
基于模约束CentreFace的低分辨率人脸识别
2021-06-03 06:39范文豪吴晓富张索非
计算机技术与发展 2021年5期
范文豪,吴晓富,张索非
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 物联网学院,江苏 南京 210003)
0 引 言
近年来,人脸识别[1]问题引起了越来越多研究人员的关注。在具有一定约束环境下的人脸识别问题, 它们的识别精度已经取得了极大的提高。然而,低分辨率人脸识别问题在人脸识别领域仍然具有挑战性。在人口较稠密的公共场所[2-3],例如购物商场和游乐园,通常需要通过从监控视频中获得的图像来寻找具有特殊身份的人。但是,由于行人与监控摄像头之间距离较远以及摄像头的分辨率有限,通常只能够获得较低分辨率的人脸图像。在这种情况下捕获的人脸经常是模糊的、光照不均匀的或人脸姿势[4]不正确的,这些干扰因素使得基于深度模型和预处理的技术(例如人脸正面化和人脸对齐),不能直接应用于低分辨率的人脸图像[5]。
对于人脸识别中的低分辨率问题,已经有了许多解决方法。这些方法大多数基于超分辨率(super resolution,SR)技术[6-7]来尝试提高图像的质量,将复原后的较高分辨率图像用于人脸识别。尽管基于深度学习的SR技术使得重建后的图像在主观图像质量评价指标上取得了较好的评分,但重建后的图像通常过于平滑,会丢失高频细节信息。当图像的分辨率非常低时,通常会出现上述情况,导致恢复的高分辨率图像和低分辨率图像差异明显,识别性能显著下降。
为了提高低分辨率人脸识别的准确率,该文针对低分辨率人脸识别问题对CentreFace方法进行了改进。主要的改进包括以下三个方面:(1)提出新的模损失函数与原来的损失函数进行联合训练,以学习在类内距离不变的情况下,具有更大类间距离的人脸识别模型;(2)在训练过程中,随机更改输入图像的亮度,以进行数据增强;(3)改进了传统CentreFace中模型的训练方法,能够使模型收敛的效果更好。实验结果证明,改进方案可以有效地解决CentreFace方法中的不足,使得在低分辨率人脸识别问题中具有更好的识别精度。
1 相关工作
低分辨率人脸识别是一种特殊的人脸识别问题,用于解决这类的方法可以大致概括为两种:一种是图像的超分辨率技术,另一种是图像分辨率不变的学习方法。第一种方法主要采用超分辨率和去模糊技术,将输入的低分辨率人脸图像转换为对应的高分辨率人脸图像,从而可以采用高分辨率人脸识别(HRFR)技术。第二种方法旨在学习分辨率不变图像的人脸特征。在许多论文中都对第一种方法进行了尝试,但是从结果来看使用这种方法对识别精度的提升并不明显。
为了获得具有高度区分性的人脸特征,近年来提出了一系列新的深度学习人脸识别方法,例如DeepID2[8]、FaceNet[9]、CentreFace[1]、SphereFace[10]和ArcFace[11]等,这些方法在解决高分辨率人脸识别问题时通常能够表现出良好的性能。2014年提出的DeepFace和DeepID系列主要是先训练Softmax多分类器;然后抽取特征层,用特征再训练另一个神经网络、孪生网络或组合贝叶斯等人脸验证框架。2015年FaceNet提出了一个绝大部分人脸问题的统一解决框架,直接学习嵌入特征,然后人脸识别、人脸验证和人脸聚类等都基于这个特征来做。FaceNet在DeepID2的基础上,抛弃了分类层,再将Contrastive Loss改进为Triplet Loss,获得更好的类内紧凑和类间差异。但人脸三元组的数量出现爆炸式增长,特别是对于大型数据集,迭代次数显著增加;导致样本挖掘方法使得很难有效地进行模型的训练。2016年提出的Center Loss为每个类别学习一个中心,并将每个类别的所有特征向量拉向对应类别中心,根据每个特征向量与其类别中心之间的欧几里得距离,以获得类内紧凑度;而类间分散则由Softmax Loss的联合训练来保证。然而,在训练期间更新实际类别中心非常困难,因为可供训练的人脸类别数量急剧增加。2017年SphereFace提出A-Softmax,是L-Softmax的改进,提出了角度间隔损失,又归一化了权值W,让训练更加集中在优化深度特征映射和特征向量角度上,降低样本数量不均衡问题。2018年ArcFace提出加性角度间隔损失,θ+m,还归一化特征向量和权重,几何上有恒定的线性角度margin。直接优化弧度,为了模型性能的稳定,ArcFace不需要与其他损失函数联合监督。
在QMUL_SurvFace论文中,采用了五种不同的人脸识别方法实现监控下低分辨率人脸识别挑战。但是仅使用论文中提出的QMUL_SurvFace数据集进行训练时,并不是所有的FR模型都可以达到收敛。然而,五种不同的FR模型都可以在CASIA数据上成功训练并收敛。在所有这些FR方法中,使用CASIA和QMUL_SurvFace数据集进行训练的CentreFace模型,可以在QMUL_SurvFace基准测试上得到最佳Rank1识别率为25.8%。因此,该文针对低分辨率人脸识别问题对CentreFace方法进行一系列改进。同时,还与其他较好的FR方法进行了比较。
2 CentreFace方法介绍及改进
2.1 CentreFace介绍
在本节中,首先简单介绍一下CentreFace方法,然后指出CentreFace在用于低分辨率人脸识别问题时的一些缺陷,接着对CentreFace方法提出一系列的改进。
通常,CentreFace采用尺寸为112×112的RGB图像作为输入,并将输入图像像素大小压缩至[-1,1]。将参数N设置为模型训练时输入的batch大小,然后使用具有不同结构的CNN模型作为骨干网络从人脸图像中提取深度特征进行分类。模型的输出是尺寸为d的脸部特征向量,可以使用xn表示。为了对特征向量进行分类,在网络的最后添加了一个全连接层用于计算logits。全连接层中参数W的尺寸为d×M,M为训练集中类别数量。
在训练过程中,采用Softmax损失函数来监督类间特征向量进行分离,可表示为:
其中,xn表示第n个特征向量[12-13],yn是对应于xn的类别,Wm表示最后全连接层权重W的第m列,b是偏差(可省略),N是batch大小,M是训练集种类个数。Softmax损失函数确保可以通过决策边界来区分学习到的不同类别的深度特征。
如果仅使用Softmax损失函数进行训练,虽然可以在训练过程中很好地区分不同类别的特征向量,但最终的测试结果会很差,因为类间不够紧凑。所以加入中心损失函数来减少类内距离,可表示如下:
其中,cyn表示yn类的中心特征向量,它应随着训练数据的不断更新而变化。在对cyn进行更新时,有两点需要注意。首先,每次更新cyn时不是基于整个数据集而是基于当前的小批量训练集进行更新。在迭代过程中,每个类中心点的变化取决于这个batch中相应类的特征向量的均值。在这种情况下,每次进行迭代时,并不是所有中心点都会进行更新,因为每个batch中经常不能包含所有的类。其次,为了避免由少量错误标记的样本引起的大扰动,需要使用一个小的常量来控制中心向量的学习率。要对cyn进行更新,需要计算LC相对于xn的梯度,cyn的更新步骤如下:
中心损失函数可以在保持不同类的特征可分离的情况下,最大程度地减少特征的类内距离。在算法描述中,总结了联合监督[14]下CentreFace训练步骤和细节。
2.2 CentreFace缺陷及改进
在本节中,将会指出CentreFace应用于低分辨率人脸识别问题时的两个缺点,并针对这两个问题加以改善。首先,如果仅使用Softmax损失函数和中心损失函数来训练模型,会发现中心损失函数的值在训练过程中会不断减小,但是各类的中心点到原点的距离也在不断减小,这意味着类内和类间距离都减小了,这种现象并不能证明中心损失函数的减少对于分类效果是有利的。更加直观的解释可以参考图1(a),在这种情况下,类内距离的减少对于分类是没有作用的。为了改进CentreFace这一缺点,在Softmax损失函数和中心损失函数的基础上又添加了一个模损失函数,在保持类内距离的情况下,增加类间距离。提出的模损失函数表示如下:
其中,LN损失表示每个类中心点到原点O的平均距离。在总的损失函数中加入LN是为了防止在训练期间随着类内距离的减少,类间距离也随之减少。模损失函数的影响如图1(b)所示。采用Softmax损失、中心损失和模损失的联合监督来训练判别特征学习模型。总的损失函数如下:
L=LS+λ1LC+λ2LN

图1 特征分布
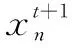

参数初始化和训练方法:参数:首先初始化卷积层中的参数θC,全连接层中的参数W,和每个类的中心点{cmm=1,2,…,M},设置超参数λ1,λ2,α和学习率μt,迭代次数t←0。训练步骤:1:while not converge do2:t←t+13:计算总的损失函数Lt=LtS+λ1LtC+λ2LtN4:计算反向传播梯度:∂Lt∂xtn=∂LtS∂xtn+λ1∂LtC∂xtn+λ2∂LtN∂xtn5:更新参数W:Wt+1=Wt-μt·∂Lt∂Wt=Wt-μt·∂LtS∂Wt 6:更新参数cm:ct+1m=ctm-αΔctm 7:更新参数θC:θt+1C=θtC-μt∑Nn∂Lt∂xtn·∂xtn∂θtC 8:end while
3 实验与分析
在本节中,首先介绍作为低分辨率人脸识别问题的基准数据集QMUL_SurvFace。然后,在该数据集上进行四组对比实验。通过实验结果证明对CentreFace方法进行改进的有效性。
3.1 数据集介绍
为了能促进更多的研究人员来开发有效且鲁棒的人脸识别方法来解决低分辨率人脸识别问题,一个新的监控下人脸识别挑战在论文中有所介绍,该挑战称为QMUL_SurvFace。这一新挑战是目前最大的且唯一一个真实的监控下人脸识别问题。在该挑战中,低分辨率人脸图像是由监控摄像头拍摄得到,而不是通过对高分辨率图像的人工下采样来合成的。数据分布可见表1。QMUL_SurvFace数据集包含463 507张低分辨率面部图像,这些图像来自于15 573个不同的人。在数据集中,人脸图像有着不同的姿势、遮挡、背景、亮度,且伴随着一些运动造成的模糊和其他干扰因素。其中有10 638(68.3%)个人有两张以上的人脸图像。10 638个人分为两部分:其中一半(5 319)作为训练数据,另一半(5 319)加上剩余的4 935(总计10 254)作为测试数据。QMUL-SurvFace数据集中人脸图像的分辨率非常低,这使得监控下的人脸识别任务非常具有挑战性。面部的空间分辨率的长度/宽度范围为6/5至124/106像素,平均值为24/20。由于分辨率太低,导致人脸检测操作不能检测出QMUL_SurvFace数据集中所有图像中的人脸,人脸对齐[15-16]操作也就无法进行。

表1 QMUL_SURFFACE挑战数据集划分
3.2 网络模型
文中使用的网络模型以34层和50层的ResNet为主,具体参见表2。fc1层的输出是输入人脸图像所提取到的特征向量。fc2层的输出向量的维数为训练数据集种类数,以QMUL_SurvFace数据集为例,网络模型输出维数为5 319,网络输入图像的尺寸为112×112。为了分析提取到的特征维度对结果的影响,对比实验中分别提取人脸图像的256维和350维的特征向量进行对比。对于数据预处理部分,会将所有面部图像的大小调整为112。即使图像的大小发生了改变但基本分辨率改变不大,因此仍将这些调整大小后的图像视为低分辨率图像。通过观察QMUL_SurvFace数据集,发现来自同一身份的人脸图像的亮度经常变化很大。因此在数据预处理期间,会随机改变面部图像的亮度以作为数据增强。

表2 34层和50层ResNet网络结构
3.3 对比实验和结果分析
在所有实验中,会将QMUL-SurvFace数据集中的所有人脸图像调整为所需的大小112,然后对图像中每个像素减去127.5除以128,从而将像素值压缩至[-1,1]。在CentreFace算法中,设置参数λ1=0.005,λ2=0.2,α=0.5。为了对closed-sets数据集识别的性能进行评估,选择广泛使用的度量:累积匹配特征(cumulative matching characteristic,CMC)曲线。receiver operating characteristic(ROC)曲线同CMC一样,是模式识别系统,如人脸、指纹、虹膜等的重要评价指标,尤其是在生物特征识别系统中,一般同ROC曲线一起给出,能够综合评价出算法的好坏。CMC曲线综合反映了分类器的性能,它评价的指标与深度学习当中常用的top1 err和top5 err评价指标意思一样,不同的是横坐标的Rank表示正确率而不是错误率。其中Rank-1的比率是最常见的评价指标。Rank-r的CMC定义如下:
其中,Nmate(i)表示匹配在Rank-i处的probe图像数量,N表示probe中的类别数。在以下实验中,使用Rank-1作为评价指标[17]。
不同训练方法:在第一组对比实验中,网络模型采用34层ResNet,提取到的人脸特征向量维数为256。分别采用文中提出的改进后和改进前的训练方法[9]进行训练,可以获得两条损失函数曲线。损失函数曲线如图2,Rank-1识别率可见表3。比较两条曲线可以发现,图2(a)的loss函数曲线收敛于值1.45,图2(b)的loss函数曲线收敛于值1.3,说明改进后的训练方法有助于以更快的速度收敛且收敛后的中心损失更小。
不同网络和特征维度的影响:在第二组对比实验中,分别采用34层ResNet和50层ResNet的网络模型,且提取了不同维度的特征向量。实验结果见表4,从中可以发现,当网络模型为50层ResNet,特征向量维数为350时可以获得最佳结果。
预处理加入数据增强:在第三组对比实验中,在数据预处理期间随机更改人脸图像的亮度。仍然使用34层ResNet和50层ResNet,提取到的特征向量维度是350。实验结果见表5,可以发现,数据预处理阶段采用数据增强可以极大地提高人脸的识别性能。
模损失函数联合监督:在第四组对比实验中,根据上述对比实验中的最佳结果进行了进一步的实验。将模损失函数添加到总的损失函数中,将三个损失函数结合起来进行联合训练。首先,计算每个类别中的点到该类别的中心点的距离,以及从所有类别的中心点到原点O的距离。距离分布如图3所示。发现在加上模损失函数后,各类中心点到原点O的距离大约增加了一倍,但是每个类中的点到中心点的距离分布和未添加之前相当接近。从图中可以看出,模损失可以在保持类内距离的同时增加类间距离。从表6中可以看出,提出的模损失函数给Rank-1的识别率带来了进一步的提高。

表3 不同训练方法下的Rank-1识别率 %

表4 不同网络结构和特征维度下的Rank-1识别率 %
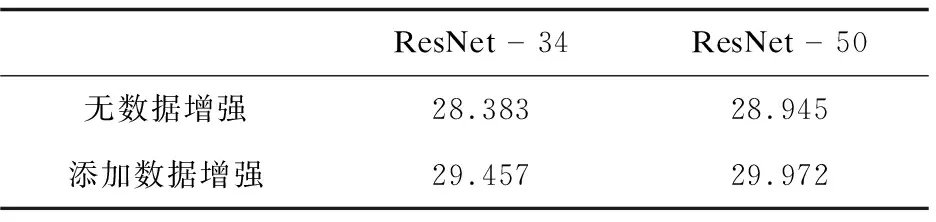
表5 数据增强对Rank-1识别率的影响 %

表6 添加模损失函数对Rank-1识别率的影响 %
在以上四组实验中,仅使用QMUL_SurvFace数据集来训练模型,最佳的Rank-1识别率为30.403%。与文中使用CASIA和QMUL_SurvFace图像训练模型的最佳Rank-1识别率相比,实验结果中的最佳Rank-1识别率更高。这意味着改进后的CentreFace比原始的CentreFace效果更好。此外,还在QMUL_SurvFace数据集中测试了最新的ArcFace方法的性能。为了便于进行比较,实验中仍然使用50层的ResNet,提取的特征向量维度为350。将ArcFace中尺度因子s设置为64,参数m设置为0.5。在实验中也仅使用QMUL-SurvFace数据集来训练所构建的模型, 但得到的Rank-

表7 不同FR方法的Rank-1识别率

(a)训练方法改进前中心损失函数曲线

(b)训练方法改进后中心损失函数曲线

(a)两种情况下各类中心点到原点O的距离的分布图
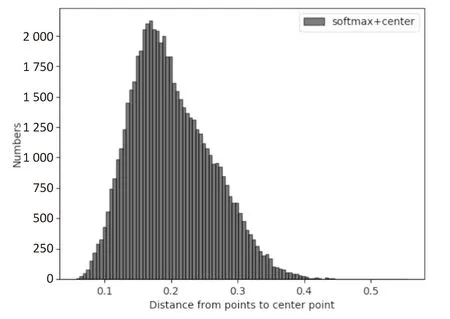
(b)未添加模损失情况下各类中的点到中心点的距离的分布图

(c)添加模损失后各类中的点到中心点的距离的分布图
1识别率仅为24.987%。在表7中,对原始CentreFace,改进后的CentreFace,SphereFace和ArcFace的实验结果进行了比较。
4 结束语
提出了一种模损失函数并将该损失与Softmax损失和中心损失相加,三种损失函数联合监督进行训练。相比于仅使用Softmax损失和中心损失,加入的模损失函数可以在保持特征类内距离不变的情况下,增大类间距离,从而增强网络模型对特征的判别能力。此外,还对CentreFace的训练方法做了一些改进,通过调整训练步骤来更好地进行参数更新优化,最终中心损失函数值可以收敛得更好。在基准人脸数据集上的实验结果表明,改进的CentreFace在低分辨率人脸识别任务上的识别精度要优于之前的CentreFace以及其他先进的人脸识别方法。
猜你喜欢
中学生理科应试(2021年11期)2021-12-09
奥秘(2021年5期)2021-06-15
数学学习与研究(2018年15期)2018-11-12
小雪花·初中高分作文(2017年9期)2018-05-21
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
电脑知识与技术(2016年22期)2016-10-31
米娜·女性大世界(2016年8期)2016-08-17
