
融合粗细粒度信息的长答案选择神经网络模型
2021-05-27 06:28:24张益嘉钱凌飞林鸿飞
中文信息学报 2021年4期
孙 源,王 健,张益嘉,钱凌飞,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
问答系统的构建一直都是自然语言处理领域中一个具有挑战性的任务,同时还在工业界有着广泛的应用(如智能助理,聊天机器人等)。答案选择[1]作为多数问答系统构建过程中的关键步骤,也一直受到广泛的关注。该问题可以定义为:给定一个问题及这个问题的候选答案,组成问题-答案对,计算问题-答案对的相关性评分,最终根据问题与其所有候选答案的相关性评分选择最适合该问题的答案。
长答案选择是答案选择任务的一个变种。如表1所示,不同于选择一个实体或单个句子的传统答案选择任务,长答案选择任务选择的通常是一段多句的长文本(如描述)。这种长答案通常出现在社区问答系统中,如在StackExchange学术论坛上的平均答案长度为229[2]。答案的文本长度和句子数量都有所增大的特点对当前的针对较短答案的答案选择神经网络模型提出了新的挑战。

表1 长答案选择(上)与传统答案选择(下)对比
大多数的答案选择问题是通过文本对匹配的方法解决的。该方法可以被分为两个主要步骤:①将问题序列和答案序列编码为相应的表示向量。②计算两个表示向量的相关性评分。早期研究者们使用卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural networks,RNN)及其变种等深度学习模型提取序列的上下文或时序信息,接着用拼接、池化等操作获取整个序列的向量表示。然后使用余弦相似度、神经网络匹配等方法获取两个序列的相关性得分,最后通过得分对答案池中的答案排序,选择其中得分最高的答案[1,3]。
如何利用注意力机制捕捉重要信息的能力来对文本序列更好地建模,是近期研究者们主要研究的问题[4]。该方法在答案选择领域的应用主要分为两类:①使用注意力机制捕捉问题序列和答案序列之间的关键信息,从而增大关键信息的权重并减小无用信息的权重。如Wang等[5]在使用RNN编码答案序列的上下文信息前,使用注意力机制获取答案中每个单词相对问题的权重,并对其加权。②使两个序列之间的信息得到交互。这种方法的思想主要是计算一个序列相对另一序列的对齐信息,然后通过原序列信息和对齐序列信息之间的融合(拼接原向量和对齐信息向量后使用多层感知机、拼接后池化等操作)获得该序列的另一序列感知表示[6-7]。两种方法都能通过让模型关注更重要的信息提升答案选择的准确率。
尽管上述方法在许多的文本匹配任务中取得了较好的效果,但由于长答案选择领域中答案通常较长(200以上),即使引入了注意力机制,将一个长序列编码为向量通常也不能很好地获取该序列的所有重要信息,研究者们采用比较-聚合框架来解决这个问题[2,8-9]。这种方法的思想是:通过对细粒度的文本(单词或n元单词)建模,比较这些细粒度文本之间的相似度,获取细粒度文本的相关性矩阵,然后聚合(池化、使用神经网络如CNN等操作)该相关性矩阵来进行下一步的决策。这类方法的主要贡献是有效利用了长句中更多的重要信息。尽管这种方法拥有长文本匹配效果好、模型参数少、拟合速度更快等优势,但也有过于关注细粒度的比较结果而缺失对全局信息把握的缺点。使得这类方法在带有一定推理性质的更加复杂的长答案选择任务中表现较差。
综上所述,现有的方法在长答案选择任务上取得了一定进展,但都有所不足。使用传统答案选择的句子建模方法将一段话编码为一个长度与单词数量相近的向量,即便能充分发挥注意力机制的优势,难免也会丢失一些重要信息。而针对长句设计的比较-聚合框架更加关注的是n元短语和短语之间的相关性,即便在聚合时使用相对复杂的神经网络模型,也很难不丢失全局性的语义信息,从而只关注句子中n元短语的相关性匹配,缺失了一定的推理能力。
为了保持传统句子建模中把握句子粗粒度信息和比较-聚合框架中处理细粒度信息这两种匹配方法各自的优点,本文结合两种方法的思想,设计了一个将比较细粒度相关性融入到句子建模过程中的模型(coarse-fine-grained information fusing model,CIFM)。在不使用预训练模型、外部语义特征、堆叠更深层模型等复杂方法的前提下,取得了很好的效果。同时设计了一个在句子建模的过程中不引入多余训练参数的细粒度级别相关性预测方法,在有效控制模型复杂度的前提下进一步提升了预测的效果。
1 模型描述
本节将介绍我们所提出的粗细粒度特征融合模型,图1是模型的整体结构。该模型主要由三个部分组成。分别是N个具有相同结构的特征萃取块(图中虚线部分)、细粒度级别的预测层和粗粒度级别的预测层。在本次实验中我们使用词向量将输入的问题和答案两个序列中的每个单词映射为词表示,分别记为Q∈n×e和A∈m×e。其中n和m分别是问题句子和答案句子的长度,e为词向量的长度。接下来我们将逐一介绍模型的主要组成部分。

图1 粗细粒度特征融合模型架构
1.1 特征萃取块
一个特征萃取块(如图2所示)是由获取上下文信息的编码器和获得两个句子交互信息的对齐融合层组成的。该模块的输入为问题序列和答案序列,输出为上下文编码器编码的特征序列。为了更加清晰地表述模型结构,图中省略了与虚-实线左侧对称的部分。本文提出的模型使用了多个特征萃取块(图2虚线所示)来获取更高维度的特征以及采用基于注意力机制的对齐、融合操作获得两个序列间的对齐特征。

图2 特征萃取块
研究者们在实验中发现,原始的词向量、富含上下文信息的编码器输出向量和对齐后的句子信息残差向量都在文本匹配的过程中占有重要位置[6]。因此,我们在本次实验中使用与之相同的加强版残差链接。编码器的输入除了词向量外还拼接了上个模块中对齐融合层的输出,对齐融合层的输入拼接了编码器的输入和输出,具体表示为:
(1)
(2)
其中,[]表示向量的拼接操作,第一个模块的编码器输入为单独的词向量,其余模块将词向量和对齐融合层输出的特征向量拼接作为输入。i表示第i个特征萃取块,in表示该模块的输入,out表示该模块的输出。
在这次实验中,我们使用两层CNN作为提取上下文信息的编码器。相较于其他常用编码上下文的神经网络(如RNN及其变种),CNN具有能够很好地抓住局部信息、可以并行操作等优点。在实验中我们也尝试了RNN及其变种,但模型的效果在运行时间增加的情况下没有明显提升,因此我们采用CNN作为编码器编码句子的上下文信息。

eij=F(ai)F(qj)T
(3)
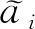
(4)
为了更加充分地利用原句信息和对齐信息之间的差异,与文献[6]相同,我们使用式(5)~式(8)的方式进行对齐后的融合操作。

1.2 细粒度预测层
该层的主要操作是对细粒度相关性比较结果聚合,解决答案句子过长导致的句子编码信息丢失问题。该层的输入为特征萃取块的输出,即上下文编码器编码后的问题序列特征和答案序列特征。输出为基于答案序列的细粒度相关性评分和基于问题序列的细粒度相关性评分。
Wang等[8]所提出的应用于长文本匹配的比较-聚合方法取得了很好的效果。受到该方法的启发,我们设计了一个没有训练参数引入的细粒度级别的预测层,该层的结构如图3所示,图中长方形为表示向量,正方形为相关性分数,虚线部分表示两个向量的点乘运算。具体描述如下。

图3 细粒度预测层
其中,n为问题长度,q′j为问题第j个token的答案对齐特征。基于答案序列的细粒度相关性评分获取方法和基于问题序列的细粒度相关性评分获取方法相同,这里不做过多叙述。
相较于文献[8]的方法,我们的方法采用了问题的答案感知和答案的问题感知两种对齐方式,分别获得了基于问题序列和基于答案序列的细粒度相关性评分。我们在实验中发现,使用基于两种序列的预测方式,而不是使用基于问题序列或答案序列的单一方式,能有效提升预测准确率。
除此之外,相较于文献[8]使用卷积神经网络进行细粒度级别相关性评分的聚合操作,我们采取了平均池化操作。这样做可以在不损失预测准确率的前提下有效地减少模型的复杂度。
为了充分地利用每一层特征萃取块萃取的特征,我们对其每层输出的上下文表示向量都做一次细粒度级别的预测。
1.3 粗粒度预测层
该层的操作主要分为两步。首先分别获得答案序列和问题序列的向量表示,其次使用多层感知机(multilayer perceptron,MLP)获得两个序列的粗粒度相关性评分。
受注意力机制的启发,我们设计了一个自动获取句子序列中每个token的权重的方法。获取到的权重用于将序列的矩阵表示加权平均为相应的向量表示。这种加权池化的操作相较于最大池化能减少有效信息的丢失,从而增加模型预测的准确率。该层的结构如图4所示,图中长方形为表示向量,正方形为相关性分数,虚线部分表示两个向量的点乘运算,具体描述如下:
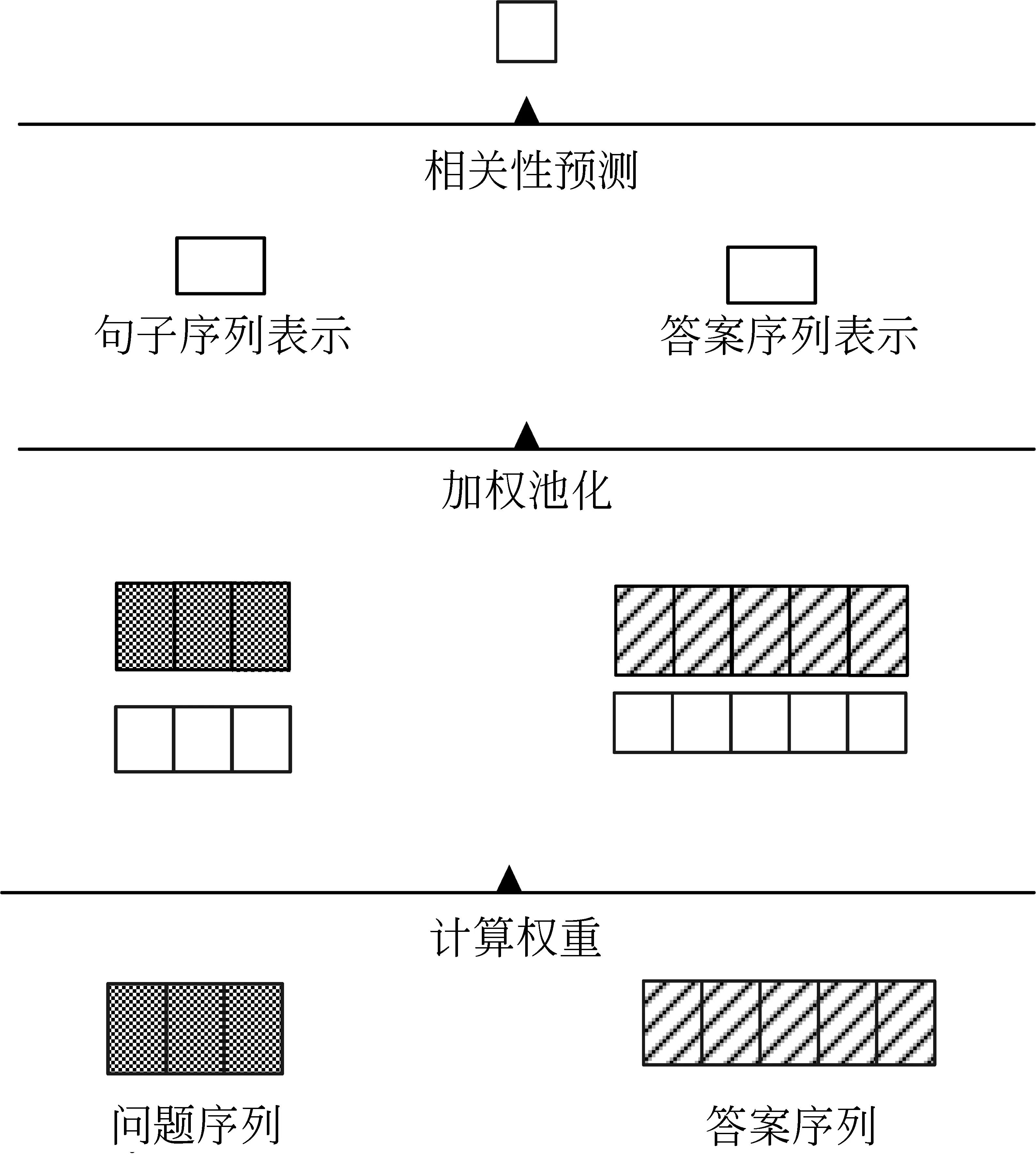
图4 粗粒度预测层
其中,w_qj为问题的第j个token的权重,q为问题序列的向量表示,m为答案序列的长度。问题序列的向量表示获取方法与之相同,这里不做过多叙述。
最后,拼接两个句子特征向量,输入到两层的前馈神经网络,获得粗粒度相关性评分。我们还尝试使用向量点乘来衡量两个句子向量的相关性,但实验结果表明由两层的前馈神经网络构成的神经网络匹配器可以更好地衡量由最大池化产生的高维抽象特征之间的相关性。具体操作如式(16)所示。
psentence=MLP([q;a])
(16)
其中,MLP为多层感知机。我们在实验中发现,还未经过对齐信息交互的上下文编码特征在长句匹配中有重要作用。因此,相较于文献[6]使用对其融合后的特征向量进行粗粒度预测,我们选择了特征萃取块中上下文编码器的输出作为粗粒度预测层的输入,同时对每个特征萃取块的输出都做一次粗粒度预测,保证了对齐信息的利用。
为了更好地衡量每个预测层的预测结果所占权重以及在训练中自动获取这个权重,我们使用自获取权重的加权平均,即拼接所有预测层的预测结果并输入到单层的前馈神经网络中。这样做的好处是可以学习到特定任务所需的预测层权重。综上,该模型的最终预测结果如式(17)所示。
(17)

2 实验分析
2.1 实验设定
2.1.1数据集及评价标准
我们在三个不同的长答案选择数据集上评估我们的模型。数据集详细信息见表2,其中答案长度为数据集中所有答案的平均长度。为了维持在每个数据集上进行模型对比的公平性,我们延续了每个数据集本身常用的评价方法,具体如下。
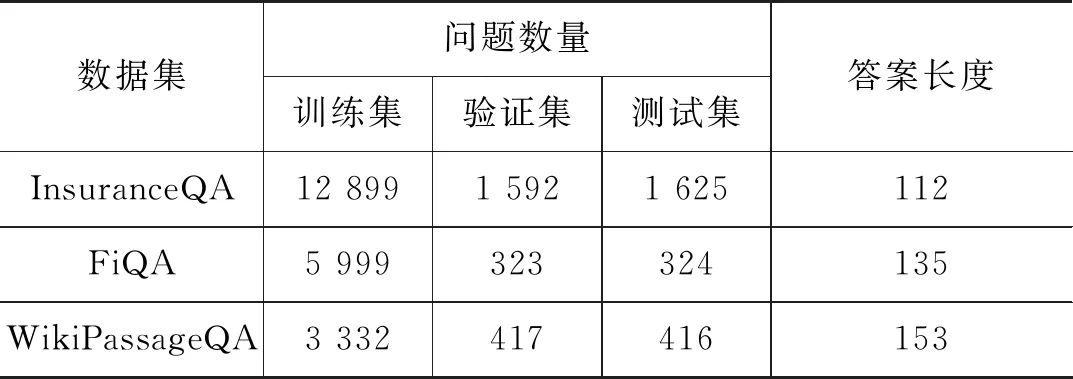
表2 数据集详细信息
InsuranceQA[1]是一个有关保险问答的数据集,它在答案选择领域得到了广泛的使用。在本次实验中,我们使用近期更新的第二版。其中每一个问题的候选答案池大小为500。为了保证对比的公平性,和已存在的实验[2]一样,使用正确率来对模型在这个数据集上的结果进行评估。FiQA[10]是金融领域的社区问答数据集。我们采取文献[11]的方法对数据进行了简单的预处理。处理后的结果如表2所示。我们使用常用的检索评价指标MAP(mean average precision)和MRR(mean reciprocal rank)来对模型的效果进行评估。WikiPassageQA[12]是一个近期的相关篇章检索任务,该任务的问题和传统的社区问答问题同样是非实体问题,答案长度也和社区问答领域的长度相当。在这个数据集上,我们使用与FiQA数据集相同的指标进行模型效果的评估。
2.1.2 对比实验
对比实验可分为两类,一类是对比使用传统文本匹配方式即建模句子表示的方法。在这类实验中我们分别对比了基于长短期记忆网络(long short-term memory,LSTM)的方法[13]和基于CNN的方法[6]。两种方法都使用池化操作来获得句子表示,但在预测相关性时有所不同。其中文献[13]使用余弦相似度来刻画两个句子的相关性,而文献[6]拼接两个向量,使用双层前馈神经网络构成的神经网络匹配器完成预测。
第二类对比了使用比较-聚合框架思想的方法。CNN能很好地获取局部的上下文信息,这在使用比较-聚合思想的模型中是至关重要的。因此在本次实验中我们对比了两个基于CNN的现阶段最高水准的模型[2,8]。
本次实验中的对比试验均使用原作者的开源代码,并在实验前根据原作者提出的实验结果进行代码的有效性验证,保证了实验的公平性和有效性。
2.1.3 训练与参数设置
为了缓解正负样本不平衡的问题(如InsuranceQA数据集中平均正负样本比例接近1∶60),我们采用与文献[13]相同的负样本采样方式。即为每个正例挑选一个“最错误”的负例。挑选方式为:在每个问题的候选答案池中随机选择一部分错误样例,放入当前模型中进行预测,选择其中预测结果最高的作为“最错误”的负例。为保证实验的公平性,我们在本文的所有实验中均使用以上方式挑选训练样本。其中除文献[13]的实验采用max-margin hinge loss训练模型外,其他模型均采用交叉熵损失函数。所有模型参数的训练均使用随机梯度下降法。
对比实验模型的超参数设定均与其相关论文相同,对于文本匹配领域的模型[6]来说,超参数的设定与其答案选择任务设置的参数相同。本文实验使用了3块特征萃取块,词向量由FastText[14]初始化,其中编码器使用两层窗口大小为3的CNN,实验中所有隐层大小为150,激活函数为ReLU,学习率为0.005,batch_size大小为64。
2.2 实验结果与分析
实验结果如表3所示。我们的模型相较于基于比较-聚合框架的模型在三个数据集上都有很大的性能提升(如在InsuranceQA数据集上对比两个模型分别有5.71%和8.60%的准确率提升),这说明了在长答案选择任务中,仅仅关注问题和答案的细粒度匹配结果是不够的。细粒度匹配的结果在全局信息的指导下才能更好地对整个句子之间的相关性进行判断。

表3 实验结果
相较于传统的句子建模方法,我们的模型在融入了细粒度比较信息后性能也有所提升。例如在WikiPassageQA数据集上,我们的模型较RE2[6]有6.34%的MAP值提升。可以看出细粒度信息的融入能缓解长句子建模为向量时重要信息把握不足的缺点。同时我们的模型在不引入额外参数的情况下融合了细粒度信息,这在很大程度上降低了模型的复杂度。
因此,在长答案选择任务中,相较于单一使用细粒度信息或粗粒度信息的方法,我们的模型能更有效地聚合这两种重要信息,使该任务的准确率得到提升。
2.3 消融实验
为了验证本文提出模型每个部分的有效性,我们对模型进行了消融性研究。该研究将分6个部分与原模型进行对比,分别是:①仅仅使用一层特征萃取块;②不使用细粒度级别的预测结果;③仅使用第一个特征萃取块的上下文感知向量进行细粒度级别的预测;④仅使用最后一个特征萃取块的上下文感知向量进行细粒度级别的预测;⑤不使用粗粒度级别的预测结果;⑥采用算术平均而不是神经网络对最后的两类预测结果进行聚合。
该消融实验是在答案池长度为500的InsuranceQA数据集上进行的,和上文所述相同,我们采用准确率作为模型效果评估的指标。实验的结果如表4所示。
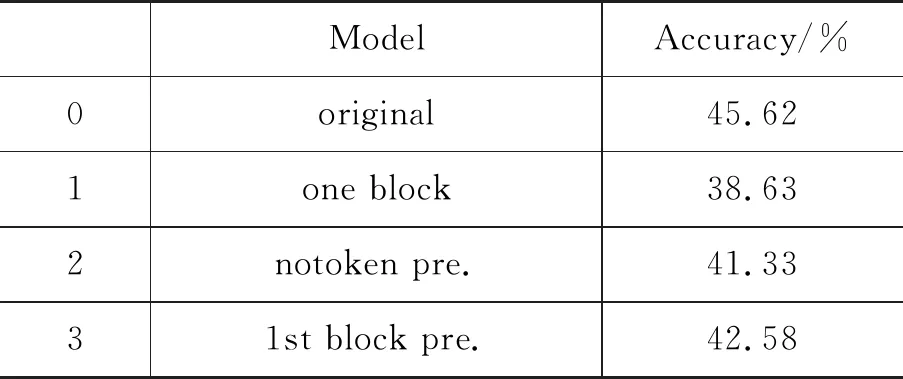
表4 InsuranceQA数据集上的消融实验结果

续表
第一组消融对比实验的结果说明,仅仅使用一层特征萃取块不能充分获取序列所有的重要信息,以及未能利用到问题序列和答案序列的对齐信息。减少特征萃取块的数量同时会减少细粒度级别预测的次数,这也可能是性能下降的原因之一。我们在实验中还测试了增加特征萃取块数量的影响,实验结果表明模型的表现并非与萃取块的数量成正相关,过多的萃取块除了会增加模型的复杂度外还有可能引入一些错误信息。
第2组到第4组的对比实验体现了细粒度级别预测的重要性。在不使用细粒度级别预测时,我们的模型和文献[6]的模型需要训练的参数是相同的,在不引入多余训练参数的前提下,我们的模型比文献[6]的模型在InsuranceQA数据集上的准确率提升了3.30个百分点,相比不使用细粒度预测提升了4.29个百分点,这足以证明细粒度级别预测在长句匹配中占有重要地位。同时可以发现,仅仅使用一层细粒度级别预测,如第3组和第4组对比实验,虽然相较不使用细粒度级别预测(第2组实验)性能有所提升(分别提升1.25个百分点和0.70个百分点),但很明显不能充分利用每一个特征萃取块所提取的信息。
第5组对比实验的结果表明,不使用句子的全局信息会导致预测的准确率大幅度下降(6.71个百分点)。直观来看,单词或n元单词之间的相关性也不能准确地衡量句子和句子之间的相关性。因此,以句子的全局信息为主并辅以单词或n元单词之间的相关性信息,能更好地解决长答案选择问题。
我们同样测试了使用每个预测结果的算术平均数作为最终的预测结果(第6组)。实验结果表明这样做同样不能很好地利用粗细粒度级别信息。在实验中我们还观察到对于不同的数据集,每个预测结果在聚合过程中所占的比重是不同的。由此我们推断神经网络可以更好地对粗细粒度级别预测的关系进行建模,从而得到一个任务相关的关系最优解。
2.4 长答案选择效果分析
我们还在答案池长度为100的InsuranceQA数据集上分析了答案长度与CIFM(结合粗细粒度信息)、RE2(使用粗粒度信息即句子建模)、COALA(使用细粒度级别预测)三个模型预测准确率的关系,结果如图5所示,其中答案长度小于50的样例因为数量过少而没有参与统计。

图5 InsuranceQA数据集上答案长度与准确率的关系
实验结果表明,细粒度信息对准确率的提升主要集中于对答案长度大于100的样本预测。这也验证了我们所提出的细粒度级别预测相对于仅使用句子建模的方法[6]能更好地应对长句之间的匹配。同时相较于只使用细粒度级别预测的方法[2],实验结果在各个长度部分都有所提升,这也说明了句子全局信息在衡量句子之间相关性时占有很重要的地位。
为了进一步分析答案长度与模型预测准确率的关系,我们将整个InsuranceQA数据集分为答案长度小于100、答案长度在100与200之间、答案长度大于200这三部分,重新对模型进行训练,最后结果如图6所示。

图6 拆分InsuranceQA后重新训练的答案长度与准确率关系
可以看出,我们的模型在三部分数据集上的答案选择准确率仍处于领先地位。其中在答案长度100到200这一长答案选择任务主流区间中,CIFM相较于RE2的准确率提升从3.30%到4.59%。因此,我们的模型在训练更加普遍的长答案选择任务中更具优势。而在答案长度大于200这部分数据集上,我们的模型相较于RE2的性能提升有所下降,可能的原因是训练数据的缺乏(这部分训练集占整个InsuranceQA数据集的13%左右)。与之相同,所有模型的预测准确率都受到了训练数据减少的影响。但我们的模型在训练答案长度过长(大于200)的答案选择任务时受到训练集数量的影响较大,这可能是未来需要改进的缺点之一。
2.5 错误分析与展望
在类似句子主题之间相互匹配的长句选择上,我们的模型有较高的准确率。而错误的选择主要集中在带有推理性质的长句选择上。例如:
问题:why is my car insurance claim being investigated ?
(译文:为什么我的汽车保险索赔被调查?)
答案1(模型给出的最优答案):the insurance company first investigates to determine the coverage they have on the vehicle.then they determine responsibility in the case of a crash.then they determine the extent of damage.because the adjuster handles numerous claims they can spot a claim that requires additional investigation.if fraud is suspected the investigation takes a much deeper look into the circumstances of the crash.
(译文:保险公司首先调查确定他们的保险范围,然后他们确定事故的责任方,接着确定损坏程度。富有经验的理赔员会发现需要进一步调查的保险索赔。如果可能存在欺诈行为,就需要对车祸情况进一步调查。)
答案2(Ground Truth):hard to answer such a question without any details.but in general,I wouldn’t worry too much about it.fraud is so out of control,that they have to investigate certain claims.during the claims process,companies have their set of “red flags” that triggers further investigation.as long as you have nothing to hide,you shouldn’t worry about it too much.they may ask for things such as:- bank statements - proof of residency - receipt from last oil change - etc.,etc.,etc..sometimes innocent minor things can trigger a red flag,and it ends up being no big deal.other times,fraud is suspected.and sometimes,a high dollar amount of loss can trigger an investigation simply for due diligence.so don’t sweat it.if you have nothing to hide,give them what they want and you should be fine.
(译文:在没有细节的情况下很难回答这个问题。但正常情况下我不会对此感到担忧。欺诈行为横行,因此保险公司需要调查清楚情况。在理赔阶段,公司有一些“红灯标志”会触发进一步的调查。只要你没什么隐瞒的,就不需要担心。他们可能会需要诸如:-银行对账单-居住证明-上次加油收据等。有时一些小事也会触发警报,但这没什么。有时是被怀疑欺诈;有时为了尽职调查,高额损失也会触发警报。所以不用担心。给他们想要的,理赔会正常进行。)
以下我们简称答案1(模型给出的最优答案)为错误答案,答案2(Ground Truth)为正确答案。
正确答案与错误答案都有与问题相匹配的主题,例如调查、索赔等。但在总体上,错误答案阐述的是车祸理赔调查的过程,而正确答案所阐述的才是问题所问的为什么被调查。这种带有一定推理性质的预测是该模型不能有效处理的问题。即使一些句子建模方法如文献[6]等提出的模型在一些自然语言推理任务如文本蕴含中有很好的效果,但在长文本如篇章推理方面还有所欠缺。
在不能有效推理的前提下,错误的相关性推断也可能导致模型选择了错误的答案。例如,因为正确答案中没有任何与问题里汽车保险相关的信息,无论是在细粒度匹配过程中还是在句子建模过程中都会因为这部分信息的缺失而降低最后的相关性预测结果。与之相较,错误答案中由于带有“车祸”信息,可能会增加与问题之间的相关性评分。由“车祸”信息增加的相关性显然是不合理的,但该模型并不能对其进行有效的分辨。这种情况在只使用细粒度信息的模型中很常见,因为对句子全局信息的缺失,模型只能通过判断细粒度信息之间的相关性而对结果进行判断,缺少对全局的把握,从而引入错误的相关性判断。
综上所述,如何能在保持主题匹配准确度的同时,加强模型的推理能力是未来提升长文本选择效果的可行性研究方案之一。例如,对待为什么我的汽车保险索赔被调查这一问题,可以使用注意力机制将匹配的重心放在为什么、保险索赔、调查等方面,而不是汽车保险方面。除此之外,还可以加大对粒度大小的进一步研究,如以句子为粒度对多句的答案序列进行划分,通过聚合问题序列与多个答案句子之间的相关性比较结果,对问题序列和答案序列的相关性进行评估。
3 结论
我们提出了一个同时使用粗细粒度信息进行预测的长答案选择模型,有效解决了建模句子方法信息抓取不全和细粒度相关性比较缺失全局信息的问题。设计了一个不引入多余训练参数的细粒度预测方法,该方法不但可以有效提升长答案选择任务的准确率,还可以为其他相关长句研究提供新思路,在3个相关领域数据集上都取得了当前最高水平的评估结果。同时还分析了在答案长度较长情况下模型的有效性。此外我们还对模型的常见错误进行分析,并提出了未来进一步可能的研究方向。
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
新高考·高一数学(2022年3期)2022-04-28 07:02:46
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
高技术通讯(2021年1期)2021-03-29 02:29:24
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中国交通信息化(2018年5期)2018-08-21 03:37:40
电脑与电信(2018年11期)2018-02-16 05:41:32
信息安全研究(2016年3期)2016-12-01 06:06:41
