
基于BERT-LSTM的答案选择模型
2021-06-02 09:37朱剑,饶泓,李姗
南昌大学学报(理科版) 2021年1期
朱 剑,饶 泓,李 姗
(南昌大学信息工程学院,江西 南昌 330031)
智能问答系统是信息检索的一种高级表达方式,通过理解用户提出的问题,提供精确的信息服务。目前,智能问答系统在语音交互、在线客服、知识获取、聊天机器人等诸多领域被广泛应用。答案选择是智能问答系统的基础,是自然语言处理领域的重要研究方向。
答案选择的核心是根据问题和候选答案之间的匹配关系对候选答案进行排序,选择最适合问题的答案。因此,答案选择任务是一个典型的句子匹配任务,即寻找两个句子之间的匹配关系。但由于自然语言的复杂性,答案的智能选择面临如下挑战:
(1) 问题和答案在语义上存在联系,但是这种联系不是简单的语义相似性,不能仅以相似性作为是否准确的衡量指标。
(2)不同类型的问题所需要的答案形式不同,如“为什么”、“怎么样”、“什么时候”、“什么人”等,问题形式具有多样性。
(3)问题和答案存在长度差异,答案句子一般较长,包含有噪音和与问题无关的信息,从而干扰了对正确答案的判断。
(4)答案与问题可能不共享相同的词汇集。
本文结合BERT预训练模型和BiLSTM,引入注意力机制构建新的答案选择模型,以解决上述问题。
1 研究现状
1.1 传统方法
答案选择任务是给定问题q和对应的候选答案集合(a1,a2,…,as),从候选答案集合中找到能够回答问题q的正确答案ak,1≤k≤s,其中s表示候选答案集合的大小。
传统的答案选择方法主要依赖特征工程构建文本特征,使用语法树、依赖树等语言学工具提取句子特征,或者借助某些外部资源来解决问题,如Yih[1]等人基于wordNet构建语义特征;Joty[2]等人使用NLP工具包提取单词层的匹配特征,如关键词匹配特征、命名实体匹配特征以及一些类似单词长度等非语义类特征,再使用SVM模型进行分类;还有一些工作试图使用依赖解析树之间的最小编辑序列来实现匹配[3]。这些方法主要从词语和句子结构的角度对文本之间的相似关系进行建模,没有充分考虑两个句子之间的语义联系;其次,人工制定的特征提取策略具有主观性,依赖于个人直觉和经验,不够全面客观理解问题;另外,引入语言学工具的模型比其他模型复杂度高,计算成本增大,计算效率低。
1.2 深度学习方法
深度学习技术在计算机视觉、图像处理、自然语言处理等领域都取得了优异的效果,已被证明能够有效地捕获大数据中的复杂模式。因此,近年来,人们研究使用深度学习方法进行答案选择,利用深度学习技术自动学习有意义的特征表示,将特征学习融入到模型建立的过程中,节省大量人力物力,也减少了人为设计特征造成的不完备性问题[4,12]。
1.2.1 基于表示的答案选择
目前答案选择模型的大致流程是:(a)使用word2vec或glove将句子中的词语映射为向量表示;(b)利用CNN或RNN对文本序列进行建模,提取序列特征以构建句子的表示向量;(c)计算得到句子的表示向量后,对表示向量进行相似度计算。
根据模型对于句子特征提取结构的不同,基于深度学习的答案选择模型可以归纳为基于表示的答案选择方法和基于交互的答案选择方法两类。
基于表示的答案选择算法(如图1),通过相同的CNN或者RNN结构把两个句子投影在同一个词嵌入空间中,将两个句子编码为向量表示,再根据两个句子向量做出匹配决定。Feng等人[5]提出CNN-QA方法,采用相同结构且参数共享的CNN来编码问题和答案,学习问题句子和答案句子的整体表示。Tan等人[6]提出QA-LSTM方法,利用BiLSTM分别编码问题和答案句子,并通过max/mean pooling得到句子整体表示;QA-LSTM/CNN方法,在BiLSTM层上添加一个CNN层来捕获句子特征,从而给出问题和答案的更多复合表示;Wang[7]采用堆叠的BiLSTM来学习句子表示;陈[8]从不同角度构造多个文本匹配特征,作为排序模型的特征输入,并对比了不同的匹配特征组合对应的排序效果,且对每个排序特征的作用做了分析。该类框架的优点是共享参数使模型更小、更容易训练。但在编码过程中,忽略了两个句子之间内在的语义联系,容易受句子中噪声的干扰,丢失一些重要信息。
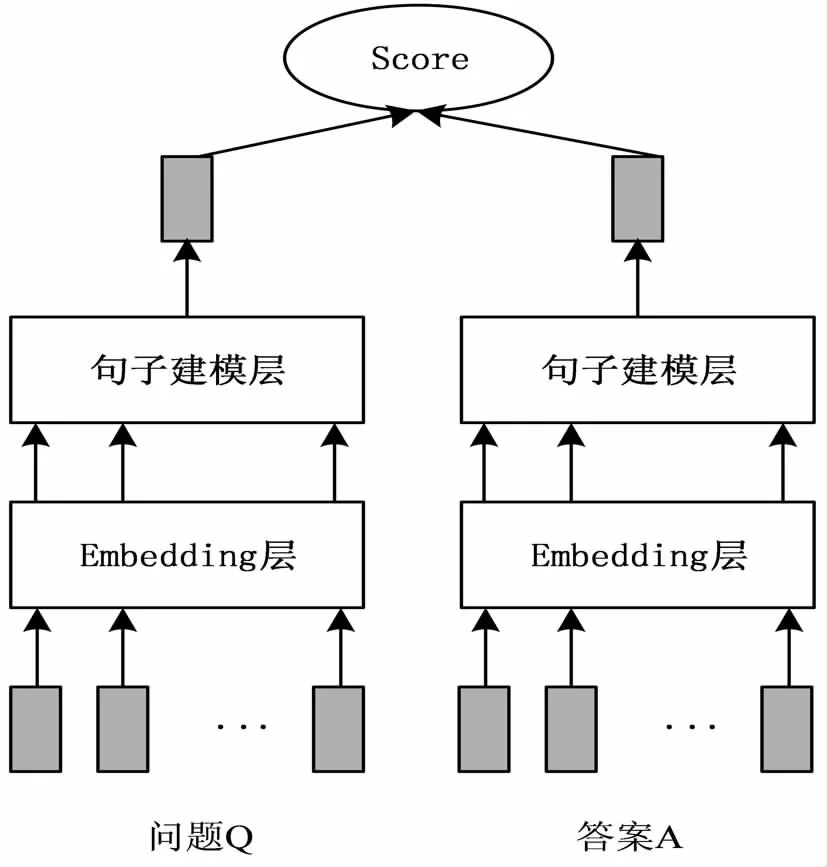
图1 基于表示的答案选择模型
1.2.2 基于交互的答案选择
基于交互的答案选择模型(如图2所示)通过注意力机制实现问题和答案之间的信息交互,模型考虑两个句子之间的相互影响,更关注有用信息、减少无用信息的干扰,从而提高模型性能。在Feng等人[5]以及Tan等人[6]的论文中,答案中单词的注意权重依赖于问题的隐藏表示;Tan采用BiLSTM结构提取问题和答案的语义特征,根据问题表示学习答案的注意力权重,从而提升了答案选择的准确率。Santos等人[9]提出了一种双向注意机制,根据逐字交互矩阵,表示问题和答案的相互影响;Zhang[10]提出AI-NN,利用CNN或RNN来学习问题和答案的表示,使用AI-NN捕获问题和答案之间各个匹配片段的内在联系。MVFNN[11]提出了基于多注意力视图的网络模型,不同类型的注意力关注不同的信息,再将所有信息融合构建更准确的文本表示。在这种框架中,模型层更深,结构更加复杂,RNN、CNN以及Attention机制以更加复杂的方式结合使用,问题和答案句子之间有更多的交互,从而更准确地提取语句特征。
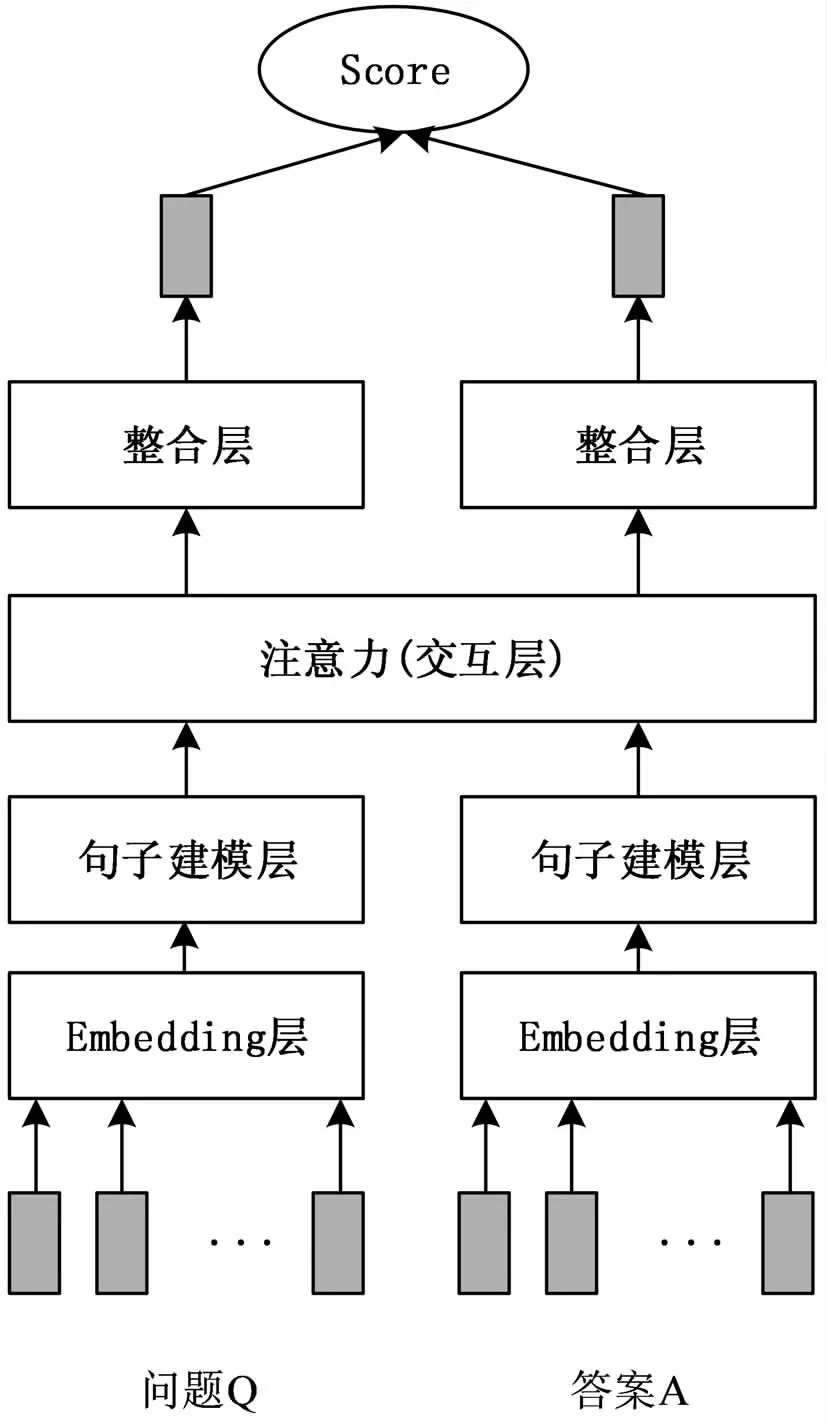
图2 基于交互的答案选择模型
以上的方法大多使用word2vec或glove词嵌入进行词向量表示,即将词语投影到一个低维的词向量空间,每个词被表示为一个低维向量,向量之间的空间关系反应了单词之间的语义特性。但在实际生活中,同一个词在不同的语境下可能具有不同的意思,即存在一词多义问题。如“Bank”有“银行”的意思,也有“河畔”的意思。词嵌入表示是静态固定的,无法真实反应不同语境下不同的词语意思,很难仅通过静态嵌入来解释词语的实际含义。
ELMO、GPT、BERT等预训练模型的出现,在很大程度上改变了目前众多自然语言处理任务中的模型架构范式,在NLP领域的诸多任务中取得了相比以往更具竞争性的效果。而BERT使用Transformer结构提取文本信息,比传统的CNN、RNN具有更好的特征提取能力。BERT不仅可以视为嵌入层,获取文本的上下文嵌入,也可以看作编码层,实现对文本的特征提取[13]。因此,论文基于BERT预训练模型,提出BERT-LSTM网络模型实现答案选择。模型首先利用BERT对当前语料进行微调,获取包含上下文信息的词嵌入,即初步的特征编码,再利用BiLSTM实现文本序列信息整合,最后引入注意力机制突出重点信息,以更好完成答案选择任务。
2 BERT-LSTM答案选择模型
2.1 BERT模型
BERT[14]使用的是一个双向Transformer语言模型,如图3所示。BERT不是像传统语言模型那样用出现过的词去预测下一个词,而是直接把整个句子的一部分词随机掩盖,双向编码预测这些掩盖的词。同时,在编码的选择上,没有用LSTM,而是使用了可以做得更深、具有更好并行性的Transformer,其中,Self-Attention可以学习序列中词与其他词之间的关系,充分挖掘每个词的上下文信息。BERT模型在预训练阶段学到了通用的语言知识,在当前任务上微调学习词语的上下文表示contextual-embedding,该嵌入一方面包含词语的自身表示,又包含其语境的上下文表示,比单独的word2vec/glove蕴含更加丰富、准确的信息。
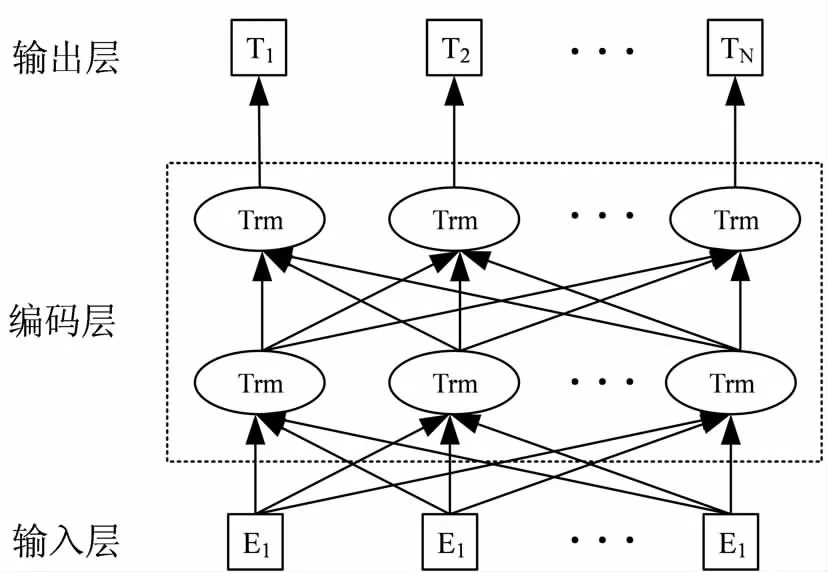
图3 BERT模型
为了能应对下游任务,BERT给出了句子级别的表示(如图4)。BERT输入可以是一个单独的句子、一段连续的文本或者一个句子对。如果BERT对应输入是一个句子,句子的头部需要添加标识符[CLS],尾部添加标识符[SEP],如果输入是两个句子,则需要使用分隔符号[SEP]隔开作以区分。句中每个单词有三个embedding:词语向量(Token Embeddings)、段向量(Segment Embeddings)和位置向量(Positional Embeddings),单词对应的三个embedding叠加,就形成了BERT的输入,如图4所示。其中,[CLS]是每个输入句子的第一个标记,最终对应的输出可理解为句子整体含义,用于下游的分类任务。标记[SEP]是用来分隔两个句子的。
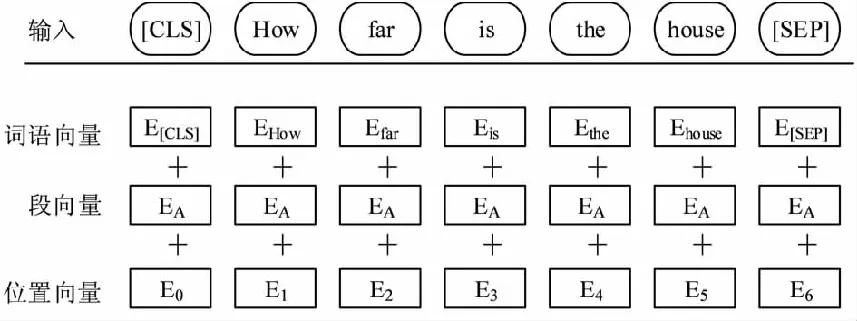
图4 BERT输入示例
Google提供了两种预训练好的BERT模型:BERT_base和BERT_large。两种模型的具体情况如表1所示。
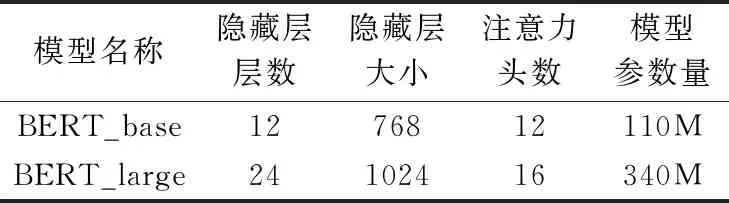
表1 BERT的两种模型
2.2 BiLSTM
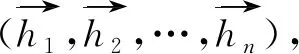
2.3 BERT-LSTM模型
BERT-LSTM模型主要由BERT层、BiLSTM层以及注意力计算组成,如图5所示。首先,将预训练好的BERT模型在本任务数据集进行微调,获取文本序列的词义表示;将得到的词语表示向量输入BiLSTM模型,进行进一步的文本语义信息整合;利用注意力机制实现问题和答案之间的信息交互,突出重点信息,减少无关信息的干扰;计算问题和答案句子表示向量,进行余弦相似度计算,返回相似度得分最高的候选答案。
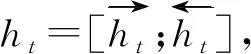
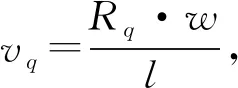
(1)
(2)
其中,Wa和Wq是网络参数,αi表示注意力权重。
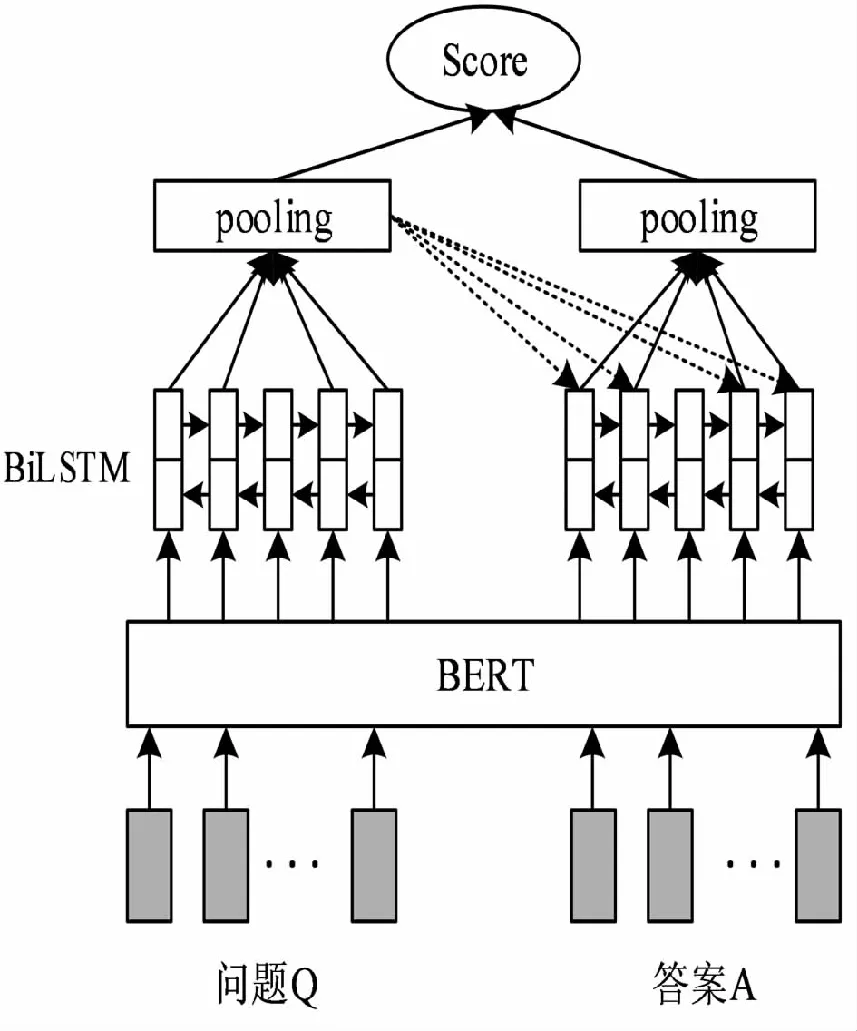
图5 BERT-LSTM模型结构
3 实验和分析
3.1 数据集介绍
WikiQA[15]和InsuranceQA[5]是两个常用的答案选择任务基准数据集。WikiQA是微软研究院2015年公开的英文答案选择数据集,收集和注释用于开放域问题回答的研究。WikiQA使用Bing查询日志作为问题源,反映一般用户的真实信息需求。由于原始数据集中有一部分问题没有对应的答案,对原始的数据进行了筛选,去除没有正确答案的数据。InsuranceQA数据集是保险领域首个开放的QA语料库。该语料库包含从网站Insurance Library收集的问题和答案,是一个现实世界的语料。数据集具体情况如表2所示。
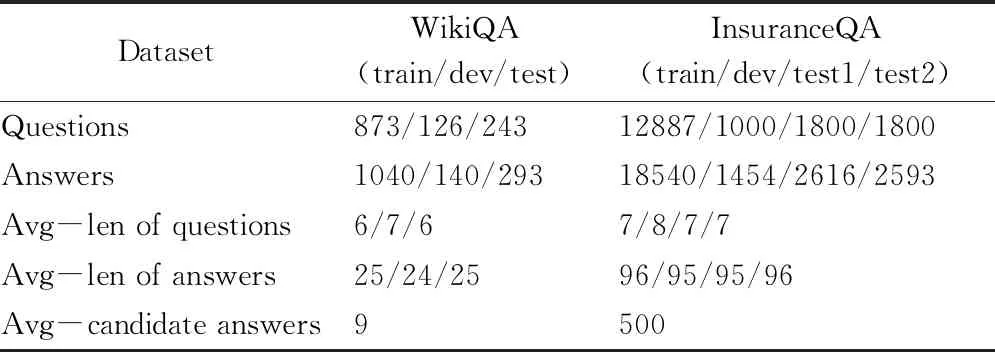
表2 WikiQA和InsuranceQA数据集情况
3.2 评价指标
不同数据集的数据来源不同、内容领域不同、数据特点不同,不同的评价指标从不同的角度反应模型的性能。目前的答案选择算法对于不同的数据集采取不同的评价指标,目前常用的评价指标主要有MAP、MRR以及Accuracy。
(3)
其中,mi是第i个问题的候选答案个数,pj是第i个问题的第j个正确答案的排序位置。
(4)
pi表示正确答案在排序中的位置,|Q|表示数据集大小。
准确率也是常用来的评价指答案选择模型的性能。|Q|表示数据集大小,precision@1表示排序第一个候选答案的准确率。
(5)
3.3 实验参数设置
深度神经网络模型训练中主要有模型参数和超参数,参数的选取和模型效果息息相关。实验中的模型,先初始化参数,在训练数据集上进行训练,利用验证集来选择最佳参数,将最优的模型在测试集上进行测试。本文实验中BERT采用Google发布的预训练好的英文模型“BERT-base,Uncased”,Transformer层数为12,隐藏层大小为768,注意力head数目为12,模型总参数量110M。使用Adam进行模型优化,学习率设置为2e-5,训练的batch_size设置为64,BiLSTM的隐藏单元为256,为了避免模型过拟合设置dropout为0.2。对比实验中的词向量来源于glove官网下载的glove.840B.300d,词向量维度为300。
问题和答案句子的表示向量,采用余弦相似度进行计算:
(6)
采用Hingle损失函数计算损失进行计算,损失Loss计算方式如下:
Loss=max{0,m-cos(vq,va+)+cos(vq,va-)}
(7)
训练的目的就是要在训练过程中不断更新参数,使得模型的总损失尽可能的小。vq,va+和va-分别是问题以及正确答案和错误答案的表示向量,损失函数的目的就是要问题和正确答案的相似度尽可能大于问题和错误答案的相似度,而且二者的尽可能有明显的间隔,m是超参数,实质就是表示这个间隔,即cos(vq,va+)-cos(vq,va-)>m。实验中m取值为0.1。
3.4 实验结果与分析
将本文模型与常见的多个答案选择算法分别在InsuranceQA和WikiQA数据集的结果进行对比,比较模型之间的性能差异。
模型在InsuranceQA数据集的实验结果如表3所示。word2vec-Pooling直接对词嵌入求平均作为句子表示,该方法忽略了词序和词语之间的联系,结果最差;BERT-pooling将BERT的输出取平均作为句子表示,取得了不错的结果;BERT-LSTM比word2vec-LSTM等其他一系列方法取得了更好的结果。一方面,BERT模型在预训练阶段学到了通用的语言知识,在当前任务上微调学习词语的上下文表示,该嵌入既包含词语的自身表示,又包含语境的上下文表示,比单独的word2vec/glove蕴含更丰富、准确的表示信息。另一方面,BERT实际不仅起到了嵌入层的作用,还起到了编码层的作用。BERT以Transformer作为编码器,学习序列中词与词之间的关系,充分挖掘了每个词的上下文信息。
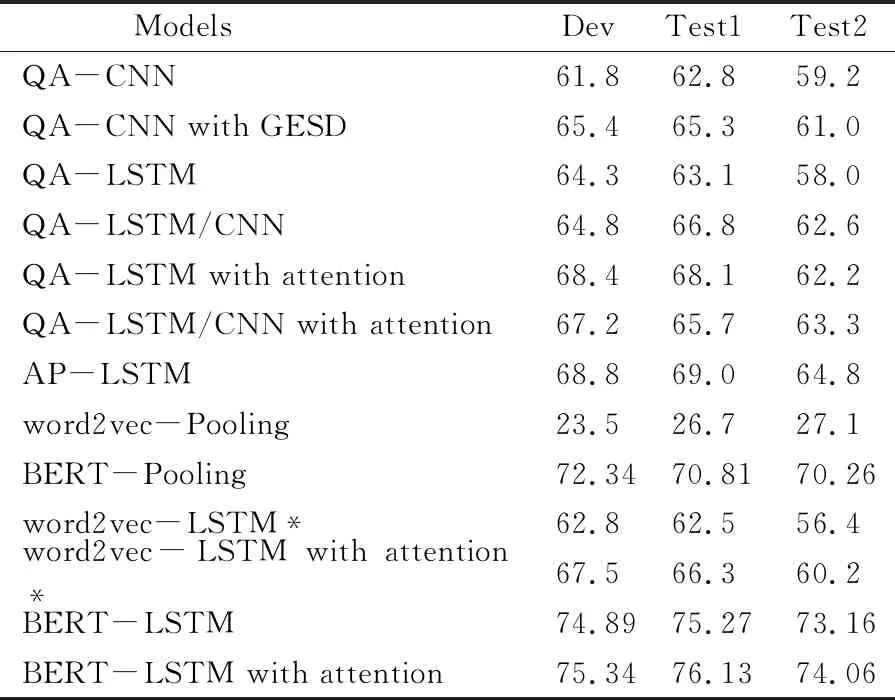
表3 在InsuranceQA数据集上的准确率
在WikiQA数据集上的实验结果如表4,可以看出,BERT-LSTM模型提升了MAP和MRR两个指标上的性能,取得了更好的效果。
论文所提出方法在两个标准数据集上均取得了较好的结果,验证了模型的有效性。同时,引入注意力机制的模型相比未使用注意力机制的模型具有更好得结果。说明了注意力机制在句子建模的过程中可以增加对关键信息的关注,抑制无关信息的干扰,提升模型对句子语义的表示。
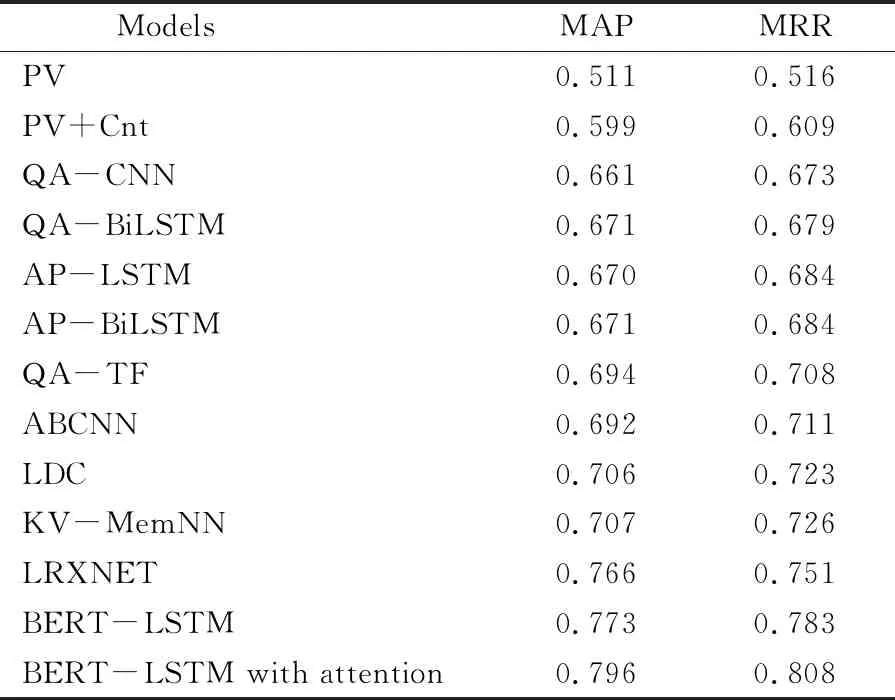
表4 在WikiQA数据集上的结果
4 总结
论文针对智能问答选择领域常见的文本语义表示模型中词向量存在的一词多义以及无法包含上下文语义信息的问题,提出了BERT-LSTM问答选择模型,该模型在两个答案选择基准数据集上的测试均取得了理想的结果,在答案选择基准数据集InsuranceQA上准确率达到75%至76%,WikiQA数据集上MAP提升了3.92%,MRR提升了3.19%。验证了基于BERT的上下文嵌入比word2vec/glove具有更好的表示能力,并证实了所提出模型的有效性。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小天使·一年级语数英综合(2020年4期)2020-12-16
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
传奇故事(破茧成蝶)(2015年7期)2015-02-28
