
基于Transformer-BiLSTM-CRF的桥梁检测领域命名实体识别
2021-05-27 05:32:00杨建喜莫天金蒋仕新
中文信息学报 2021年4期
李 韧,李 童,杨建喜,莫天金,蒋仕新,李 东
(重庆交通大学 信息科学与工程学院,重庆 400074)
0 引言
作为文本信息抽取的基础性工作之一,命名实体识别研究多年来一直受到学术界和产业界的广泛关注。以条件随机场(conditional random field,CRF)为代表的概率图模型成为命名实体识别任务的经典方法。近年来,随着双向长短期记忆(bidirectional long short-term Memory,BiLSTM)网络和文本分布式表示等理论方法的长足发展,面向通用领域人名、地名和组织机构名等目标的命名实体识别方法取得了较大幅度的性能提升[1],并为智能问答、知识图谱构建等任务奠定了基础。与此同时,国内外学者也针对中文电子病历[2]、军事文本[3]和生物医学[4]等特定领域命名实体识别方法进行了许多有益探索。
随着交通基础设施建设的快速发展,我国已有80余万座公路桥梁建成服役。以《公路桥涵养护规范》和《公路桥梁技术状况评定标准》等行业规范为指导,在一定实施周期或特殊服役状态条件下,开展以结构构件表观病害、材料性能劣化和结构几何变形等为主要内容的桥梁检测,已成为当前我国公路桥梁管理养护业务体系中最重要的工作内容之一[5]。目前,业界已积累了大量桥梁检测文本数据,其中蕴含了丰富的桥梁结构参数、结构病害检测结论及养护维修处置建议等重要信息。对桥梁检测文本开展以命名实体识别为基础的关键信息抽取方法研究,可为科学化、智能化的桥梁管理养护决策及领域知识共享奠定基础,也是人工智能时代桥梁工程领域的迫切需求和发展趋势[6]。然而,虽然业界已有少量面向桥梁检测领域的命名实体识别研究成果[7],但现有方法仅针对英文桥梁检测文本,适应于中文语境的相关方法研究尚未有效开展。正如本文第2小节分析所述,由于桥梁检测文本中包含较多专业术语,并且待识别的命名实体存在地名或路线名嵌套、字符多义、上下文位置相关和方向敏感等较强特性,需要探寻一种适用于该问题域的实体识别解决方案。
本文面向桥梁管理养护实际行业需求及其检测文本领域特性,结合Transformer的长距离位置依赖关系建模和BiLSTM的双向序列特征提取能力,提出一种基于Transformer-BiLSTM-CRF联合模型的桥梁检测领域命名实体识别方法。通过构建桥梁检测命名实体语料,并在无预训练模型和有预训练模型支撑两种场景下,与当前主流的命名实体识别神经网络模型进行对比实验,本文提出的方法在实验数据集下具有更好的综合识别效果。
本文的组织结构如下:第1节对国内外相关研究现状进行介绍。第2节提出桥梁检测领域命名实体识别的具体目标并分析其领域特性。第3节阐述提出的Transformer-BiLSTM-CRF模型架构及其命名实体识别方法。第4节在介绍实验语料和实验设置的基础上,对实验结果进行分析。第5节给出本文结论及后续工作展望。
1 相关工作
由于基于规则或统计机器学习的传统命名实体识别方法依赖于人工构建文本特征,基于深度神经网络模型的“端到端”识别方法成为当前主要研究方向[8]。例如,Huang等[9]提出了BiLSTM-CRF模型,并将其应用于命名实体识别和词性标注等序列标注任务。该网络结构成为后续众多模型方法扩展的基础。另外,Collobert等[10]提出了卷积神经网络(convolutional neural networks,CNN)与CRF相结合的命名实体识别方法,在CONLL2003语料上取得了较好的识别效果。李丽双等[11]提出了基于CNN-BiLSTM-CRF联合模型的生物医学命名实体识别方法,通过CNN获取字符级特征补充词向量,在Biocreative Ⅱ GM和JNLPBA2004语料中实验的F1值分别达到89.09%和74.40%。
在中文命名实体识别任务方面,由于不准确的中文分词可能会造成误差传递问题,以字向量作为输入特征成为中文语境下的另一解决方案[12]。除此以外,张海楠等[13]提出基于字词联合特征编码的深度神经网络模型,在人民日报语料的人名、地名和组织机构名实体识别取得了F1值的有效提升。盛剑等[14]面向多场景、多领域文本环境,提出了基于BiLSTM-CRF模型并引入CNN特征提取模块的细粒度命名实体识别方法,面向全领域实体识别平均F1值达到80%左右。禤镇宇等[15]面向影评人名实体识别具体问题,将预训练字向量和边界特征、用字特征等人工特征相结合,并采用了BiLSTM-CRF模型进行字符序列标注。2018年,Zhang等[16]提出了基于Lattice-LSTM模型的命名实体识别方法,通过字符和词特征的联合表示,并在外部大规模词典嵌入的支撑下取得了较好的通用领域数据集评测效果。由此可见,当前基于深度神经网络的命名实体识别方法总体上可以规约为由嵌入层、编码层和解码层构成的三层模型架构,其中适宜的特征表示和深度网络模型是实现识别性能提升的关键。
近年来,为克服传统深度神经网络模型在长程记忆能力等方面存在的不足,国内外学者开始将注意力(attention)机制引入深度神经网络模型,并在自然语言处理研究领域取得了较好的应用效果[17]。例如,杨培等[18]将注意力机制加入到BiLSTM-CRF模型中,在化学药物命名实体识别任务中取得了较好效果。2017年,Vaswani等[19]提出了融合多头注意力(multi-head attention)和位置编码(positional encoding)等机制的Transformer模型。在此基础上,Devlin等[20]提出了BERT(bidirectional encoder representations from transformers)预训练模型,并在通用领域的11项文本分析任务中取得了当时的最佳效果,成为当前国内外自然语言处理领域关注的焦点。在此基础上,Sehanobish等[21]提出了基于中文字形的命名实体识别方法,通过联合BERT文本预训练模型与基于CNN的中文字符图片预训练模型作为输入,在BiLSTM-CRF网络模型中进行实体识别,并取得了较好的实验效果。然而,开源的BERT模型通常基于通用领域文本进行预训练,对于含有大量专业术语和语法结构的特定领域很难直接适用。另外,Sehanobish等的方法需要海量中文字符图片作为支撑,且引入更多模型参数,需要海量数据作为训练样本支撑,这一前提条件对语料资源相对匮乏的特定领域是极大挑战。
针对桥梁检测领域文本的信息抽取任务,目前仅有Liu等[7]提出了基于BridgeOnto本体和半监督CRF的结构状态和养护活动命名实体识别方法。然而,该方法仅面向英文桥梁检测报告,适用于中文桥梁检测文本描述方式特性的命名实体识别方法仍有待进一步研究。
2 桥梁检测领域命名实体识别目标与特性
通过收集多地区真实桥梁检测报告并分析其特性发现,该领域文本通常包含了桥梁基本信息、检测内容、检测工具、检测结果和后续管养处治建议等章节,其中蕴含的桥梁名称、桥梁结构部件或构件描述、病害检测结果等是桥梁工程业界最关心的业务内容。因此,在充分考虑我国公路桥梁业主需求的基础上,参照桥梁结构划分、病害表征及技术状况评定方法等行业规范,将桥梁检测领域命名实体定义为六大类别,分别是桥梁实体(BRI)、桥梁结构实体(ENT)、结构元素实体(ENTE)、结构位置实体(ENTL)、结构病害实体(DIS)和病害否定修饰(UND)。在“不重叠、不嵌套、不包含停顿标点符号”的常用原则下,本文面向最小粒度的上述实体进行识别,即若文本中有描述“重庆长江大桥桥墩”,那么“重庆长江大桥”为BRI实体,“桥墩”为ENT实体。表1给出了桥梁检测领域命名实体类型及其示例。

表1 桥梁检测领域命名实体类型及其示例
除了上述桥梁检测领域命名实体识别目标与通用领域的人名、地名、组织机构名等存在较大区别以外,由于桥梁结构属性参数及其检测文本信息具有一定的隐私性要求,难以获取到类似于通用领域的海量语料。与此同时,上述各类型命名实体还存在以下领域特性。
(1) 由于我国公路桥梁通常以所在地区或者服务路线为命名基础,因此,BRI实体通常嵌套有城市地名、路线桩号等信息,并伴有英文或数字的联合表达,以及存在不同风格的缩写形式。例如,桥梁名“重庆大佛寺长江大桥”包含有“重庆”和“大佛寺”两个地名,并且可能简称为“大佛寺大桥”。“X655线李渡长江大桥”同时包含了英文和数字组合构成的路线及地名信息。
(2) 相同字可能存在于多种类型领域命名实体中,并具有较强的字符多义性、上下文位置相关性和方向敏感性。例如,“桥”通常作为BRI实体结束字,也可能描述“桥墩”“桥台”等某一类型结构构件并作为ENT实体的开始字。在描述某一具体构件时,会存在类似于“0#桥台”的表述方式,而“桥”字在该ENT实体的中间位置处出现,并伴随在数字和特殊符号之后。
(3) 各类型领域实体之间存在较强的上下文位置关联性。结构病害DIS实体通常出现在ENT、ENTE或者ENTL实体之后。例如,在结构病害描述的“桥台泥沙淤积”中“桥台”为ENT实体,“泥沙淤积”为DIS实体。“3#梁段存在网状裂缝”中“3#梁段”为ENTE实体,“网状裂缝”为DIS实体。否定修饰UND实体可能对ENT和DIS等多种实体进行描述。例如,“没有明显开裂现象”中的“没有明显”为UND,“开裂”为DIS实体,“未设置伸缩缝”中“未设置”为UND,“伸缩缝”为ENT实体。
由此可见,该领域命名实体识别任务涉及较多专业术语与各类型实体间的位置关联性特征,以及中文字符多义性和方向敏感性特征等。以满足上述目标任务和适应该领域文本特性为动机,本文结合Transformer模型在长距离位置依赖关系特征建模、BiLSTM模型在文本方向性特征建模,以及CRF模型在标签约束关系预测方面的优势,开展桥梁检测领域命名实体识别方法研究,并提出基于该联合模型的解决方案。
3 Transformer-BiLSTM-CRF模型
图1为本文提出的桥梁检测领域命名实体识别的Transformer-BiLSTM-CRF模型架构。该模型由Transformer模块、BiLSTM模块和CRF模块三部分组成。其基本思想是:以桥梁检测语料字符序列为输入,首先在Transformer模块中对上下文长距离的位置依赖特征进行提取,以此作为BiLSTM模块的输入。BiLSTM模块进行文本序列的方向敏感性特征提取,并在CRF模块中对上下文标注进行约束,最终输出序列标注结果。

图1 桥梁检测领域命名实体识别的Transformer-BiLSTM-CRF模型架构
3.1 Transformer模块
如文献[18]所述,面向机器翻译等Seq2Seq任务的Transformer模型主要包含编码器(encoder)和解码器(decoder)两个主要部件。本文提出模型仅使用其中的编码器进行桥梁检测语料文本序列的长距离位置依赖关系特征建模。
该模块首先对输入文本序列进行划分和字嵌入,得到输入张量Xinput∈b×l×d,其中b为批次大小,l为序列长度,d是字嵌入维度。然后,按式(1)对序列字符按sin和cos函数的线性变换进行位置编码,获取字符在当前句子中的位置信息。

(1)
其中,pos表示字符位置,i表示字符向量维度。每个编码器由多头自注意力和前馈神经网络两个内部层次构成。将位置编码与字嵌入元素相加后得到的Xembedding按式(2)分解为Q(h)、K(h)和V(h),并作为Transformer Encoder模块的输入。
其中,WQ、WK和Wv为权重参数矩阵,h∈[1,n]为head索引,head数n为超参数。然后,按式(3)进行注意力运算,在获取句子中每一个字与其他字相关性的同时,使得每个字向量都含有当前句子中其他相关字向量信息。多头自注意力计算的结果按式(4)进行拼接。
然后,将多头注意力计算的MultiHead(Q,K,V)与Xembedding进行残差连接得到Xattention,并进行归一化计算,得标准正态分布,从而加速训练和收敛。
编码器中的全连接前馈神经网络层以Xattention为输入,如式(5)所示,使用ReLU作为激活函数并进行两次线性映射,分别完成维度的扩展与压缩。
其中,W1,W2,b1和b2分别为对应的权重矩阵和偏置。最后,FFN(X)与Xattention再进行一次残差连接和归一化计算,得到编码器的输出Xhidden。
在实际的联合模型构建过程中,编码器模块可以进行多次叠加。除了最底层的编码器以随机初始化字向量或者预训练字向量为输入以外,其余层级的编码器均以上一层次输出的Xhidden为输入,并且计算过程中的Xinput,Xembedding,Xattention和Xhidden均有相同的维度,即实现输入文本序列在位置编码和多头自注意力机制下的字符级特征无监督学习与表征。
3.2 BiLSTM模块
BiLSTM模块由前向LSTM和后向LSTM组成,能够从前后两个方向获取序列的上下文信息。作为一种特殊循环神经网络(recurrent neural network,RNN)模型,每个LSTM包含了输入门、遗忘门和输出门三种“门”节点,以克服传统RNN模型在面向长序列特征提取过程中存在的梯度消失等问题。式(6)描述了LSTM具体计算过程。
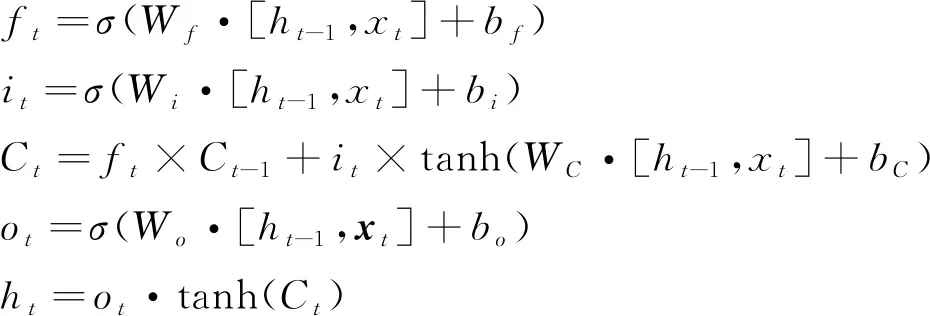
(6)
其中,σ是sigmoid函数,tanh为双曲正切函数;Wi,Wf,Wo分别是输入门、遗忘门和输出门的权重矩阵,bi,bf,bo为对应的偏置。首先,以t-1时刻的隐藏层状态ht-1和当前t时刻的字向量xt为输入,分别计算出遗忘门值ft,输入门值it。以此为基础,结合t-1时刻的细胞状态Ct-1计算出当前的细胞状态值Ct。然后,在计算输出门值ot的基础上,得到当前时刻的隐藏层输出ht。
为应对训练过程中可能存在的过拟合问题,在BiLSTM两端分别设置了Dropout层,并将t时刻的正向LSTM输出和反向LSTM输出进行拼接,得到该模块的最终输出结果。
3.3 CRF模块
以Transformer和BiLSTM模块提取的上下文特征为输入,CRF模块考虑序列标签之间的相邻依赖关系,并对最优标签序列进行求解。即对于一个输入序列S={x1,x2,…,xn},以及对应的预测标签序列y={y1,y2,…,yn},n为序列长度。CRF模型的评估得分如式(7)所示。

在训练过程的标记序列的似然函数如式(9)所示。
其中,YX为所有标记集合。最终,输出如式(10)所示的整体概率得分最大的一组序列。
4 实验及结果分析
4.1 实验语料准备
由于当前业界还没有公开的桥梁检测领域文本语料,本文搜集了我国多个省份的真实桥梁检测报告100余份,包含了梁桥、拱桥、斜拉桥和悬索桥结构形式。人工筛选出重点章节内容,并删除了其中表格和图片等信息,剩下文本共计12万余字。采用BIO标注策略对上述文本进行标注。以句子为单位,按8∶2的比例将语料划分为训练集与测试集,对应的标签信息如表2所示。实验语料中各类型实体总数及训练集、测试集数据统计情况如表3所示。

表2 实验语料中标签设置情况
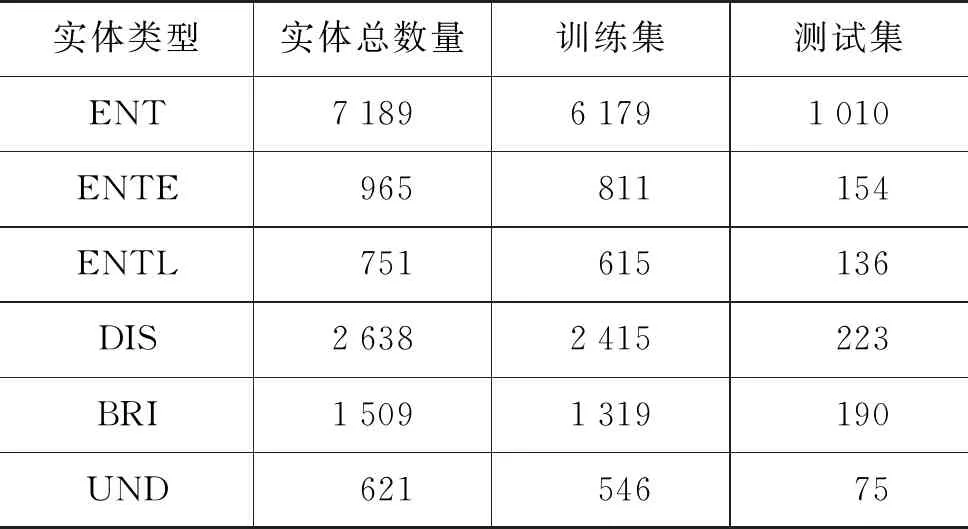
表3 实验语料中各类型实体信息统计
4.2 实验环境与参数设置
实验采用Python编程语言3.6.5版本,基于Tensorflow 1.12版本对本文方法和对比实验方法进行程序实现。实验程序部署于配置为6核AMD 3600 CPU、16 GB DDR 4内存、Nividia Geforce 2060 8 GB显卡、512 GB硬盘空间并安装Ubuntu 16.04操作系统的主机。
为验证本文Transformer-BiLSTM-CRF模型的识别效果,选取了当前本领域主流的CNN-CRF,BiLSTM-CRF与CNN-BiLSTM-CRF作为对比基准模型。为了对Transformer Encoder模块和 BiLSTM 模块在上下文长距离位置依赖和方向敏感性特征提取方面的有效性进行验证,选取了Trans-CRF模型进行对比分析。另外,使用Google开源的中文BERT预训练模型评估本文方法在有预训练模型条件下的识别性能。由于Lattice-LSTM-CRF模型引入了外部词典嵌入模型,因此,将其视为有预训练模型支撑进行对比分析。
在训练主要超参数方面,设置文本序列最大长度为100,Epoch迭代次数为100次,批次大小为128,学习率为0.001,Dropout率为0.1,Transformer中Encoder的Block数为6,Head数为8,字嵌入维度为512。
实验结果采用了命名实体识别领域常用的正确率(Precision,P)、召回率(Recall,R)和F1值作为评价指标,其中P为正确识别实体与识别结果总数的占比,R为正确识别实体与测试集实体总数占比,F1为P和R的调和平均值,体现模型的综合命名实体识别性能。
4.3 实验结果与分析
表4和表5分别描述了无预训练模型和BERT预训练模型两组实验条件下不同模型的综合对比结果。总体而言,本文模型在两组实验中的精确率、召回率和F1值三方面均优于其他对比实验模型,具有更佳的综合识别效果。

表4 无预训练模型条件下不同模型的对比实验结果 (单位:%)

表5 预训练模型条件下不同模型的对比实验结果 (单位:%)
在第一组无预训练模型实验条件下,所有对比模型均基于随机初始化的字向量。Trans-CRF模型的实验结果较差,F1指标仅有73.27%。其原因主要在于该模型仅使用了Transformer Encoder作为字符特征提取单元,位置编码和自注意力机制仅考虑了上下文的位置依赖相关性特征,对于字符级命名实体的前后顺序方向性特征提取能力不足,导致识别效果较差。类似地,CNN-CRF模型的F1值也仅有78.37%,综合识别效果也有待提升。
BiLSTM-CRF是当前基于深度神经网络的命名实体识别主流模型架构。由于BiLSTM能够从前后两个方向对文本序列字符特征进行学习,在第一组实验中,该模型测试F1值达到87.71%。与CNN-CRF模型相比,BiLSTM-CRF模型的正确率提升9.38%,召回率提升9.29%,F1值也提升9.34%。由于CNN模块的卷积操作能进一步提取字符的上下文局部特征,CNN-BiLSTM-CRF模型的正确率、召回率和F1值三个指标方面分别超过BiLSTM-CRF模型0.55%、2.91%和1.78%。
正如本文第2节所述,除了蕴含丰富的专业术语以外,桥梁检测领域命名实体还具有较强的字符多义性、位置相关性以及方向敏感性等特点,结合了Transformer Encoder和BiLSTM特征提取能力的本文方法能够同时捕获长距离和方向性特征,相较于CNN-BiLSTM-CRF模型,对比实验结果的正确率提升了1.02%,召回率提升了1.45%,F1值提升了1.24%,取得了在第一组实验测试集下的综合最优效果。
第二组实验采用BERT中文预训练模型将输入序列字符映射为字向量,并固定BERT模块参数,对下游对比模型进行参数微调。如表5所示的实验结果表明,BERT预训练模型的引入对所有实验对比模型的识别性能均有较大提升作用,第一组实验中效果较差的Trans-CRF模型识别F1值达到86.51%,相较于第一组实验结果提升了13.24%。CNN-CRF模型的F1值提升至88.89%。本文提出的Transformer-BiLSTM-CRF模型的识别正确率提升至95.79%,召回率提升至95.36%,F1值为95.57%,优于Lattice-LSTM-CRF模型F1值2.29%,仍然具有实验测试集下最优的综合识别效果。
为进一步分析各个模型对桥梁检测领域各类型命名实体在两组实验中的具体识别效果,统计了如表6和表7所示的实验对比结果F1值。

表6 无预训练模型条件下各类命名实体识别的实验F1值对比 (单位:%)

表7 预训练模型支持下各类命名实体识别的实验F1值对比 (单位:%)
如第2节所述,BRI实体通常以“桥”作为结束字,同时可能嵌套有地名或者具有缩写形式,并且BRI实体包含的字符数可能较大。例如,经统计,测试集中BRI实体最多包含11个中文字符,最少存在两个字符。由于Transformer能对整个句子进行特征提取,具有较好的长距离依赖关系表征能力,并通过进一步结合BiLSTM的双向上下文顺序特征提取能力,本文方法在两组实验中均有最佳的BRI实体识别F1值。
在本文定义的ENT实体为桥梁结构部件或者具体某一构件,是《公路桥梁技术状况评定标准》等行业规范中的检测信息记录基础,因此在训练集和测试集中的占比最大。本文方法对ENT实体的识别结果在两组实验中均优于对比模型,F1值分别达到92.03%和94.58%。
ENTE实体是组成桥梁构件的更细粒度元素,存在“左腹板”和“前墙”等嵌套有方位描述的实体,或者“后浇翼缘板”等特殊词汇,识别难度较大。因此,在第一组实验中,虽然本文方法取得了74.19%的最优F1值,但整体效果均偏低。在第二组实验的BERT预训练模型支撑下,ENTE实体的识别效果大幅度提升,达98.04%。
ENTL描述检测病害相对于ENT或者ENTE实体的具体发生位置,所包含的字符数较少,描述形式与通用领域相差不大。在第一组实验中,CNN-BiLSTM-CRF模型取得了最优的F1值,优于本文方法0.99%。第二组实验中,BiLSTM-CRF模型也优于本文方法0.97%。
DIS实体是结构病害的具体描述,具有较强专业特殊性,规范性较强,但可能存在人为书写习惯的差异性。例如,“破损露筋”可能被记录为“破损、露筋”,进而需要被识别为两个实体。两组实验中,本文方法都取得了最优的F1值。
UND实体对病害或结构构件进行否定描述,在第一组实验中Transformer-BiLSTM-CRF模型取得了91.16%的最佳F1值。由于UND实体的描述方式相对固定和常见,在BERT预训练模型支撑的第二组实验中,各对比模型的识别效果提升明显,BiLSTM-CRF和CNN-BiLSTM-CRF的F1值均达到97%以上,本文方法提升至98.46%。
为验证本文方法在通用领域命名实体识别任务中的泛化性,选择了MSRA语料并在无预训练模型条件下与上述主流模型进行了对比分析,其实验结果如表8所示。综合分析MSRA结果发现,本文提出的方法虽然具有最优的F1值,但相较于BiLSTM-CRF模型优势并不明显,并且BiLSTM- CRF有更好的识别正确率。其主要原因在于MSRA语料中各实体相对稀疏,输入文本中各个命名实体之间的方向敏感性特征占主导作用。
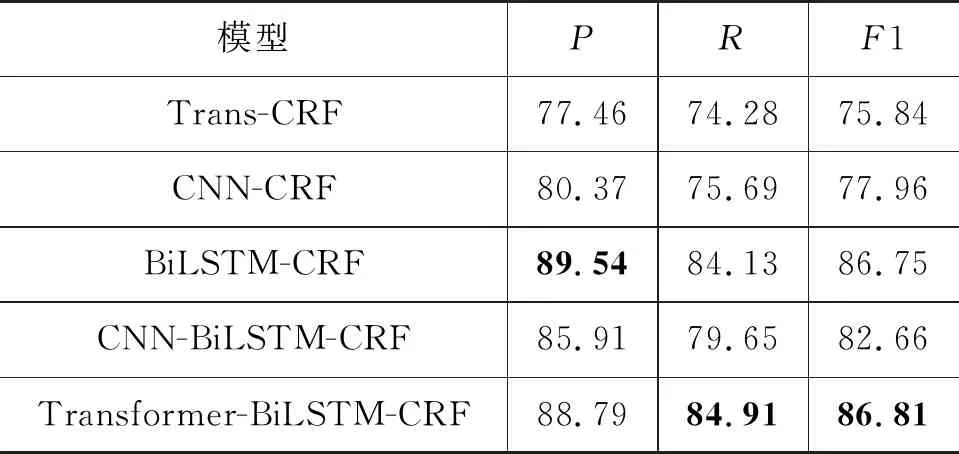
表8 MSRA语料下不同模型的对比实验结果 (单位:%)
综合分析实验结果,本文提出的Transformer- BiLSTM-CRF模型具有更好的综合识别性能,并且对于领域性较强的实体具有更明显优势。
5 总结与展望
作为当前我国公路桥梁管理养护业务体系中的重要数据源,桥梁检测文本蕴含了大量桥梁结构构件和检测病害等关键业务信息,对其开展以命名实体识别为基础的信息抽取方法研究是促进桥梁管理养护智能化发展的重要内容之一。
在上述的目标任务驱动下,针对我国桥梁检测文本领域特性,本文提出一种基于Transformer- BiLSTM-CRF模型的桥梁检测领域命名实体识别方法。该方法通过Transformer Encoder提取字符上下文长距离位置依赖性特征,并采用BiLSTM提取字符方向敏感性特征,最终使用CRF进行领域命名实体的序列标注。实验结果表明,该方法能有效识别桥梁名、结构构件、结构病害等领域实体,与现有方法相比,具有更好的正确率、召回率和F1值。与此同时,在大规模文本预训练模型的支撑下,本文方法能取得较大幅度识别性能提升。本文工作在面向桥梁检测领域特定任务的同时,也对其他具有相似特性的领域命名实体识别研究工作有一定借鉴作用。
由于本文以最小粒度实体为目标,尚未考虑该领域实体的嵌套性。因此,在未来的研究工作方面,更大规模语料库的构建,以及面向最外层实体和多层嵌套实体识别及其关系抽取方法研究是后续重要任务。与此同时,如果将该领域的先验知识与数据驱动方法相结合,在通用领域BERT预训练模型基础上构建融合领域知识语义的预训练模型,并结合Sehanobish等[21]提出的字符图像特征融合机制,进一步提升实体识别或关系抽取性能也是值得深入探究的研究内容。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
