
一种基于邻近性和团的异常数据检测算法∗
2021-06-02 07:30蔡江辉杨海峰荀亚玲
计算机与数字工程 2021年5期
解 峰 蔡江辉 杨海峰 荀亚玲
(太原科技大学计算机科学与技术学院 太原 030024)
1 引言
异常数据检测是数据挖掘的一个热门研究方向,其目标是寻找与多数对象明显不同的样本点。在数据的分布图中,这些样本点与其他数据点距离较远,所以也被称为离群点[1](outlier)。异常数据的检测方法按照类型分为基于模型的方法[2]、基于聚类[3]的方法、基于邻近[4]的方法。基于模型的方法需要建立一个异常点不能完美拟合的数据模型,通过考虑对象异常的可能概率,运用概率分布模型[5],计算样本分布的均值标准差,如果对象不能很好地同该模型拟合,则认为该对象为异常点。基于模型的异常检测方法对数据作统计学假定,只有当假定满足实际约束时,才能检测到异常数据。简单模型(如高斯模型)对参数进行拟合仅需要线性时间,但当模型复杂(如混合模型[6])时,需要多次迭代来拟合最佳参数。基于聚类的异常检测方法,假定正常数据属于相对密集的簇,而异常数据属于稀疏的簇或不属于任何簇,在这种假定下,通过考察对象与聚类算法产生的簇之间的关系来识别异常数据,当识别到不属于任何簇类的对象,或者属于偏远的且样本量较少的簇时,则大概率为异常点或异常簇。基于聚类的方法是一种无监督的检测方法,它不依赖于数据的标签,直接将对象与簇进行比较来检测异常点,但是对于大型数据集,聚类方法开销较大,不适用于异常检测。基于邻近性的方法,在对象之间定义邻近性度量,找到远离大部分对象的异常点。
研究人员在多数情况下使用基于邻近的方法来检测异常数据,如知名的K近邻[7],寻找异常得分[8]最高的样本点作为异常数据。通常异常点对K的取值高度敏感,当K较小,邻近的异常对象得到较低的分数;当K较大,则多数对象都标记为异常点。基于邻近性的方法对使用的邻近性度量依赖程度较高,并且面对分布相对密集的样本点时,不易检测异常点。
本文对基于邻近的方法进行研究,针对不易检测分布密集样本的异常点问题,将图论中团[9]的概念引入到异常检测中,对密集样本中存在的团进行分析,提出一种基于邻近性和团的异常检测算法——PCOD算法。该算法将数据转化成图,对图中的团进行分析,其中不属于团的样本点即为异常点。同时,针对样本量不断增加,搜索团的难度较大的问题,本文使用良分割技术将图分割,生成稀疏图[10],降低搜索团的时间。
2 相关理论基础
基于邻近性的异常检测使用距离度量来量化对象之间的相似性[11],并且假设异常对象与它的最近邻的邻近性显著偏离数据集中其他对象与它们近邻之间的邻近性,代表性的算法有基于距离的异常检测算法和基于密度[12]的异常检测算法。基于距离的算法一般使用欧式距离作为数据样本间的度量方式,计算多维空间中两个样本间的欧式距离d(x,y)如式(1)所示:
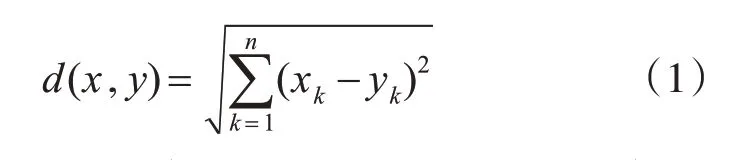
n为样本维度。当有了距离度量,需要判断给定半径的邻域[13],如果邻域内无其他对象,则可能为异常点。因此需要指定一个距离参数r来定义对象的合理邻域,对于每个对象o,分别判断它们邻域内其他对象的个数,如果数据中大部分对象远离对象o,则o为异常点,如式(2)所示:

其中r为距离阈值,π是分数阈值[14],dist为对象之间的距离,o′为其他对象。基于距离的算法通过计算o与其他对象之间的距离,统计邻域中其他对象的个数来分析o是否为异常数据。判断每个样本点的邻域需要使用嵌套循环检测异常点,嵌套循环的时间复杂度为O(n2),但在实际运用中常常是线性时间。
基于邻近的方法通常使用距离或密度作为度量方式,在低维数据中有很好的效果,但在高维空间中,不容易得到合适的度量方式,并且基于邻近的方法在处理高维数据时无法解决维度灾难和数据高度稀疏等问题。针对这些问题,学者探究了使用新的邻近度量或从高维数据中的子空间来检测异常点,文献[15]介绍了一种基于结构得分的高维数据异常检测算法。此外,还有基于传统异常检测方法扩充而来的HilOut算法,HilOut使用距离的秩作为邻近性度量,对每个样本o,得到它的K最近邻,记作nn1(o),…,nnk(o),对象o的权重定义为式(3):
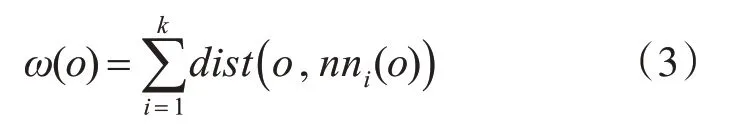
算法依赖于K值的选择。尤其是在面对大数据时,获得每个样本的K近邻对算法的消耗巨大。
3 基于PCOD的异常检测算法
PCOD算法是一种结合了邻近性与团的思想的异常检测算法,算法将对异常点的搜索转化为对数据图中抱团对象的搜索,算法首先将数据对象转化为图中的顶点,然后根据对象之间的邻近性判断顶点是否连接,最后搜索图来检测异常对象。
3.1 极大团与最大团
最 大 团 问 题[16](Maximum Clique Problem,MCP)是图论中一个经典的组合优化问题,在国际上已有广泛的研究。寻找最大团的经典算法为Bron-Kerbosch算法,其是一种递归回溯算法,用于搜索给定图的最大团。团(clique)是一个无向图的完全子图,完全子图的每对顶点之间都互相连接,寻找数据中的团就是寻找无向图中的完全子图。如果一个团不被其他任一团所包含,即它不是其他任一团的真子集,则称该团为图的极大团[17],结点数最多的极大团则为最大团。
良分割分离技术是Callahan等提出的一种对图进行成对分解获取稀疏图的方法,良分割对(Well-Separated pair)的定义如下:
定义1以c为中心,r为半径的球体,可以表示为集合B={p∈Rd:dist2c,p)≤r}。给定一个分割阈值s>0,如果数据集合A和B所在的最小矩形框R(A)和R(B)能够被半径为r的d维球体Sa和Sb分别包含,并且两个球体之间的距离不小于sr,那么称集合A和B是良分离的,如图1所示。
由定义1可知,若A与B是良分离的,则A与B中任意两点之间距离都是相近的,且都小于A与B之间的距离。通过这种方式将图成对分解,即可搜索图中孤立的异常点。
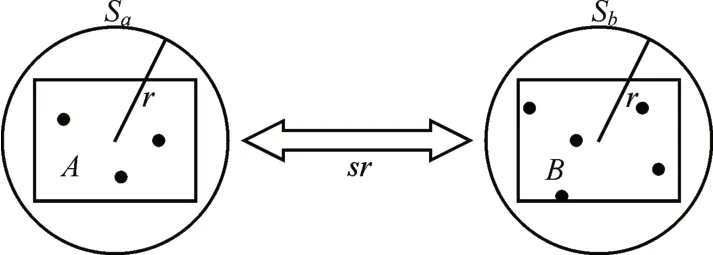
图1 WSP示意图
定义2给定无向图G=(V,E),若∃V′⊆V,使得顶点子集V′导出的子图G′=(V′,E′)为完全图,则称V′为G的团。若﹁∃V′⊆V∧V′⊂V″使得顶点集V″导出的子图为完全图,则称V′为图G的极大团,如果V′的顶点最多,则称V′为图G的最大团。
定义3如果∀o∈V,∀V′⊆V,使得o∉V′,则称顶点o为给定图G的异常点。
图2为具体案例,表示一个包含10个数据对象的无向图,其边集E={(1,2),(2,4),(2,3),(3,5),(2,5),(6,7)},采用上述方法即可得到c1、c2、c3、c4这四个包含多个对象的团,以及o1、o2、o3这三个孤立的对象,其中c3为最大团,c1、c2、c4为极大团,根据定义7可知,o1、o2、o3为给定数据的异常点。

图2 极大团、最大团与异常点
3.2 PCOD算法
PCOD算法是一种基于邻近和团的异常检测算法,该算法使用欧式距离作为邻近度量,将数据对象表示为图,递归搜索稀疏图中存在的团来检测异常点。采用良分割分离技术对图进行稀疏化并生成稀疏图。生成稀疏图的步骤如下所示:
1)给定数据集D=[X1,X2,……,Xn]。
2)取数据集中的对象Xi,i=1,计算X1与其他对象之间的距离d(i,j),则X1与其他对象的最大距离为maxd(i,j),最小距离为mind(i,j)。
3)s为分割阈值,σ为对象之间的邻近距离,σ=s×( maxd(i,j)-mind(i,j)),如果对象之间的距离小于邻近距离,即d(i,j)≤s×(maxd(i,j)-mind(i,j)),则两个对象之间存在着边的连接。
4)重复以上步骤,直到生成所有对象的边,将数据转化为图。
PCOD算法对分割后的稀疏图进行搜索,检测没有与其他对象抱团的异常点。本文在实验部分验证了邻近距离对异常点检测的影响。
Bron-Kerbosch算法是一种经典的团搜索算法,其效率较低且会遍历图中所有非极大团的样本点。为了提高本文算法效率,采用一种改进的搜索图算法。该算法加入了轴的概念,其思想是选择一个节点u作为轴,极大团要么包含u,要么包含u的非直接邻居,因此PCOD算法通过搜索u及u的非直接邻居来减少节点的搜索,降低算法的运行时间。PCOD算法首先将稀疏图转化为邻接数据表;再根据邻接数据表递归搜索团;最后对团进行分析检测异常点,如果存在没有与其他对象抱团的对象,则该对象被识别为异常点。PCOD算法具体步骤如下所示。


PCOD算法前期需要计算样本点之间的邻近距离生成距离矩阵,时间复杂度为O(n log2n),在第二阶段寻找数据中的团时,虽然使用了改进的搜索团算法,但它基础形式仍是一个递归回溯算法。算法过程中使用邻接数据表保存对象之间的近邻集合,其空间复杂度为O(mn),m为近邻列表的广度,n为近邻列表的深度,即样本个数。
4 实验结果及分析
在本文的实验环境为Windows10,处理器为In⁃tel Core i5-7200U,8.0GB运行内存,64位操作系统,开发工具为Spyder,开发语言为python。实验采用UCI数据集,其基本信息如表1所示。PCOD算法从三个方面评估异常检测的效果,一是邻近距离对算法运行时间和精确率的影响;二在UCI数据集上检测结果;三是与其他异常检测算法的精确率对比。
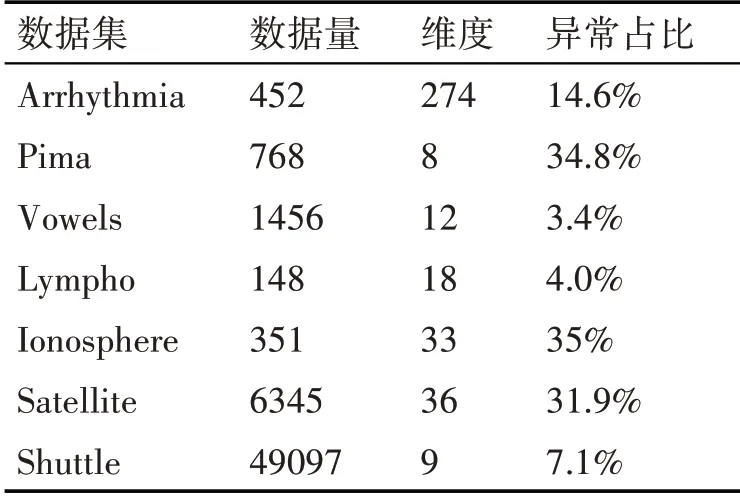
表1 UCI数据集
4.1 邻近距离对算法运行时间和精确率的影响
本文在500条数据、1000条数据、1500条数据三种数据规模下进行实验。精确率的计算方法为Precison=TP/(TP+FP),TP为真异常个数,FP为假异常个数,实验结果见图3。从图3可以明显看出对于测试数据集,当邻近距离σ较小时,运行时间趋势较为平稳。出现这种情况的原因是σ较小时搜索到的团的个数较少,因此算法运行时间较低。当σ=2.0时,精确率达到最高。当σ>2.0时精确率趋于平滑,随着σ继续增大,算法运行时间激增,精确率基本保持不变。随着σ的不断增大,团的数目逐渐增加,团搜索消耗的时间也随之增加。实验结果表明,当邻近距离值在相对小的范围时,算法检测到相对多的异常点,且消耗的时间较少,验证了算法在不同数据规模下的伸缩性。
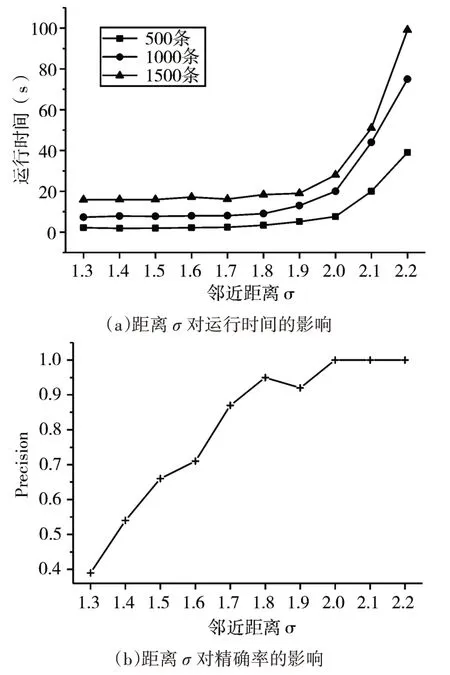
图3 邻近距离对算法检测结果的影响
4.2 PCOD在UCI数据集上的检测结果
检测率的定义为检测出的异常个数与异常总数之比。误检率也称为假警告率,其计算方法为假异常的个数与被分类为异常的对象个数之比,实验结果如表2所示。
表2结果可以看出PCOD算法在不同的数据集上都有较高的检测率。其中Ionosphere数据集上检测率达到92%,而误检率仅为9%,Ionosphere数据集的异常点占比达到35%。Vowel数据集的异常数据占比则相对较小,检测到多个异常点,证明算法不受异常点占比的影响。算法在小规模数据集与相对较大数据集上都有较高的检测率,整体结果表明PCOD算法在UCI数据集中有良好的适用性。

表2 PCOD在UCI数据集上的检测结果
4.3 PCOD与其他算法的对比
本文使用的对比算法有基于角度的异常检测算法ABOD、基于集成的FB算法、基于邻近性的KNN和基于密度的LOF算法,算法对比结果如图4所示。
总体来看,基于邻近和团的异常检测算法相比其他模型表现更好。PCOD算法与KNN算法都是基于邻近的异常检测方法,同样考虑距离来分析数据的异常性,但是PCOD算法分析了对象之间存在团的可能性,因为异常点不会被吸纳进正常样本的团内,所以在多数数据集上PCOD算法表现更优。Vowel数据集中异常点数占比相对较少且存在一部分与正常点较为邻近的异常点,导致LOF和KNN等算法无法轻易识别这些对象。由于Lympho数据集仅有六个异常点,除了ABOD算法,其余检测算法都检测到四个异常点,并且3个为真异常点,精确率为75%。在Shuttle数据集上,基于距离的算法精确率相对较低,因为数据集规模较大且异常点数多,不容易检测异常点,这也是基于距离的算法局限性。相比KNN、LOF等基于距离的算法,PCOD仍有比较好的检测效果。从图4分析可知,PCOD算法结果稳定,在多个数据集都有较好的精确率。实验结果证明简单模型效果不一定比复杂模型差,需要综合考虑算法在数据集上的稳定性。

图4 PCOD与其他算法在UCI上的精确率对比图
5 结语
本文对基于距离的异常检测算法进行研究,引入图论中团的概念,将数据对象转化为图,分析图中的团来检测异常点。通过对象之间的最大最小距离以及良分割技术对图进行稀疏化,提升了算法的检测效果。同时在UCI数据集上进行实验,对比了多种类型的异常检测算法,实验结果表明,在多数数据集上,本文提出的PCOD算法相比其他算法在精确率上表现更优。未来将进一步扩展算法在大型高维数据上的有效性与可伸缩性。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
领导决策信息(2018年16期)2018-09-27
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
数学学习与研究(2017年3期)2017-03-09
文苑(2015年9期)2015-09-10
计算技术与自动化(2014年1期)2014-12-12
新课程学习·中(2013年3期)2013-06-14
西南学林(2011年0期)2011-11-12
