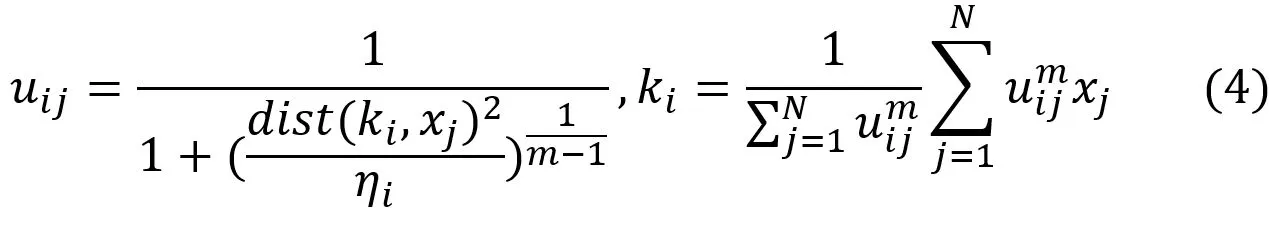
求出:

通过对聚类中心C和隶属度矩阵U的不断更新,计算目标函数J(U,C)当两次结果的变化量小于迭代阈值ε时,迭代停止,输出隶属度矩阵U和聚类中心数C。
(4)从每一类选出AUC值最高的树构成新的子森林,得到pCM-RF模型。
2.3 实验结果与分析
用pCM-RF算法对3.1中三个数据集进行分类,得到各自的分类精度和分类时间,再用经典SVM和传统RF算法对数据分类的结果作为对比实验。具体的分类精度与分类时间见图1和表1。

图1 不同算法下的分类精度
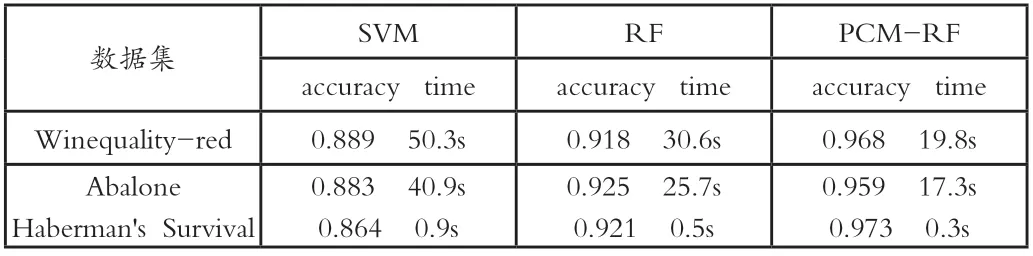
表1 不同算法下的分类精度和分类时间
从实验结果可以看出,pCM-RF算法在分类精度和分类时间两方面皆明显优于传统RF和SVM算法。与经典SVM算法相比,分类精度提升了8.6%~12.6%,分类时间减少了57.7%~66.7%;与传统RF算法相比,分类精度提升了3.6%~5.6%,分类时间减少了32.7%~40%。
2.4 分类精度分析
随机森林算法中某些参数会影响算法对数据分类的精度,上述实验仅对pCM-RF算法与经典SVM和传统RF算法作了一个横向的分类精度比较,下面将调整pCM-RF中CART决策树的深度作纵向分析,通过不断调整树的深度得到不同的分类精度,分析树的深度对最终分类精度的影响。
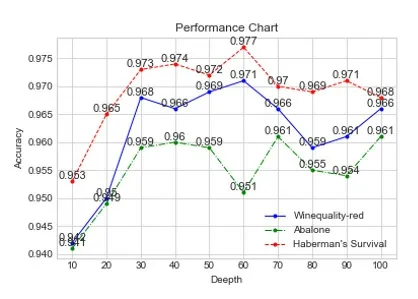
图2 不同深度下PCM-RF的分类精度变化
从图2中可以看出,当模型中CART决策树的深度大概在30~60这个范围内时,模型的分类性能达到最优。当树的深度为60时,在Abalone数据集上出现了一个波动,这是由于pCM-RF在进行分类时,由于随机性会出现比上一次分类效果更差的情况,但是这个波动非常微小,属于正常范畴。
从图3中可以看出随着深度的增加,模型的拟合效果逐渐优化,但是当深度超过50之后,模型在训练集上的均方误差逐渐减小,在测试集上的均方误差逐渐增大。由此可推断,当树的深度增加到一定的程度,模型会陷入过拟合的现象,所以对深度参数的设置应控制在30~50这个范 围内。

图3 不同深度下PCM-RF的拟合效果
3. 结语
本文以分类精度和分类时间作为模型评估指标,通过选出高精度的子树,对子树进行pCM聚类,最后选出精度高、相似度低的树构建新模型,即pCM-RF算法。通过对UCI数据库中的3个数据集进行实验,证明了经过改进后的随机森林算法在分类精度和分类时间方面都要优于传统的随机森林,说明作此改进提升了随机森林的分类性能,同时也节约了分类时间。最后通过调整pCM-RF模型中决策树的深度,分析其对分类精度的影响,根据实验结果可知,当树的深度不断增加,模型的分类效果会有所优化,但是树的深度不能过深,否则模型容易陷入过拟合。
由于聚类方式和模型性能评估指标有许多,可选取别的聚类方式和评估指标再次实验。因此接下来的研究工作应从以上两个方面入手,即寻找更优的聚类方式和选用其他精度评估指标进行实验再做比较分析。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2022年8期)2022-08-31
一重技术(2021年5期)2022-01-18
数码世界(2020年4期)2020-06-18
科学与信息化(2019年28期)2019-10-21
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
科学与财富(2016年32期)2017-03-04
互联网天地(2016年1期)2016-05-04
华人时刊(2016年16期)2016-04-05
