
基于数据驱动的迭代式软件开发交付研究
2021-05-29 02:01:14马波
萍乡学院学报 2021年6期
马 波
基于数据驱动的迭代式软件开发交付研究
马 波
(阳泉师范高等专科学校 信息技术系,山西 阳泉 045000)
为了提高监控软件迭代的交付性能,文章提出了一种数据驱动的新方法,用以预测软件迭代的交付能力,为项目管理者提供自动化支持。该方法提取了历史项目迭代和迭代中问题的特征,并使用统计聚合、词袋和基于图的技术将迭代问题特征进行组合来表征迭代。使用多个真实的开源项目数据对该方法进行评估,结果表明,该方法在预测迭代进度方面具有较好的性能。
软件交付预测;迭代式开发;数据驱动
软件交付延迟和成本超支是软件项目中的常见问题。一项研究发现,软件项目平均支出超过了预算的50%,约30%参与项目的人员都需要加班[1]。低效率的风险管理是软件项目超支的主要原因之一,风险管理的核心是:能够在项目的任何阶段预测软件开发团队是否能够如期完成,同时将成本控制在预算之内,并最终实现设计要求。所以有效的计划、进度监控和预测对于迭代式软件开发项目的顺利完成至关重要[2–3]。本研究将重点放在预测软件开发项目一次迭代的交付能力,以确定项目能否会在迭代结束时交付目标的工作量,所提的方法可以从先前的迭代中学习以预测后续迭代的性能。
1 迭代式软件开发
1.1 软件交付预测概述
在软件开发过程中,一个项目会进行多次迭代[4]。一次迭代的时间通常为2到4周,在此期间开发团队设计、实现、测试和交付一个产品增量。每次迭代都需要解决和改进前一次迭代遗留下来的问题,这些问题会在迭代开始时被放置在待办列表中。
在迭代开始之前需要确定迭代计划,迭代计划包括迭代的开始时间、完成时间、待解决的问题、负责人和参与人。迭代期间可以添加和删除问题,迭代完成后会将本次迭代未完成和未解决的问题分配给下一次迭代。
为了预测属于集合中的问题,需要量化迭代中完成的工作量,并将其用作预测的基础。为每个问题分配若干个故事点,用速度表示单次迭代中完成的工作量,即迭代中完成的故事点总数,于是速度就反映了一个团队在一次迭代中完成了多少工作。
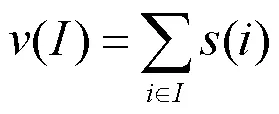
1.2 学习和预测阶段概述
此方法包括两个阶段:学习阶段和预测阶段(如图1)。学习阶段是基于历史迭代来构建预测模型,预测阶段是使用该预测模型来预测速度差。一次迭代包括许多特征变量(例如,持续时间、参与者等)和一组问题,而问题的依赖关系表示为依赖关系图,每个问题都有自己的属性和派生特征。本方法将迭代的派生特征分为三个部分:迭代属性、依赖图的描述符和问题集合的聚合特征。聚合特征是通过将问题空间中的一组点映射到迭代空间中的一个点而得到。其中,统计聚合为集合中的点寻找简单的集合统计信息,例如,迭代中问题评论数量的最小值、最大值、平均值和标准偏差。而词袋技术自动将问题空间中的所有点聚类,并为每个新点找到最接近的词以形成一组新的特征(即词袋)表示迭代。这种技术提供了一种强大、自动的方法,可以从它下一层的一组问题中进行迭代学习。对于预测模型,采用三种随机集成方法:随机森林、随机梯度提升机和深度神经网络来构建预测模型,以实现对迭代过程中交付能力的预测。
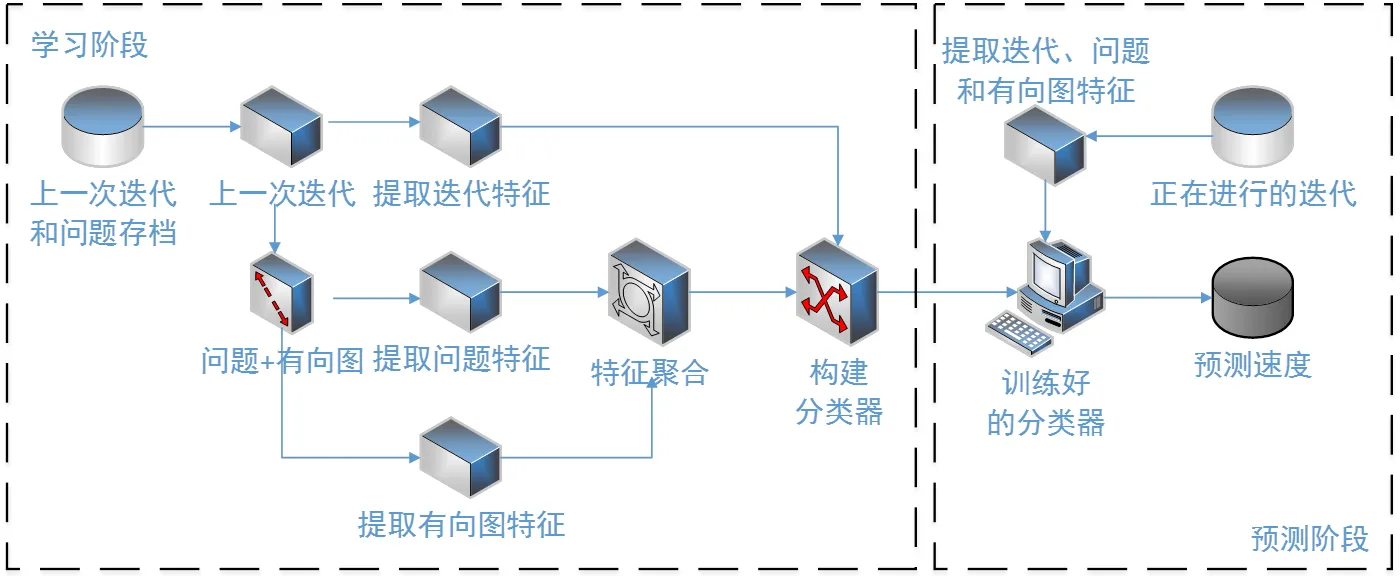
图1 学习阶段和预测阶段
2 特征提取
2.1 迭代特征
所考察的迭代特征包括迭代持续时间、迭代所包含的问题数量、问题的速度、新增问题数量、新增问题的速度、移除的问题、移除问题的速度、待处理问题、待处理问题的速度、正在处理的问题、正在处理问题的速度、已解决的问题、已解决问题的速度、管理者数量、团队负责人的数量和团队的规模。将预测时刻用作参考点来计算反映工作量的多个特征,包括在迭代开始时分配给迭代的问题集合以及在开始时间和预测时间之间从迭代中添加或删除的问题集合。此外,还利用了能反映团队在预测时间之前的进度特征:已完成的问题集合、正在进行的问题集合以及团队的待解决问题。团队的特征包括了团队负责人的数量和团队的规模。
2.2 问题的特征
分配给迭代的问题在表征迭代方面也起着重要作用,本研究所考虑的问题特征如表1所示。问题的详细信息包括了问题的类型、优先级、描述和故事点和所分配的迭代。这些特征直接从问题的属性中提取,包括类型、优先级、评论数量、影响版本数量和修复版本数量。每个问题都将被分配一个类型和优先级。
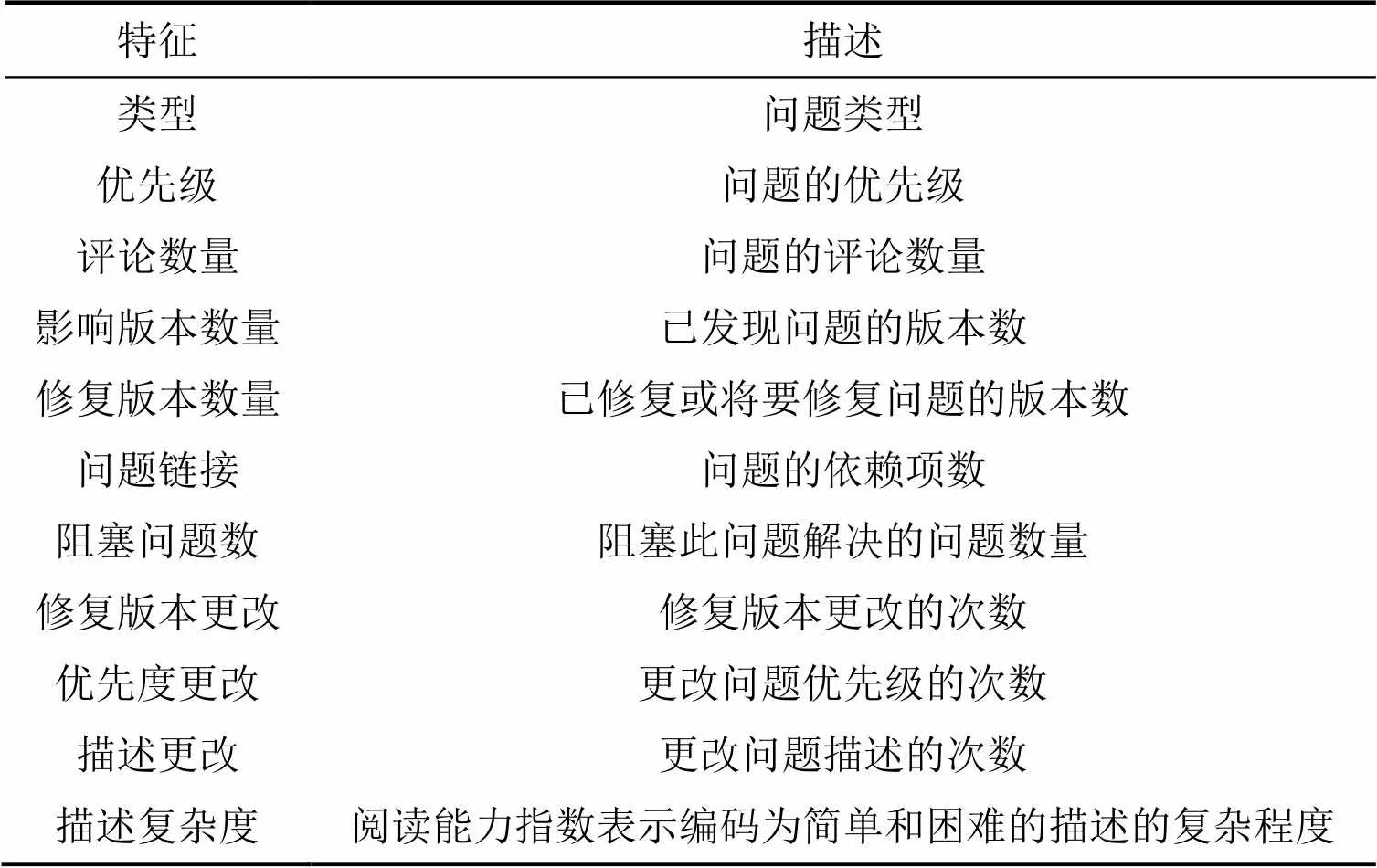
表1 问题特征
一个问题可能会在多个版本中出现,而影响多个版本的问题需要得到更多的关注。问题链接是指问题之间的关系,而问题链接拥有包括相关和依赖等多种关系类型。其中,阻塞是问题链接类型之一,属于阻塞类型的问题会阻止其他问题的解决。因此属于阻止类型的问题都需要优先修复。问题描述文本解释了问题的性质,有助于项目成员了解其性质和复杂性。采用了可读性度量来从问题文本描述中导出文本特征,使用Gunning Fox[5]根据可读性分数来衡量描述的复杂程度(即分数越低,越容易阅读)。
2.3 特征聚合技术
为了表征迭代,提取了迭代的特征和分配给迭代的问题的特征。特征聚合通过聚合分配给迭代的问题的特征,从迭代的问题中导出一组新的特征。这里讨论统计聚合和词袋两种不同的特征聚合技术,采用分配给迭代的问题的特征来表征迭代。描述这些问题之间依赖关系图的描述符也形成了一组代表迭代的特征,这些聚合方法能在不同方面捕获与迭代问题相关的特征。然后将迭代的特征及其问题的聚合特征输入分类器以构建预测模型。
2.3.1 统计聚合
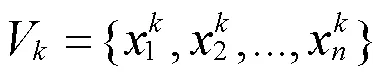
2.3.2词袋
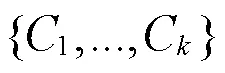
算法1 词袋算法
2.3.3 基于图的技术
迭代中的问题之间通常存在依赖关系,这些依赖关系以问题链接(如相关、依赖和阻塞)的形式记录。阻塞是问题跟踪系统中记录的一种常见的依赖关系。这种依赖关系形成了一个有向无环图,以描述如何安排迭代中解决问题的工作。
问题的有向无环图的复杂性描述符提供了一组表征迭代的特征。使用的一组基于图的特征包括了节点数、边数、传入边的总数、传出边的总数、问题的最大传入边数、问题的最小传入边数、平均传入边数、平均传出边数、最常出现的传入链接数、最常出现的传出链接数和节点和边的度分布。
3 预测模型
本预测模型可以预测迭代的实际交付速度与承诺速度之间的差异。为此,采用回归方法,其中输出反映迭代中的可交付能力。从历史迭代(即训练集)中提取的特征将用于建立预测模型。迭代的特征向量和分配给迭代的问题的聚合特征向量被连接并馈入回归器。
运用了随机集成方法,该方法使用许多回归器来进行预测。随机方法通过随机化数据、特征和内部模型组件来创建回归器。随机化是强大的正则化技术,可减少预测方差,防止过度拟合,对噪声数据具有鲁棒性,并提高整体预测精度。
所使用的回归器包括随机森林、随机梯度提升机和深度神经网络。所有这些都是使用分而治之的方法来提高性能的集成方法,使用一组“弱学习器”来形成一个“强学习器”。
4 实验评估
本研究从3个开源项目中收集了迭代及其问题的数据,这3个项目包含2295个迭代和这些迭代涉及的19592个问题。通过删除重复的迭代以及未来和正在进行的迭代,对数据进行了预处理。表2显示了数据集中的迭代次数和问题数量,并展示了3个项目的相关信息。3个项目的迭代长度都是在2到4周的范围内,而每次迭代的问题数量各不相同。

表2 项目信息
实验使用收集的所有迭代和问题来进行预测,以得到实际交付速度与目标速度之间的差异。例如,如果模型的输出是-2,则说明团队将比目标少交付2个故事点。
本研究采用了平均绝对误差(MAE)作为衡量本模型预测性能的指标。由于不同的项目有不同的速度差,因此需要对MAE进行归一化,并将此度量称为归一化平均绝对误差(NMAE)。另外,还用了精度、召回率、F度量、ROC曲线下面积(AUC)来衡量预测模型的性能。实验将使用了三种特征聚合方法的预测模型与仅使用迭代特征的预测模型进行了比较,结果如图2所示。对比结果表明,使用特征聚合方法获得的预测性能始终优于仅使用迭代特征的预测模型。
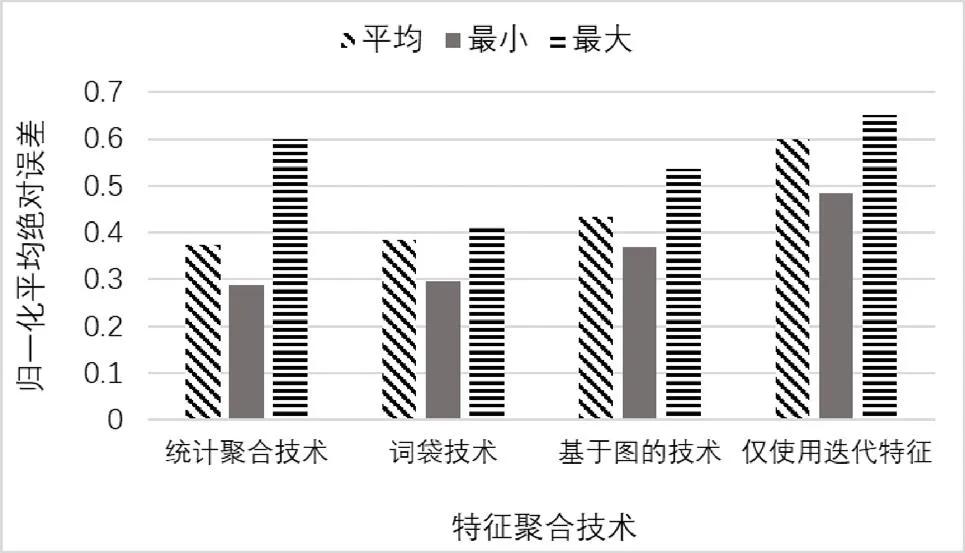
图2 特征聚合技术对比
接下来,对聚合特征组合的性能进行探索,结果如图3所示。由结果可知,在大多数情况下,两个或多个特征聚合方法的组合比单个聚合方法产生了更好的性能。然而,最佳的组合因项目而异。将统计聚合和词袋技术进行组合,探讨随机森林、随机梯度提升机、深度神经网络和支持向量机的性能,结果如图4所示。结果表明,所采用的三种集成方法均具有较低的归一化平均绝对误差,比支持向量机方法拥有更好的预测性能。
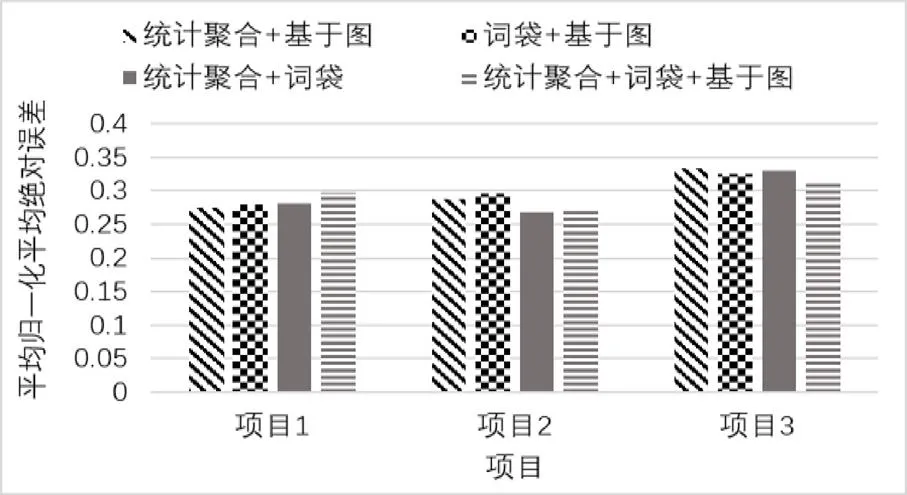
图3 组合特征聚合技术对比
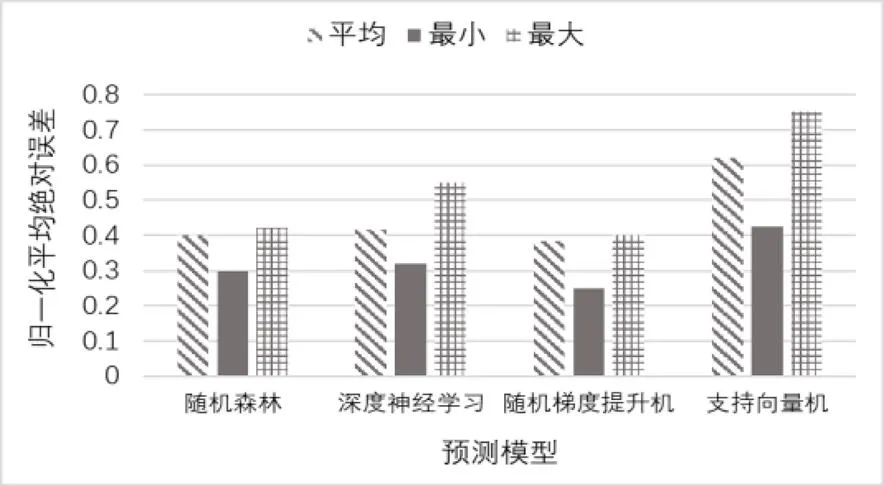
图4 预测模型对比
另外,展示了使用结合统计聚合和词袋特征组合的随机梯度提升机进行速度差预测的结果,如表3所示。表3显示了开源项目的精度、召回率、F度量和AUC结果,这些评估结果证明了本预测模型的有效性。
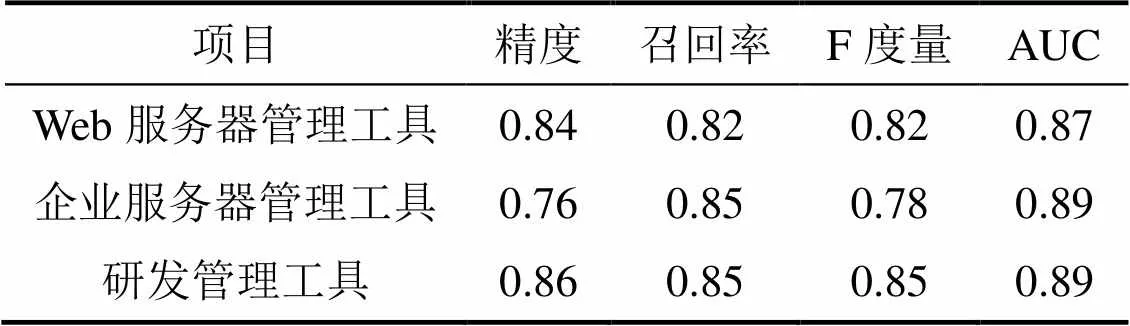
表3 预测性能对比
5 结语
本研究提出了面向迭代开发环境的数据驱动软件交付风险预测的方法,该方法利用迭代和迭代中的问题的特征,结合多种特征聚合技术,使用多种优秀的机器学习模型来预测在迭代过程中完成的工作量。使用多个项目数据来验证提出方法的有效性。实验结果表明,通过结合特征聚合技术的组合,本方法可以获得更好的预测性能。未来的工作将集中在通过结合更多的开发团队特征来丰富本方法,并将探讨如何使用图嵌入将问题依赖图应用于无监督的学习中。
[1] Bloch M, Blumberg S, Laartz J. Delivering large-scale IT projects on time, on budget, and on value[J]. Harvard Business Review, 2012, 5(1): 2–7.
[2] Kurniawan F F, Shidiq F R, Sutoyo E. WeCare project: development of web-based platform for online psychological consultation using scrum framework[J]. Bulletin of computer science and Electrical engineering, 2020, 1(1): 33–41.
[3] Copola Azenha F, Aparecida Reis D, Leme Fleury A. The role and characteristics of hybrid approaches to project management in the development of technology-based products and services[J]. Project Management Journal, 2021, 52(1): 90–110.
[4] Carneiro L B, Silva A C C L M, Alencar L H. Scrum agile project management methodology application for workflow management: a case study[C]//2018 IEEE International conference on Industrial engineering and engineering management (IEEM). IEEE, 2018: 938–942.
[5] 林煜明, 王晓玲, 朱涛, 等. 用户评论的质量检测与控制研究综述[J]. 软件学报, 2014, 25(3): 506–527.
Research on Data-driven Iterative Development and Delivery
MA Bo
(Information Technology Department, Yangquan Teachers College, Yangquan Shanxi 045000, China)
To improve the performance of monitoring software iteration and delivery, a new data-driven method is proposed to predict the delivery capability of software iteration and provide automation support for project managers. This method extracts the characteristics of historical project iterations and problems in iterations, and uses statistical aggregation, bag-of-words, and graph-based techniques to combine the characteristics of iteration problems to characterize iterations. Real open source project data are used to evaluate the method, and the results show that the method has better performance in predicting the iteration progress.
software delivery forecast; iterative development; driving by data
TP391
A
2095-9249(2021)06-0068-05
2021-12-17
马波(1979—),女,山西左权人,讲师,研究方向:计算机应用与技术。
〔责任编校:吴侃民〕
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
小猕猴智力画刊(2022年4期)2022-05-25 02:29:38
中学生百科·大语文(2021年4期)2021-05-12 18:04:07
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
发明与创新(2016年5期)2016-08-21 13:42:44
