
机器学习分类算法在社区问答系统中的应用
2021-05-24 08:29孙熙然
电脑知识与技术 2021年12期
孙熙然
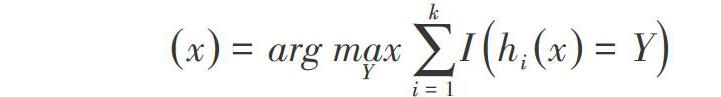

摘要:机器学习被广泛应用到自然语言处理中,社区问答提供了新的有趣的研究方向。在传统问答领域,通过分类算法研究用户交互行为并分析其交互方式,能够促进用户交互与相关岗位结构的开发。在此背景下,针对SemEval语义测评大赛提供的语料库进行了研究,基于KNN算法、随机森林等分类方法对问题的答案进行分类,并对分类结果进行分析和研究。实验结果表明,GBRT和随机森林这两种算法的分类效果最好。
关键词: 答案分类; 自然语言处理; 机器学习; 随机森林;最邻近节点算法
中图分类号:TP39 文献标识码:A
文章编号:1009-3044(2021)12-0195-03
Abstract:Machine learning is widely used in natural language processing, and community question answering provides a new and interesting research direction. In the field of traditional Question Answering(QA),it can promote the development of user interaction and related post structure by studying user interaction behavior and analyzing its interaction mode through classification algorithm. In this context, this paper studies the corpus provided by SemEval semantic evaluation contest, classifies the answers based on KNN algorithm, random forest and other classification methods, and analyzes and studies the classification results. Experimental results show that GBRT and random forest algorithm are the best.
Key words:answer classification; natural language processing; machine learning; nearest neighbor node algorithm; nearest neighbor node algorithm
1引言
现如今许多社会活动都是通过互联网进行,国内以知乎、BBS论坛、豆瓣社区等为主,人们通过发帖、回帖,以问答的形式交流。无论国内还是国外,人们通过社区问答(CQA)的形式在论坛和社交网络上进行互动,在此上下文中的用户交互是相当开放的,因此有很少的限制,每个用户都可以发布帖子提问,同时也可以回答一个或多个问题。从好的方面来说,这意味着一个人可以自由地提问问题并且期待能得到一些好的、有用的答案。但在消极的方面上,提问者需要浏览所有相关的答案,并且需要进一步判断这些答案的意义,即答案是否对解决问题有益。通常情况下,许多答案只是松散地与实际问题有关,有的时候甚至改变了话题的方向。一般来说,一个常见的问题可能有上百个答案,其中绝大多数的答案并不能满足用户的信息需求。因此,在一长串答案中找到所需的信息是非常耗时的。分类问题及其算法是机器学习的一个重要分支,Cover和Hart在1967年提出了基于距离度量的KNN分类算法[1],在此之后,Breiman 等率先完成对于初期决策树(DT)分类算法的阐释,此即CART 算法,其特点在于借助树结构算法这一形式,完成对于数据的拆分形成离散类[2],进入21世纪后在前人的研究上Breiman提出了随机森林(RF)分类算法[3],本论文针对社区问答系统的研究主要基于随机森林分类算法展开。
本次研究基于SemEval给出的语料库,针对社区问答系统中给定的带有短标题和扩展描述的问题,对其每一个答案按如下分类:好(good),代表肯定有关;可能(potential),表示可能有用;另外其他情况分类为坏(bad),例如答案与问题无关,问题与答案为一组对话,语言为非英语等。
2机器学习分类算法及随机森林算法
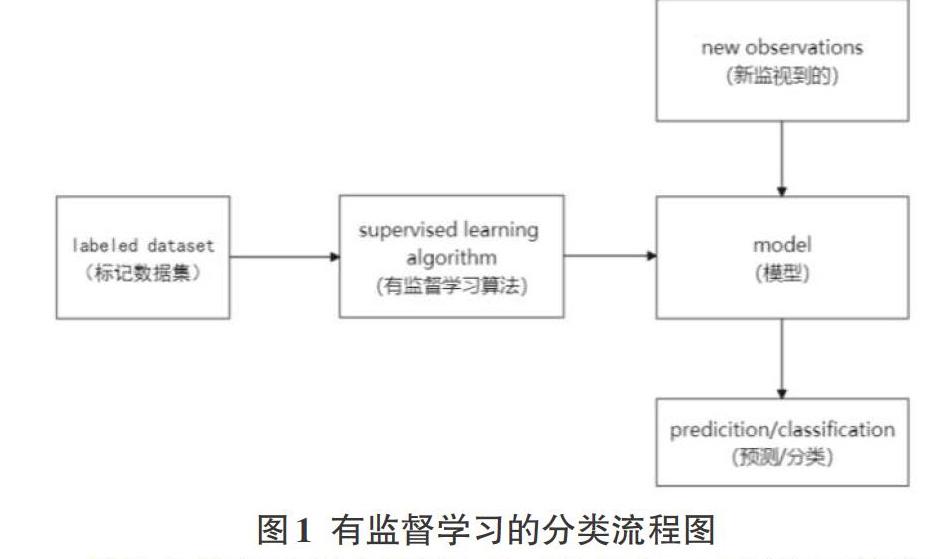
机器学习能够借助计算机这一媒介,基于网络存在的海量数据中研究以及学习数据出现规律以及存在方式,进而提前判定以及推测潜在信息,最终实现分类、回归以及聚类等相关问题的有效解决。当前最常见的机器学习方式分为监督、半监督以及无监督三类[4]。监督学习问题,数据输入对象往往提前配置分配标签,借助大量数据进行训练得出模型,随后借助模型完成后续推测。若输出变量具备连续性时,即回归问题,若其呈现离散状态,即分类问题。无监督学习问题特点在于不会配置标签,其重点在于研究数据可能存在的隐藏结构,以此为基础判定有无可区分组以及集群。半监督学习基于二者间,借助适量标记数据以及海量未标记数据进行训练和分类,虽然与标记数据相比未标记数据更容易获得,但是少数标记样本训练深层神经网络会导致过度拟合[5],如图1所示,为一种有监督学习的分类流程图。
随机森林(RF)算法关键点在于将经由CART算法[6]构设的尚未剪枝分类决策树,视为基分类器,将Bagging[7]以及随机特征选择[8]进行有机融合,确保决策树模型具备丰富性与多元性。其原理具體表现为:基于原始样本大量借助Bootstrap法对于训练集进行抽取处理,随后各训练集均训练各自的决策树模型,完成以上步骤之后,全部基分类器投票最高类别或其一,此即最终类别。具体步骤如下所示:
(1) 通过Bootstrap 法自原始训练集中抽选数量为 k的样本,确保各样本容量均与原始训练集保持一致;
(2) 基于k个样本依次构设与之对应的k个决策树模型,进一步获取k种分类结果;
(3) 对于各k种分类结果进行记录,从中决定最优分类结果。
最终分类结果选取的分类决策公式[9]如下:
[x=argmaxYi=1kIhix=Y]
其中 , H(x)表示组合分类模型 , hi是单个决策树分类模型,Y 表示输出变量(或称目标变量), I(·)为示性函数。
与传统的分类算法相比,随机森林分类算法具有高准确性等优点,所以近年来无论理论还是方法在许多领域都有了比较迅速的发展。有研究者提出了一种基于随机森林分类器的耕地提取方法[10],通过分类实验结果表明该方法可以在不降低分类性能代价的前提下减少特征冗余;文献[11]研究了基于随机森林特征选择和Ceemd的短期光伏发电预测;唐洵等学者提出基于特征选择与随机森林的混合模型[12],用以检测网络社区中的恶意评论,通过实验得到了良好的判断准确率。
3 实验数据
3.1 英语数据集
使用了SemEval语义测评大赛提供的三个数据集:训练,扩展和测试。所有的数据以xml格式存储,文本编码为UTF-8编码。
数据集包含的属性如下:
QID: 问题的内部标识;
QCATEGORY: 问题的类别;
QDATE: 问题发布的时间;
QUSERID: 发布问题的用户的内部标识符;
CID: 注释的内部标识符;
CUSERID: 用户发布评论的内部标识符
CGOLD: 人类对评论即答案的评价标签,为Good, Bad, Potential, Dialogue, on-English, 或 Other。
3.2 特征提取
从样本中共提取了八个特征,问题和答案对的特征(特征有可能是答案单独的特征,有可能是问题和答案结合产生的特征)。其中包括答案中有多少词,网址连接的个数,图片数;答案的标题和问题标题的基于tfidf的余弦相似度;答案的内容和问题的内容的余弦相似度;答案内容和问题标题的余弦相似度;答案的用户id和问题的用户id是否相同(若相同,很大概率是对话)
4实验结果及分析
针对实验所用数据集使用的如下分类算法与随机森林算法为参照:有逻辑回归(Logistic Regression)分类器,梯度提升回归树(gradient boosting regression tree),K近邻分类器(KNN)。
分类结果如表1所示:
根据精确率,召回率,f1分数,可以看出随机森林和gbrt这两种分类算法的效果最好。但是gbrt对于类别potential的分类不是很好。KNN对于potential的分类效果较其他算法好一些,但是耗时较其他算法有些长,可能是由于测试集的数据不够多,造成了这一结果。后续研究中可以改进的内容包括在特征提取方面,可以从语义的角度考虑,以及在分类时使用神经网络,可以更加有效地处理数据,分类的结果也会更准确。
参考文献:
[1] Cover T,Hart P.Nearest neighbor pattern classification[J].IEEE Transactions on Information Theory,1967,13(1):21-27.
[2] Breiman L,Friedman J H,Olshen R A,et al.Consistency[M]//Classification And Regression Trees. Belmont:Routledge,2017:318-341.
[3] Breiman L.Random Forests[J].Machine Learning,2001,45(3):261-277.
[4] (土)Ethem Alpaydin.机器学习导论[M].范明,昝红英,牛常勇,译.北京:机械工业出版社,2009.
[5] Mayer C,Paul M,Timofte R.Adversarial feature distribution alignment for semi-supervised learning[J].Computer Vision and Image Understanding,2021,202:103109.
[6]Denison David G. T.,Mallick Bani k.,Smith Adrian f. M.. A bayesian cart algorithm[J]. Denison david g. T.;mallick bani k.;smith adrian f. M.,1998,85(2).
[7] Bauer E,Kohavi R.An empirical comparison of voting classification algorithms:bagging,boosting,and variants[J].Machine Learning,1999,36(1/2):105-139.
[8] Stoppiglia H,Dreyfus G,Dubois R,et al.Ranking a random feature for variable and feature selection[J].Journal of Machine Learning Research,2003,3:1399-1414.
[9] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,26(3):32-38.
[10] Su T F,Zhang S W,Tian Y N.Extracting croplands in western Inner Mongolia by using random forest and temporal feature selection[J].Journal of Spatial Science,2020,65(3):519-537.
[11] Niu D X,Wang K K,Sun L J,et al.Short-term photovoltaic power generation forecasting based on random forest feature selection and CEEMD:a case study[J].Applied Soft Computing,2020,93:106389.
[12] 唐洵,湯娟,周安民.基于特征选择与随机森林混合模型的社区恶意评论检测研究[J].现代计算机,2020(19):22-26.
【通联编辑:唐一东】
猜你喜欢
计算机应用(2016年12期)2017-01-13
南水北调与水利科技(2016年6期)2017-01-06
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
