
基于DPC 优化动态路由的胶囊网络算法
2021-05-24 01:21:16林凯迪杜洪波朱立军
沈阳工程学院学报(自然科学版) 2021年2期
林凯迪,杜洪波,朱立军
(1.沈阳工业大学 理学院,辽宁 沈阳 110870;2.北方民族大学 信息与计算科学学院,宁夏 银川 214215)
随着深度学习的不断发展,卷积神经网络得到深入研究,在实时应用、人脸识别、复杂网络、迁移学习及图像分割等领域都有着不凡的表现[1-5]。但是卷积神经网络存在两个重要缺陷,一是无法考虑部分与整体之间的空间关系,二是池化过程中丢失了大量有价值的信息。SABOUR S 等人[6]于2017年提出了胶囊网络及胶囊层间的动态路由算法。胶囊由一组神经元组成,将标量提升为向量,不仅可以表示特征(或实体)间的空间关系,还可以表示特征(或实体)存在的概率。动态路由算法中的不同胶囊层通过路由迭代的方式进行连接,使胶囊以更少的模型参数获得更大的泛化能力。随后,HIN‐TON G E等人[7]于2018年提出了使用EM算法的矩阵胶囊网络,其胶囊包括姿态矩阵和激活概率,感受野的增加使得该网络可以拟合复杂图像。
胶囊网络具备更好地拟合特征的能力,但是计算开销过大成为该网络模型无法广泛应用的阻碍,因此减少计算开销是胶囊网络的一个重要研究方向。文献[8]提出了一种孪生胶囊网络(SCNet),并通过引入丢弃(dropout)操作来减少胶囊的数量。文献[9]提出了SPARSECAPS 网络,建立了一种完全无监督的胶囊网络,并且去掉网络的全连接层。文献[10]则是提出了运用胶囊池化(capsule-pool‐ing)的方法来降低胶囊的数量。
提升胶囊网络的性能主要从两方面进行,即优化胶囊和优化路由[11]。上述胶囊网络的研究均通过优化胶囊来提升网络的性能,而优化路由的方法较少。由于胶囊网络中的动态路由迭代过程非常耗时,SAHU S K 等人[12]提出了内联胶囊路由协议(inter capsule routing protocol,ICRP)来减少路由迭代的计算时间。王维美等人[13]提出一种改进的胶囊网络知识图谱补全方法,通过路由操作产生维度较小的胶囊,生成连续向量并将其与权重向量做点积运算,构建评分函数用于判断三元组的正确性。张天柱等人[14]将模糊聚类算法与动态路由相结合,并添加信息熵度量不确定性的激活值,提出了FM-Cap‐sule及效果更好的F-Capsule,提高了网络的性能。
胶囊网络中的动态路由规则是基于聚类算法思想来实现的,即通过聚类的方式对特征进行整合与递进。文献[6]中动态路由的聚类算法受初始聚类中心的影响较大。密度峰值聚类(DPC)算法是一种基于密度的方法[15],可以处理任意形状的类簇,并且对噪声不敏感,同时该算法具有参数唯一、实现简单、鲁棒性强的特点。本文将普适性更好的DPC 算法与动态路由规则结合,使用DPC 算法获得初始聚类中心,提出DPC-CapsNet 模型。在MNIST 及Fashion-MNIST 上的实验表明,该算法识别准确率较高,在图像分类中有一定的应用潜力和研究价值。
1 胶囊网络
文献[6]提出的胶囊模型,又称为向量胶囊网络。由于选取向量作为胶囊,网络的输出也是向量,因此可以用向量的长度表示目标的存在,向量的方向表示目标的特征。
胶囊模型的隐藏层包含卷积层、初始胶囊层和全连接层3 种隐藏层,如图1 所示。初始胶囊层将卷积层提取的特征图转化为向量胶囊,接着通过动态路由规则将初始胶囊层与全连接层连接输出最终的结果。
首先,卷积层有256 个步长为1 的9×9×1 的卷积核,使用ReLU 激活函数从图像中提取特征图;其次,主胶囊层使用8 个步长为2 的9×9×256 的卷积核将特征图转化为32 个向量胶囊;最后,使用动态路由规则计算出全连接层的输出,得到一个大小为16×10 的矩阵。
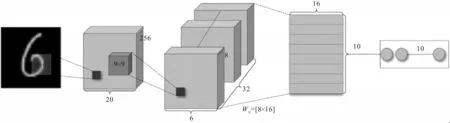
图1 向量胶囊网络结构
胶囊网络是一种具有全新结构的网络,与神经网络相比,神经元的输入和输出都由标量提升为向量,胶囊层间通过动态路由的方式进行特征的整合与传递。用向量的长度表示某个实体存在的概率,向量的模长越接近1,实体存在的可能性越大。此外,与标量相比,向量还能表达信息的种类(姿态、颜色、纹理等),因此胶囊网络极大地丰富了特征的表达能力。
动态路由规则的实质就是通过聚类方法,将底层特征组合为上层的特征。文献[6]中的动态路由规则采用的是k-means 聚类算法。假设胶囊的输入特征为ui(i=1,2,…,n),通过k-means聚类获得k个聚类中心vj(j=1,2,…,k),即下一胶囊层的特征向量。低层胶囊通过聚类的方式将特征传递给高层胶囊,如图2所示。
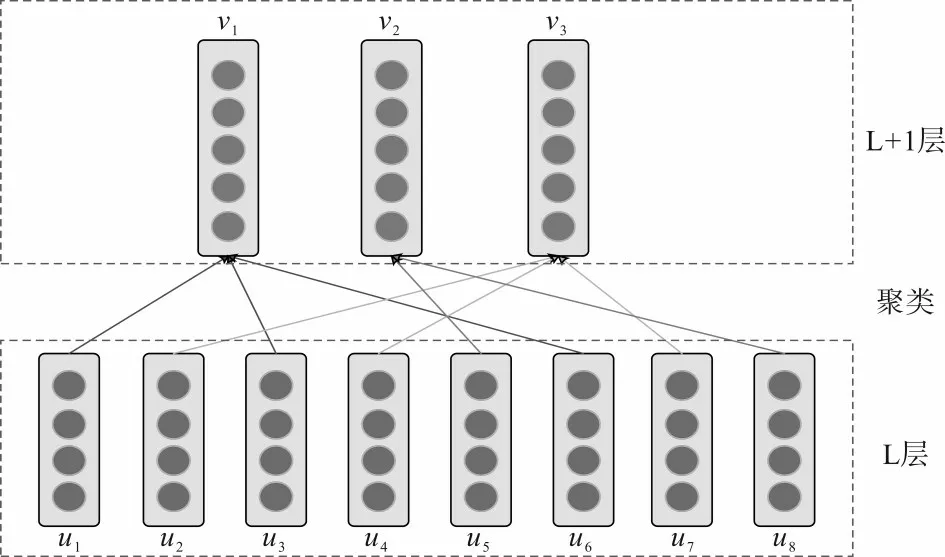
图2 低层胶囊通过聚类的方式将特征传递给高层胶囊
k-means聚类算法因其快速简洁的优点而被广泛使用,但是也有局限性。该算法需要随机确定k个初始聚类中心,并根据k个中心来确定一个初始划分,然后迭代地进行调整,直到聚类中心不再改变[15]。因此,初始聚类中心的选择对聚类结果的优劣有关键性的作用。
密度峰值聚类(DPC)算法是RODRIGUEZ A等人[16]于2014 年提出的一种新型聚类算法,能够快速地发现任意形状数据的密度峰值点,可以作为聚类中心。该算法具有参数易确定、鲁棒性强的特点。本文采用DPC 算法来计算初始聚类中心,解决k-means算法对初始聚类中心敏感可能导致聚类结果不稳定的问题。
2 密度峰值聚类的动态路由算法
2.1 密度峰值聚类算法
密度峰值聚类算法是粒度计算模型。该算法基于两个假设:
1)聚类中心被局部密度低的相邻数据点围绕;
2)聚类中心与更密集的数据点i之间的距离较远。
对于数据点i,需要计算两个值:数据点的局部密度ρi及样本距离δi。
局部密度ρi包括以下两种计算方式:
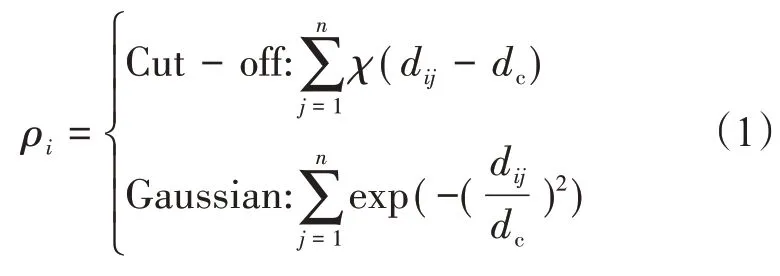
式中,dc为截断距离,由人工确定,通常选取将所有数据对象两两之间的距离按升序排序后前2%位置的数值距离作为截断距离。
数据点i的样本距离:

2.2 基于密度峰值聚类的动态路由算法
胶囊网络中的动态路由规则是基于k-means聚类算法的思想实现的,该算法只能处理球形数据,并对初始聚类中心的选择较为敏感。针对这一问题,本文将DPC 算法与动态路由规则结合,提出DPC-CapsNet 模型,从优化路由的角度提高网络的性能。
胶囊网络中,用输出向量的长度表示实体存在的概率。因此,使用非线性的压缩函数将向量压缩至[0,1]。
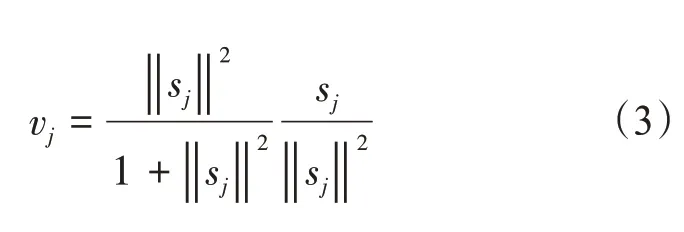
式中,vj是胶囊j的向量输出;sj是总输入。
除第一个胶囊层,胶囊的总输入sj由下一层的所有胶囊的预测向量计算求得。

式中,Wij是权重矩阵;cij是由动态路由迭代过程决定的耦合系数,表示胶囊i和胶囊j的连接概率,且有∑cij=1。
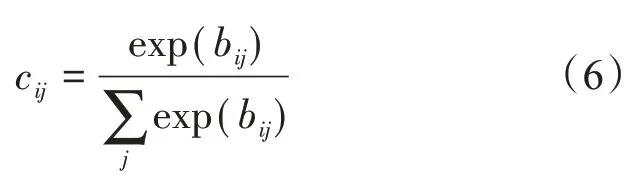
式中,bij是胶囊i和胶囊j的先验概率,通过路由迭代的方式进行更新。
在文献[6]中,bij初始化为0。考虑到k-means算法易受初始聚类中心的影响,本文使用密度峰值聚类算法先获得初始聚类中心,并将胶囊与聚类中心的距离作为权重。
首先计算局部密度。式(1)中,前者Cut-off ker‐nel 针对的是离散的数据,后者Gaussian kernel 针对的是连续的数据。本文选取第2种计算公式,即
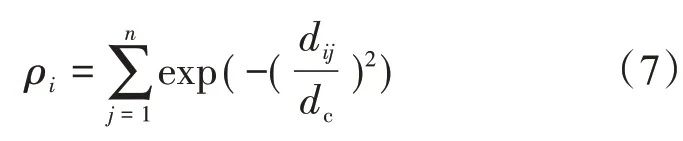
连续的局部距离ρi便于计算和编程实现。将聚类中所有样本点之间的相互距离进行升序排序,在2%的位置的距离数值记为dc,即2%×N,N=[|D|×(|D|-1) ]/2。

对于每一个样本数据均可求出对应的ρi和δqi,令γi=ρiδqi,对γi(i=1,2,…,m)再按从大到小的顺序排列。由于本文所使用的两种图像数据集均为10 个分类,所以取前10 个对象作为聚类中心aj(j=1,2,…,10)。计算胶囊i与聚类中心aj的距离,并将该距离作为初始连接概率,更新bij。然后进入路由迭代阶段。文献[6]中建议在路由迭代过程中迭代3 次,本文采用同样的次数,即取r=3,迭代3 次后得到胶囊j的输出向量vj。
综上,使用密度峰值聚类算法的动态路由规则的流程如下:
输入:迭代次数r,胶囊层数l;
输出:胶囊j的输出向量vj。
step 1:低层胶囊权重映射;
step 2:确定截断距离dc;
step 3:计算局部密度ρi和样本距离δqi;
step 4:计算γi=ρiδqi,并对γi降序排列,取前10个值作为聚类中心aj;
step 5:计算每个对象与各聚类中心aj的距离,更新bij;
step 6:迭代r次:
①根据cij=softmax(bij),计算胶囊层间的连接概率;
②计算下一层胶囊的总输入sj;
③将sj压缩到[0,1];
④更新bij;step 7:返回vj。
3 实验及结果分析
3.1 实验环境
实验仿真环境为python3.6、TensorFlow1.14、keras2.2.5。硬件配置为戴尔(DELL)T640深度学习GPU 运算塔式服务器主机,内存为64G,显卡为1RTX2080。
3.2 数据集
实验采用测试图像分类任务算法性能的2 个图像数据集(MNIST 和Fashion-MNIST 数据集)对算法进行测试和评价。
MNIST 来自NIST(National Institute of Stan‐dards and Technology)的手写数字数据集,常用于各种图像处理的训练及测试。训练集由250 个不同人手写的数字构成,分别为125 名高中学生和125名人口普查局的工作人员。测试集也由相同比例的数据构成,且所有图片均为28×28 的灰度图像。训练集图像有60 000张,测试集图像有10 000张。
由XIAO H 等人[17]创建的Fashion-MNIST 数据集来自10 个类别,每个类别有7 000 幅图像,包括T 恤、裤子、套头衫、连衣裙、外套、凉鞋、衬衫、运动鞋、包和靴子。与MNIST 相同,该数据集同样有70 000 张大小为28×28 的灰度图像,训练集和测试集的比例为6:1。
3.3 实验分析
DPC-CapsNet 模型由编码器和解码器构成。编码器由卷积层、PrimaryCaps及DigitCaps构成,解码器由后三个全连接层构成。各层参数如表1所示。

表1 DPC-CapsNet模型参数
本文从训练损失值及图像分类的准确率两方面对算法进行测试和评价。模型的损失函数为
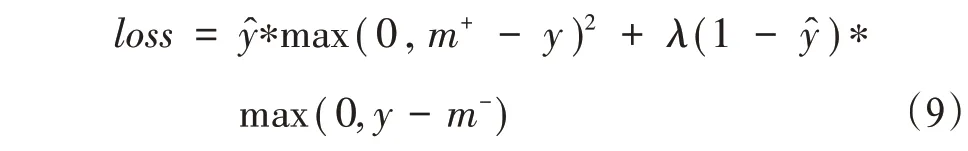
在训练过程中,设置路由次数为3,batch_size为128,迭代周期epoch 为50。DPC-CapsNet 模型在MNIST上的实验结果如图3所示。其中,图3a为损失情况,图3b 为训练集上的准确率,图3c为测试集上的准确率。从图中可以看出,训练经过2 000 步时,损失函数值和训练精度基本趋于平稳,收敛速度较快,测试精度平均值为99.51%。仅以三层(一个卷积层和两个胶囊层)的网络结构达到了较高的准确率,证明了该网络在特征拟合上的高效性,以及较强的泛化能力。
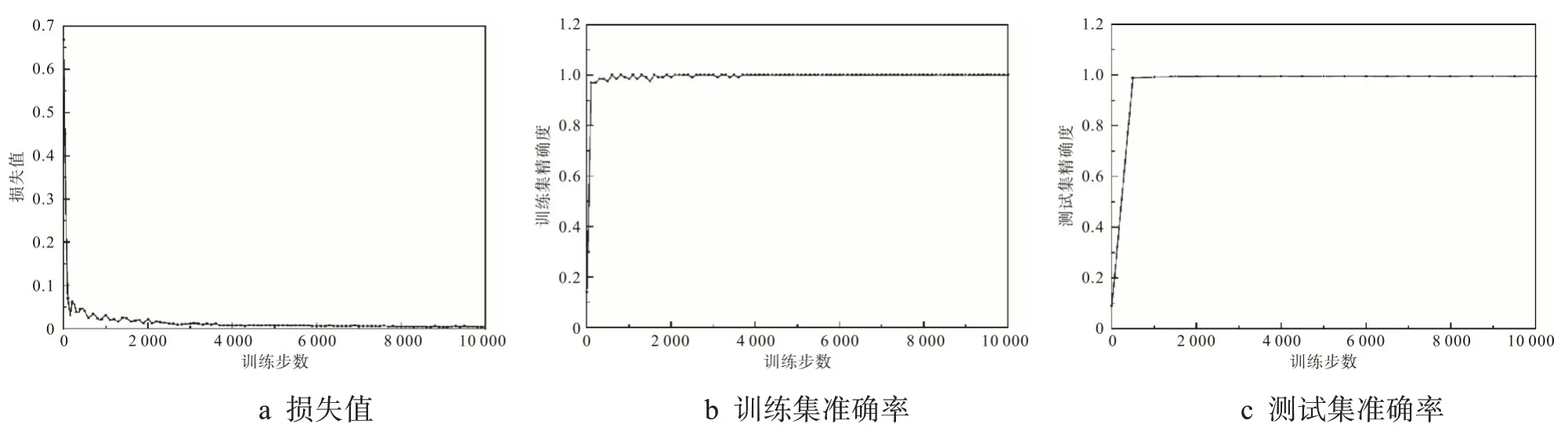
图3 MNIST上的实验结果
为了进一步证明DPC-CapsNet的有效性,将模型在更加复杂的图像数据集Fashion-MNIST 上进行实验,结果如图4 所示。由图4 可以看出,与MNIST 上的实验相比,训练时间更长,收敛速度随着数据集的复杂程度升高而降低,训练达到5 000步时,损失函数值和训练精度基本达到平稳状态。测试集的平均准确率虽然低于上一个实验,但是也可以达到91.41%,这说明本文提出的模型在图像分类中具有一定的优势。
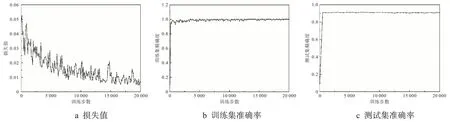
图4 Fashion-MNIST上的实验结果
为了进一步测试本文模型的性能,证明改进路由规则的有效性,在相同的实验环境下,使用卷积神经网络(CNN)、胶囊网络(CapsNet)、文献[14]中提出的FM-Capsule 和F-Capsule 以及本文提出的DPC-CapsNet 模型分别在MNIST 和Fashion-MNIST 数据集上进行实验,分类准确率的结果如表2所示。
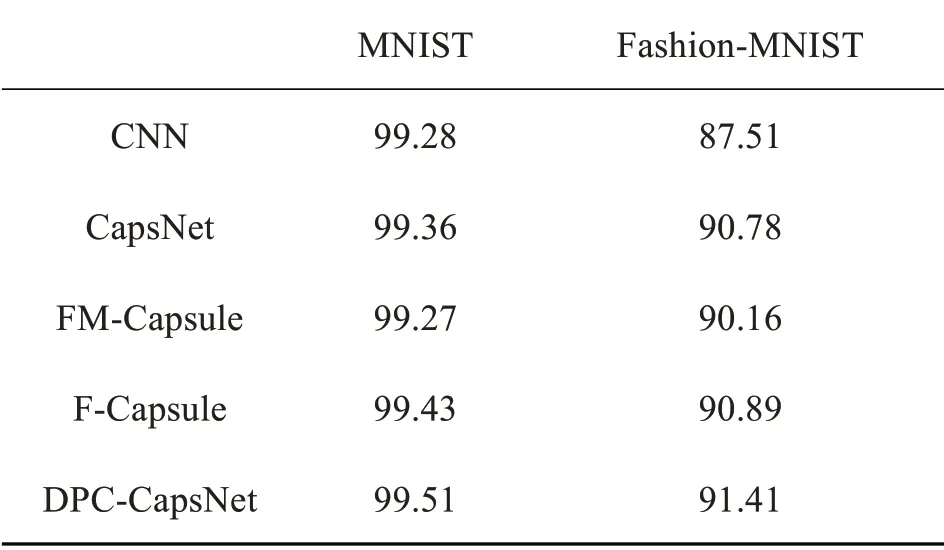
表2 图像分类准确率的比较 %
从表2中可以得出如下结论:
1)本文构建的DPC-CapsNet模型在MNIST 和Fashion-MNIST 上的准确率均为最高,说明采用密度峰值聚类算法进行优化的胶囊网络可以使图像分类结果更加准确;
2)在MNIST 数据集上,4种网络结构的分类准确率差距较小,都达到了99%以上,DPC-CapsNet的分类准确率略优于另外4种网络结构;
3)在Fashion-MNIST 数据集上,CNN 的结果明显低于胶囊网络、FM-Capsule、F-capsule 及本文提出的DPC-CapsNet。这也说明了将标量提升为向量使得胶囊网络对于目标的位置、角度变化更具有鲁棒性。
4 结论
本文针对胶囊网络中原有的聚类算法对初始聚类中心敏感的问题,构建了一种新型胶囊网络模型DPC-CapsNet。将密度峰值聚类算法与胶囊网络中的动态路由规则结合,先使用密度峰值聚类算法计算出初始聚类中心,再进入路由迭代过程进行特征的整合与递进。在MNIST 和Fashion-MNIST 两种数据集上的实验证明,该模型能够较快地收敛,并且有效地提高图像分类的准确率,具有实际应用的价值。但是,与卷积神经网络相比,胶囊网络的层数较浅,在复杂数据集上的识别准确率的表现还不理想。因此,加深网络结构,优化动态路由,增加训练技巧等成为下一步的研究方向。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
网络安全和信息化(2018年3期)2018-11-07 03:02:44
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电测与仪表(2014年16期)2014-04-22 05:20:30
电视技术(2014年19期)2014-03-11 15:38:20
