
基于语谱图的江西境内赣方言自动分区研究
2021-05-27 06:14颜为之王明文但扬杰
中文信息学报 2021年4期
颜为之,王明文,徐 凡,但扬杰,罗 健
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
0 引言
汉语方言的变化与人类历史的变迁、社会活动有着密切的关系。某一地域的方言与其历史方言的关系纷繁复杂,有的是在其历史方言的基础上传承演变而来,有的是由于战争动乱、人类迁徙等原因消亡,有的语音已经发生明显变化却依旧保留历史特征[1]。其中,方言的分区是文化交互的内在关系的实质体现。现代语言学中主流的方言分区以语言因素为重要依据,在对方言语音、方言词汇以及方言语法进行充分的调查研究基础上,通过古今语音比较的方式,辅以社会历史背景方面的资料,并结合地理类型和行政区域等其他因素,根据各地方言中表现出来的语言特征对方言片区进行划分。语言的复杂性造成了方言分区在原则、依据和条件等方面的不统一,使得现代语言学家对方言片区的人工划分持有不同意见[2-6]。计算机自动分区通过采用自然科学方法,为方言的分区提供了客观的数据参照,对提高方言识别精度有着重要作用,对发掘方言文化的内涵关系具有进步意义。
赣方言(赣语)是中国汉语七大方言之一,为汉族江右民系使用的主要语言,使用范围主要在江西省境内,分布在赣江的中下游、抚河流域、鄱阳湖流域及其周边、湘东和闽西北、皖西南、鄂东南和湘西南等地区,使用人口约5 500万左右。目前,现代语言学家对江西省境内赣方言(以下简称赣方言)分区的主流方案都是采用人工划分方式[7-11],主要采用方言词汇和语法特点进行人工分区。在汉语方言与计量研究上,先后有学者发表了一些颇有影响的文章和专著[12-17],这些文献都从理论和实践两方面对计量研究在汉语方言关系研究中的地位、作用和意义作了探讨。近年来,部分学者开始在汉语方言的分区上尝试采用计量分析方法,通过聚类分析对现有方言的语音特征进行方言的分类或方言分区。而在如何利用计算机自动提取方言的语音特征,并对其进行聚类分析鲜有文献著作。
基于此,本文首先构建了江西省11个省辖市,91个下辖县级行政区的时长约1 500分钟的1 223条语音语料库。然后分别提取方言语音中梅尔频率倒谱系数(Mel-frequency cepstral coefficient,MFCC)特征以及语谱图两种不同的语音特征。针对语音特征提取的维度过大问题,在MFCC特征上采取了PCA(principle component analysis)降维处理,在语谱图特征上采用基于卷积神经网络(convolutional neural networks,CNN)系统的自编码降维处理。对降维后的语音特征分别采用k-均值算法聚类、高斯混合聚类和层次聚类对方言自动分区,并采用聚类性能度量指标评价聚类效果。实验结果表明,新型语谱图特征的聚类性能度量内部指标DBI以及DI指数显著优于传统MFCC特征,维度为16时语谱图和MFCC下拼接特征的聚类效果与传统人工方言分区较为接近。
本文组织结构安排如下:第1节介绍赣方言分区的相关工作;第2节介绍本文采集的赣方言语音语料库;第3节详细阐述本文使用的两种语音特征及聚类算法;第4节描述在不同算法下的实验结果和分析;第5节是结论及后续工作展望部分。
1 相关工作
本节对方言的人工分区方法、计量分区方法以及语音的特征提取进行简要介绍。
1.1 人工分区方法
针对江西省境内赣方言(以下简称赣方言)的分区,颜森将其划为5个片区,分别是昌靖片、宜萍片、吉莲片、鹰弋片和抚广片,分区标准既采取了语音标准,也采取了词汇标准[7]。李如龙将其划为3个片区,分别为赣东区、赣中区和赣北区,分区标准主要以词汇为标准,根据相同词汇的接近总数的多少来分区[8]。刘纶鑫将赣方言划为5个片区,分别是波阳片、宜春片、临川片、都昌片和奉新片,分区标准主要采取了综合标准,将语音、词汇和语法特点综合考虑[9]。孙宜志等人将其划为南北两大区,共7个小片区,北区包括都昌片、乐平片和奉新片,南区包括崇仁片、铅山片、泰和片和分宜片,分区标准主要采取了语音标准,也考虑了自然地理和行政区划的关系[10]。谢留文在前任学者基础上将赣方言划为9个片区,分别是昌靖片、宜浏片、吉茶片、抚广片、鹰弋片、大通片、耒资片、洞绥片和怀岳片,分区标准主要采取了语音标准划分[11]。这些研究运用了传统的语言学方法,通过田野调查收集语料。由于研究者采取的分区依据存在个体差异,导致赣方言片区划分不一致问题的出现。
1.2 计量分区方法
从20世纪70年代初开始,郑锦全、陆致极、陈海伦、王士元等语言学家将计量方法应用于汉语方言研究,讨论了方言关系的材料和计量单位问题,区分了方言的亲疏关系和亲缘关系,并在方言上进行了不同计量方法的实践和研究[12-17]。现代语言学家对赣方言分区的主流方案主要是根据方言词汇和语法特点,结合行政地理特征进行人工分区。近几年,已有部分学者开始尝试采用计量分析方法对汉语方言分区进行研究,例如,项梦冰的沂南方言分区[18]、王荣波等人的江淮官话洪巢片分区[19]等,主要采取聚类分析的方法对现有方言的语音特征进行方言的分类或方言分区。而在如何利用计算机自动提取方言的语音特征,并对其进行聚类分析鲜有文献。
1.3 语音特征提取方法
语言特征提取是从说话人语音信号中获得能够描述语音信号特征参数的过程,是语音识别过程中至关重要的一步。现有的特征提取方法包括线性预测编码提取(linear predictive coding,LPC)[20]、线性预测倒谱系数提取(linear predictive cepstral coefficient,LPCC)[21]以及梅尔频率倒谱系数提取(Mel frequency cepstral coefficents,MFCC)[22]等。
20世纪90年代初,潘凌云等人[23]就提出了使用语谱图进行语音实验,利用语谱图密度变化的形变函数,以及自适应阈值技术来定位每个音素段的边缘,实验所得结果与语音学家分割的结果进行比较,得到的识别率高于93%。近几年,语谱图特征的应用也较为广泛,如文献[24]提出将语谱图特征应用于语音情感识别,文献[25]将语谱图输入到有生物视觉依据的人工神经网络——脉冲耦合神经网络,得到输出图像的时间序列及其熵序列作为说话人语音的特征,利用其不变性实现说话人识别等。
2 赣方言语音语料库
本节主要介绍赣方言语音语料库的采集工作。
2.1 语料库设计
如何选取录音文本语料,是语料库建库工作的关键。为了保证语料库的质量,体现方言语料的特点,在语料库构建之前,本文按照以下原则选取了语料库的文本语料:①语料库中的单字、词尽量涵盖声韵现象,以便更好地反映该方言语音的音系特征;②语料库中的词汇以汉语调查常用表为基础,选取了具备客赣方言特色的口语语料,以便更加符合语音识别面对的真实情形;③语料库中的句子在内容和语义上尽量保证完整,能够尽可能地反映一个句子的韵律信息;④要求发音人在自然状态下说方言,从而反映语音特征[26-31]。本文依据此原则,参照国际上语音语料库的设计标准,结合汉语方言之间的差异性,选取了江西省11个省辖市、91个下辖县级行政区进行录音采样(图1)。

图1 方言点采样
在确定方言点之后录制语料。说话人选择的是生活或居住在方言采集点10年以上的高校新生,包含学生姓名、性别、出生年月、出生地、现居住地、方言区生活时间和录音时长。该方言语音语料库将语音中的性别、年龄、地域等信息用于语音识别和方言特征识别等研究。例如,姓名:某某某;性别:女;出生年份:2000年;民族:汉族;出生地:九江市星子县南康镇迎春桥;现居住地:九江市星子县南康镇黄泥岭;在方言区居住年数:18年;方言所在地经纬度:东经116.051 7,北纬29.462 04;录音1时长:37s;录音2时长:34s。
方言语料采集参与人数共740人,其中男性186人,占比25.1%;女性554人,占比74.9%。17至20岁学生人数为537人,占72.6%;录制语音1 223条,时长约1 500分钟;录音人最大年纪91岁,最小年纪16岁;方言居住地居住最长84年,最短10年;方言点南昌地区录音人数78人,九江地区64人,上饶地区62人,抚州地区38人,宜春地区111人,吉安地区134人,赣州地区158人,景德镇地区29人,萍乡地区31人,新余地区16人,鹰潭地区29人。地域分布基本符合方言分区的均匀采样原则。最终,用于实验的下辖县级行政区个数76个,用于特征提取的有效录音936条。
3 赣方言语音特征提取及自动分区
本节主要描述语谱图的特征提取及基于CNN的自编码器降维、MFCC特征的提取和PCA降维以及所采用的聚类算法。
3.1 语谱图及基于CNN的自编码器降维描述
首先提取每一条语音文件的音频参数,例如,声道数(nchannels:1)、量化位数(sampwidth:2)、采样频率(framerate:16 000)、采样点数(nframes:不同长度语音采样点数不同,大概范围为300 000~910 000)。将这些得到的语音参数(字符串类型)转化为整型参数并且进行归一化处理,可以得到语音的帧长和帧叠点数等参数。最后将这些参数作为输入得到对应语音的语谱图。
为了对语谱图特征进行降维,本文构造了基于卷积神经网络的自编码降维系统。自编码器(autoencoder)是一种利用反向传播算法使得输出值等于输入值的神经网络,它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。本文使用自编码器提取语谱图的瓶颈特征,输入是原始语谱图,输出是生成的语谱图。自编码器由编码器和解码器组成,编码器将语谱图压缩成瓶颈特征,解码器将瓶颈特征还原成语谱图。
本文所使用的CNN网络结构包括输入层(input layer)、卷积层(conv layer)、编码层(encoder layer)、解码层(decoder layer)、最大池化层(max pool)、和输出层(output layer)。语谱图自编码器的结构如图2所示。
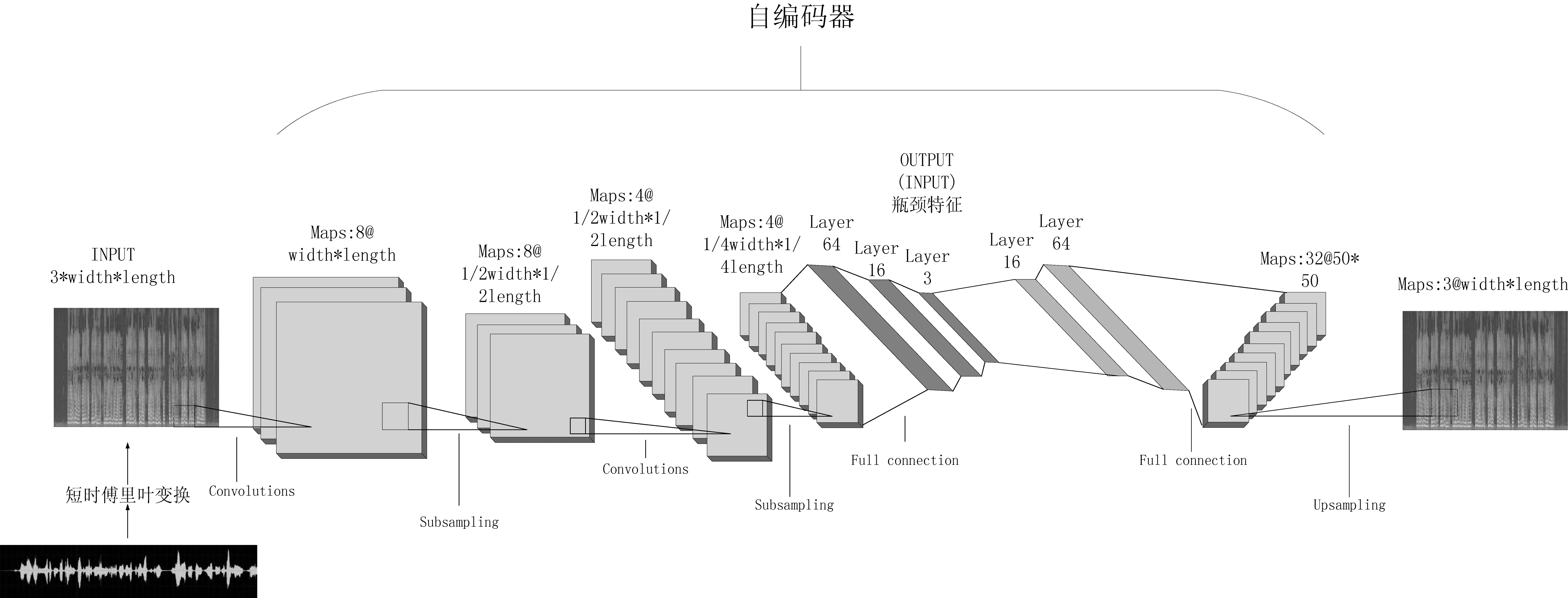
图2 语谱图自编码器的结构
从图2可以看出,输入层输入的是由语音文件产生的对应语谱图,输出层最后输出每一个语谱图对应的编码层和解码层计算后的特征向量。编码器由两层卷积层、两层最大池化层和3层全连接层组成,两层卷积层的卷积核大小为3×3和2×2,步长为(1,1)、(2,2)。其中第一层卷积核数量为8,第二层卷积核数量为4。两层最大池化层的卷积核大小均为2×2,步长均为2。卷积层不改变图像的大小,最大池化层将图像长、宽减半。三层全连接层分别将数据降维到64维、16维和3维,其中3维是瓶颈特征的大小。解码器由三层全连接层和一层反卷积层组成,三层全连接层分别将3维的瓶颈特征升维到16、64,解码器第二层池化后的维度(记此特征为Linear_3),再经过一层反卷积将Linear_3还原至语谱图。本文使用L1计算输入语谱图与生成语谱图之间的损失。通过Adam算法更新模型参数,同时学习率设置为0.001。
3.2 MFCC特征及PCA降维描述
本文将每一个语音信号首先分帧处理,将信号帧化为15 ms/帧,帧移为10 ms,对每帧进行快速离散傅里叶变换(fast Fourier transformation,FFT),从时域数据转变为频域数据能量分布来观察。对FFT的数据计算谱线的能量,得到向量特征,在梅尔域内能量谱经三角带通滤波器后得到26个对数滤波器组能量。最后,采用26个对数滤波输出经过离散余弦变换(discrete cosine transform,DCT),得到每帧语音的13维的MFCC特征向量。其中,1s的语音按照帧移为10ms来计算,可以切分出100帧,每帧的特征向量是13维,即长度为1s的语音得到的特征向量长度为1 300维。如此高维的特征向量对于聚类来说计算量巨大。因此,本文使用PCA方法对MFCC的高维特征进行降维处理(图3)。主成分分析PCA也称主分量分析,它是一种将原有的多个变量通过线性变换转化为少数几个新的综合变量的统计分析方法。这些新变量互不相关,即能有效地表示原变量的信息,也在降维之后依然能够最大化保持数据的内在信息。MFCC特征在经过PCA处理后,既减少了后续聚类分析工作的运算量,又降低了数据的存储量,同时还对语音的特征参数进行了最优化。

图3 MFCC特征提取及PCA处理过程
3.3 聚类分析
聚类是将没有分类的标签数据集分为若干个簇的过程,是一种无监督的机器学习方法。聚类分析的过程则是将聚类对象的数据集进行特征的选择或变换,再通过聚类算法得出结果进行评价。综上所述,本文将采集到的赣方言语音语料进行预处理,提取每条语音的MFCC特征和语谱图特征,作为聚类分析的特征,并对特征进行降维处理。由于特征的选择并不会改变其原有属性,所以结果只是一个原始属性的优化特征子集,保留了原属性的物理意义。聚类簇的选择依靠聚类结束准则函数,所以,这种准则函数一般由人为设定的终止条件实现。本文在传统语言学家对赣方言分类的基准上,人工将聚类簇定为3、5、7、9类,并分别采用传统的k-means聚类,语言特征常用的层次聚类和语音识别常用的GMM聚类方法进行比较。
4 实验结果及分析
本节描述性能评价指标,不同语音特征下的聚类结果及对比分析。
4.1 性能评价指标
本文使用聚类性能度量内部指标来评价不同聚类方法的效果。常用的内部指标有DB指数(Davies-Bouldin Index,DBI)和Dunn指数(Dunn Index,DI),如式(1)、式(2)所示。
① DBI

(1)
② DI
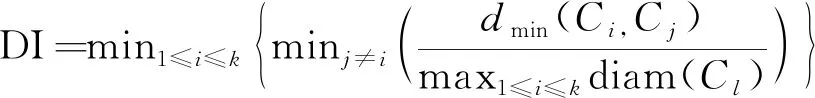
(2)
上述公式中,avg(Ci,Cj)表示某一聚类簇内部样本点距离的均值;diam(Ci,Cj)表示聚类簇Ci,Cj中样本间的最大距离;dmin(Ci,Cj)表示聚类簇Ci与Cj间的最小样本距离;dcen(μi,μj)对应于簇μi与μj中心点之间的距离。对每一个方言类别,计算与其他方言类的最大相似度值,也就是取出最差结果,然后对所有类的最大相似度取均值就得到了DBI指数。其中,DBI的值越小说明类内距离越小,同时类间距离越大,而 DI则相反。
4.2 实验结果分析
本文依据上述工作,在收集的936条赣方言语音中按照每个下辖县级行政区(76个下辖县)对应一条录音的原则,随机抽取76条语音进行实验。表1及表2列出语谱图和MFCC特征下的三种聚类方法的评价指标的四种结果(字体加粗数据为更优数据)。实验结果表明,3分类上,MFCC特征的DBI数据要优于语谱图特征;5分类上,MFCC特征的层次聚类效果优于语谱图特征的层次聚类效果。总体而言,语谱图特征下的聚类效果要优于MFCC特征的聚类效果。

表1 语谱图特征在不同聚类下比较
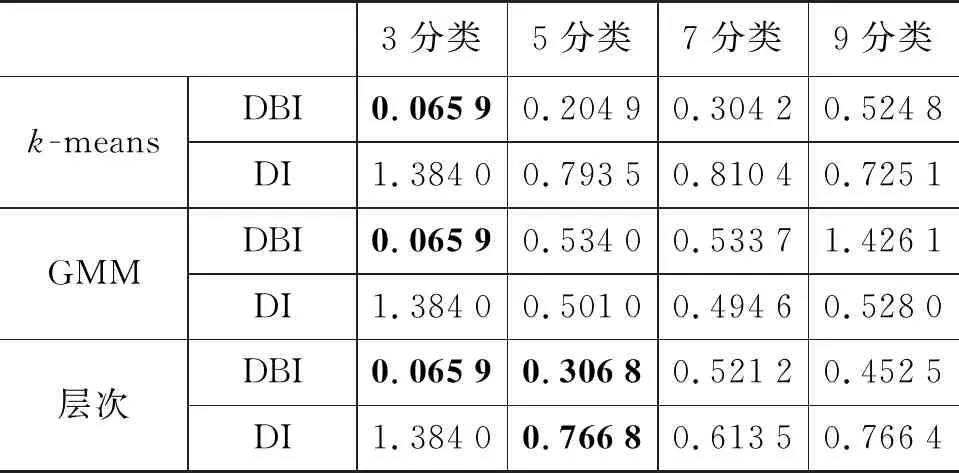
表2 MFCC特征在不同聚类下比较
一条方言语音不仅反映了方言的音位系统、声韵调系统、音节系统,还包含不同地域的有连续音变的多音词的变调、变声、变韵的规律。通过实验,MFCC下能发现语音特征中频率的出现,却无法得知该频率出现的时间点。而语谱图特征中则蕴含了大量的与语音的语句特性有关的信息,它综合了频谱图和时域波形的特点,明显地显示出语音频谱随时间的变化情况,对方言而言是一种很好的区分性特征。
4.3 实验对比
本文将MFCC特征与语谱图特征进行拼接,得出方言自动分区的数据,并与语言学家的方言分区进行对比。其中,MFCC主要关注声学底层特征方面,而语谱图主要考虑语音信号的能量(幅度谱)方面,拼接权重可以考察实验数据的分类性能,如式(3)所示。
其中,Vmfcc是mfcc特征的向量,Vyupu是语谱图特征的向量,λ是权重。V是二者加权后最终的向量。实验结果表明,在16维的语谱图权重为0.2和MFCC权重为0.8下层次聚类的拼接效果和语言学家分区最为接近。
本文以颜森[7]的方言分区为例进行分析。5分类结果如表3所示,颜森的昌靖片和宜萍片在计算机的5分类中均匀分布;吉莲片在1、3、5类中较为集中;抚广片和鹰弋片在3、4、5类中较为集中。

表3 16维下语谱图权重为0.2和MFCC权重为0.8层次聚类的拼接效果
颜森[7]将南昌市等14个市县划入昌靖片,并总结出该片区共同的两个音系特点和若干特例。而本文将两种语音特征进行拼接,不同权重得出不同的聚类效果,如语谱图特征权重为0.9的特征拼接下,新建、安义、德安、都昌以及湖口语音特征聚在一类;语谱图特征权重为1的特征拼接下,修水、武宁、都昌和德安语音特征聚在一类。从江西地势上而言,武宁、修水、奉新等地有九岭山脉穿过,都昌、德安、永修等地绕鄱阳湖水域,南昌、新建、安义等地属于省会城市区域范围。
本文又以萍乡市为例进行分析,萍乡地处江西省和湖南省的边界地区,其内部方言片分区传统语言学家就有不同的意见。对萍乡话的集中分区的代表有:颜森将萍乡话分在宜萍片。对萍乡话内部离散的分区代表有:陈昌仪[32]将萍乡话分在宜春片,将莲花话分在吉安片;孙宜志等人[10]将萍乡话分别分在北区的奉新片和南区的泰和片、宜春片;谢留文[11]将萍乡市内的萍乡话、上栗话和芦溪话分在宜浏片区,莲花话分在吉茶片区。萍乡属江西省下辖设区的地级市,下辖莲花、上栗、芦溪三县和安源、湘东两区。本文将语音特征提取距离和传统的语言学家的方言分区的聚散做可行性分析比较。以语音特征距离为坐标,计算机既能在语谱图特征下将萍乡地区的三县两区语音聚合(如图4实心标示所示),也能在MFCC特征下将三个县两区分散(如图4空心标示所示)。
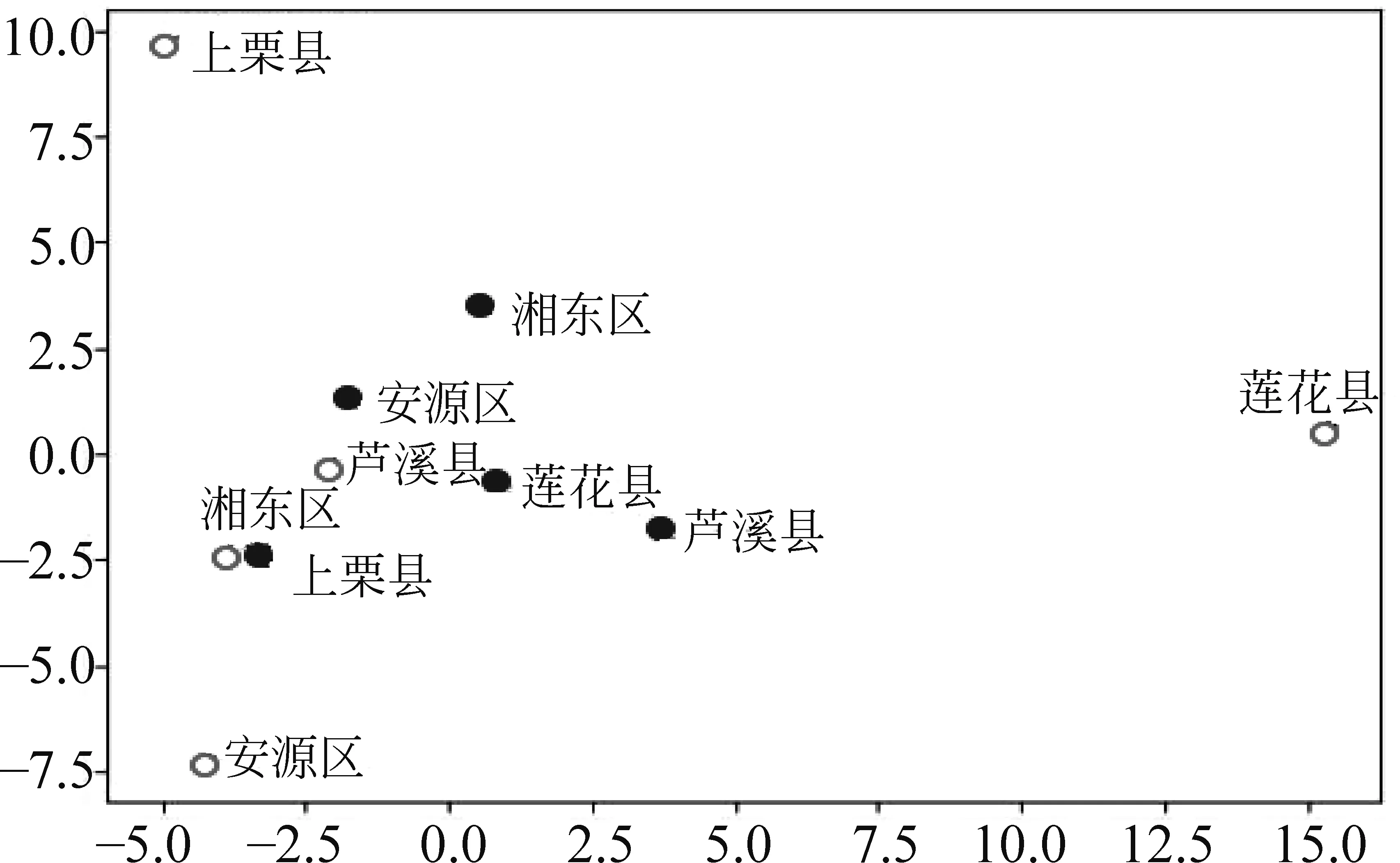
图4 萍乡方言在MFCC特征(空心)和语谱图特征(实心)下的聚类效果
受水系、山脉等地理因素影响,传统的方言调查方法受到极大的限制,如颜森[7]将同属于鄱阳湖边的湖口、彭泽、鄱阳三县划分在不同的分区。而计算机的自动分区更关注语音本身特征的划分,如本文实验的自动分区所示,湖口、彭泽、鄱阳三县都在同一个类别中,体现出语音的地理信息特征。因此,对比人工分区而言,计算机的自动分区可以在语音特征的基础上加入地理信息、行政区域等特征,填补传统语言学研究方法上的不足,为具有争议的方言分区提供一定的参考。
5 总结
采用计算机对汉语方言进行自动分区对语言学研究有着重要的印证作用。在语言工程领域,方言识别能够为带口音的语音识别、说话人识别等方面的研究打下良好基础[33-34]。在信息查询和检索服务领域,方言的语音识别可以作为一个前端处理,预先区分用户的方言类别,以便于接受不同方言的语音服务。
本文构建了江西省范围内的赣方言语音语料库,在传统的语音特征提取基础上,设计了基于语谱图的深度学习模型提取特征。最后,通过聚类性能度量内部指标评价了不同聚类方法上的聚类效果。实验结果表明了语谱图特征的有效性,维度为16时语谱图特征下的聚类效果和传统人工方言分区较为接近。后续的工作中,还将扩大现有语料,并研究其他类型的学习模型对赣方言语音特征提取的作用,提高方言自动分区精度。
猜你喜欢
东方少年(2022年28期)2022-11-23
环球时报(2022-03-29)2022-03-29
今日农业(2021年15期)2021-11-26
天津外国语大学学报(2020年1期)2020-03-25
新世纪智能(高一语文)(2019年11期)2020-01-13
新世纪智能(高一语文)(2019年11期)2020-01-13
知识经济·中国直销(2018年7期)2018-07-27
语言与翻译(2015年4期)2015-07-18
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
