
基于深度图像增益的RGB-D显著性物体检测
2021-05-27 06:51:34魏计鹏秦国峰
计算机与现代化 2021年5期
魏计鹏,秦国峰
(青岛大学计算机科学技术学院,山东 青岛 266000)
0 引 言
当人类进入到一个陌生的场景中会更加关注突出的物体,以获得物体的更多细节信息,显著性物体检测旨在自动识别出图像中最具有吸引人类注意力的区域。显著性物体检测可作为其他计算机视觉应用的预处理步骤,如目标检测[1]、视频分析[2]、物体定位[3]和图像质量评估[4]。早期的显著性物体检测采用传统的方法[5],存在空洞、假阳性概率高、适应面窄、鲁棒性差和运算效率低等问题。随着近几年卷积神经网络在其他视觉任务中的应用,深度学习的方法越来越受到了人们的青睐,RGB-D显著性物体检测得到了快速发展。基于深度学习的方法可以很好地克服传统方法中存在的问题,并且在面对当前日益增长的数据量也表现出了较高的处理效率,能够帮助人们从海量的图像数据中快速获得最重要的信息。
基于深度学习的RGB-D显著性物体检测方法根据融合方式主要分为3种,分别是RGB信息和深度信息的早期融合方案、中期融合方案和后期融合方案。早期融合将RGB图片和深度图片组合成多通道共同输入到网络中[6]。中期融合把不同网络提取的RGB特征和深度特征通过集成方案进行融合,中期融合是目前广泛采用的一种融合方式。例如PDNet[7]直接将深度分支的最深层特征和RGB分支的深层特征简单叠加并馈入到反卷积网络,以恢复到输入图像相同的分辨率。后期融合将来自RGB分支预测结果和深度分支的预测结果通过特定方式融合,输出最终的显著图。例如AFNet[8]采用双分支的网络结构分别获得RGB显著图和深度显著图,并使用一个开关图指导双分支显著图的自适应融合。上述几种方法虽然表现出了较好的性能,但没有考虑到深度信息作为辅助信息对显著性物体检测的贡献的多少,在面对稍复杂的场景时,尤其是在RGB信息中前景物体和背景区分度较小,往往检测结果会出现空洞或检测不全的情况。因此,在双分支网络结构的基础上,本文提出利用深度图像增益提高检测性能的方法,通过学习深度信息为检测带来的增益,将预测的增益和双分支的特征进行融合,得到更加突出的显著性物体,达到预期的检测性能。
1 本文提出的网络结构
本文提出的网络结构如图1所示,主要分为2个阶段。预训练阶段,首先通过2种显著图作差的方式计算出深度图片的增益信息,即伪GT,并使用增益子网学习深度图片带来的增益。微调阶段,RGB分支和深度分支使用相似的网络结构,将学习深度信息增益的增益子网并入到整个网络中。
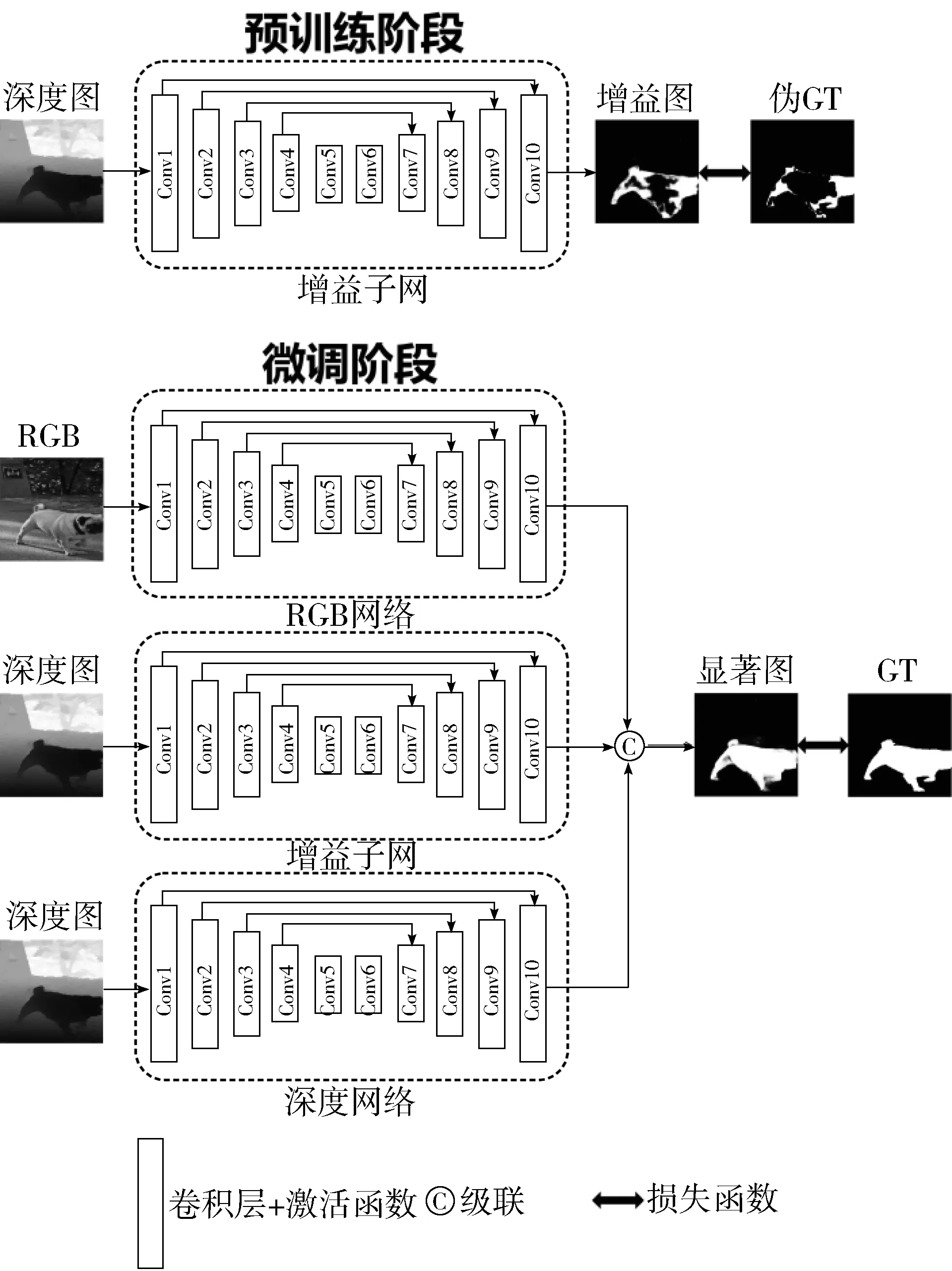
图1 本文的网络结构图
RGB网络、深度网络和增益子网结构相似,都以VGG19网络为基础,采用编码加解码的框架。同时为了充分利用每一层特征,将编码阶段的每一卷积块的最后一层特征与解码阶段的上采样特征通过级联的方式融合。较深层的特征可以准确定位显著物体的空间位置,浅层特征可以提取显著物体更多的细节信息,抓取图像的一些简单特征,通过由深到浅不断级联的方式逐步细化显著物体的细节信息。
1.1 预训练阶段
预训练阶段采用现有的RGB-D显著性物体检测方法PDNet[9]和2种不同的训练数据集(RGB图+深度图,RGB图+全黑图(像素点值全为0))。训练数据1(RGB图+深度图)输入到PDNet[9]中得到RGB-D显著图,训练数据2(RGB图+全黑图)输入到PDNet[9]中得到RGB-RD显著图。通过RGB-D显著图和RGB-RD显著图作差的方式显式地表示深度图带来的增益。因为RGB-D显著图是RGB信息和深度信息两者共同作用的结果,而得到RGB-RD显著图的过程是用一张全黑图代替原来的深度图,深度信息被最小化,所以最终得到的显著图几乎是RGB信息作用的结果而不包含深度信息的贡献。通过2种显著图之间像素点作差可以表示深度图为检测带来的增益,伪GT的计算如公式(1)所示:
GT=zero(RGB-D⊙RGB-RD)⊙GT
(1)
其中,GT∈{0,1}表示手工标注的二进制显著图真实值;⊙表示逐元素的Hadamard乘积;zero( )表示将作差后的负值置0操作。
1.2 微调阶段
如图1所示,在微调阶段整个网络结构由3个小的网络组成,分别为RGB网络、增益子网络和深度网络。
级联的具体细节如图2所示,3个卷积块从左到右分别表示RGB网络最后一层卷积、增益子网的最后一层卷积和深度网络的最后一层卷积。这3个卷积层输出的特征维度大小为224×224×64,所以级联后的特征维度变成了224×224×192。
具体来说,3个网络分别提取得到RGB特征、深度增益特征和深度特征,如果只是简单地将RGB特征和深度特征进行融合,特征在融合过程中缺乏指导依据,网络无法评估哪些区域信息更重要,融合效果往往也不尽如人意。在引入深度增益网络后,深度增益特征可以在RGB特征和深度特征融合的过程中明确哪些区域是显著前景,哪些区域深度信息对检测精度的贡献更多,指引网络更加关注显著物体区域,如果深度信息贡献更多融合时更加偏向深度特征。相比于RGB特征和深度特征简单的融合,这种融合方式更加合理,融合后的结果前景物体更加突出,减少显著物体检测不完全和空洞情况的出现。
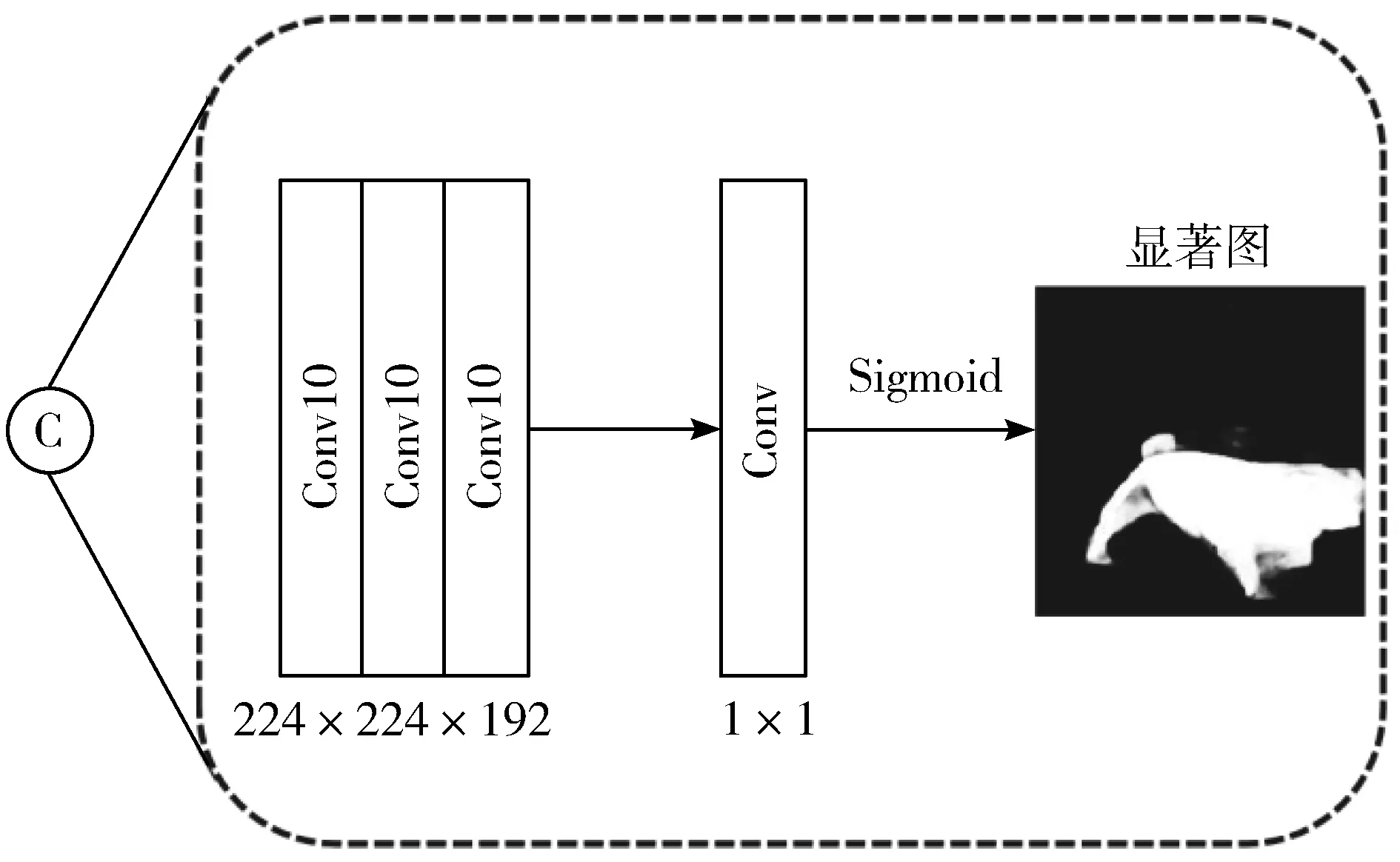
图2 级联细节图
1.3 最终结果
级联后的特征再经过一层1×1的卷积并使用Sigmoid函数[10]归一化后得到最终的显著图。使用交叉熵损失函数,可以计算为:
Loss=YlogP+(1-Y)log(1-P)
(2)
其中,P表示预测的显著图,Y表示手工标注的二进制显著图真实值。
2 实验及分析
2.1 数据库
为了公平比较,本文在5个公开可获得的基准数据集上进行训练和测试,并对其测试结果进行评价分析。5个数据集分别为NJDU2K[11]、STERE[12]、DES135[13]、NLPR[14]、LFSD[15]。NJDU2K数据集包含1985对RGB-D图片和标注良好的人工标注图。NLPR数据集由Kinect拍摄的1000张室内外不同的场景图片组成。STERE数据集包含1000张立体图片,其深度图质量稍差,该数据集全部用于测试。EDS135数据集包含135张室内物体的图片,该数据集全部用于测试。LFSD数据集有100张RGB-D图片,该数据集全部用于测试。
2.2 实验细节
为了与现有的方法进行比较,本文使用与大多数方法相同的训练和测试划分方案。训练集包含2050张训练图片,分别是从NJDU2K数据集中随机划分的1400张图片和从NLPR采样的650张图片。为了提高训练精度,采用水平翻转的方法进行数据增强,增强后的训练集总共有4100张图片。训练前将图片大小统一调整为224×224并且采用VGG[16]预训练模型初始化网络参数。训练时使用Adam优化器[17]对网络进行优化,其超参数设置为默认值,初始学习率lr=1e-3,权重衰减=0.0005。批量大小为4,网络训练80个周期,训练的时长大约为12 h。在测试阶段,输出一张显著性图片大概耗时0.08 s。网络在公共框架Python3.6、Tensorflow1.4[18]的环境下搭建。实验使用一台工作站进行,该工作站配有Intel(R) Xeon(R) CPU,Nvidia GTX1080 Ti GPU和64 GB RAM。
2.3 评价指标
本文使用3个常用的标准评价指标在上述5个公开数据集上进行定量评估,3个指标分别为S-measure、F-measure和平均绝对误差(MAE)。
S-measure[19]是一种近期提出的新的结构相似性测量方法,定义为:
S=γSo+(1-γ)Sr
(3)
其中,So和Sr分别表示区域感知和对象感知的结构相似性,γ是默认参数,遵从于论文中的大小,设置为0.5。
F-measure评价指标同时考虑精度和召回率,其定义如下:
(4)
其中,Precision表示预测的显著性图片中为显著性像素的比率,Recall表示人工标记图片中为显著像素的比率。参数β2参考论文中的大小设置为0.3,用于加权Precission。本文只比较了在每个数据集上的MaxF和adpF。
MAE用于表示预测的显著性图和人工标记图之间的平均差值,定义如下:
(5)
其中,P和Y分别表示预测的显著性图和人工标记图;H和W分别表示显著性图的高和宽;(r,c)表示像素坐标,MAE取平均值。
2.4 消融性研究
本节通过在5个公开的数据集上的实验对比验证所提出的深度增益组件的作用。为了验证本文所提出的深度增益模块的有效性,将删除增益子网的结果和本文方法的结果进行比较,定量结果可以在表1中找到。显而易见,当删除增益子网后,双分支网络缺少指导双流特征融合的依据,最终结果稍差,该结果表明了本文提出的增益子网的有效性。
图3展示了无增益子网的结果和本文方法结果的定性比较。为了更好地验证增益子网的作用,图3特意地展示了增益图。从前3列可以看出,增益图作为增加的补充信息会弥补一些显著物体中存在的空洞和物体检测不完整的地方。后2列增益信息准确定位到显著性物体的空间位置,使网络在融合特征时更加专注显著前景,相比无增益的方法减少了假阳性情况的出现。
2.5 性能比较及分析
在上述5个公开的数据集上将本文所提出的方法和9种RGB-D检测方法进行比较,9种检测方法包括传统方法和基于卷积神经网络的深度学习方法。比较的模型包括LBE[20]、DCMC[21]、MDSF[22]、DF[6]、CDB[23]、CTMF[24]、PCF[25]、TANet[26]和CPFP[27]。
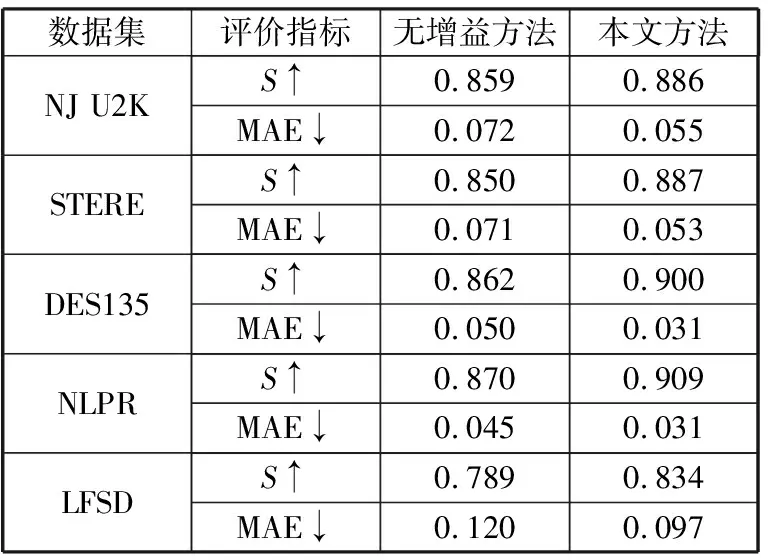
表1 2种模型的消融性比较

图3 消融实验中增益子网定性比较
表2详细展示了定量比较的结果,为了直观起见,表中排名最好的指标被加粗。从表2可以看出,本文方法的性能在5个公开的数据集上虽然个别指标没有达到最优,但始终处于前3的领先位置。
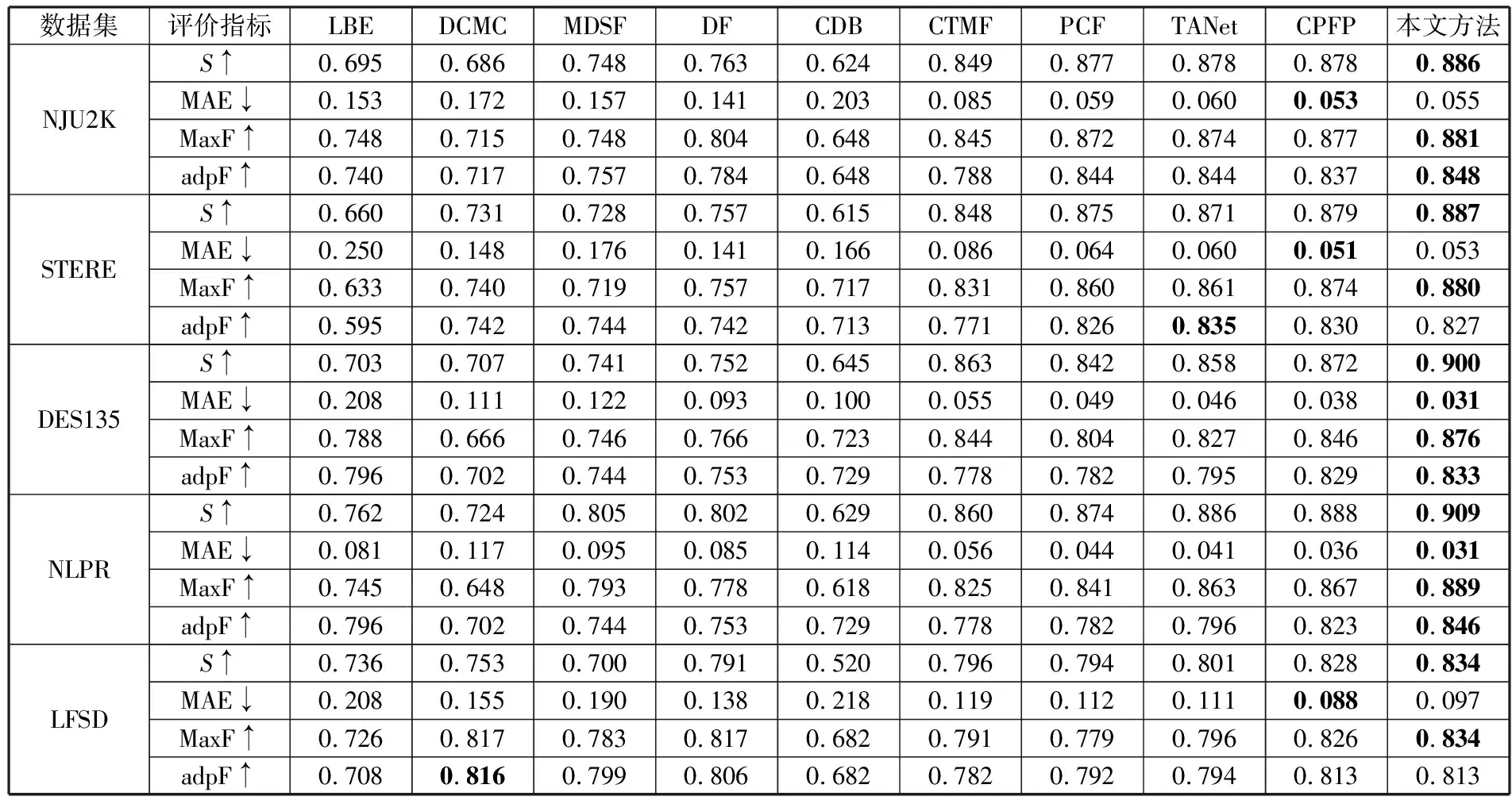
表2 本文方法与9个模型在5个数据集上的比较结果

图4 与其他方法的定性比较
图4展示了和其他方法的定性比较。在可视化结果比较中列举了几种具有挑战的场景,即多个物体、复杂场景、RGB图片低对比度。
如图4所示,在第一行和第二行中展示了多个显著性物体的场景,本文方法表现了较好的检测能力,而其他方法存在检测不完整或错误地将背景误检测为显著性物体的情况。第三行和第四行展示了复杂场景的情况。复杂场景中模型容易受到其他物体的影响,其他方法很容易出现把背景误检测为显著性物体的情况,但是本文方法表现很好。此外,还采样了一些RGB图片低对比度的情况,第五行和第六行,由于显著性物体前景和背景色差不明显,这给检测带来了一定的难度。此时,可以通过深度信息和预测的深度增益信息辅助检测。其中预测的深度增益信息可以很好地帮模型定位显著性物体的空间位置和一些细节信息,从而达到更好的性能。通过上面的几种情况验证了使用深度增益信息的合理性。当然也存在一些失败的案例,在未来的工作中还有改进的空间。
3 结束语
本文提出了深度图像增益的显著性物体检测方法,通过2种不同的训练数据得到深度信息增益,并预先学习增益信息,在RGB和深度双流特征融合的过程中引入深度增益信息,深度增益信息作为补充信息,能够更好地实现特征融合,指导模型更关注显著性物体,进而得到性能更好的显著性检测模型。通过实验结果对比可以看出,本文方法在多个公开的数据集上,更符合人类视觉主观关注的显著性物体。与其他显著性物体检测方法相比,本文提出的方法在多个评价指标上处于领先地位,但在个别的场景中会出现空洞、假阳性等问题,将来的工作需要对模型进行优化,争取让模型的检测性能进一步提高。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
电子制作(2019年19期)2019-11-23 08:41:36
电子制作(2019年24期)2019-02-23 13:22:26
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
电子制作(2018年19期)2018-11-14 02:37:02
西南交通大学学报(2018年5期)2018-11-08 10:58:04
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20 15:25:20
知识产权(2016年8期)2016-12-01 07:01:32
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
