
一种自标签特征点异源图像目标检测算法
2021-06-01 04:38:48张栩培贺占庄马钟杨一岱
北京理工大学学报 2021年5期
张栩培,贺占庄,马钟,杨一岱
(西安微电子技术研究所,陕西,西安 710068)
目标实例检测是指在预存图像上选择目标,在实时图像中检测出该目标及目标位置,因此该技术在景象匹配,视觉导航与定位等领域有着广泛的应用. 目前针对可见光图像的实例识别算法已有很多. 然而在无人机视觉导航等实际应用中,基于可见光图像的目标实例检测算法受光照影响较大,在夜晚、雾天等缺乏光照的场景下实时图像质量无法满足该类算法的使用条件,而红外图像则可以利用热成像原理克服光照不足的问题. 因此在可见光图像选取目标在红外图像进行实例目标识别的异源图像实例检测成为了应对这类应用场景的研究热点. 该技术是无人系统实现全天候视觉导航的关键,在军民领域均有着重要的应用潜力.
近些年来随着深度学习算法在计算机视觉领域的发展,通过神经网络提取图像的不同层级的特征具有比传统算法更好的目标识别效果,在异源图像实例目标识别领域也出现了像孪生神经网络[1]等方法,该算法证明了异源图像在高层级特征中存在着相似性,但现有的实验结果表明基于块匹配思想的该类方法在视角变换等场景变换情况下目标识别准确度以及目标定位精度上仍存在着比较大的实用差距. 而LIFT[2],Super-Point[3]基于深度学习的特征点匹配算法利用神经网络也能够提取出高层次的特征,在可见光的同源图像上也有了比传统特征点匹配算法更好的效果,且能够在视角变换及光照条件不足时提供比较高的目标识别准确度以及目标定位精度.
但想要实现异源图像实例目标检测仍存在以下问题:1)基于特征点匹配的算法其核心是几何配准,但由于外观变化红外与可见光图像存在着几何变化关系,怎样将这个变换关系得到从而进行异源图像上的特征点进行配准是异源图像目标检测的基础问题. 2)基于深度学习的特征点匹配算法需要巨大的标注工作量无法利用人工完成,如何设计一种高效并且能够获得异源图像共有特征来产生训练需要真值的标注方法是异源图像目标检测需要解决的核心问题. 3)特征点匹配任务需要特征点提取与描述符计算同步进行,因此如何设计一个能够同步训练特征点提取和描述符计算的深度学习网络也是异源图像目标检测的关键问题.
针对上述问题,本文设计了一种能够对异源图像特征进行自标签的深度学习特征点提取与匹配算法从而实现异源实例目标检测. 实验证明本文算法相较于传统的SIFT算法和基于深度学习的特征点匹配算法对异源图像的共有特征点有更好的提取匹配效果,对异源图像的实例目标检测成功率也有明显的提升. 本文算法主要贡献有:1)通过对图像预处理,得到红外图像和可见光图像间的几何变换关系. 构建了异源图像间高层级特征点映射的基础. 2)通过随机仿射变换的方法进行数据增殖,利用合成图像上训练的“粗”检测器对可见光与红外图像提取特征,使算法具有同步提取异源图像特征的能力,利用特征点重复性与几何映射关系作为跨域特征的筛选方法,将异源图像上具有映射关系并重复出现的特征点作为“伪”标签值从而实现自标签效果,为后续的特征点提取与匹配网络的迭代训练提供真值. 3)结合现有深度学习算法框架的特点设计了一个能够实现特征点提取和描述符计算同步训练的网络架构.
1 相关工作
1.1 特征点匹配算法
基于特征点匹配的识别算法先通过在图像数据上分别提取特征点,并将特征点对应的描述子和特征点在图像上的位置存储下来. 只要找到足够数量的匹配特征就可以利用基础矩阵或单应性矩阵等几何配准算法实现目标识别[4]. 该类方法在SIFT[5]、SURF、ORB等特征匹配算法以及基于深度学习的特征提取算法提出后取得了非常明显的进步. 但是由于红外和可见光相机成像原理的差异,使得算法在异源图像上提取的特征存在差异,而传统的SIFT等算法并没有学习能力不能自适应这种异源图像特征差异. 基于深度学习的特征点提取算法Super-Point可以利用神经网络提取出高层级的图像特征,这些特征也被证明在异源图像上存在着相似性,进而展现出了比传统算法更高的潜力和更好的目标检测效果. 如图1所示,即使可以使用SIFT算法在红外图像和可见光图像上提取到不少特征,但这些特征并不能满足匹配关系,会导致出现大量误匹配或没有匹配点对. 而基于深度学习的Super-Point算法虽然能够通过神经网络提取出异源图像中高层级的相似特征,但这些特征没有建立明确的映射关系,因此匹配的精度较差,甚至会出现误匹配,通过上述方法实现异源图像实例目标检测任务非常困难[6-10].

图1 SIFT算法和Super-Point算法在RGB-IR图像的目标检测结果Fig.1 The instance detection results of SIFT/Super-Point on RGB-IR images
1.2 深度学习特征点提取算法标签值获取
与传统分类任务与分割任务不同,基于深度学习的特征点提取匹配算法在获取训练标签值时的难度非常大. 其主要原因是图像特征点主要是依靠灰度值变化来确定,对于人工标注来说不可行,并且图像特征点往往数量巨大也不利于人工标注. 目前基于深度学习的特征点提取算法主要依靠3类方式实现. 1)通过RGBD相机或SFM(structure from motion)对具有视角重叠的图像对进行三维重建,直接或估计出图像上各点在空间中的坐标,利用多视图几何计算出空间点在图像上的投影,从而设计损失函数进行网络训练. 这类方法标签值的获取成本高,标签值的精度依赖于设备和三维算法的精度. 2)依靠光流追踪算法实现标签值获取,其思想与三维重建方法类似,都需要借助其他算法来寻找图像对之间的对应关系. 3)与被动寻找图像对之间对应关系不同,本文所提出的自标签方法是通过主动生成随机几何变换矩阵将原图进行变换生成与原图像具有确定变换关系的新图像. 由于原图像与新图像之间的变换关系是已知的,那么在原图像上的每一个特征点通过这个已知的变换矩阵一定在新图像上会存在一个对应的点. 因此在训练时就可以将在原图上提取到的点视为“伪”标签值,并利用变换矩阵获得的新图像上的对应点来设计损失函数完成训练,从而实现不借助人工标注或其他工具的自标签效果.
2 基于异源图像特征点匹配的目标识 别算法
本文在采集可见光与红外图像后采用标注求解单应性矩阵的方法得到了图像间的几何变换关系,为高层级共有特征映射关系建立基础. 其次将自标签技术扩展至异源图像的应用中去. 通过利用深度学习算法设计一个粗检测器,并对输入的可见光与红外数据进行特征点提取. 利用随机单应性矩阵对可见光和红外图像进行数据增殖,再利用粗检测器对增殖的数据进行特征点检测并记录特征点的位置,由于可见光与红外,可见光之间以及红外图像间的单应性矩阵即仿射变换关系已知,便可将异源图像上的共有特征映射到原可见光图像上进行提取预筛,从而解决了异源图像共有特征点的提取问题,并将对异源图像的自标签结果作为特征点提取和描述符计算迭代训练的真值,从最终实现了异源图像实例目标. 本文算法的整体框架如图2所示. 针对网络输入的可见光,将对应的红外图像加入到数据增殖与自标签过程中获取可见光与红外共有的特征点作为后续训练检测器和描述子的伪标签.

图2 本文算法流程图Fig.2 The algorithm architecture
2.1 异源图像预处理与“粗”特征点检测器
本文用于训练的异源图像在采集过程中由于无人机飞行轨迹差异,以及可见光与红外相机内参的差异,因此本身图像就存在着一定的仿射变换. 虽然深度学习方法能够提取出高层级的特征,但由于这些仿射变换,相似的高层级特征在图像上的位置也会由于上述仿射变换而产生差异. 因此,通过多视几何求取单应性矩阵的方法[6]对采集图像进行同名点标注,计算出了所有可见光与红外训练图像间的单应性矩阵,如图3所示,从而获得可见光与红外成对影像间的仿射变换关系,为后续异源图像之间的特征点映射打下基础.
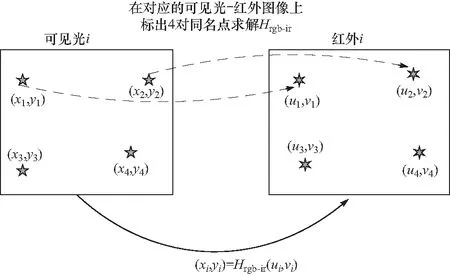
图3 利用同名点求解可见光红外图像间的变换关系Hrgb-irFig.3 Using homonymous points to solve the transformation matrix Hrgb-ir
作为自标签以及算法实现的基础,需要先利用神经网络设计一个特征提取器,并确保这个特征提取器对角点特征具有提取能力. 然而对于任意的图像很难确定特征点的位置,但是如果图像上只有线段、三角形、矩形、立方体等规则形状的简单图形. 那么根据特征点提取的原理,特征点位置一般都在端点和角点上,这些位置的坐标就很好确定了. 因此使用图形渲染工具生成大量规则图形作为特征点检测器训练的初始数据,通过记录上述规则图像的角点. 就可以利用这些确定位置的特征点作为标签值进行特征提取器进行训练. 通过将特征点检测表达成一个分类问题,利用卷积神经网络提取特征后,对于对图片的每个8×8图像块都计算一个概率,这个概率表示的就是其为特征点的可能性大小,前64维对应每个点是否为关键点的概率,最后一维对应是否存在特征点. 经过了在合成数据上的训练后,便可以得到一个具有特征点提取能力“粗”特征检测器. 为了进一步提高对异源图像共有特征的提取,就需要利用预处理的异源图像和自标签技术来迭代训练这个“粗”特征检测器,从而获得高质量的异源图像特征点.
2.2 可见光红外图像自标签
由于异源图像特征点匹配的根本是要将异源图像上公共的特征点提取出来,因此本算法的核心工作就是利用自标签方法建立异源图像之间特征的联系从而将公共特征点进行提取匹配,从而实现目标匹配. 可见光红外图像自标签流程如图4所示.
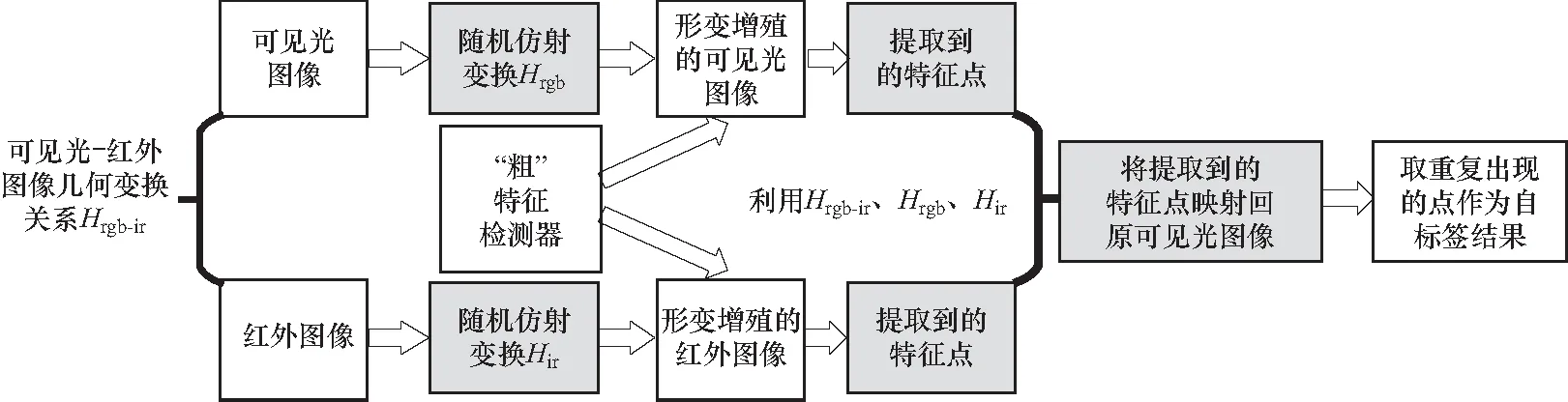
图4 可见光-红外影像自标签流程Fig.4 Self-labeling on RGB-IR images
在预处理阶段为了提取异源图像之间的公共特征首先需要建立可见光与红外图像之间的联系. 已经计算出了可见光与相应红外影像间的单应性矩阵Hrgb-ir,得到了图像对之间的仿射变换关系. 结束对数据集仿射变换关系的求解后,将可见光图像作为输入,利用在合成数据集上训练好的特征点检测器提取特征点,利用随机生成的单应性矩阵对原本的可见光数据进行仿射变换以达到数据增殖的效果. 同时由于在建立数据集时已经通过前期处理获得了可见光-红外数据间的放射变换关系,那么也可以用同样的方法对红外数据进行数据增殖. 将仿射变换过后的可见光和红外图像也通过特征点检测器提取特征点. 由于单应性矩阵本身就可以反映二维图像之间的几何变换关系,假设frgb()为特征点在输入可见光图像上的映射关系,fir()为特征点在对应的红外图像上的映射关系,RGB为输入的可见光图像,IR为对应的红外影像,Hrgb为可见光与可见光增殖数据间随机生成的单应性矩阵 ,Hir为红外与红外增殖数据间的单应性矩阵,x代表提取到的特征点. 由此可得
x=frgb(RGB)∪fir(IR)
(1)
根据计算机视觉原理,理想的情况下2D特征点在不同图像上的形变也是能够用单应性矩阵来表征的,因此可以通过前期获得的可见光-红外图像间的单应性矩阵Hrgb-ir以及数据增殖时获得的随机单应性矩阵Hrgb及Hir,将可见光增殖数据和红外及红外增殖数据上提取到的特征点映射到原可见光图像. 换句话说特征点检测应该满足如下关系:
Hrgbx=frgb(Hrgb(RGB))∪fir(Hrgb-ir(Hir(IR)))
(2)
将Hrgb左移至等式右侧则有

(3)
然而实际上,在标注Hrgb-ir以及本身“粗”检测器在可见光与红外影像上的提取结果无法完美的满足公式(3)的等式关系,因此将通过随机变换矩阵来生成新图像以此来实现数据增殖的目的,并将特征点提取结果进行经验求和,最终筛选出在原图像和生成图像上重复出现次数最多的特征点作为本文自标签结果. 即特征点检测器F(·)满足:
(frgb(Hrgb(RGB))∪fir(Hrgb-ir(Hir-i(IR)))
(4)
如图5所示,由此实现了异源图像间共同特征点自标签的工作,为后面训练最终的特征点检测器以及描述子提供了训练的“伪”真值.
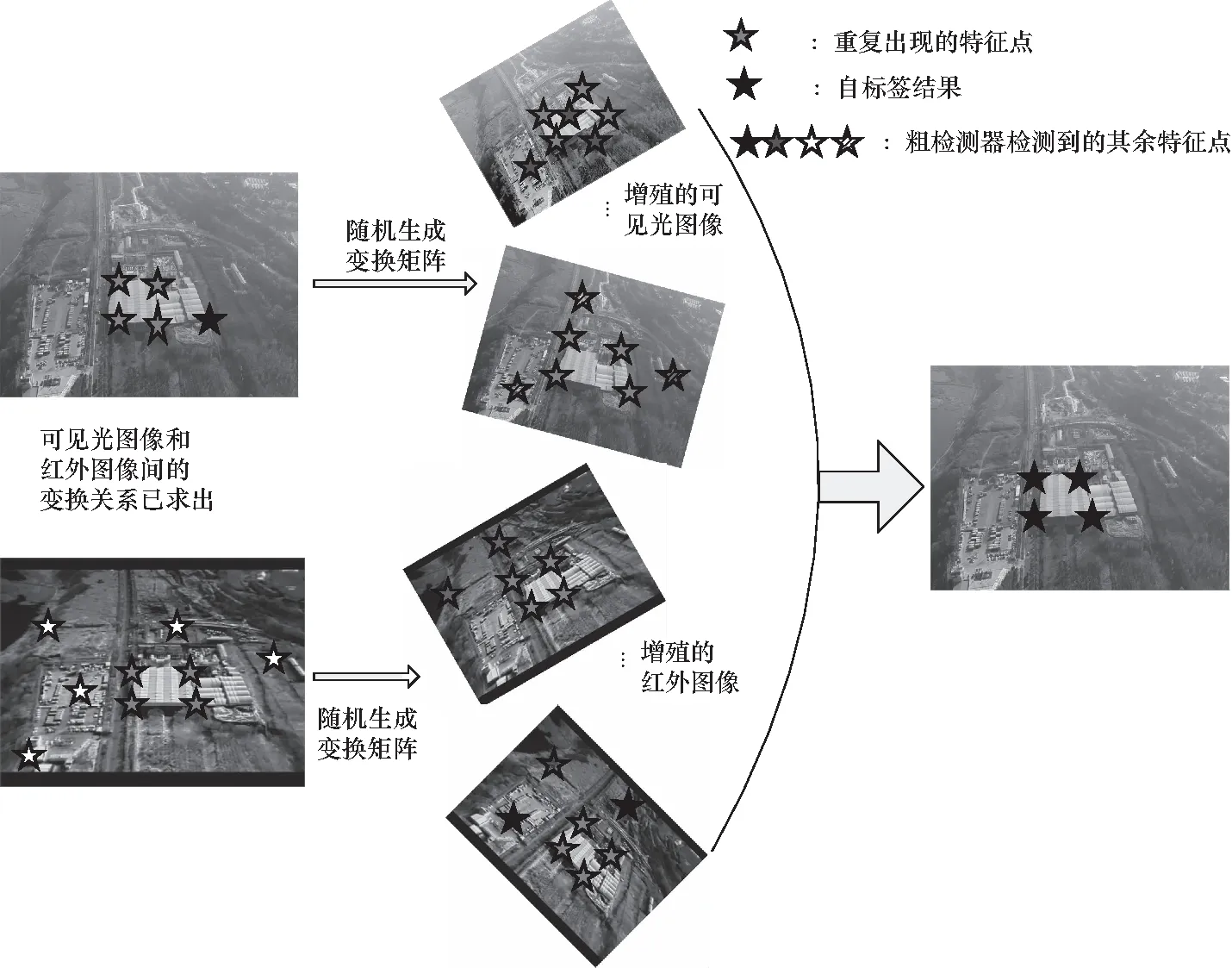
图5 自标签效果Fig.5 Self-label in results
2.3 特征点检测器与描述子同步训练网络
为了实现端到端的同步训练,结合现有算法的框架本文网络使用同一个编码器(采用VGG16作为骨干网络)对输入的图像进行了降维处理后提取特征,在编码器后网络利用两个解码器分别学习不同的任务权重,分别是特征点检测以及描述符计算. 网络架构如图6所示.
这里的特征点检测器与粗检测器使用的是一样的设计思想和网络架构,利用编码器对图像做8次降采样,最后会输出65通道的heatmap,每一个通道对应原图像上的8×8大小的图像块,后接softmax表示该点是特征点的概率,多出的一个值表示该图像块上是否存在特征点,这样就将特征提取问题转换成了一个分类问题. 而描述符计算则是先按照8×8的图像块来学习半稠密的描述子,然后利用双三次插值算法得到完整的描述子,最后利用L2归一化得到一个关键点对应的D维描述子.
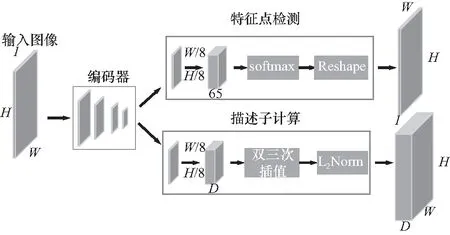
图6 训练网络框架Fig.6 Training-network architecture
本文的loss函数也分为了特征点和描述子两部分,整体的loss函数如下:
L(X,X′,D,D′;Y,Y′,S)=
Ldet(X,Y)+Ldet(X′,Y′)+λLdis(D,D′,S)
(5)
其中Ldet为特征点检测器的损失函数而Ldis为描述子损失函数. 本文对原始图像做仿射变换,这里我们依然是通过随机生成单应性矩阵来实现. 特征点检测的损失函数是分别用特征点检测器在原图和随机变换后的图像上提取特征点. 将原图特征点位置经过单应性矩阵变换得到的特征点位置作为伪真值Y和在随机变换的图像上提取的点的位置X计算差值得到Ldet(X,Y),Ldis(X′,Y′)则是相反的过程即先在变换的图像上提取点的位置Y′,然后利用单应性矩阵的逆得到原图像上的位置X′求差值得到. 描述符的损失函数计算则是先利用S判断特征点是否是对应关系,对应关系的判断还是利用随机单应性矩阵与图像块实现,即图像块位置利用单应性矩阵变换后是否能落到变换的图像上特征点位置的一个领域范围内. 如果特征点对是对应关系(在领域内)距离越近越好,如果特征点对不是对应的(领域外)则距离越远越好.
3 实验结果与分析
3.1 数据集
由于目前还没有公开的可见光-红外实例目标检测数据集可以用于算法的训练和测试. 本文算法的数据集是由利用无人机单独收集的涵盖了不同场景和目标的可见光-红外图像数据. 数据集包含内容如表1所示.

表1 本文算法数据集概况Tab. 1 Our dataset overview
测试集中主要包含了厂房、公园平房、板房、居民楼、交通道路等建筑物作为目标. 测试集图像示例如图7所示.

图7 测试数据集图像示例Fig.7 The images in test dataset
为了验证本文算法的泛化能力,本文还选取了同源图像进行实例目标检测试验,本文所选用的同源图像为可见光图像,采用的是公开数据集HPatches. 数据集中包含了共116个场景(每个场景5~6张图像),其中光照变化场景57个,视角变换场景59个,共计696张图像.

图8 HPatches数据集示例Fig.8 The images in HPatches
3.2 评价流程与评价方法
本文主要针对单张可见光目标图像匹配多张红外目标图像,即将可见光图片作为输入图像,分别与多张红外图像进行目标匹配. 主要的评价包含以下两个方面:
1)当红外图像中出现目标时,比较不同方法的准确率(参照单对图像情况)和成功率(红外目标与可见光目标匹配成功次数);
2)当红外图像中无目标时,比较不同方法误匹配出现的次数.
针对上述情况,设想评价系统的流程如图9所示.
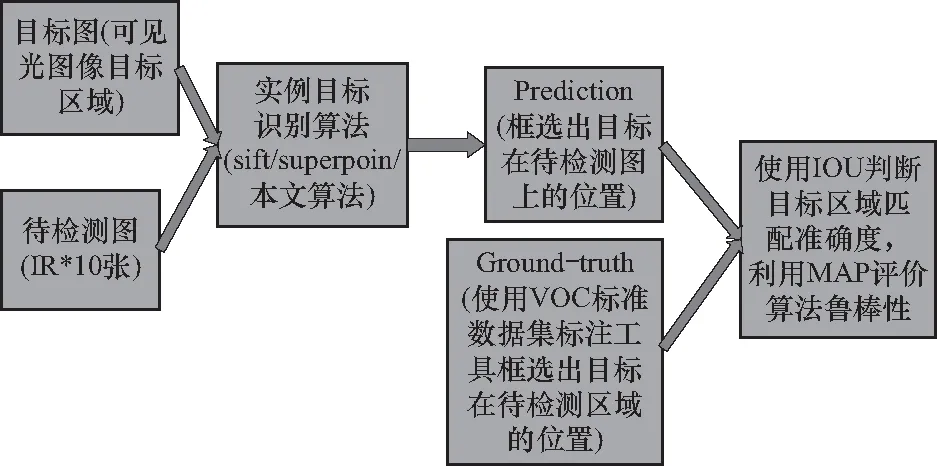
图9 实验评价流程图Fig.9 Experimental evaluation flow
综上所述,本文主要利用AP(平均精度)及mAP(所有类别的平均精度)对算法进行评价.
① AP:计算平均精度时需要结合交并比(intersection over union,IoU)和实际的实例目标应用场景.
IoU是目标检测中常见的评价标准,主要是衡量模型生成的bounding box和ground truth box之间的重叠程度,计算公式为
其中:detectionResult为检测结果;GroundTruth为真实值.
而本文测试主要针对两个场景,即红外图像上存在可见光目标以及红外图像上不存在目标. 假设红外图像中存在目标,并且IoU值大于预先设定的阈值(本文设为0.8),那就说明预测区域是对的,此时这个区域就是TP(true positive);假设红外图像中存在目标,但IoU值小于预先设定的阈值,那就说明这个预测是错的,此时这个预测就是FP(false positive). 同理还可以将红外图像中不存在目标但错误检测出目标的情况定义为FN(false negative),将红外图像中没有目标算法也未检测出目标定义为TN(true negative).

3.3 实验结果与分析
为了充分验证本文算法的先进性,选取了传统的特征点匹配方法SIFT算法,基于块匹配的KCF跟踪匹配算法,Superpoint算法,R2D2算法,D2-Net[17]算法以及HOG-HardNet[18-19]算法. 将测试数据分为5个待检测的可见光目标,每个目标分别对应10张红外图像. 同时为了模拟红外图像中不存在目标的情况,利用不同目标对应的红外图像进行了测试. 即正类样本和负类样本的红外测试图像均为20张,将IoU设为0.6,表2为实验结果.
由表2、表3所示本文算法在5个目标的两类检测任务中均比实验对比的其他先进算法具有更好的检测成功率以及鲁棒性. 但对于部分可见光和红外图像尺度差异较大的目标4及目标5算法也出现了误检测和漏检测的目标. 说明本文算法在尺度差异加大的情况下仍存在着不足. 为了直观地体现本文算法的检测效果,下面将展示几组算法的检测效果对比结果.
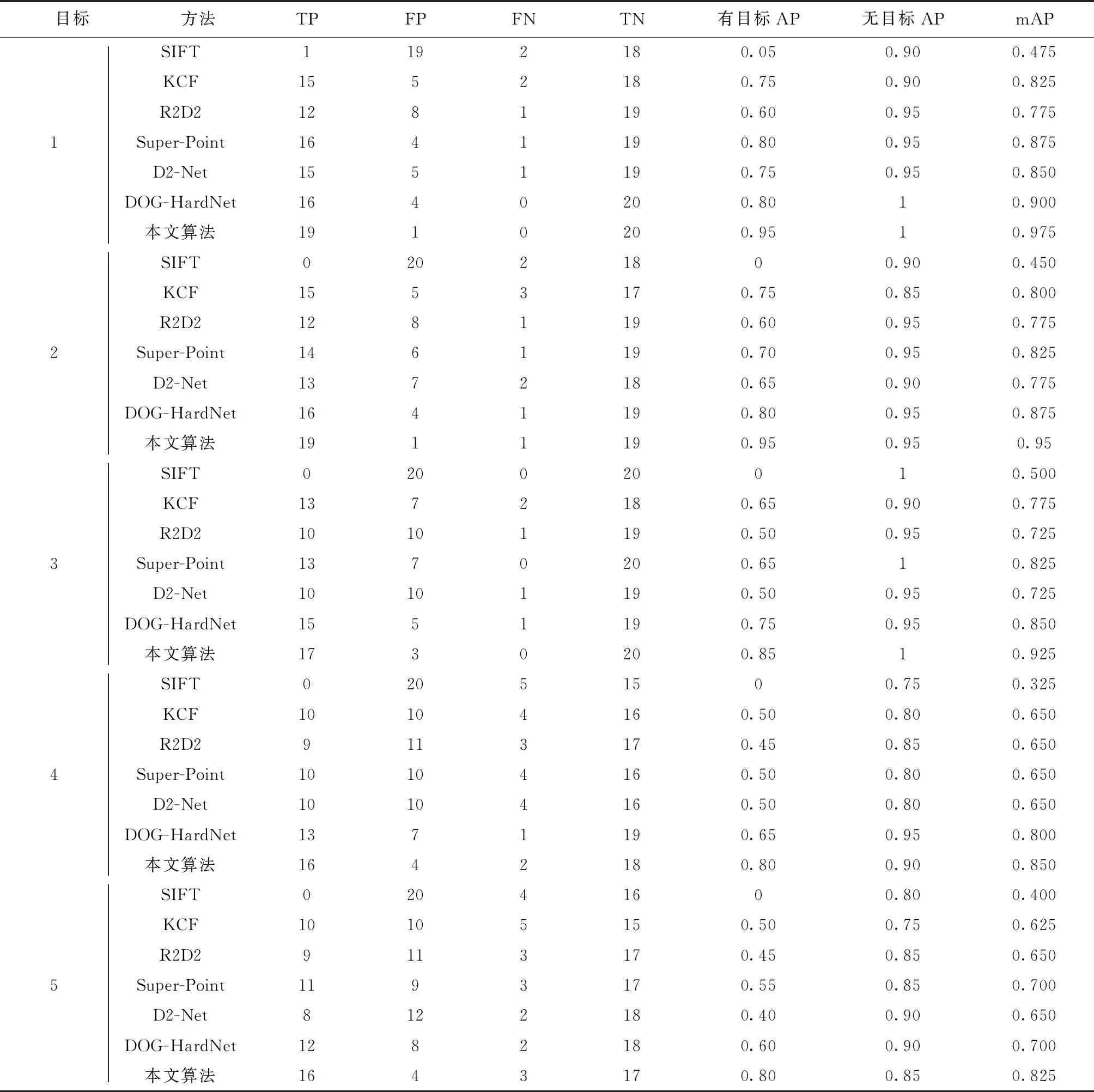
表2 5个待测目标评价结果
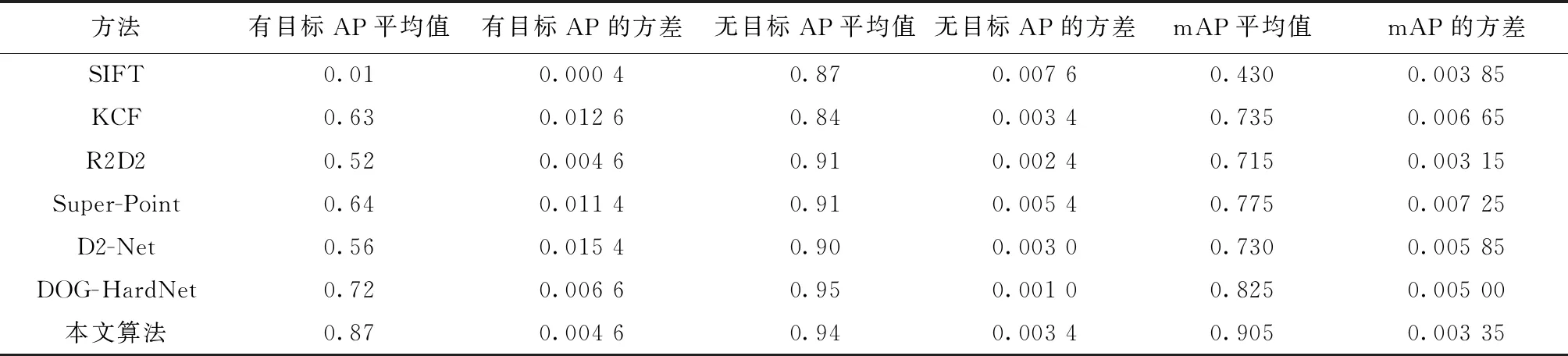
表3 算法在异源图像上目标实力识别的总体表现

图10 对可见光红外异源图像目标的检测效果Fig.10 The objection detection results on different source images
从上述匹配效果图可以看出,本文算法所提取的共有特征点充足且匹配准确率高,可以满足在异源图像上实例目标检测的任务,正确检测出目标并给出目标所在位置.
此外为了验证本文算法的泛化能力,还对本文算法以及上述特征点提取匹配算法在同源图像数据集HPatches上进行了实例目标检测的测试. 表4为实验结果.
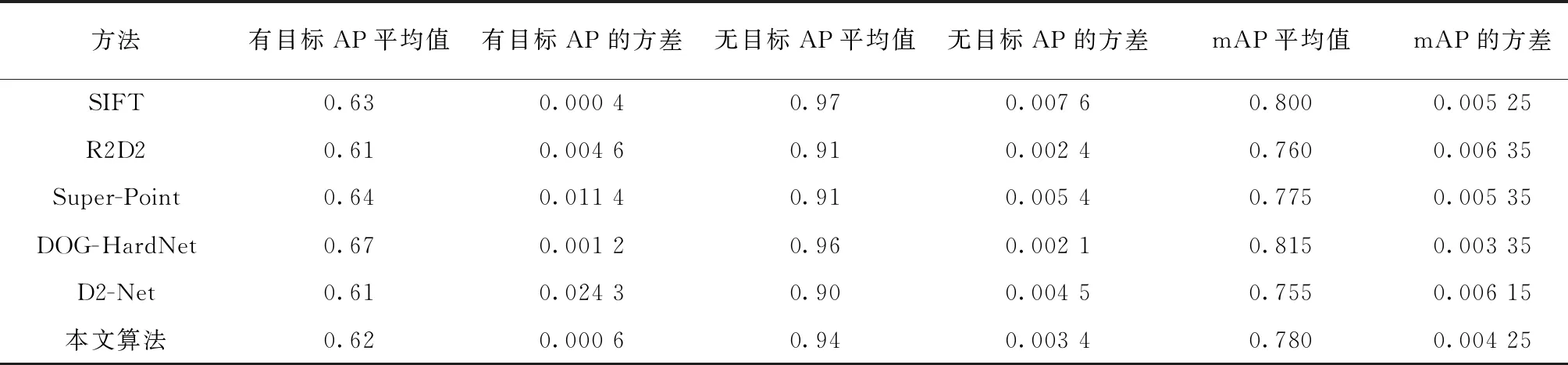
表4 算法在HPatches上的总体表现

图11 对光照变化下同源图像(HPatches)目标的检测效果Fig.11 The objection detection results in illumination change on same source images(HPatches)

图12 对视角变化下同源图像(HPatches)目标的检测效果Fig.12 The objection detection results in view-point change on same source images(HPatches)
通过上述的客观实验结果和主观的测试对比效果可以发现:①在红外图像上存在目标时,本文算法效果明显优于现有的实验对比算法. 本文算法成功的建立了跨域特征之间的联系,使得异源图像上的高层级特征有了明确的匹配关系. 因此在异源图像上的实力识别准确率和精度都较其他两种算法有了明显的提升. 在红外图像无目标时,由于是基于特征点匹配的实力识别,因此无法找到足够的目标区域匹配特征点的情况下3种算法均极少出现误匹配的情况. ②针对异源图像尺度差异较大的情况,本文算法虽然较实验对比算法有较好的检测效果但仍存在漏匹配和错误匹配的情况. 这主要是由于本算法并没有过多的考虑解决尺度一致性的问题,在自标签阶段的数据增殖没有考虑对尺度因子也进行缩放. 算法缺乏对该情况的学习,进而导致了漏匹配和错误匹配的情况. 这一问题在几类比较算法中也存在. ③本文算法主要针对的是异源图像上的实力目标检测任务,缺乏对同源图像的针对性研究,但实验显示本文算法在同源图像实例目标检测任务上仍然能够取得与先进算法接近的效果.
4 结 论
本文提出了一种基于深度学习特征点提取匹配的算法,该算法解决了以往研究无法获取异源图像共有特征的问题,从而实现了异源图像实例目标检测任务. 并通过实验证明了算法在异源图像上对5类不同目标的识别整体精度较现有的表现最好的DOG-HardNet算法提升了8%. 未来针对尺度差异引起的误匹配,漏匹配问题可以通过借鉴图像金字塔的思想构建新的自标签方法,使得算法充分学习多尺度图像特征点信息,从而解决图像尺度差异所带来的算法效果不佳的问题.
猜你喜欢
海洋通报(2022年4期)2022-10-10 07:40:26
农业工程学报(2022年5期)2022-06-22 12:15:58
环球时报(2022-05-23)2022-05-23 11:28:37
金桥(2021年4期)2021-05-21 08:19:20
中华戏曲(2020年2期)2020-02-12 05:17:58
电子制作(2019年7期)2019-04-25 13:17:14
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
光学精密工程(2016年3期)2016-11-07 09:03:43
公民与法治(2016年10期)2016-05-17 04:12:58
